祝大家国庆节快乐! 中秋节快乐!
在真实世界的工业场景中,大规模语言模型(LLMs)的部署和应用面临着一个持续的、根本性的挑战:环境是动态变化的。新的业务需求、不断涌现的数据模式、持续迭代的任务目标,都要求模型具备一种“自进化”的能力——即能够在不依赖大量人工干预的情况下,自主地学习新知识、适应新任务,同时不遗忘已经掌握的核心能力。
然而,传统的模型训练范式,无论是“一次性”的预训练-微调,还是简单的序贯微调,都难以应对这种动态性。现有主流的持续学习(Continual Learning, CL)方法在试图解决此问题时,往往陷入一个两难的困境:
-
以“回放”为基础的方法的困境:这类方法通过存储历史数据或生成伪样本来“复习”旧知识,以对抗遗忘。然而,在工业级应用中,存储和处理海量历史数据的成本是巨大的。更重要的是,生成的伪样本往往会引入噪声,污染任务的表征空间,从而干扰模型的学习。 -
以“正则化”为基础的方法的瓶颈:这类方法通过对模型参数的更新施加约束,保护那些对旧任务重要的权重。这种策略在一定程度上缓解了遗忘,但其代价是牺牲了模型的“可塑性”。过于严格的约束会妨碍模型充分学习新任务的特有模式,导致在新任务上表现不佳。 -
以“参数隔离”为基础的方法的局限:这类方法为每个任务分配独立的参数空间,从物理上避免了新旧知识的冲突,从而最大程度地保留了旧任务的性能。但这种“老死不相往来”的设计也完全切断了任务间的知识迁移路径。模型无法利用从旧任务中学到的通用知识来加速新任务的学习,导致整体学习效率低下,难以扩展。
这三种方法的局限性共同指向了一个关键的研究空白:我们如何设计一个统一的框架,使其既能像参数隔离方法一样有效地“保留”任务的专属知识,又能像知识共享方法一样高效地“迁移”任务间的通用知识,从而在模型的稳定性和可塑性之间找到一个理想的平衡点?
来自北京邮电大学和腾讯 AI Lab 的研究者们在论文《Self-Evolving LLMs via Continual Instruction Tuning》中,为这一问题提供了一个富有洞察力的解决方案。他们提出的 MoE-CL (Mixture of Experts for Continual Learning) 框架,是一种新颖的、参数高效的对抗性混合专家架构。它结合了混合专家(MoE)的思想和生成对抗网络(GAN)的训练机制,旨在解决大模型在持续指令微调过程中的灾难性遗忘问题,并最终赋予模型持续自进化的能力。

-
论文标题:Self-Evolving LLMs via Continual Instruction Tuning -
论文链接:https://www.arxiv.org/pdf/2509.18133
1. 背景
在深入 MoE-CL 的技术细节之前,我们有必要首先清晰地定义其所要解决的核心问题——灾难性遗忘,以及其追求的最终目标——大模型的自进化。
1.1 什么是灾难性遗忘 (Catastrophic Forgetting)?
灾难性遗忘是神经网络在持续学习或序贯学习(sequentially learning)场景下普遍存在的一个现象。当一个已经在一个任务(例如,任务 A)上训练好的模型,接着在另一个新的任务(例如,任务 B)上进行训练时,模型为了适应任务 B 的数据分布,会调整其内部的权重参数。在这个过程中,那些对任务 A 至关重要的权重很可能被“覆盖”或“破坏”,导致模型在任务 A 上的性能出现断崖式下跌。
