对于大型语言模型(Large Language Models, LLMs)的研究而言,提升其推理能力,特别是模拟人类“系统2思维”(System 2 thinking)的深思熟虑过程,是一个核心且持续的目标。近年来,两条主流的技术路径在该领域取得了进展:一是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF),二是基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)。
RLHF 的优势与局限:RLHF 通过学习一个奖励模型(Reward Model, RM)来捕捉人类的偏好,并以此为指导信号对语言模型进行微调。这种方法在提升模型遵循指令、减少有害输出以及提高对话质量方面表现出色,已成为对齐(Alignment)语言模型的标准流程。然而,传统的 RLHF 流程通常将模型的输出视为一个整体进行优化,缺乏对生成内容之前的内部“思考”过程的显式建模和激励。模型为了获得更高的奖励分数,可能会学会生成更“讨喜”的答案,但其背后的推理过程可能是缺失或不连贯的,这限制了其在需要复杂规划和多步推理任务上的表现。
RLVR 的突破与瓶颈:与 RLHF 不同,RLVR 专注于那些具有明确、客观评价标准(即“可验证性”)的领域,如数学问题求解、代码生成和逻辑谜题。在这些任务中,奖励信号可以直接通过规则(例如,答案是否正确、代码单元测试是否通过)来确定,无需依赖于一个学习到的人类偏好模型。RLVR 鼓励模型生成详尽的思考链(Chain-of-Thought, CoT),即在给出最终答案前,先输出一步步的推理过程。通过对最终答案的正确性进行奖励,模型被激励去产出更可靠、更严谨的推理路径。这种方法在提升模型在数学和编程等领域的推理能力上取得了显著成效。然而,RLVR 的成功高度依赖于任务奖励的“可验证性”。对于绝大多数开放式、非结构化的日常任务,如撰写电子邮件、构思文章大纲或制定旅行计划,并不存在一个简单的、基于规则的验证器。人类在处理这些任务时同样会进行推理和规划,但这种推理的质量难以用客观标准衡量。因此,RLVR 获得的领域内推理能力,很难直接泛化到更广泛的通用聊天和创造性写作任务中。
这两个技术路径的特点共同揭示了一个研究上的挑战:我们能否将 RLVR 范式中“激励显式推理”的核心思想,扩展到 RLHF 所擅长的、缺乏客观验证标准的通用开放域任务中?如何设计一个既能鼓励模型进行深度思考,又能适用于广泛真实世界场景的训练框架?
陈丹琦团队在其发表的论文《Language Models that Think, Chat Better》中,对这一问题提出了一个创新的解决方案。他们引入了一种名为“基于模型奖励思考的强化学习”(Reinforcement Learning with Model-rewarded Thinking, RLMT)的新范式。RLMT 的核心思想是,将 RLVR 中生成长思考链(long CoT reasoning)的结构,与 RLHF 中使用通用偏好奖励模型的框架相结合。它要求语言模型在生成最终回复之前,先产出一段详细的内部思考过程,然后使用一个在通用人类偏偏好数据上训练的奖励模型来评估最终回复的质量,并通过在线强化学习算法对整个“思考-回答”过程进行优化。这种设计巧妙地绕开了开放域任务缺乏客观验证器的难题,同时又显式地将“思考”作为训练过程中的一个核心环节。

-
论文标题:Language Models that Think, Chat Better -
论文链接:https://arxiv.org/pdf/2509.20357
RLMT:融合 RLVR 与 RLHF 的新范式
为了理解 RLMT 的设计哲学,我们首先需要回顾其所基于的两个核心训练范式:RLHF 和 RLVR。
背景:RLHF 与 RLVR
1. RL from Human Feedback (RLHF)
RLHF 的目标是使语言模型的输出与人类的偏好对齐。其数学形式可以概括为:
给定一个语言模型策略 (由参数 定义),以及一个提示 ,模型生成一个回复 。存在一个奖励函数 ,它为给定的提示-回复对打分。在实践中,这个奖励函数 通常是一个在人类偏好数据集上训练出来的奖励模型(RM),更高的分数代表更符合人类的偏机。RLHF 的优化目标是最大化模型生成回复的期望奖励:
这个过程通过强化学习算法(如 PPO)来完成,模型在与奖励模型的交互中不断调整其策略 ,以生成更高奖励的输出。
2. RL with Verifiable Rewards (RLVR)
RLVR 是为那些可以进行程序化验证的领域设计的。它对 RLHF 框架进行了两个关键的修改:
首先,它用一个确定性的验证函数(verification function)替代了学习到的奖励模型 。例如,在数学问题中,这个函数可以是检查模型答案 是否等于标准答案 的指示函数 。
其次,RLVR 明确地将模型的生成过程分为两步:先生成一个推理轨迹(reasoning trace),然后再基于提示 和推理 生成最终答案 。这种设计直接激励模型产出有助于得到正确答案的中间思考过程。其优化目标是最大化最终答案的期望正确率:
RLVR 在形式化领域取得了成功,但其应用范围受限于“可验证性”这一先决条件。
RLMT 的核心机制
RLMT 旨在结合 RLHF 的通用性和 RLVR 对推理过程的显式激励。它继承了 RLVR 的两步生成结构(先思考 ,后回答 ),但采用了 RLHF 的奖励机制(使用通用的奖励模型 )。RLMT 的优化目标如下:
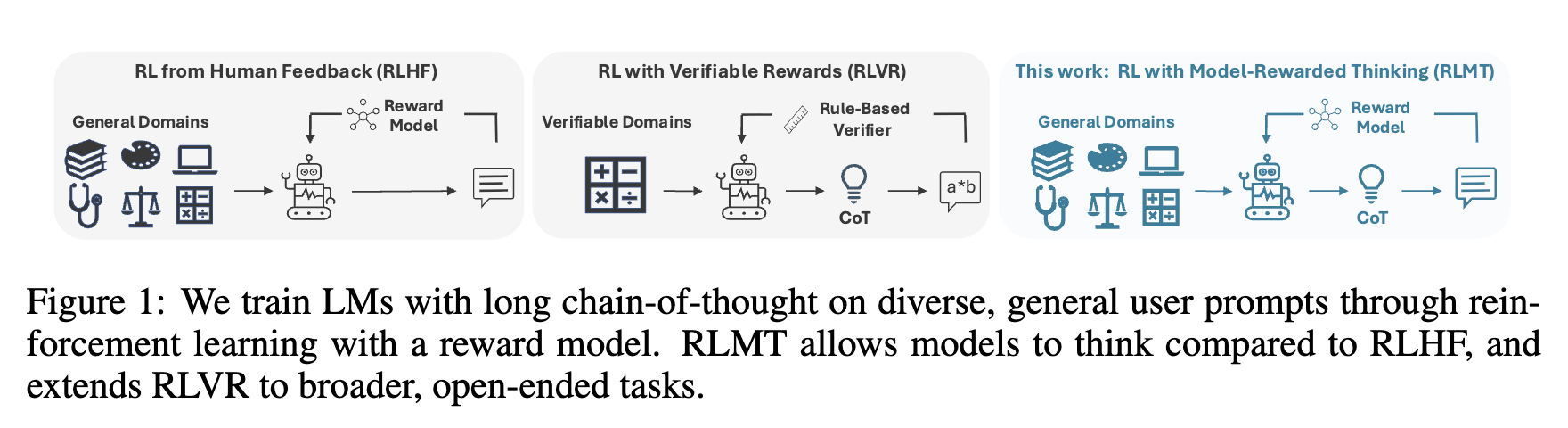
图 1 展示了三种范式的区别。RLHF 直接从提示生成回复,并用奖励模型评估。RLVR 从提示生成思考链和回复,并用基于规则的验证器评估。RLMT 同样生成思考链和回复,但使用通用的奖励模型进行评估,从而将其适用范围从可验证领域扩展到了通用开放域。
与 RLHF 相比,RLMT 的关键区别在于强制模型生成推理轨迹 。与 RLVR 相比,其关键区别在于使用了一个通用的、基于人类偏好学习的奖励模型 来评估最终的回复 ,而不是依赖于基于规则的验证器。这一设计使得 RLMT 能够处理那些没有唯一正确答案的开放式任务。例如,在一个“为安迪·杜佛兰写一本哲学书”的开放式查询中,RLMT 模型会首先生成一段 <think> 标签内的思考过程,规划如何构建安迪的哲学思想、核心主题以及引言结构,然后再生成最终的书名和哲学概述。

图 2 展示了模型在回答关于《肖申克的救赎》主角安迪·杜佛兰哲学思想的问题时,生成的详细思考过程。思考过程包括回顾角色故事、提炼哲学主题、设计回应结构等步骤,这些都在最终回答生成之前完成。
RLMT 的关键设计选择
论文的作者们对 RLMT 框架中的几个关键设计选择进行了系统的实验和分析:
-
训练算法 (Training algorithm) :研究者们测试了多种强化学习和在线偏好学习算法,包括直接偏好优化(Direct Preference Optimization, DPO)、近端策略优化(Proximal Policy Optimization, PPO)以及组相对策略优化(Group Relative Policy Optimization, GRPO)。实验发现,GRPO 整体表现最好,但 DPO 和 PPO 在 RLMT 框架下也同样有效,且优于其对应的 RLHF 基线。
-
奖励模型 (Reward model) :一个强大且可靠的奖励模型对 RLMT 的成功至关重要。研究中主要采用了 Skywork-v1-Llama-3.1-8B-v0.2 作为一个强大的奖励模型,它在多个奖励模型基准测试中表现出色。消融实验也证实,使用更强的奖励模型能带来更好的性能。
-
提示混合 (Prompt mixture) :用于 RL 阶段的提示分布对模型最终的聊天能力有直接影响。研究者们发现,使用来自真实世界用户查询的、更具对话性的提示(如 WildChat-IF 数据集子集)比使用含有大量数学和越狱提示的混合数据集或相对简单的 UltraChat 数据集,能获得更好的通用聊天性能。这表明,RL 阶段的训练数据应该与目标应用场景(即通用聊天)紧密匹配。
-
“热启动”SFT 与 “零”训练 ("Warm-Start" SFT and "Zero" Training) :由于基础模型(Base Models)本身不会自然地生成“思考-回答”格式的输出,研究者们探索了两种方式来引导模型学习这种行为:
-
热启动 SFT (Warm-start thinking with SFT) :在 RL 训练之前,先进行一步监督微调(Supervised Fine-Tuning, SFT)。SFT 的数据由一个强大的教师模型(如 Gemini 2.5 Flash)生成,这些数据包含了模拟的思考过程和最终的回复。这个阶段相当于“教会”模型如何进行结构化的思考。 -
零训练 (Zero training with base models) :直接跳过 SFT 阶段,对基础模型应用 RLMT。通过在提示中加入固定的指令前缀,引导模型在初始阶段生成所需的“思考-回答”结构。这种方法的灵感来源于 R1-Zero 等工作,旨在探索 RL 是否能从零开始塑造模型的行为。
-
实验结果表明,两种方法都是有效的。热启动 SFT 为 RL 提供了一个更好的起点,通常能达到更高的最终性能。但令人注意的是,“零”训练方法也能取得显著的性能提升,甚至在某些情况下超过了经过复杂多阶段后训练流程的标准指令微调模型。
实验设置
为了全面评估 RLMT 的有效性,研究者们进行了一系列严谨的实验。
模型与基准
-
基础模型:实验选用了两个有代表性的模型系列:Llama-3.1-8B 和 Qwen-2.5-7B,并同时在它们的基础版(Base)和指令微调版(Instruct)上进行了实验。 -
评估基准:评估涵盖了四大类共七个基准测试,力求全面地衡量模型的各项能力: -
聊天 (Chat) :AlpacaEval 2 (AE2), WildBench (WB), ArenaHardV2 (AH2)。这三个是衡量模型通用对话能力的核心基准。 -
创造性写作 (Creative writing) :CreativeWritingV3 (CWv3)。 -
指令遵循 (Instruction following) :IFBench (IFBen)。 -
通用知识 (General knowledge) :MMLU-Redux (MMLUR), PopQA。
-
-
基线模型:为了严格隔离“思考”过程的有效性,研究者为每一个 RLMT 模型都训练了一个对应的 RLHF 基线模型。这个基线模型使用完全相同的训练设置(相同的提示、奖励模型、RL算法),唯一的区别是它不生成思考链(即标准的 RLHF 流程)。这种成对比较能够清晰地揭示引入 CoT 推理所带来的性能增益。
训练设置
实验主要在两种设置下进行:
-
热启动设置 (SFT Warm-Started Models) :模型首先经过一个 SFT 阶段,学习生成思考-回答的格式,然后再进行 RLMT 或 RLHF 训练。 -
零训练设置 (Zero Training) :直接在基础模型上进行 RLMT 或 RLHF 训练,不经过 SFT 阶段。
研究者们系统地报告了 DPO, PPO, 和 GRPO 三种算法在不同模型和设置下的结果,以确保结论的普适性。
核心实验结果与分析
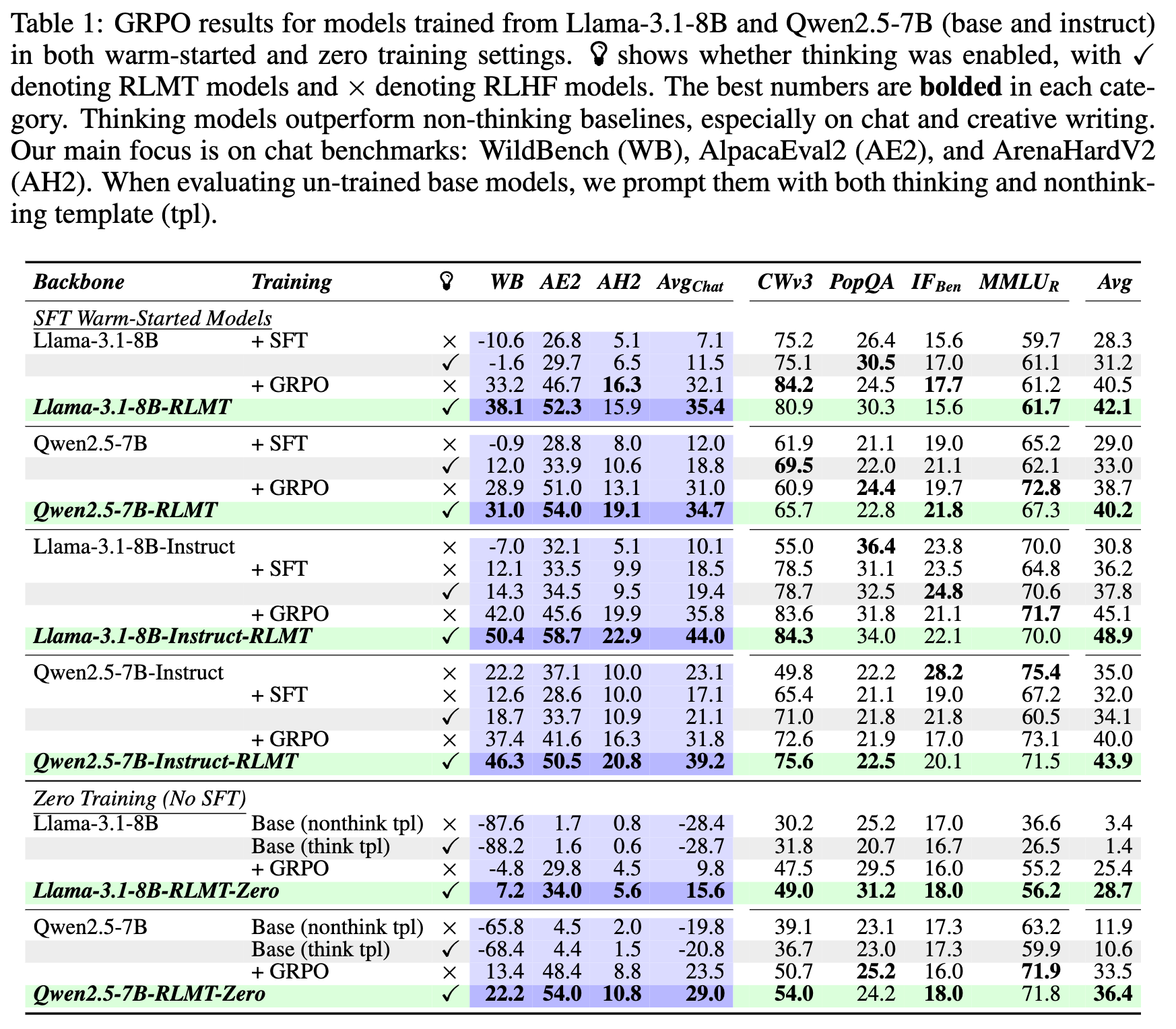
表 1 详细列出了 Llama-3.1-8B 和 Qwen2.5-7B(包括 base 和 instruct 版本)在经过不同训练阶段(仅 SFT、SFT+GRPO)后的性能表现。表格通过对比有思考(✓,RLMT)和无思考(×,RLHF)的模型的得分,清晰地展示了 RLMT 在多个基准测试,特别是聊天基准上的优势。
1. 思考模型在聊天和创造性写作方面表现出色
从表1可以看出一个一致的趋势:无论是在 Llama-3.1-8B 还是 Qwen2.5-7B 上,也无论是基础模型还是指令微调模型,引入思考过程的 RLMT 模型(标记为 ✓)在性能上都系统性地优于其对应的无思考 RLHF 基线(标记为 ×)。
-
在聊天基准上的巨大优势:这种优势在聊天基准(WildBench, AlpacaEval2)上尤为明显。RLMT 模型通常比 RLHF 基线高出 3-8 个百分点。例如,在 Llama-3.1-8B-Instruct 模型上,经过 GRPO 训练后,RLMT 模型的平均聊天分数(Avg Chat)达到了 44.0,而 RLHF 基线模型为 35.8,提升了超过8个点。 -
对其他能力的增益:除了聊天,RLMT 模型在创造性写作(CWv3)和通用知识(如 PopQA)等任务上也展现出了一致的性能提升。这表明,通过 RLMT 培养的“思考”能力具有一定的泛化性。
为了进一步展示其性能,研究者将他们最好的模型 Llama-3.1-8B-Instruct-RLMT 与更强大的开源和闭源模型进行了比较。
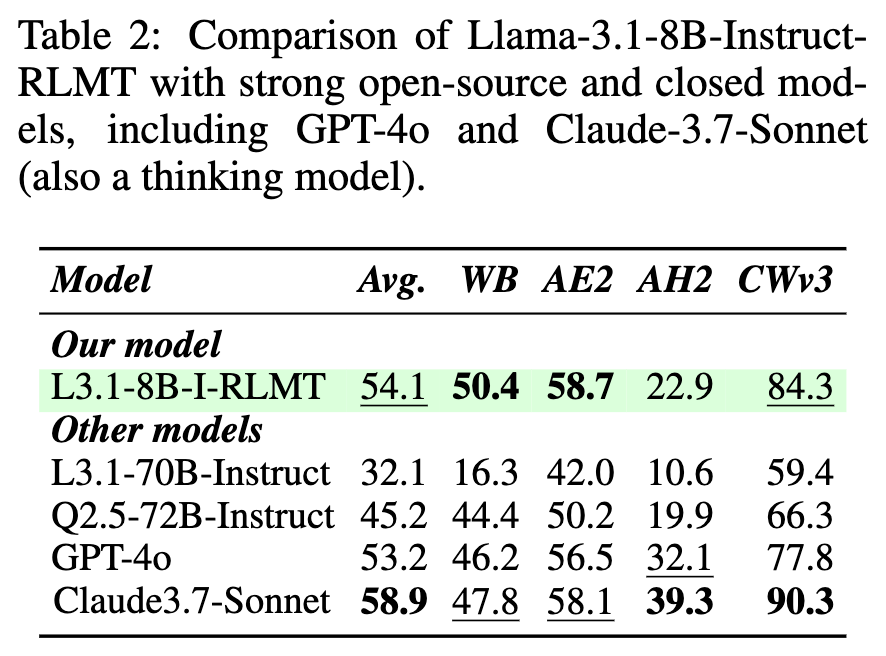
表 2 将作者训练的最佳 8B 模型与 10倍大的 Llama-3.1-70B-Instruct、Qwen2.5-72B-Instruct,以及闭源前沿模型 GPT-4o 和 Claude-3.7-Sonnet 进行了比较。
结果显示,尽管 Llama-3.1-8B-Instruct-RLMT 的模型体积远小于 70B 级别的开源模型,但其在所有基准上的平均分(54.1)都大幅超过了 Llama-3.1-70B-Instruct(32.1)和 Qwen2.5-72B-Instruct(45.2)。更值得注意的是,这个 8B 模型在聊天(WB, AE2)和创造性写作(CWv3)任务上甚至超过了 GPT-4o。它在 AlpacaEval2 和 Wildbench 上的表现也超过了以思考能力著称的 Claude-3.7-Sonnet,尽管在包含更多数学和代码问题的 ArenaHardV2 上有所不及。这些结果有力地证明了 RLMT 范式在提升中小规模模型聊天能力方面的效率和潜力。
2. 不同 RL 算法的性能比较
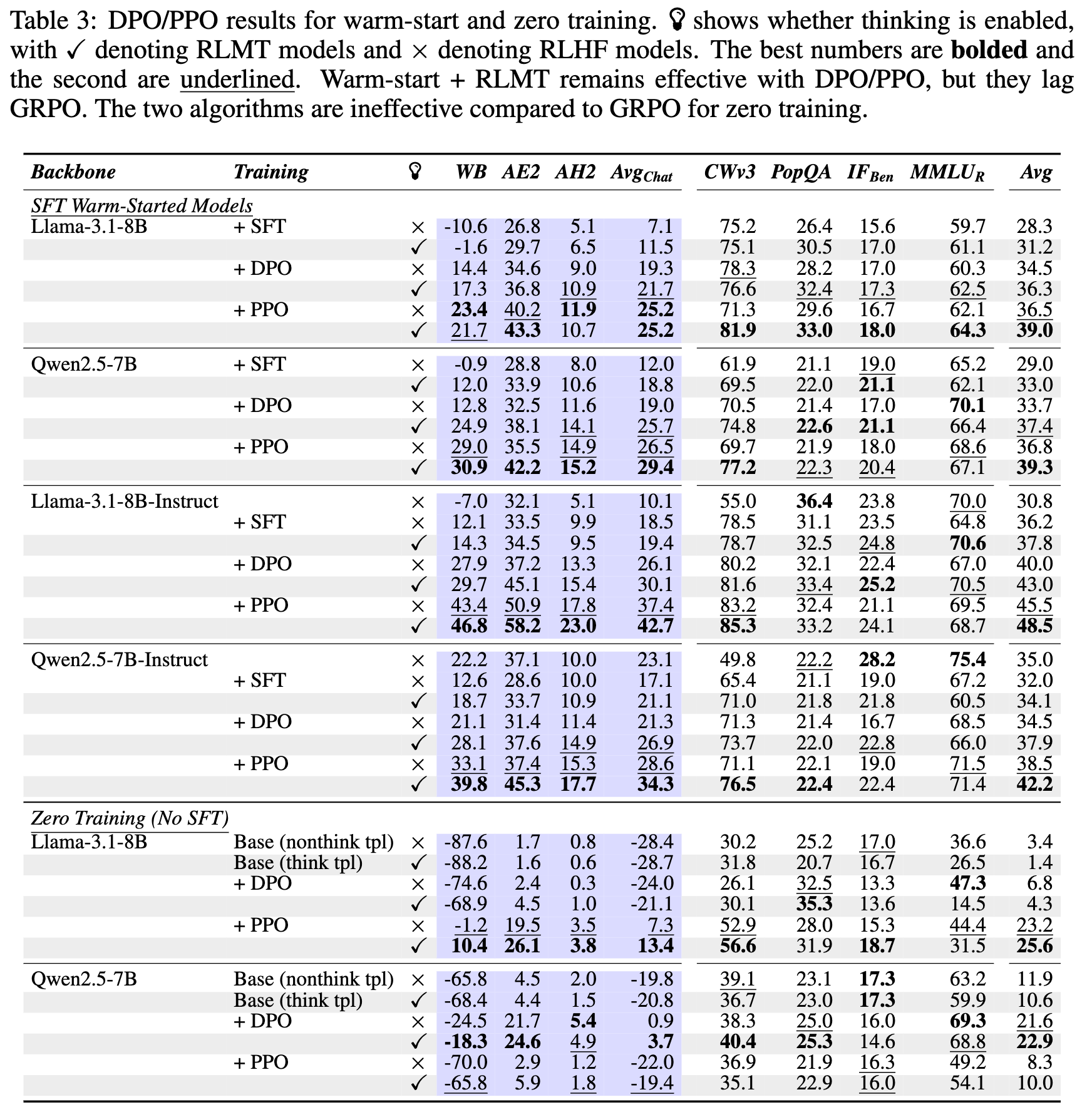
此表补充了表1的数据,展示了使用 DPO 和 PPO 算法时的性能。
通过对比表1和表3,可以得出以下结论:
-
GRPO 表现最佳:在所有测试场景中,GRPO 通常能带来最佳的性能,比 PPO 高出约 1-3 个点,比 DPO 高出约 5 个点。这表明在线的、基于组优势计算的 RL 算法可能更适合优化这种带有长思考链的生成策略。 -
RLMT 在所有算法下均有效:尽管 GRPO 效果最好,但即使在使用 DPO 和 PPO 时,RLMT 模型仍然稳定地优于其对应的 RLHF 基线。这说明 RLMT 范式的有效性并不依赖于某一种特定的优化算法,具有较好的普适性。
3. RLMT 无需 SFT 也能有效引导聊天能力
在零训练设置中,RLMT 直接应用于基础模型。从表1和表3的 "Zero Training" 部分可以看出:
-
基础模型初始性能差:未经任何后训练(post-training)的基础模型在聊天基准上表现很差,得分通常是负数。 -
DPO/PPO 效果有限:在零训练设置下,使用 DPO 或 PPO 对基础模型进行微调,带来的性能提升有限。 -
GRPO 带来巨大提升:然而,当使用 GRPO 进行 RLMT 训练时,模型性能出现了大幅提升。例如,Llama-3.1-8B-RLMT-Zero 模型的平均聊天分数从-28.7提升到了15.6。Qwen-2.5-7B-RLMT-Zero 的平均聊天分数更是达到了29.0,这个分数已经超过了经过复杂流程微调的 Qwen-2.5-7B-Instruct 模型的聊天性能。
这些结果表明,即使没有 SFT 阶段来预先“教授”思考模式,强大的在线 RL 算法(如 GRPO)也能够从零开始,在基础模型中塑造出有效的对话和推理能力,这为简化 LLM 的后训练流程提供了新的可能性。
4. RLMT 模型优于仅在数学数据上训练的思考模型
一个自然的问题是,RLMT 培养的通用聊天“思考”能力,与 RLVR 在数学等可验证领域培养的“思考”能力有何不同?
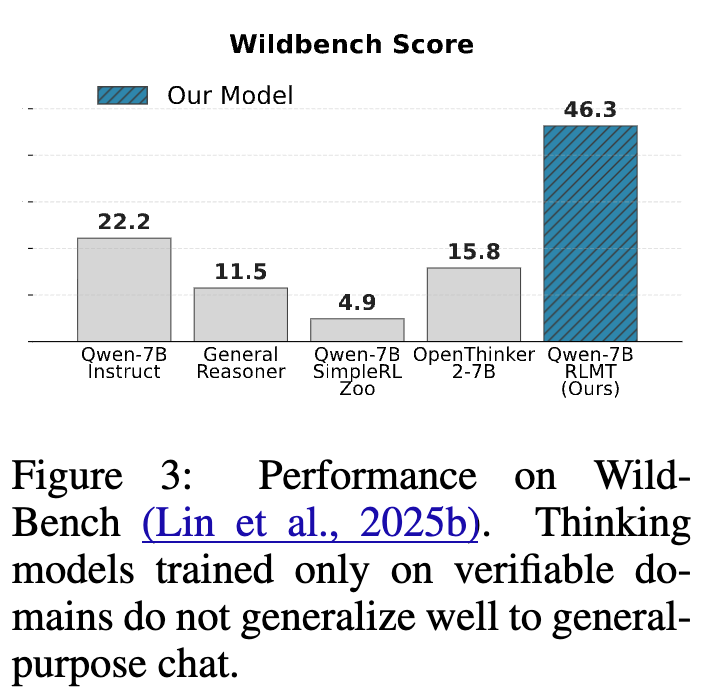
图 3 比较了作者的 RLMT 模型与多个在数学领域通过 RLVR 训练的“思考”模型(如 General Reasoner, OpenThinker)在通用聊天基准 WildBench 上的得分。
结果清晰地显示,专门为数学等可验证领域训练的思考模型,其推理能力并不能很好地泛化到通用聊天任务中。RLMT 模型在 WildBench 上的得分比这些数学思考模型高出 10-25 个点。这印证了论文开头的假设:为通用聊天任务注入推理能力,需要使用与之匹配的、更广泛的提示和奖励信号,而不能仅仅依赖于在狭窄、形式化领域获得的技能。
消融实验与深入分析
为了更深入地理解是什么因素使得 RLMT 如此有效,以及 RL 训练过程如何改变了模型的行为,研究者们进行了一系列的消融实验和定性分析。
1. 关键组件的影响
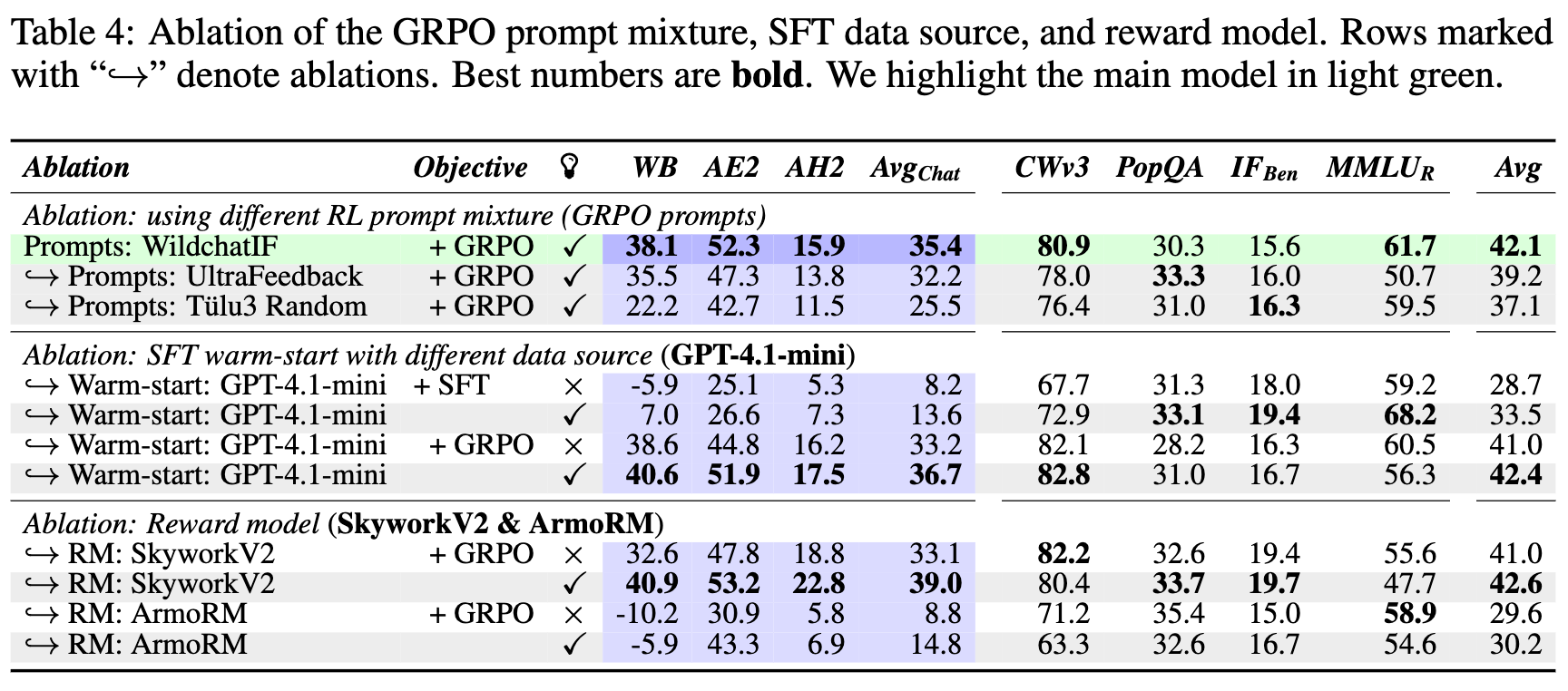
此表格通过控制变量法,分别测试了不同 RL 提示、不同 SFT 教师模型(Gemini vs GPT-4.1-mini)以及不同奖励模型(Skywork-V1, Skywork-V2, ArmoRM)对最终性能的影响。
实验揭示了几个关键点:
-
RL 提示混合的重要性:使用更接近真实聊天场景的 Wildchat-IF 提示,比使用更简单的 UltraFeedback 提示或包含大量非聊天任务的 Tülu3 随机提示,能获得更好的性能。这再次强调了 RL 阶段数据分布与目标任务对齐的重要性。 -
SFT 数据源的稳健性:将生成 SFT 数据的教师模型从 Gemini 2.5 Flash 更换为 GPT-4.1-mini,最终模型的性能没有出现显著下降。这表明 RLMT 的成功并非偶然依赖于某个特定的教师模型,只要 SFT 阶段能教会模型基本的思考格式即可。 -
奖励模型的关键作用:奖励模型是 RLMT 的核心驱动力。实验发现,使用更强的奖励模型(SkyworkV2)可以进一步提升性能,而使用较弱的奖励模型(ArmoRM)则会导致性能下降。一个有趣的发现是,无论使用哪个奖励模型,RLMT(有思考)都比 RLHF(无思考)在聊天基准上表现更好。这表明,“思考”这一结构性优势与奖励模型的强度是两个相对独立的、可以叠加的增益来源。
2. RL 训练如何改变模型的行为?
RLMT 训练不仅提升了分数,更重要的是,它改变了模型进行任务规划和推理的“心智模式”。研究者们通过一个巧妙的定性分析流程来揭示这种变化。他们比较了同一个模型在 RLMT 训练前(仅经过 SFT)和训练后(SFT + RLMT)所生成的思考过程,并使用 GPT-4.1-mini 来自动提取和比较两种状态下思考过程的特征差异。

图 4 左侧展示了一个条形图,对比了 RLMT 训练后的模型(GRPO)与训练前的模型(SFT)在多种推理特质上的“头对头”胜率。绿色条表示 GRPO 模型更常表现出的特质,红色条表示 SFT 模型更常表现出的特质。右侧则给出了一个具体的例子,展示了 GRPO 模型在规划一个推特帖子时的思考过程,其中高亮了它所展现出的高级推理特质。
分析结果揭示了一个从“刻板”到“灵活”的转变:
-
训练前的 SFT 模型:其思考过程更像一个线性的、自上而下的清单。它倾向于先设定好严格的层级结构(章节、小节),然后按部就班地填充内容。这种方式虽然结构化,但显得僵化,缺乏对任务约束和内在逻辑的深入理解。图中红色条代表的“以清单开始”、“僵化的分步结构”等特质就反映了这一点。 -
训练后的 RLMT 模型:其思考过程变得更加迭代和动态。它首先会识别和列出任务的所有约束和子主题,然后将相关的想法组织成主题簇,并思考不同部分之间的内在联系。在规划过程中,它会权衡利弊,甚至会回溯修改之前的计划。这种行为更接近人类专家在处理复杂问题时的思维方式:不是一次性规划到底,而是在一个灵活的框架内不断探索、组合和优化。图中绿色条代表的“将想法分组”、“整合约束”、“权衡取舍”等高级推理特质,在 RLMT 训练后被显著增强。
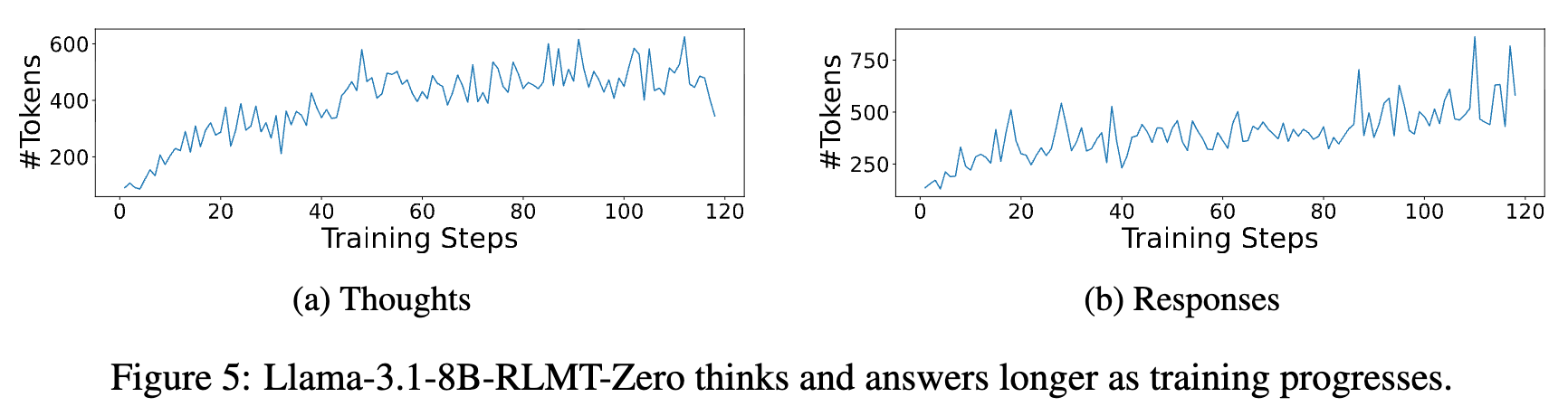
图 5 展示了在零训练设置下,随着 RL 训练的进行,模型生成的思考过程((a) Thoughts)和最终回复((b) Responses)的平均长度(#Tokens)都在稳步增加。
这一发现与 DeepSeek-R1-zero 的观察相呼应,表明模型在强化学习的过程中,不仅学会了如何更好地回答问题,也学会了进行更长时间、更深入的思考。
相关工作与讨论
这项工作处在语言模型训练的几个重要研究方向的交汇点。
-
语言模型的训练阶段:传统的 LLM 训练通常遵循“预训练 -> SFT -> RLHF”的三阶段流程。RLMT 为这个流程提供了新的视角。一方面,它可以作为 RLHF 的一个直接替代品,通过引入显式思考来增强模型的对齐效果。另一方面,零训练的成功表明,一个设计良好的 RL 阶段甚至有可能整合或替代 SFT 的部分功能,直接从基础模型中引导出复杂的、符合指令的行为。
-
RLHF 的演进:大多数 RLHF 的研究将模型输出视为一个整体。近期有一些工作开始探索将 CoT 推理与偏好优化相结合。但这些方法通常依赖于离线算法,并且是在已经经过指令微调的模型上进行。RLMT 的不同之处在于它直接将在线 RL 算法与长 CoT 推理相结合,并且证明了这种方法可以直接应用于基础模型。
-
RLVR 的扩展:RLVR 在可验证领域取得了巨大成功,但其泛化能力一直是个问题。近期有研究尝试通过设计替代性的奖励信号(如基于 BLUE 分数的奖励、基于语言模型生成规则的奖励)来将 RLVR 扩展到通用领域。本文的发现表明,使用一个在广泛人类偏好数据上训练的强大奖励模型,是为通用领域在线 RL 训练提供有效和鲁棒信号的一种更直接、可能也更有效的方法。
结论与展望
本文介绍的 RLMT 范式,通过将 RLVR 的长思考链结构与 RLHF 的通用奖励模型相结合,为提升语言模型在开放域任务中的推理和对话能力提供了一个简洁而有效的框架。
主要贡献:
-
提出了 RLMT 范式:一个能够将显式推理能力扩展到通用聊天任务的新颖训练方法。 -
全面的实验验证:在两个主流模型系列、多种 RL 算法和多个基准测试上,系统地证明了 RLMT 相较于标准 RLHF 的优越性。其训练出的 8B 模型在聊天能力上可以媲美甚至超越远大于其规模的模型。 -
揭示了零训练的潜力:证明了即使没有 SFT 的预先指导,RLMT 也能在基础模型上有效引导出复杂的对话能力,为简化训练流程提供了新思路。 -
深入的机理分析:通过定性分析,揭示了 RL 训练如何将模型的思考模式从机械的清单式规划,转变为更灵活、更深入的动态推理过程。
局限性与未来工作:
作者也坦诚地指出了当前工作的局限性以及未来的研究方向。
-
能力来源的剖析:目前尚不完全清楚性能的提升在多大程度上来源于对模型已有能力的“放大”,又在多大程度上是 SFT 或 RL 阶段“学习”到的新能力。对这一问题的深入研究,将有助于设计更高效的训练流程。 -
超参数与格式优化:本文旨在探索一个简洁方法的可行性,因此没有对内部 CoT 的格式、训练超参数或提示混合的构建进行深度优化。未来在这些方面的探索,有可能进一步释放 RLMT 的潜力。
总而言之,这项工作表明,通过在训练中显式地激励一个结构化的思考过程,并结合一个强大的通用奖励信号,我们可以用较低的成本显著提升模型在复杂开放域任务中的表现。
往期文章:


