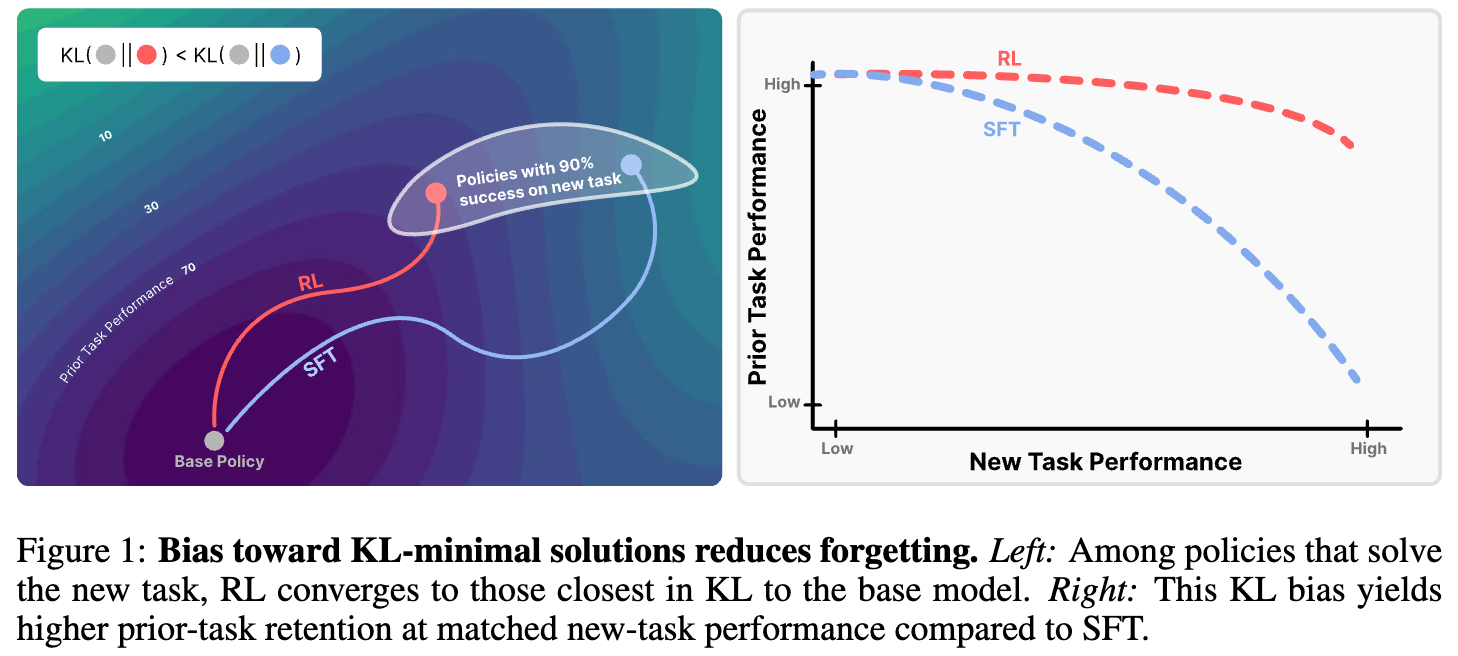
在RAG应用中,LLM的上下文主要由检索到的段落拼接而成,其中只有一小部分与用户的查询直接相关。由于在重排阶段的多样性或去重操作,这些段落间的语义相似性不高,导致了块对角(Block-Diagonal)的注意力模式,这与标准LLM生成任务中的注意力模式有所不同。基于这一观察,研究者认为在RAG上下文上的大多数解码计算是不必要的,可以在对性能影响很小的情况下被消除。
为此,来自Meta Superintelligence Labs、新加坡国立大学和莱斯大学的研究人员共同提出了一种名为REFRAG(REpresentation For RAG) 的高效解码框架,旨在通过压缩(Compresses)、感知(Senses)和扩展(Expands)来改善RAG应用中的延迟问题。通过利用这种注意力稀疏结构,REFRAG在不损失困惑度(Perplexity)的情况下,实现了高达30.85倍的首个token生成时间(Time-to-First-Token, TTFT)加速,相较于之前的工作有3.75倍的提升。此外,该框架的优化设计使得LLMs的上下文窗口大小能够扩展16倍。经过在包括RAG、多轮对话和长文档摘要在内的多种长上下文任务和数据集上的严格验证,实验结果表明,与LLAMA模型及其他基线相比,REFRAG在各种上下文大小下均能提供显著的速度提升,且不影响准确性。

-
论文标题:REFRAG: Rethinking RAG based Decoding -
论文链接:https://arxiv.org/pdf/2509.01092
REFRAG是什么?
REFRAG提出了一种新颖的机制,用于高效解码RAG中的上下文。该框架在不修改LLM架构或引入新解码器参数的前提下,显著降低了延迟、TTFT和内存使用。
其核心创新点可以概括为以下几个方面:
-
基于预计算块嵌入(Chunk Embeddings)的解码:
传统的RAG系统将检索到的原始文本 token 直接作为输入。与之不同,REFRAG利用预先计算好的、经过压缩的块嵌入作为上下文的近似表示,并将这些嵌入直接送入解码器。 -
带来的三大优势:
-
缩短解码器输入长度:通过使用块嵌入代替原始 token ,有效缩短了输入序列的长度,提升了 token 分配效率。 -
复用检索阶段的计算:使得在检索阶段生成的块嵌入可以被重复使用,避免了冗余的编码计算。 -
降低注意力计算复杂度:注意力机制的计算复杂度从与 token 数量的二次方关系转变为与块(Chunk)数量的二次方关系,从而大幅降低了计算开销。
-
-
“随处压缩”(Compress Anywhere)能力:
与以往的方法不同,REFRAG支持在任意位置对 token 块进行压缩,同时保持了解码器的自回归(Autoregressive)特性。这一能力使其能够很好地支持多轮对话和智能体这类需要动态交互的应用。 -
轻量级强化学习策略:
为了进一步提升性能,REFRAG引入了一个轻量级的强化学习(RL)策略。该策略能够选择性地判断何时需要使用完整的、未经压缩的 token 块输入,以及何时使用低成本的近似块嵌入就足够了。这样一来,REFRAG最小化了对计算密集型 token 嵌入的依赖,在RAG场景下将大部分上下文块都进行了压缩。
模型架构
REFRAG的模型架构由一个解码器模型 (例如,LLaMA)和一个编码器模型 (例如,RoBERTa)组成。给定一个总共包含 个 token 的输入 ,假设前 个是主要输入 token (如问题),后 个是上下文 token (如RAG检索到的段落),满足 。
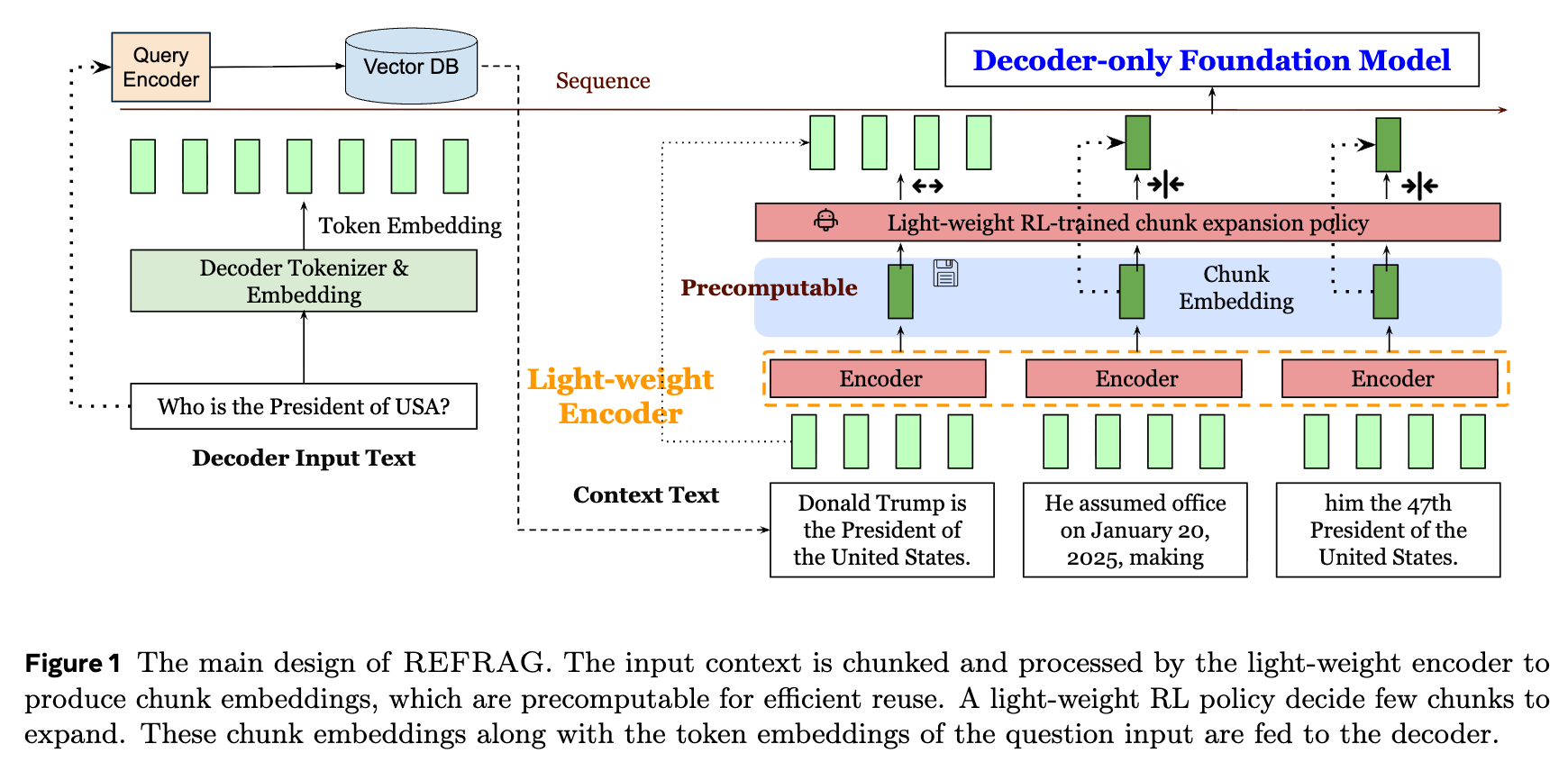
如上图所示,REFRAG的整体设计如下:
-
上下文分块与编码:
对于一个给定的问题 和上下文 ,上下文首先被分割成 个大小为 的块(Chunks),记为 ,其中 。 -
生成块嵌入:
轻量级的编码器模型 并行处理所有这些块,为每个块 生成一个块嵌入 。这些块嵌入是预先计算好的,可以被高效复用。 -
投影与输入解码器:
接着,一个投影层 将这些块嵌入 投影到与解码器模型词元嵌入相匹配的维度,得到 。 -
生成答案:
最后,这些投影后的块嵌入与问题的词元嵌入 一同被送入解码器模型,以生成最终的答案 。
在实际的RAG应用中,上下文部分通常远大于问题部分(即 ),因此通过这种方式,输入到解码器的总长度被缩减了大约 倍。这种架构设计显著减少了延迟和内存使用。
系统性能提升:延迟与吞吐量
REFRAG评估了三个关键指标:
-
TTFT (Time-To-First-Token) :生成第一个 token 的延迟。 -
TTIT (Time-To-Iterative-Token) :生成后续每个 token 所需的时间。 -
吞吐量 (Throughput) :单位时间内生成的 token 数量。
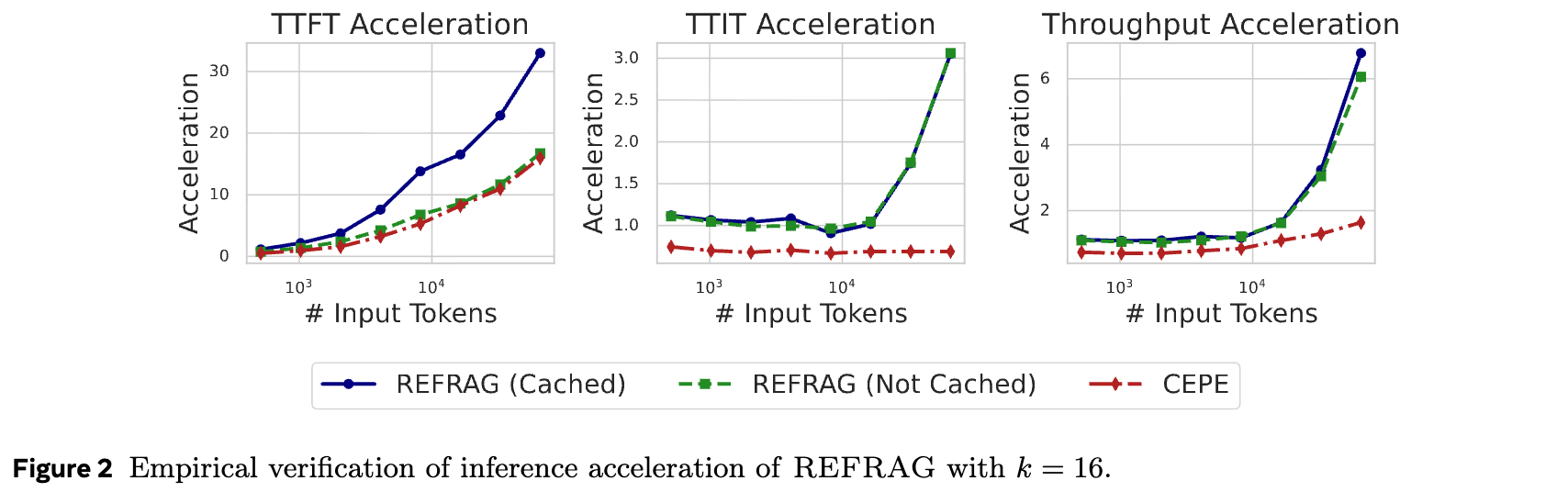
理论分析表明,对于短上下文,该方法能在TTFT和吞吐量上实现高达 倍的加速。对于长上下文,加速效果可以达到 倍。
实证结果也验证了这一点。如上图所示,在一个长度为16384的中长上下文场景下,当压缩率 时:
-
TTFT加速:REFRAG(带缓存)实现了16.53倍的TTFT加速,而无缓存版本也达到了8.59倍。这均优于之前的SOTA模型CEPE(分别为2.01倍和1.04倍)。 -
吞吐量加速:相较于LLaMA,REFRAG实现了高达6.78倍的吞吐量加速,同样显著优于CEPE。 -
性能保持:在实现加速的同时,其模型性能(以困惑度衡量)相比CEPE提升了9.3%。
当压缩率 时,TTFT加速更是达到了32.99倍(相较于LLaMA),是CEPE的3.75倍,同时保持了与CEPE相当的性能水平。
方法
为了使编码器和解码器能够协同工作,REFRAG采用了一套精心设计的训练方法。
3.1 持续预训练方案(Continual Pre-training Recipe)
为了确保CPT(Continual Pre-training)阶段的成功,REFRAG提出了一套包含重建任务(Reconstruction task)和课程学习(Curriculum learning)的训练方案。消融实验表明,这套方案对于达到强大的CPT性能至关重要。
-
重建任务:
此任务的目标是让编码器学会在信息损失最小的情况下压缩 个 token ,同时让投影层能有效地将编码器的块嵌入映射到解码器的 token 空间中。具体做法是,将前 个 token 输入编码器,然后让解码器学会重建这 个 token 。在此阶段,解码器模型被冻结,只训练编码器和投影层。这个任务旨在鼓励模型依赖上下文记忆而非参数化记忆。 -
课程学习:
直接让模型学习从多个块嵌入中重建长序列是复杂的。因为随着块长度 的增加,可能的 token 组合数量呈指数级增长(,其中 是词汇表大小)。为了解决这个优化难题,REFRAG采用了课程学习,即从易到难逐步增加任务难度。-
重建任务的课程学习:训练从重建单个块开始,然后逐步增加需要重建的块的数量。 -
数据混合:随着时间的推移,训练数据中的任务难度会动态调整,从以简单任务(如单个块嵌入)为主逐渐过渡到以更难的任务(如 个块嵌入)为主。
-
3.2 选择性压缩(Selective Compression)
REFRAG通过引入选择性 token 压缩来进一步提升性能。其核心思想是,对于上下文中重要的块,不进行压缩以保留其原始信息,从而改善答案的预测质量。
一个强化学习(RL)策略被用来决定哪些块应该保持原始形式。该策略以“下一段预测的困惑度”作为负向奖励信号进行引导。编码器和解码器经过微调,可以处理压缩和未压缩块的混合输入。这个策略网络利用块嵌入和掩码来优化块的序列化扩展决策,从而保留了解码器的自回归特性,并允许在任意位置进行灵活的压缩。
实验结果
4.1 训练与评估数据集
-
训练数据:使用了Slimpajama数据集中的Book和ArXiv两个领域的数据,构建了一个20B token 的训练集。选择这两个领域是因为它们包含长文本。 -
评估数据:在Slimpajama的Book和ArXiv保留集,以及PG19和Proof-pile数据集上进行了评估,以检验模型的泛化能力。
4.2 基线模型
所有基线模型都基于LLaMA-2-7B,以确保公平比较。主要基线包括:
-
LLaMA-No Context: 无上下文的LLaMA模型。 -
LLaMA-Full Context: 使用完整上下文的LLaMA模型,作为性能上限参考。 -
CEPE: 先前的一个内存高效的长上下文模型。 -
LLaMA-32K: 为32K上下文长度微调的LLaMA-2-7B。 -
REPLUG: 一个检索增强的LLaMA-2-7B模型。 -
REFRAG: 本文提出的方法,REFRAG表示压缩率为 。
4.3 性能比较
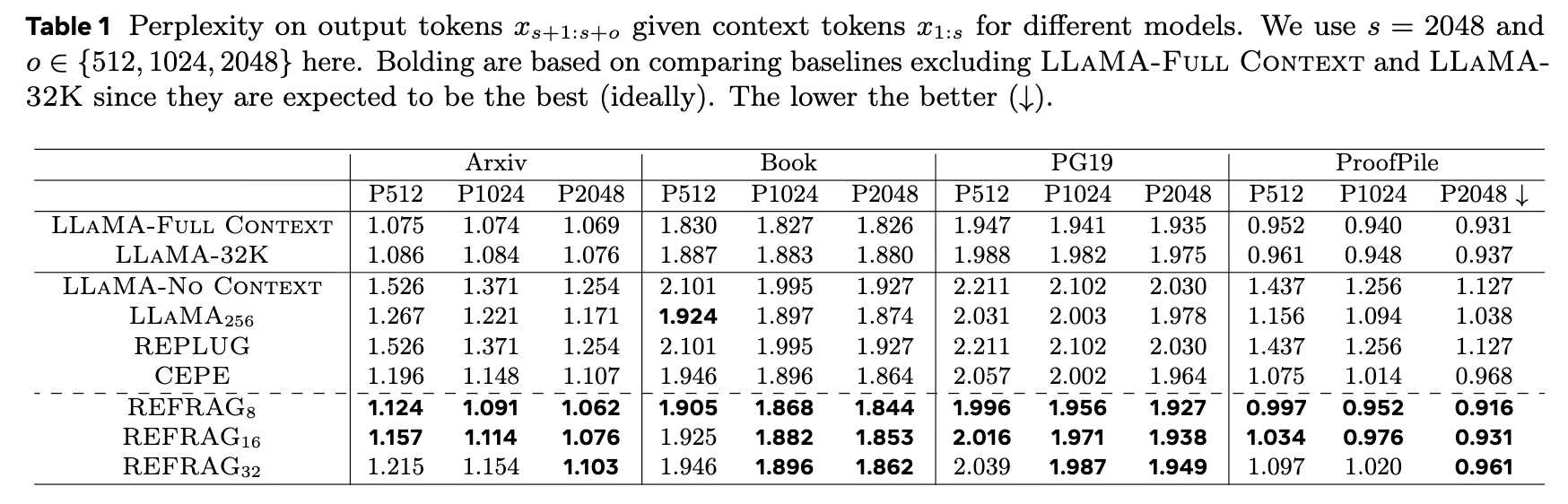
-
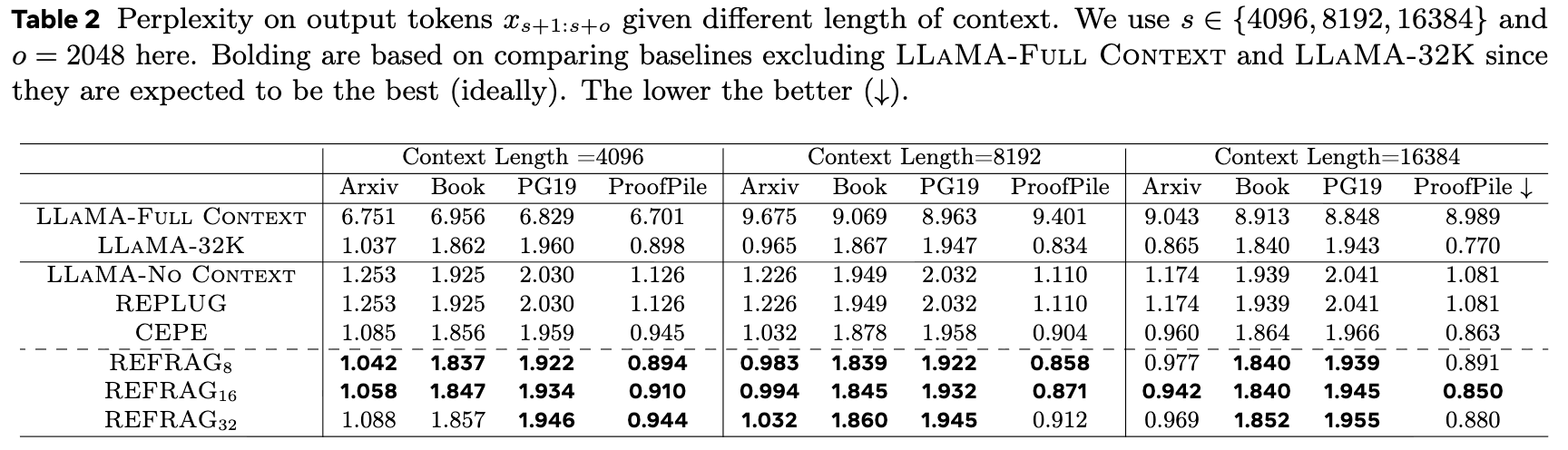
标准上下文长度 (s=2048): 如表1所示,REFRAG和REFRAG在几乎所有设置下都优于其他基线(不包括作为理想上限的Full Context和32K模型),同时延迟远低于CEPE。 -
扩展上下文长度: 如表2所示,即使在模型未见过的更长上下文(高达16384)上,REFRAG仍然保持了优越的性能。这表明通过块嵌入的方式,模型获得了外推(Extrapolation)能力,支持了更广泛的应用。
4.4 选择性压缩的效果
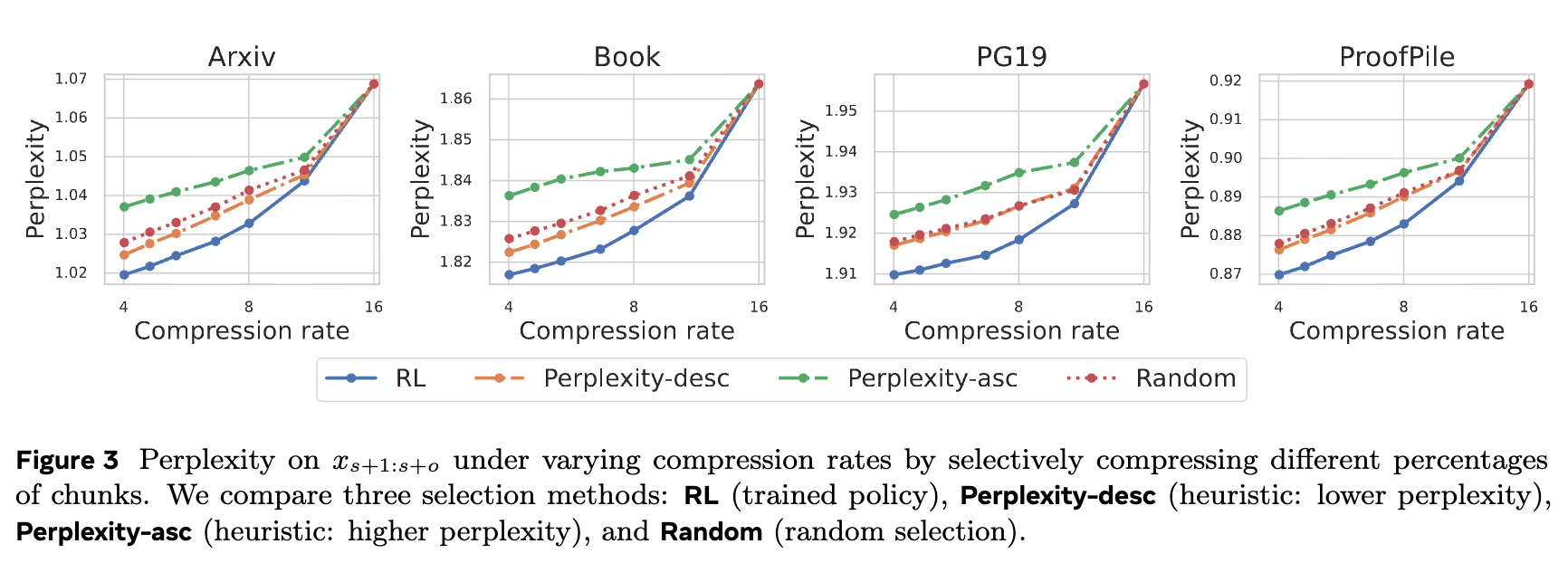
上图展示了不同选择性压缩策略的性能。RL策略在不同的压缩率 下都取得了最好的性能,一致优于基于困惑度的启发式方法和随机选择方法。这证明了RL策略在识别信息密集块方面的有效性。
消融研究
-
课程学习的重要性:实验证明,对于重建任务,课程学习是必不可少的。没有课程学习,模型在重建多个块时性能会下降。 -
重建任务的重要性:预先进行重建任务对于后续的持续预训练任务的学习也至关重要。 -
RL选择性压缩的优势:结果表明,使用RL策略的REFRAG(在运行时动态调整压缩块数)在达到相同的等效压缩率(例如8)时,性能优于原生以压缩率8训练的REFRAG。这凸显了RL策略的有效性和动态调整压缩率的实用性。
上下文学习应用
5.1 检索增强生成 (RAG)
研究人员对预训练好的REFRAG模型进行了微调,以适应多种下游任务。
-
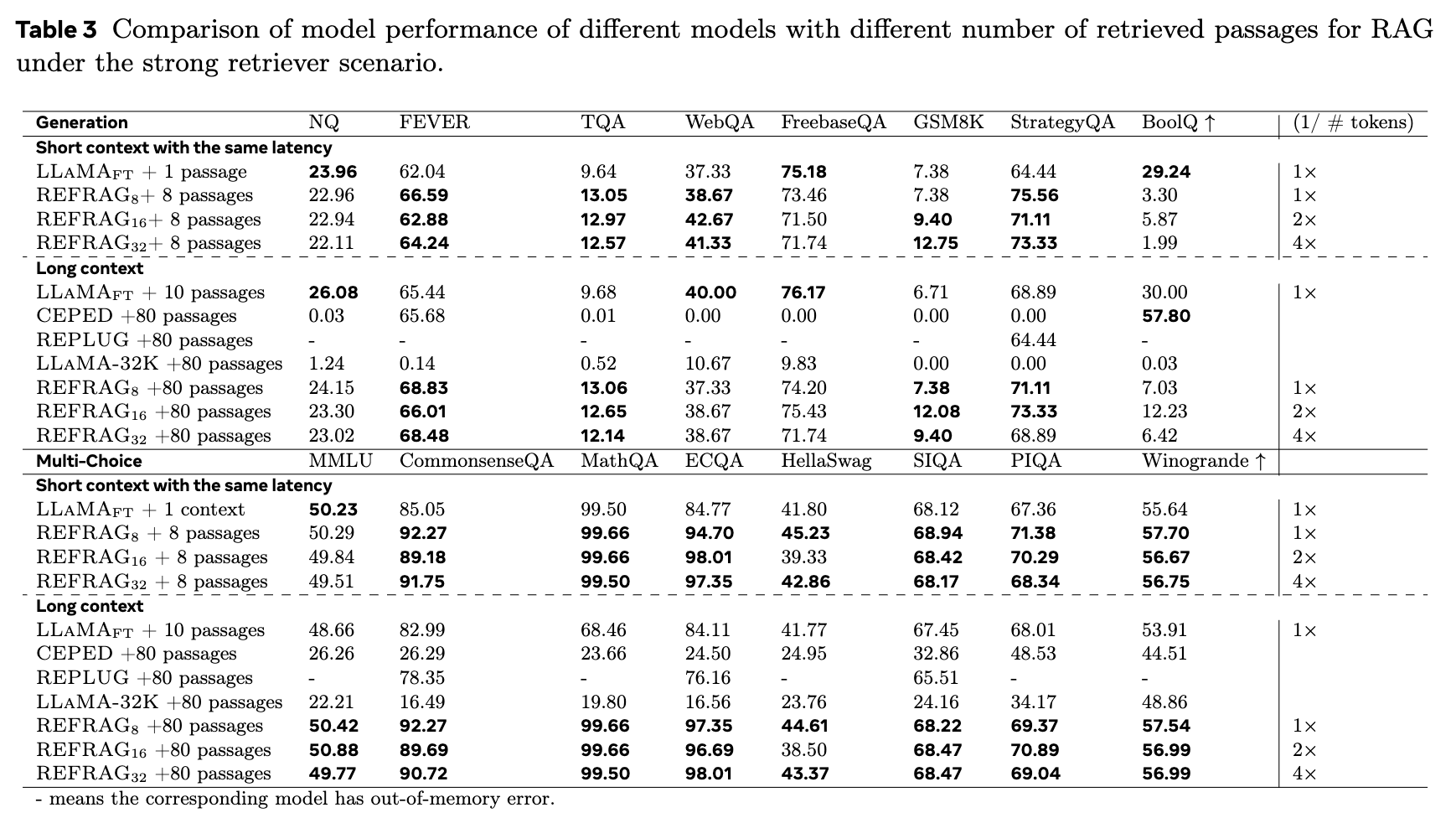
结果分析: -
在同等延迟下(例如,REFRAG使用8个段落,LLaMA使用1个段落),REFRAG由于能够处理更多的上下文信息,性能更优。 -
在更低延迟下(例如,REFRAG和REFRAG的输入 token 数分别是LLaMA的1/2和1/4),REFRAG的性能仍然能够超越LLaMA。 -
在长上下文场景和多选任务中,REFRAG的性能优势更为明显。
-
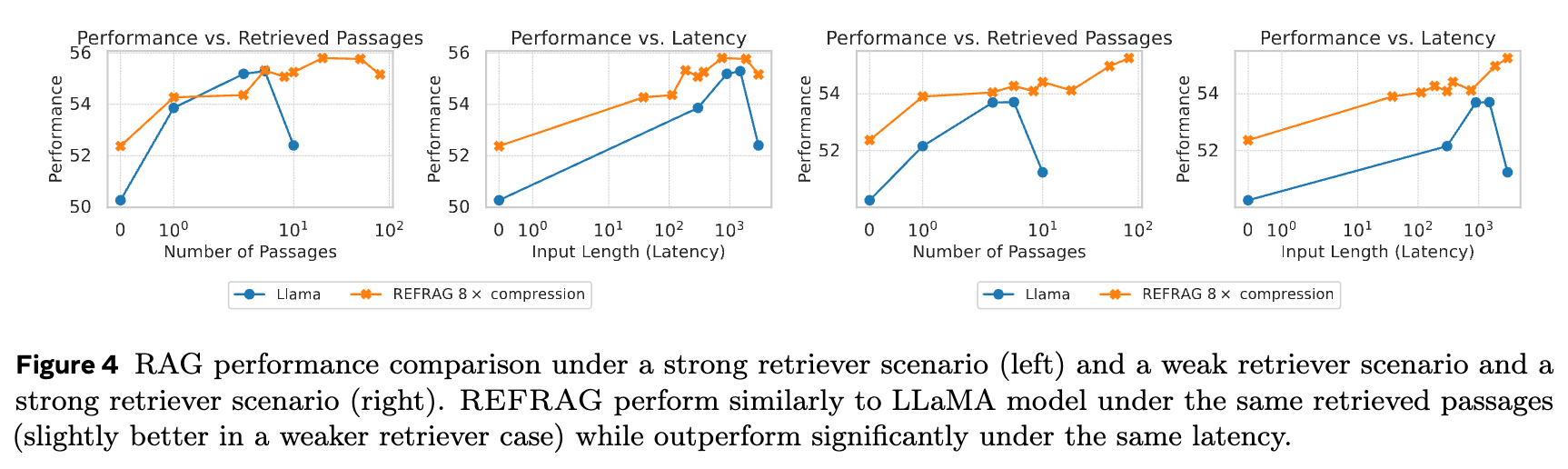
上图比较了在给定相同数量的检索段落和相同延迟两种条件下,REFRAG与LLaMA模型的性能。
-
在强检索器和10个段落的设定下,REFRAG在性能上与LLaMA持平,同时TTFT加速了5.26倍。 -
在同等延迟下,REFRAG在16个RAG任务上的平均性能提升了1.22%。 -
在弱检索器场景下,REFRAG的优势更加突出,因为它能从更多的(可能相关性较低的)段落中提取有用信息。
5.2 多轮对话
在知识密集型的多轮对话数据集(TopiOCQA, ORConvQA, QReCC)上的实验结果表明,REFRAG同样表现出色。
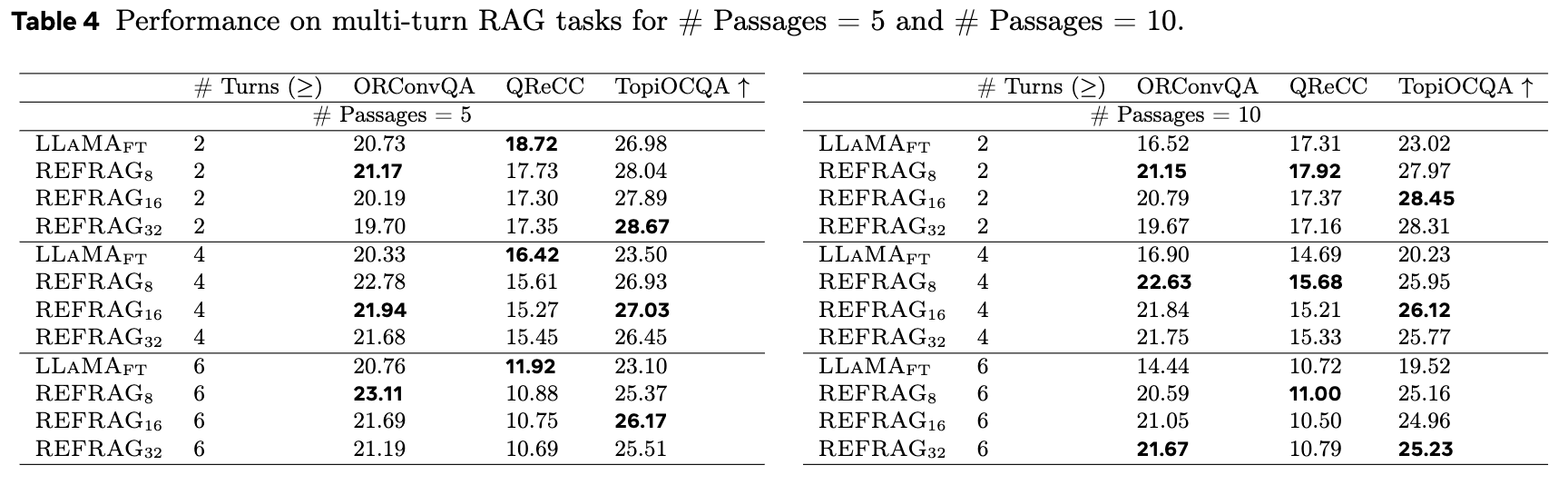
随着对话轮次的增加,标准LLaMA模型由于其有限的4k token 上下文窗口,不得不截断部分对话历史,导致信息丢失和性能下降。而REFRAG通过其压缩机制,能够在不扩展位置编码的情况下,保持稳健的性能,在多数场景下优于经过微调的LLaMA模型。
相关工作
-
高效长上下文LLMs: 已有工作通过修改注意力机制(如压缩注意力)或改变上下文供给策略(如Attention Sinks)来降低长上下文处理的开销。REFRAG的方法与这些工作是互补的。 -
压缩变换器 (Compressive Transformer): 早期的工作通过压缩KV缓存来减少内存使用,但并未改善TTFT延迟。后续工作虽然引入了递归压缩,但其串行特性阻碍了预计算和复用。REFRAG是首个能够对块嵌入进行预计算并在提示中任意位置使用的框架。 -
提示压缩 (Prompt Compression): LLMLingua等工作旨在缩短输入 token 长度。这些方法同样与REFRAG互补,可以被整合进来以进一步降低延迟。
结论
REFRAG是一个为RAG应用量身定制的新颖高效解码框架。通过利用RAG上下文中固有的稀疏性和块对角注意力模式,REFRAG通过压缩、感知和扩展上下文表示,显著降低了内存使用和推理延迟,特别是TTFT。在包括RAG、多轮对话和长文档摘要在内的多种长上下文应用中的大量实验证明,REFRAG可以在不损失困惑度或下游任务准确性的情况下,实现高达30.85倍的TTFT加速(比现有SOTA方法快3.75倍)。这些结果凸显了为RAG系统设计专门处理方法的重要性,并为高效的大上下文LLM推理开辟了新的方向。REFRAG为在延迟敏感、知识密集的应用中部署LLMs提供了一个实用且可扩展的解决方案。
往期文章:
-
-
DeepSeek V3.1 翻车了!字节 Seed 提出 Inverse IFEval 判断大型语言模型能否听懂“逆向指令”?
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
蚂蚁浙大提出基于“评分细则”(Rubric)的奖励机制,仅靠5000+样本,让30B轻松击败671B DeepSeek V3
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-