这个现象的根源在于神经网络参数的“共享性”和学习过程的“覆盖性”。对于一个给定的模型,其参数是有限的,并且被所有任务共享。当模型优化算法(如梯度下降)为了最小化新任务的损失函数而更新参数时,它并不会“考虑”这些更新对旧任务性能的影响。因此,新知识的“写入”过程,往往伴随着旧知识的“擦除”。
这一现象构成了所谓的 “稳定性-可塑性”困境 (Stability-Plasticity Dilemma) :
-
可塑性 (Plasticity) :模型能够快速从新数据中学习新知识的能力。 -
稳定性 (Stability) :模型能够保持已有知识不被新知识干扰的能力。
一个理想的持续学习系统,必须在这两者之间取得平衡。过度追求可塑性会导致灾难性遗忘;而过度追求稳定性则会让模型僵化,无法适应变化。
1.2 工业界对 LLM 自进化的迫切需求
“自进化”是工业界对理想 LLM 应用形态的一种愿景。它指的是模型能够在部署后,根据不断变化的业务需求和数据流,自主地进行知识的迭代、能力的优化和性能的保持,而无需频繁地、大规模地进行重新训练或人工干预。
以论文中提到的腾讯内容合规审核场景为例:
互联网平台每天都会产生数以亿计的文本、图片、视频内容。这些内容的合规标准并非一成不变,而是随着法律法规的更新、平台政策的调整以及新型风险的出现而动态演化。例如,今天出现的某种新型网络诈骗话术,在昨天的模型知识库中是不存在的。模型必须能够快速学习并识别这种新模式。
在这种场景下,如果模型不具备自进化能力:
-
响应滞后:每当出现新的审核规则,都需要算法工程师收集数据、标注、重新训练模型并上线。这个周期可能长达数天甚至数周,期间平台将面临巨大的合规风险。 -
知识遗忘:在为新规则训练模型时,如果采用了简单的序贯微调,模型可能会忘记如何识别旧的、但仍然存在的风险类型,导致审核覆盖率下降。 -
成本高昂:频繁地对整个模型进行全量微调,不仅计算成本高昂,也需要大量的人力投入。
因此,一个具备自进化能力的 LLM,应当能够:
-
增量式学习:当新的审核任务(例如,识别新型诈骗话术)出现时,模型能够增量式地吸收这部分知识。 -
知识保持:在学习新知识的同时,模型在旧的审核任务(例如,识别色情、暴力内容)上的性能不应下降。 -
知识迁移:如果新旧任务之间存在关联(例如,不同类型的诈骗话术可能共享某些语言模式),模型应该能够利用旧知识加速新知识的学习。
MoE-CL 正是为实现这一“自进化”愿景而设计的技术框架。
1.3 主流持续学习范式梳理
为了更好地理解 MoE-CL 的设计动机,我们梳理了当前主流的持续学习方法及其核心思想:
-
回放-重演 (Replay-based) 方法:
-
核心思想:温故而知新。在训练新任务时,从一个“记忆缓冲区”中抽取一部分旧任务的样本,与新任务的样本混合在一起进行训练。 -
优点:直观有效,能够直接缓解遗忘。 -
缺点: -
存储开销:需要额外存储旧数据,对于数据量巨大的 LLM 任务不现实。 -
计算开销:训练时需要同时处理新旧数据,增加了计算负担。 -
数据隐私:在许多场景下,存储和重复使用用户数据存在隐私风险。 -
伪样本噪声:一些方法尝试用生成模型来“创造”旧样本,但生成的样本质量难以保证,可能与真实分布存在偏差,引入噪声。
-
-
-
正则化 (Regularization-based) 方法:
-
核心思想:保护重要知识。通过在损失函数中增加一个正则化项,来惩罚对旧任务重要的参数的大幅变动。 -
优点:无需存储旧数据,概念优雅。 -
缺点: -
计算复杂:通常需要计算参数的重要性(如 Fisher 信息矩阵),计算量较大。 -
过度约束:为了保护旧知识,可能会过度限制模型学习新知识的能力,导致模型在新任务上性能不佳,即“可塑性”不足。 -
对任务相似性敏感:当新旧任务差异巨大时,效果往往不理想。
-
-
-
参数隔离 (Parameter Isolation / Dynamic Architectures) 方法:
-
核心思想:专人专事。为每个任务分配一组专属的、独立的模型参数。训练新任务时,只更新其对应的参数,而将旧任务的参数冻结。 -
优点:完全避免了灾难性遗忘,在旧任务上的性能得以完美保留,“稳定性”极佳。 -
缺点: -
参数量线性增长:随着任务数量的增加,模型参数量会线性增长,导致模型变得臃肿。 -
缺乏知识迁移:由于各任务的参数相互隔离,模型无法将在任务 A 上学到的通用知识(例如,语言的句法结构)应用到任务 B 的学习中,导致学习效率低下。
-
-
分析至此,我们可以清晰地看到,现有方法都在“稳定性”和“可塑性”的天平上有所偏颇。MoE-CL 的设计初衷,正是要打破这种非此即彼的局面,通过一种创新的架构,同时实现高稳定性和高可塑性。
2. MoE-CL
MoE-CL 的核心创新在于,它没有在“隔离”和“共享”之间做选择题,而是将两者有机地结合在一个统一的框架内。它认为,对于一个持续学习的任务序列,知识可以被分解为两个部分:一部分是 任务专属知识 (task-specific knowledge) ,另一部分是 跨任务的通用知识 (cross-task generalizable knowledge) 。
-
保留任务专属知识,需要 参数隔离。 -
迁移通用知识,需要 参数共享。
MoE-CL 正是基于这一思想构建了其独特的双专家架构。
2.1 核心思想
MoE-CL 的设计哲学可以概括为:用专属的“专家”来固守阵地,用共享的“专家”来开疆拓土。
-
固守阵地 (知识保持) :为每一个到来的新任务,都分配一个独立的、专属的 LoRA 专家。这个专家只负责学习该任务的特有知识。一旦该任务训练完成,这个专属专家就会被“冻结”,其参数在后续其他任务的训练中不会被修改。这从根本上保证了任务专属知识的稳定性,解决了灾难性遗忘问题。
-
开疆拓土 (知识迁移) :除了所有专属专家外,系统中还存在一个所有任务都共同拥有的“共享 LoRA 专家”。在训练任何一个任务时,这个共享专家都会参与其中并得到更新。它的目标是学习所有任务背后共通的、可以迁移的模式和表征。这为模型在不同任务间进行知识迁移提供了桥梁。
通过这种“一专多能 + 一通百通”的组合,MoE-CL 试图达到两全其美的效果。
2.2 MoE-CL 整体架构
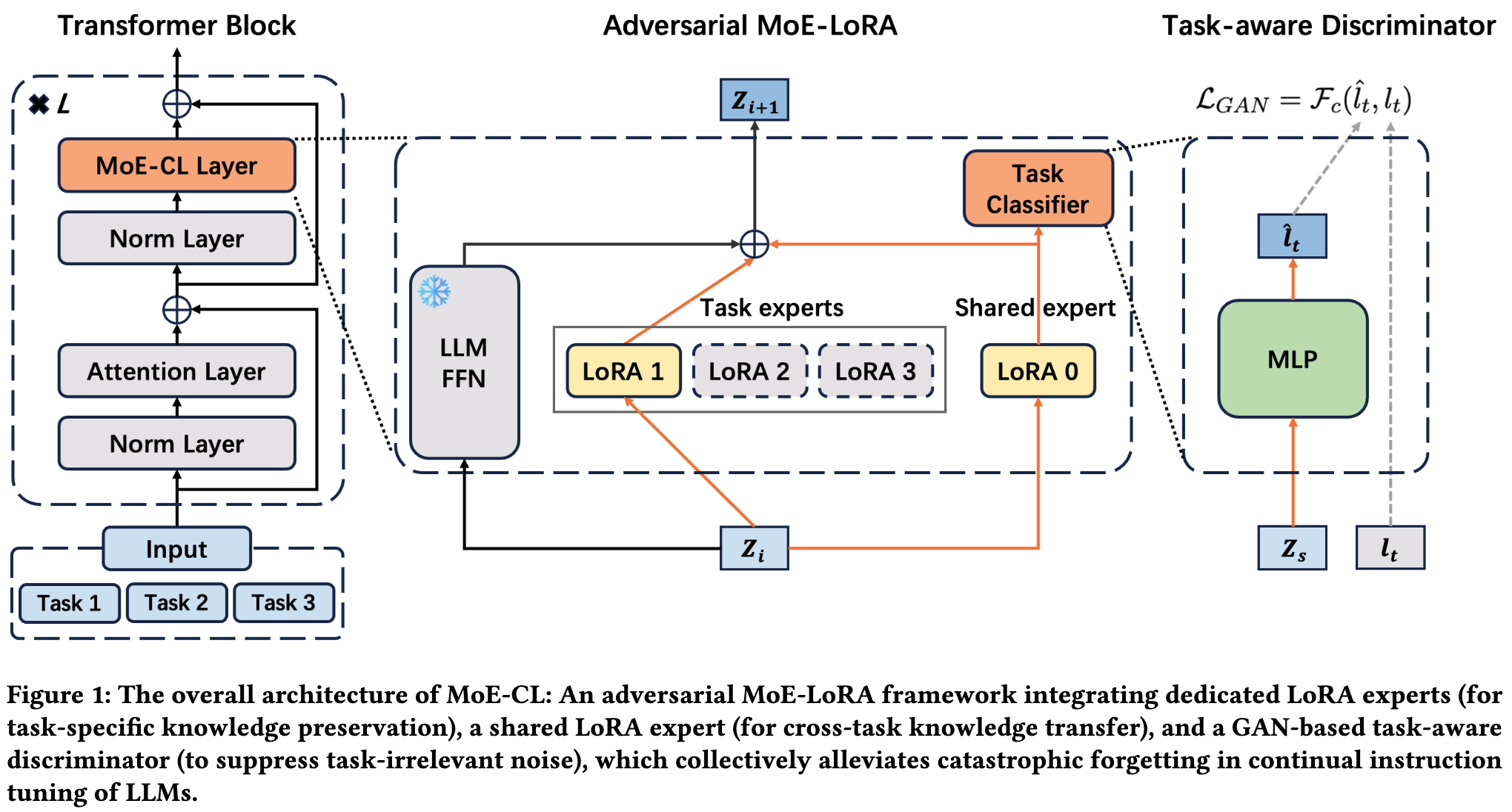
上图展示了 MoE-CL 的整体架构。我们可以从左到右,顺着数据流动的路径来理解它。
-
输入与 Transformer 模块:输入数据首先通过标准的 Transformer 模块(如 Attention Layer, Norm Layer 等)。
-
MoE-CL 层:在 Transformer 模块的 Feed-Forward Network (FFN) 部分,MoE-CL 进行了改造。传统的 FFN 层被一个 MoE-CL 层 所取代。这是整个框架的核心。
-
双路径专家系统:进入 MoE-CL 层后,数据流被分成了两条路径:
-
任务专家路径 (Task experts) :这里有一系列的 LoRA 专家(LoRA 1, LoRA 2, LoRA 3...)。假设当前正在处理的是任务 2,那么输入数据 会被送入 LoRA 2,生成一个任务专属的表征 。 -
共享专家路径 (Shared expert) :同时,输入数据 也会被送入共享的 LoRA 0,生成一个跨任务的共享表征 。
-
-
门控与融合:两条路径的输出 和 并不会被简单相加,而是通过一个门控网络(Gating Network)进行加权融合。该网络根据输入 自动学习两个权重 和 ,最终的输出 是 。这种动态加权机制使得模型可以根据当前输入的特性,自主决定更多地依赖专属知识还是通用知识。
-
对抗训练模块 (Adversarial MoE-LoRA) :这是 MoE-CL 的另一个关键创新。共享专家路径的输出 并不仅仅用于最终的预测,它还会被送入一个“任务感知判别器”(Task-aware Discriminator,在图中表现为一个 Task Classifier)。这个判别器的作用我们将在第三章详细阐述。它与共享专家构成了一个生成对抗网络(GAN),其目的是“提纯”共享知识。
2.3 双专家 LoRA
为了让架构更加清晰,我们来深入了解其核心组件——LoRA 专家。
-
LoRA 基础回顾
LoRA (Low-Rank Adaptation) 是一种参数高效的微调技术。其核心思想是,在微调大型预训练模型时,我们不需要更新所有的原始权重。对于一个原始的权重矩阵 ,LoRA 冻结 ,并在旁边增加一个“旁路”,这个旁路由两个低秩(low-rank)矩阵 和 的乘积来表示权重的更新量 ,其中秩 。因此,前向传播的计算变为:
在微调时,我们只训练参数量很少的 和 矩阵,而巨大的 矩阵保持不变。这使得微调的成本大大降低。在 MoE-CL 中,每一个“专家”,无论是任务专属的还是共享的,都是一个这样的 LoRA 模块。
-
任务专属 LoRA 专家 (Dedicated Task LoRA Experts)
它们是模型“记忆”的守护者。对于任务序列 ,系统会维护 个专属 LoRA 专家 。当训练任务 时:-
专属专家 的参数(即 和 )会被更新。 -
所有其他的专属专家 的参数都保持冻结。 -
这确保了为任务 学习的知识只会存储在 中,不会干扰到任何其他任务的知识。
-
-
共享 LoRA 专家 (The Shared LoRA Expert)
它是模型“泛化”能力的源泉。系统中只有一个共享专家 。在训练任何任务 时:-
共享专家 的参数(即 和 )都会被更新。 -
因为它见过了所有任务的数据,所以它有能力学习到超越单个任务的、更普适的语言模式和语义特征。例如,在多个不同的内容审核任务中,它可能会学到关于“负面情绪”的通用表征,而这种表征对于识别辱骂、仇恨言论等多种具体任务都是有益的。
-
这种设计在参数效率和功能划分上都做得很好。一方面,使用 LoRA 作为专家的基本单元,使得即使任务数量增多,新增的参数量也十分有限。另一方面,专属专家和共享专家的明确分工,为同时解决“遗忘”和“迁移”两大难题奠定了结构基础。然而,仅仅有共享专家还不够,我们还需要确保它学到的是“精华”而非“糟粕”。这就引出了 MoE-CL 的下一个核心武器——对抗训练。
3. 对抗训练
如果说双专家结构是 MoE-CL 的“骨架”,那么对抗训练机制就是其“灵魂”。它解决了一个共享设计中至关重要但又常常被忽略的问题:如何保证共享的知识是真正有益的?
3.1 为什么需要“过滤”?
一个天真的共享专家,在学习了多个任务之后,其学到的“共享知识”中很可能会混杂着大量 任务相关的噪声 (task-relevant noise) 。
举个例子,假设共享专家先后学习了两个任务:
-
任务 A:财经新闻分类。 -
任务 B:体育新闻分类。
在学习任务 A 时,共享专家可能会将“股票”、“财报”等词汇的表征与“财经”这个概念强相关。当它再去学习任务 B 时,虽然它也能学到“篮球”、“奥运会”等词汇,但其内部的表征空间中,可能依然残留着任务 A 的“痕迹”。如果此时来了一个新任务 C——科技新闻分类,其中一篇文章提到了“某科技公司的股票大涨”,那么共享专家提供的通用知识可能会因为残留的“财经”任务痕迹,而对任务 C 的判断产生负面干扰(Negative Transfer)。
理想的共享知识应该是 任务无关的 (task-agnostic) 或 任务对齐的 (task-aligned) 。它应该关注更底层的、通用的语义和句法结构,而不是某个特定任务的“关键词”。我们需要一个机制,来从共享表征中“滤除”掉那些只对特定任务有意义的“指纹信息”,只保留那些普适的、可迁移的“DNA 信息”。
GAN(生成对抗网络)为此提供了一个优雅的解决方案。
3.2 GAN 在 MoE-CL 中的应用
在 MoE-CL 中,研究者构建了一个迷你的 GAN 系统,其参与者和目标如下:
-
角色设定
-
生成器 (Generator) :由 共享 LoRA 专家 扮演。它的任务是,接收来自上游的中间表征 ,并生成一个“共享表征” 。它的目标是让这个 变得尽可能“通用”和“模糊”,使得下游的判别器无法从中判断出这个样本最初属于哪个任务。 -
判别器 (Discriminator) :由一个 任务感知分类器 扮演。它是一个简单的多层感知机(MLP),接收生成器产生的共享表征 ,并尽力去预测这个样本对应的原始任务标签 。
-
-
对抗博弈过程
-
判别器学习:判别器努力学习,试图从共享专家生成的 中找到蛛丝马迹,以准确地分辨出原始任务的身份。它的优化目标是最小化任务分类的交叉熵损失 。 -
生成器学习:共享专家(生成器)则反其道而行之。它的优化目标是 最大化 判别器的分类损失 。也就是说,它要主动地调整自己的参数,抹去 中所有能够暴露任务身份的特征,让判别器“猜不着”。
-
-
最终效果
经过多轮的对抗训练,当系统达到一个均衡状态时,共享专家为了“愚弄”判别器,被迫学会了生成 任务不变性 (task-invariant) 的表征。这些表征中,那些与特定任务强相关的“噪声”被抑制了,而那些跨任务通用的“信号”则被保留了下来。
通过这种方式,共享专家提供的知识变得更加“纯净”和“安全”,在迁移到新任务时,产生负面干扰的风险大大降低。
3.3 模型的整体优化目标
综合来看,在训练任务 时,MoE-CL 的整体优化目标由两部分构成:
我们来分解这个公式:
-
:这是标准的 监督微调损失 (Supervised Fine-Tuning Loss) 。它是模型最终输出的预测结果与真实标签之间的损失(例如,交叉熵损失)。这部分损失确保了模型(包括任务专属专家和共享专家的组合)能够正确地学习当前任务 。这是模型学习的“主线任务”。
-
:这是来自 判别器的任务分类损失。如前所述,它衡量了判别器根据共享表征 预测任务标签的准确性。
-
:这里的负号是关键。对于整个模型的端到端训练而言,共享专家是其中的一部分。当优化整个损失函数 时,梯度下降会试图最小化 。由于 前面有一个负号,最小化 就等价于 最大化 。这正是我们希望共享专家(生成器)去做的——让判别器犯错。 是一个超参数,用于平衡主线任务学习和对抗训练这两个目标的重要性。
通过这个统一的损失函数,MoE-CL 将“学习新任务”和“提纯共享知识”这两个目标融合在了一次梯度下降的过程中,实现了高效的端到端训练。
4. 实验
MoE-CL 在多个基准上进行了详尽的实验,并与当前主流方法进行了对比。
4.1 实验基准与评价指标
-
数据集
研究者选用了两个具有代表性的数据集:-
MTL5:这是一个公开的、远距离领域(far-domain)的基准,包含了四个领域的文本分类任务(AGNews, Amazon, DBPedia, Yahoo)。这些任务领域差异大,语义鸿沟明显,对模型的持续学习和知识迁移能力构成了严峻的挑战。 -
Tencent3:这是一个来自腾讯真实业务场景的大规模工业数据集,包含了三个不同业务场景下的内容合规审核样本(均为二分类任务)。这些任务领域相对同质,但数据分布和审核侧重点有所不同,代表了典型的工业应用场景。
同时使用这两个数据集,可以分别检验模型在学术基准上的泛化能力和在工业场景下的实用价值。
-
-
评价指标
实验采用了持续学习领域标准的三个核心指标:-
平均准确率 (Accuracy, Acc) :在所有任务都学习完毕后,模型在所有任务的测试集上的平均准确率。这是衡量模型综合性能最核心的指标。 -
后向迁移 (Backward Transfer, BwT) :衡量学习新任务对旧任务性能的影响。其计算方式为:模型在学习完所有任务后在某个旧任务上的准确率,减去它刚学完那个旧任务时的准确率。一个接近 0 或正数的 BwT 值,意味着模型很好地克服了遗忘。负值越大,表示遗忘越严重。 -
前向迁移 (Forward Transfer, FwT) :衡量旧任务的知识对新任务学习的帮助程度。其计算方式为:模型在学习了某些旧任务后在某个新任务上的准确率,减去一个独立训练的模型在该新任务上的准确率。一个正数的 FwT 值,意味着发生了有效的知识迁移,模型在新任务上学得更好。
-
4.2 对比方法
MoE-CL 与以下几种有代表性的方法进行了比较:
-
Per-task FT:为每个任务独立训练一个 PEFT 模块。任务间完全隔离,无知识迁移。它可以被看作是 BwT 的“上限”(无遗忘),但 FwT 为 0。 -
Sequential FT-P:所有任务共享同一个 PEFT 模块,并按顺序进行训练。这种方法最大化了知识共享,但也是灾难性遗忘最严重的“下限”参考。 -
O-LoRA:一种先进的持续学习方法,它通过在正交的低秩子空间中为不同任务学习 LoRA 权重,来减少任务间的干扰。 -
MoCL:当时(SOTA)的持续学习方法之一,它也为每个任务配备了 PEFT 模块,并通过计算输入与任务向量的相似度来融合模块的输出。
4.3 主要结果解读
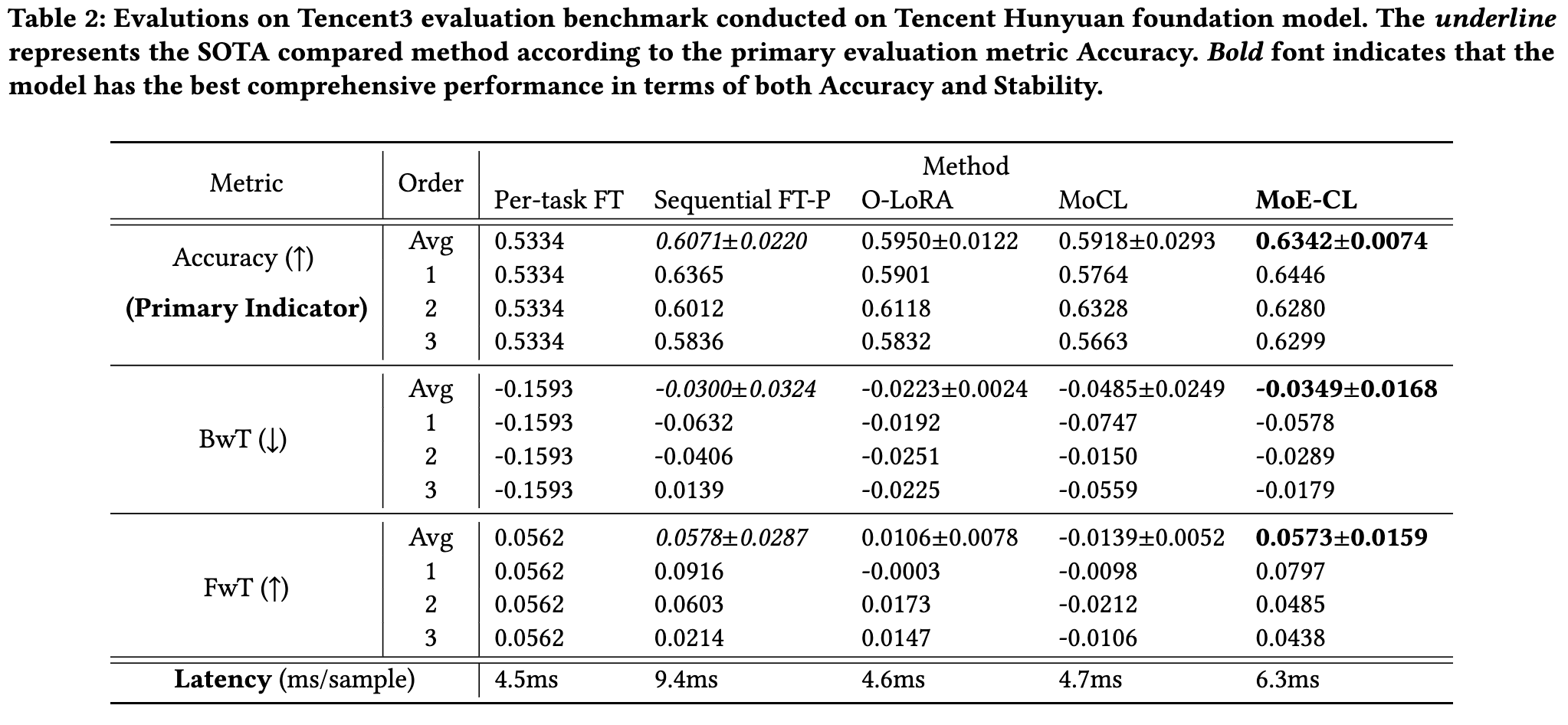
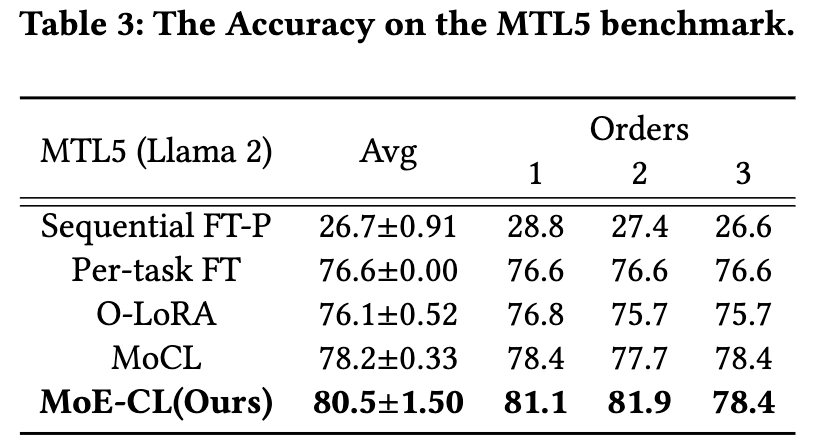
从实验结果表格中,我们可以总结出几个关键的观察:
-
综合性能优势:在 MTL5 和 Tencent3 两个基准上,MoE-CL 在核心指标 平均准确率 (Avg.ACC) 上均取得了最佳表现,并且其结果的标准差较小。这说明 MoE-CL 不仅性能强大,而且对于不同的任务训练顺序鲁棒性高,表现稳定。
-
在“稳定-可塑”困境中的平衡:
-
与 Sequential FT-P 相比,MoE-CL 的 BwT 值要好得多(负得更少),表明其通过专属专家机制有效地缓解了灾难性遗忘。 -
与 O-LoRA 和 Per-task FT 相比,MoE-CL 在 FwT 上表现更优,证明其共享专家和对抗训练机制成功地促进了正向的知识迁移。 -
MoE-CL 并非在某一个单项指标上(如 BwT)做到极致,而是在 Acc, BwT, FwT 这三个相互制约的指标上取得了最佳的综合平衡,这恰恰是持续学习系统最需要的能力。
-
-
对任务异质性的适应能力:
-
在任务差异巨大的 MTL5 基准上,Sequential FT-P 的参数共享策略导致了严重的性能崩溃(Avg.ACC 仅为 26.7%)。而 MoE-CL 依然能保持高准确率(80.5%),显示了其架构在处理异构任务时的鲁棒性。 -
在任务相对同质的 Tencent3 基准上,参数共享的优势得以体现,Sequential FT-P 表现不错。但 MoE-CL 凭借更精细的知识管理机制,性能依然领先。
-
4.4 消融实验
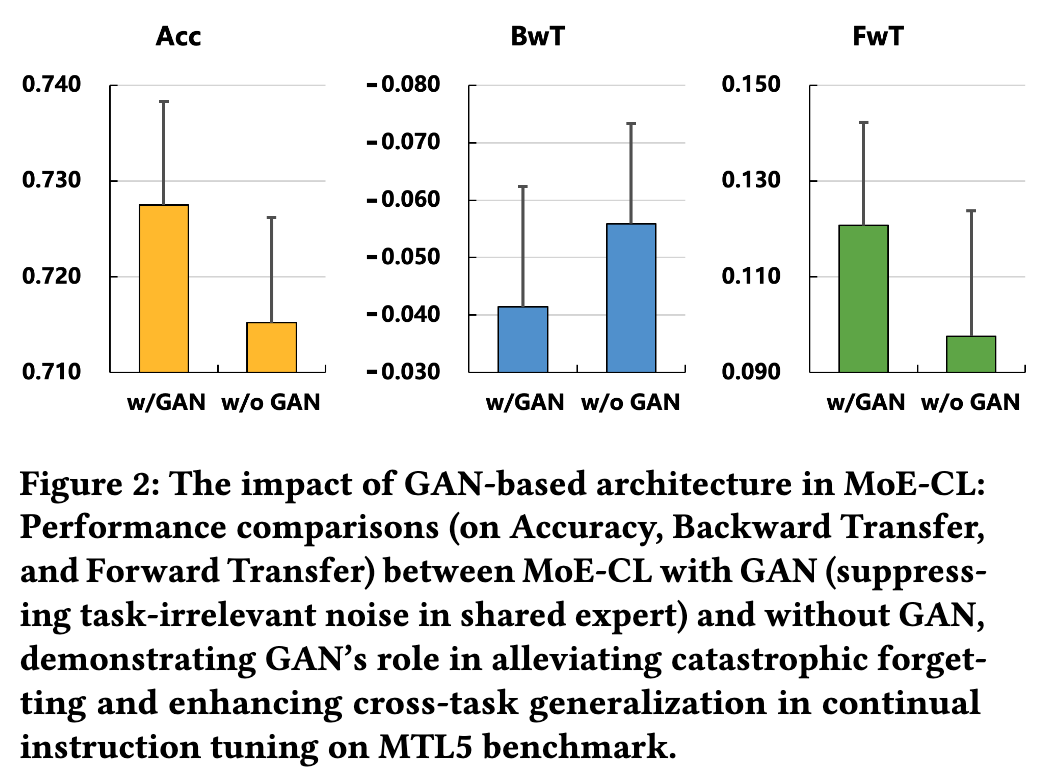
为了验证对抗训练模块(GAN)的实际作用,研究者进行了一项消融实验:将 MoE-CL 中的 GAN 组件移除(记为 w/o GAN),并与完整的 MoE-CL(记为 w/ GAN)进行比较。
结果如图所示,非常清晰:
-
在 Acc, BwT, FwT 所有三个指标上,w/ GAN 版本都显著优于 w/o GAN 版本。 -
尤其是在 BwT 指标上,w/ GAN 版本的遗忘程度更轻(负值更接近 0),在 FwT 指标上,w/ GAN 版本的知识迁移效果更好(正值更高)。
这个实验结果强有力地证明了 对抗训练机制并非锦上添花,而是 MoE-CL 成功的核心要素之一。它通过“过滤”共享知识,有效地抑制了任务间的负迁移,从而同时改善了知识的保持和迁移效率。
4.5 工业落地 A/B 测试
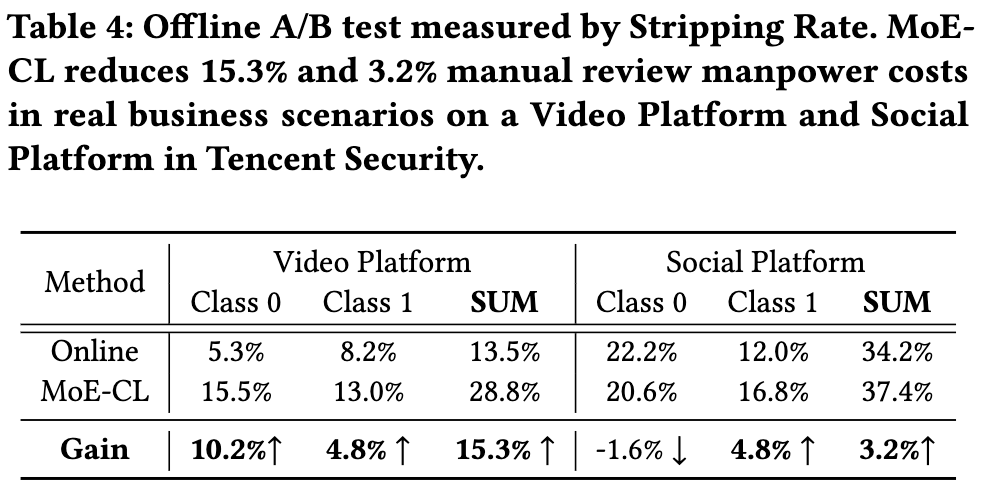
最终,模型的价值要在真实场景中得到体现。研究团队在腾讯的内容合规审核(CCR)业务中对 MoE-CL 进行了线下 A/B 测试。
-
业务背景与指标:在 CCR 业务中,一个关键的效率指标是 "Stripping Rate" (可直译为“剥离率”)。它指的是模型能够以高置信度自动处理(通过或拦截)、无需人工复审的样本比例。Stripping Rate 越高,意味着需要投入的人力审核成本越低。
-
测试结果:与线上正在使用的生产模型相比,MoE-CL 模型在视频平台场景下,将 Stripping Rate 提升了 15.3% 。这意味着,应用 MoE-CL 后,可以直接为该业务线 减少 15.3% 的人工审核成本。
这是一个具有说服力的业务成果。它清晰地展示了 MoE-CL 作为一个技术框架,如何将学术研究中的指标提升(如准确率),成功转化为可量化的商业价值,证明了其在工业规模部署中的可行性和有效性。
点评
我们可以将 MoE-CL 的核心贡献总结为以下三点:
-
创新的双专家 MoE 架构:它首次将专属专家(用于知识保持)和共享专家(用于知识迁移)的思想整合到参数高效的 LoRA 模块中,为解决持续学习的“稳定性-可塑性”困境提供了一个结构上优雅且有效的解决方案。
-
精巧的对抗训练机制:它独创性地引入了 GAN 对抗训练来“提纯”共享专家学到的知识,通过迫使共享表征变得“任务不可知”,来抑制负迁移,确保了跨任务知识迁移的高质量和高效率。
-
坚实的实验与落地验证:该工作不仅在公开和工业数据集上取得了优于现有方法的性能,更通过真实的线下 A/B 测试,证明了其能够带来显著的业务价值,完成了从理论到实践的关键闭环。
该研究以经验性验证为主,并取得了很好的效果。但MoE-CL的架构相较于传统的持续学习方法(如简单的序贯微调或正则化方法)更为复杂。它整合了MoE、LoRA和GAN,引入了更多的模块和超参数(例如对抗训练的损失权重α)。论文自身也承认其实现涉及“一些架构复杂性”。GAN的训练过程本身可能存在不稳定的问题,虽然论文结果表明其有效,但对于实践者而言,可能需要更多的调优技巧来复现和应用。
往期文章:


