今年,大模型在对话和推理能力上取得了长足的进步。但是在医疗领域,虽然在很多模型在 benchmark(如美国医师执照考试 USMLE)上刷得很高,但是在真实的临床决策场景中其实用性往往不尽如人意。
为了应对这一挑战,Baichuan-M2 团队提出了《Baichuan-M2: Scaling Medical Capability with Large Verifier System》一种新的动态验证框架。该框架超越了传统的静态答案验证器,构建了一个大规模、高保真的交互式强化学习系统。这项工作不仅在技术上有所推进,也为如何将大语言模型的能力与实际临床应用需求对齐,提供了一个清晰的思路。
Takeaways:
-
专门为验证系统训练了两个模型:患者模拟器、评估细则生成器; -
Baichuan-M2 分三个阶段训练,Mid-Training(CPT)、SFT、RL: -
Mid-Training 中Structured Rephrasing、Explicit CoT Injection、领域自约束训练机制值得借鉴; -
SFT 数据量级200万(医疗20%,Qwen2.5-32B-Base),知识密集型任务分配给 SFT 阶段,而推理密集型问题则留给 RL 阶段; -
RL 多阶段:规则强化、评估细则强化、多轮强化;用了改进版的GRPO(移除 KL 散度惩罚、clip-higher、长度归一化损失、简化的优势归一化(无方差));
-
背景
在深入了解 Baichuan-M2 的解决方案之前,有必要先理解其试图解决的核心问题。当前医疗大模型的评测大多依赖于标准化的医学考试题库,例如 USMLE 或各类模拟问答数据集。这类评测方式有其价值,能够衡量模型对静态医学知识的记忆和基础推理能力。但它们与真实的临床实践存在本质区别:
-
信息的非完整性与动态获取:真实世界中的医生面对患者时,初始信息往往是不完整甚至模糊的。医生需要通过多轮问询、检查和互动来逐步收集信息、形成假设、并进行验证。而静态问答评测通常提供一个包含了所有必要信息的“完美问题”。 -
交互的复杂性:临床沟通不仅是信息的交换,还包含了共情、安抚、解释和建立信任等多种软技能。患者可能会隐瞒信息、表达情绪,或受到自身社会文化背景的影响。这些都是静态评测无法衡量的。 -
决策过程的动态性:医生的决策是一个连续的过程,而非一次性的问答。从初步诊断到治疗方案的制定,再到后续的随访调整,每一步都基于前序的互动结果。 -
评估维度的多维性:对一名医生的评价是多维的,不仅包括诊断的准确性,还包括沟通技巧、治疗方案的合理性、对医疗伦理和风险的考量等。
正是由于这些差异,一个在考试中能得高分的模型,在面对一个模拟的、会哭泣、会担忧、会忘记提供关键信息的“虚拟患者”时,可能会束手无策。Baichuan-M2 的工作,其核心目标就是构建一个能够模拟这种真实、动态、复杂环境的系统,并在此环境中训练和评估模型。
一个大规模动态验证器系统
为了弥合上述鸿沟,研究团队从静态答案验证器转向开发一个大规模、高保真的交互式强化学习验证器系统(Verifier System)。这个系统旨在创建一个“虚拟临床世界”,让模型在模拟的“实践”中学习和成长。该系统由两大核心组件构成:患者模拟器(Patient Simulator) 和 临床评估细则生成器(Clinical Rubrics Generator)。
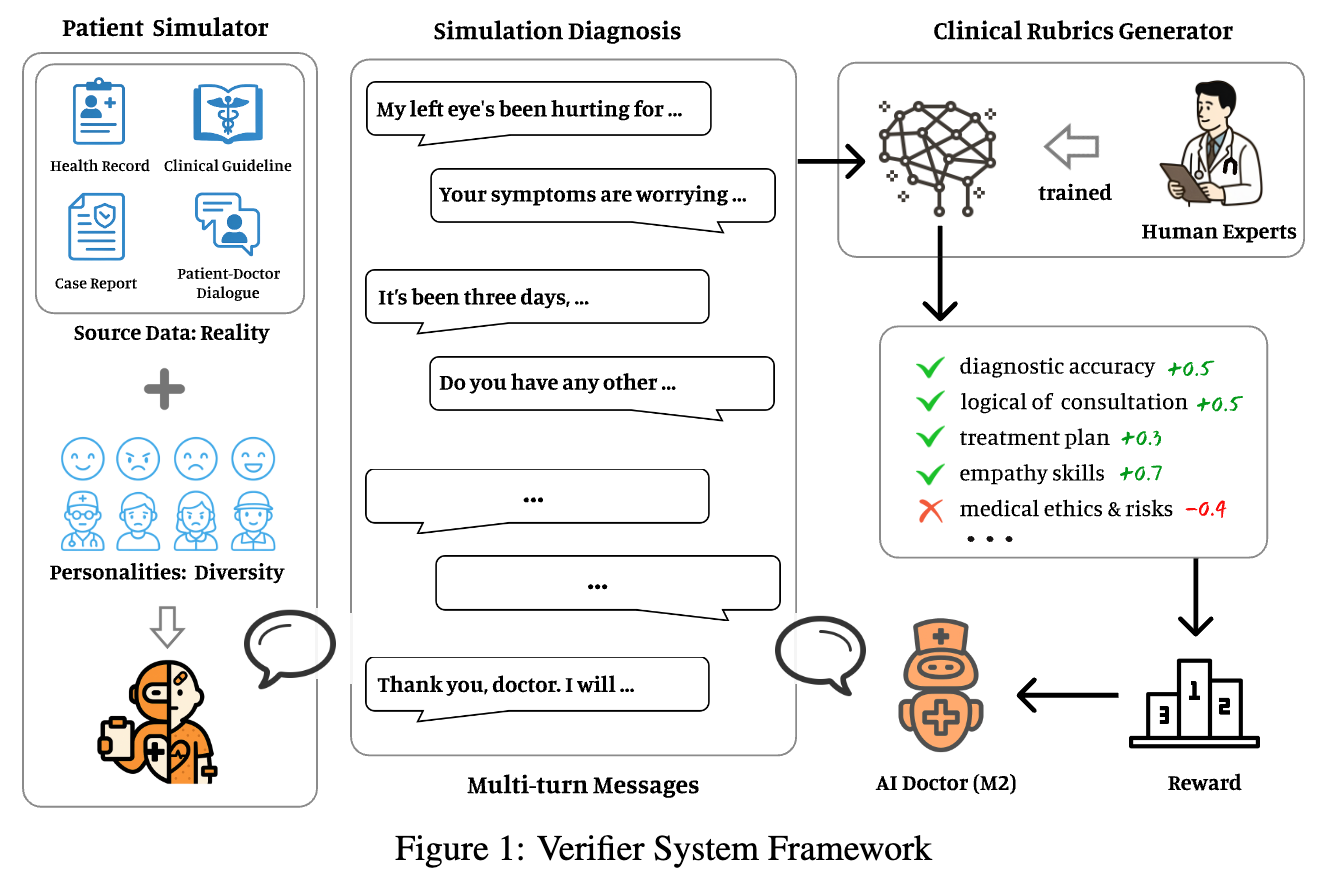
如上图所示,整个系统形成了一个闭环:
-
患者模拟器 基于真实的医疗数据生成一个具有特定病情、性格和背景的虚拟患者。 -
AI 医生(Baichuan-M2) 与虚拟患者进行多轮对话,尝试进行诊断和提供建议。 -
临床评估细则生成器 像一位经验丰富的上级医生,实时观察整个对话过程,并动态生成多维度的评估标准(Rubrics)。 -
基于这些评估标准,系统为 AI 医生的回复计算出一个量化的奖励(Reward)。 -
这个奖励信号被用于通过强化学习算法来优化 AI 医生模型。
下面我们详细解析这两个核心组件。
患者模拟器 (Patient Simulator)
患者模拟器的作用是提供一个真实且富有挑战性的动态测试环境。它需要克服以往模拟器沦为静态数据库的局限,能够综合模拟患者的生理状态、心理状态、社会背景和动态交互行为。
开发高保真患者模拟器的核心挑战在于平衡多样性(Diversity)和一致性(Consistency)。多样性要求模拟器能覆盖广泛的疾病、临床场景和患者行为模式;一致性则要求在特定病例中,模拟器的行为必须符合预设的病历和人物设定,不能出现事实矛盾或信息泄露。
为此,研究团队构建了一个包含医疗信息和心理信息的模拟框架。
-
医疗信息:数据来源于经过脱敏处理的真实世界临床数据集,涵盖多种专科和人群,确保了疾病分布和临床场景的真实性。关键信息包括主诉、现病史、既往史等,用于评估模型的信息收集能力。 -
心理信息:为了模拟行为模式,研究团队借鉴了 MBTI 16 型人格模型,将不同的人格特质映射到具体的行为表现上。例如,外向型(E)的虚拟患者可能主动询问治疗方案,而内向型(I)则可能被动接受信息;情感型(F)比思考型(T)对沟通风格更敏感。此外,社会属性(如经济状况、受教育程度)也会影响其对治疗方案的反应。
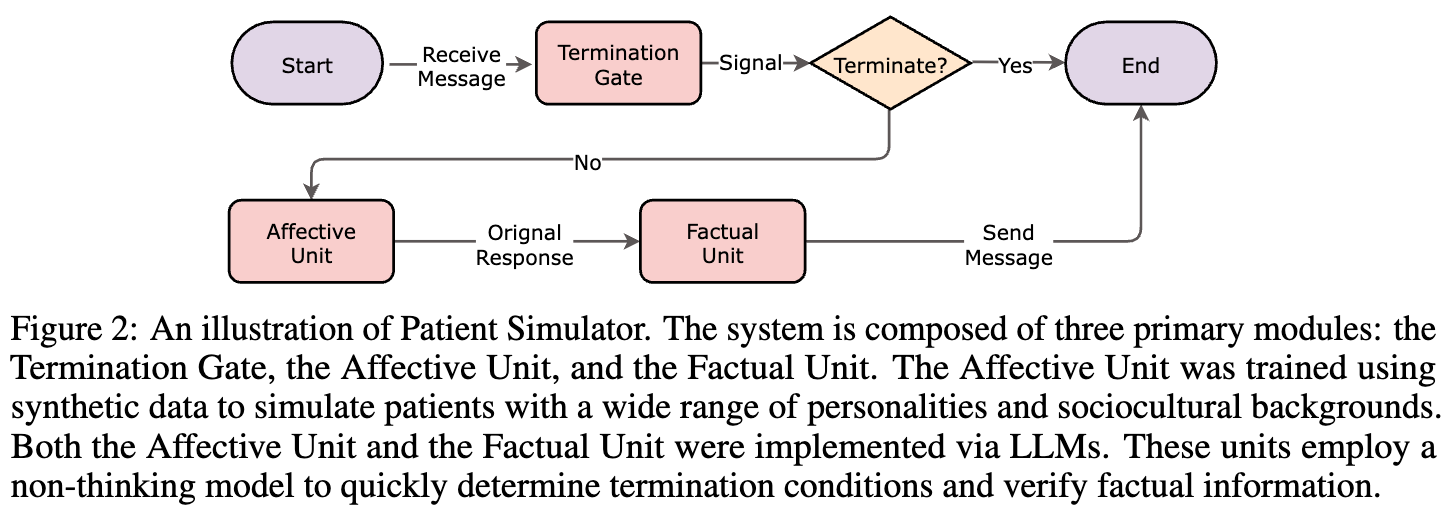
为了解决小型模型行为一致性差、大型模型计算成本过高的问题,模拟器采用了三模块组件架构:
-
终止门(Termination Gate):基于预定义规则(如医生给出明确诊断)判断对话是否应结束,避免对话无休止或过早终止。 -
情感单元(Affective Unit):负责生成符合角色设定和情感背景的回复,通过角色扮演实现行为多样性。 -
事实单元(Factual Unit):实时核对回复与患者档案,防止泄露未被问及的信息或产生与事实不符的内容,保证一致性。
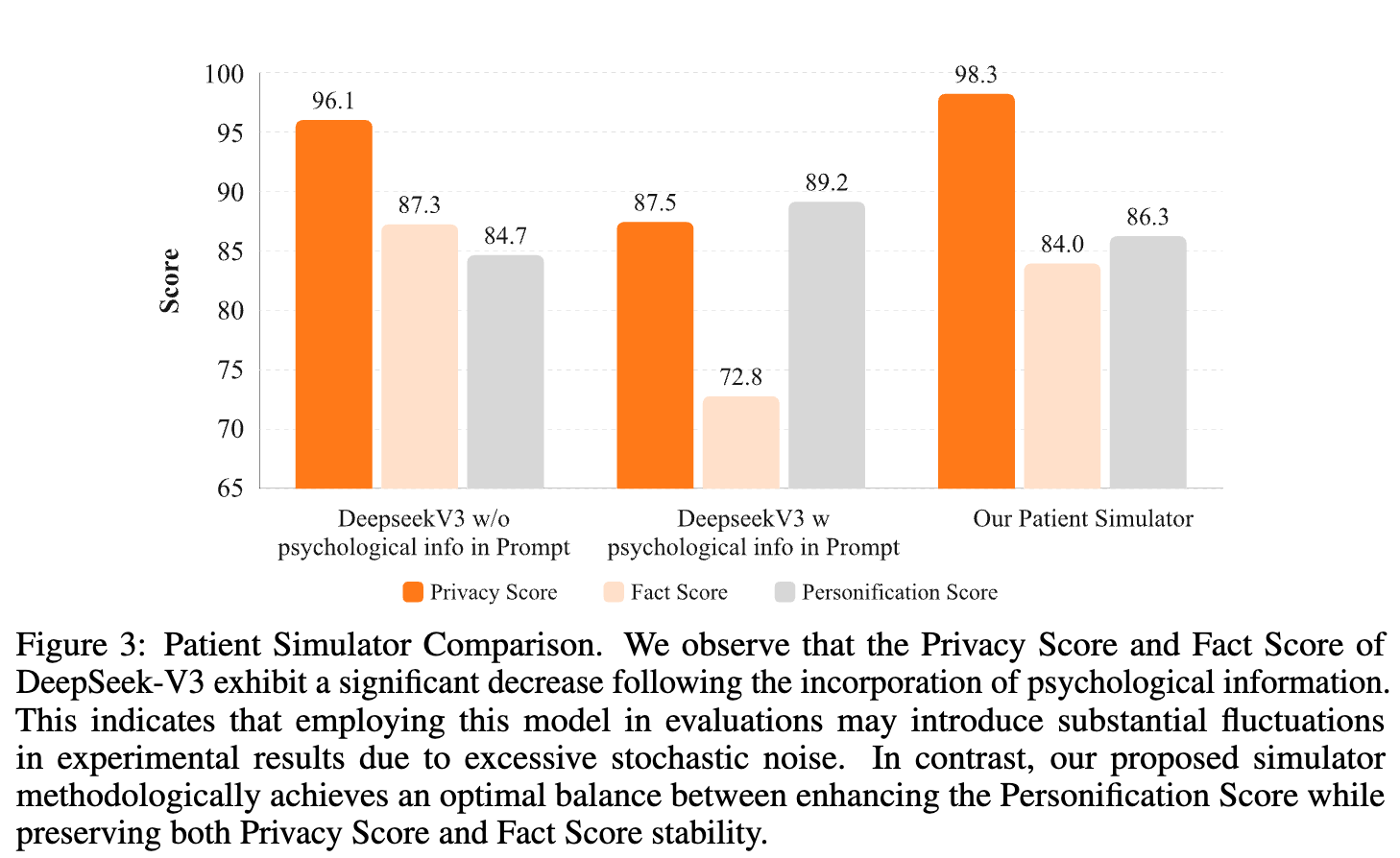
通过这种设计,患者模拟器能够用一个相对较小的模型,实现与大型模型相媲美的性能。在评测中(如下图所示),相较于直接使用大型模型(如 DeepSeek-V3)作为模拟器,Baichuan-M2 团队提出的模拟器在保持高水平的隐私保护得分(Privacy Score)和事实准确性得分(Fact Score)的同时,显著提升了个性化得分(Personification Score),达到了多样性与一致性的优化平衡。
临床评估细则生成器 (Clinical Rubrics Generator)
如果说患者模拟器创建了“考场”,那么临床评估细则生成器就定义了“评分标准”。真实临床实践的复杂性使得传统的二元(对/错)或基于规则匹配的奖励信号不足以指导模型学习。因此,需要一个能够捕捉专家医生临床判断细微差异的评估系统。
该生成器具备三个关键属性:
-
全面性(Comprehensiveness):评估不仅限于诊断准确性,还涵盖沟通质量、治疗方案合理性、共情能力、医疗伦理等多个维度。 -
可靠性(Reliability):所有评估标准都经过经验丰富的临床医生严格验证,确保与专业标准和最佳实践一致。 -
适应性(Adaptiveness):系统能根据患者模拟器生成的不同患者特征、行为模式和沟通风格,动态调整评估细则。
为了开发这个生成器,团队设计了三步核心流程:
-
提示词收集与处理(Prompt Collection and Processing):
-
来源:从三个主要来源构建提示词库:a) 医疗记录驱动,源自真实病历,确保临床真实性;b) 知识库驱动,源自教科书、指南等,确保事实正确性;c) 合成场景驱动,模拟复杂专业需求(如病程记录撰写、智能分诊),评估综合能力。 -
处理:利用 LLMs 对原始提示词进行扩充,再通过聚类去重、多维标注(难度、能力类别等)和筛选,最终形成一个高质量、多样化、均衡的提示词集。
-
-
评估细则构建(Rubric Construction):
-
定义核心维度:由医学专家根据数据源和应用场景,确定关键评估维度。 -
生成候选细则:LLMs 围绕这些维度生成大量的候选评估细则。 -
专家筛选与定制:内部临床专家为每个案例挑选最能反映其独特性的细则。 -
权重标注:专家在 [-10, 10]的范围内为每条选定的细则分配权重,以反映其相对重要性。例如,诊断准确性的权重通常高于沟通礼仪。 -
数据扩展:将这些带权重的细则作为“种子数据”,再由 LLMs 扩展生成更大规模、更全面的数据集。
-
-
评估细则生成器的训练(Training of Rubrics Generator):
-
使用一个中等规模的基础模型进行训练,以平衡生成质量和在线计算成本。 -
训练数据融合了医学评估细则、数学/代码推理和复杂指令遵循数据集,以增强模型的逻辑严谨性和任务适应性。 -
训练范式结合了有监督微调和强化学习,确保事实正确性的同时,允许在不同临床场景中灵活生成评估标准。
-
经过评估,该生成器生成的评估细则与临床专家标注的细则一致率达到了 92.7% 。这表明它能够定量地指导模型的临床推理,同时平衡了多样性、核心要点覆盖和计算成本,为后续的强化学习提供了可靠的基础。
模型构建:Baichuan-M2 的三阶段训练流程
拥有了强大的“陪练”(患者模拟器)和“裁判”(评估细则生成器)后,Baichuan-M2 模型的训练过程便得以展开。整个流程被设计为一个连贯的流水线,分为三个主要阶段:中间训练(Mid-Training)、有监督微调(Supervised Fine-Tuning, SFT) 和 强化学习(Reinforcement Learning, RL)。
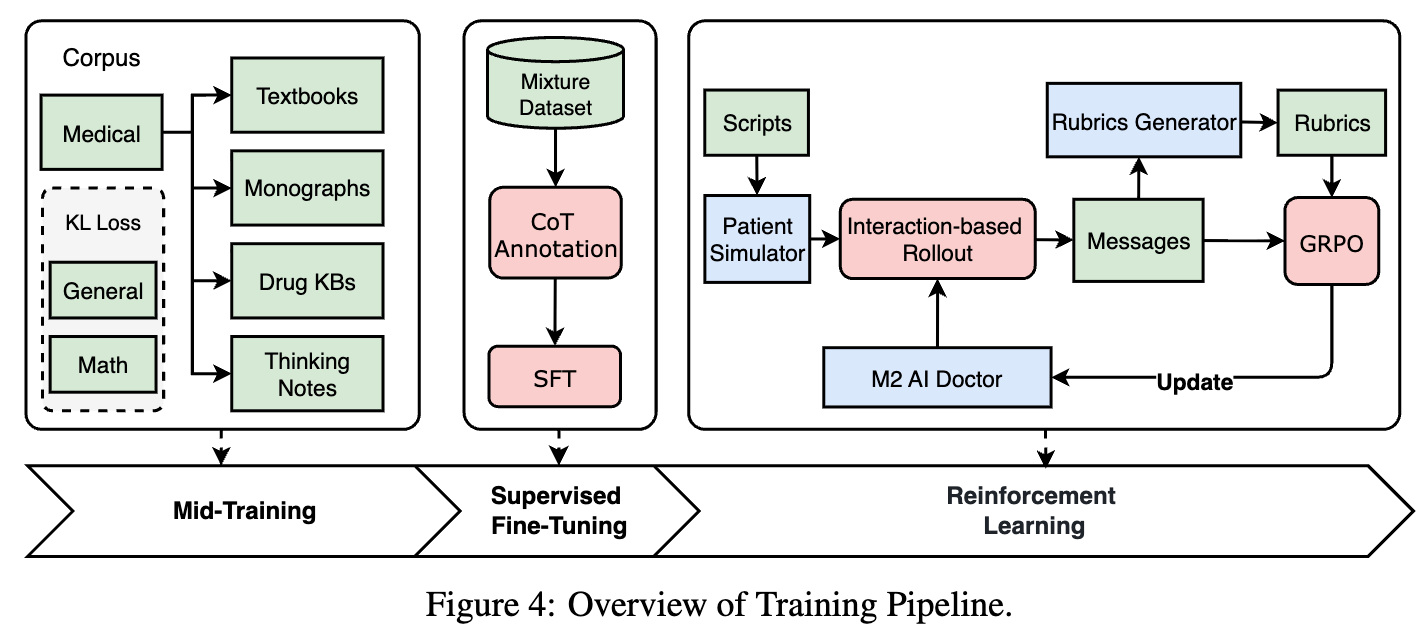
中间训练 (Mid-Training)
通用的预训练模型通常缺乏足够的医学知识储备,直接进行下游任务微调容易导致知识对齐不足或加剧幻觉。为此,研究团队采用了轻量级的中间训练阶段,旨在有效增强模型的医学领域适应性,同时最大限度地保留其固有的通用能力。
-
专业医疗语料构建:数据源包括公开的医学教科书、临床专著、药品知识库、最新的临床诊疗指南以及脱敏的真实医疗记录。 -
两阶段数据增强策略: -
结构化改写(Structured Rephrasing):对原始医学文本进行结构化重写,提升逻辑连贯性和可读性,同时严格遵守知识保真原则,减少由改写引入的幻觉风险。 -
显式思维链注入(Explicit CoT Injection):在知识密集的段落和关键结论处,自适应地插入“思考笔记”(thinking notes),涵盖知识关联、批判性反思、论证验证等,帮助模型学习可迁移的推理模式。
-
-
领域自约束训练机制:为了防止通用能力的退化,将医疗、通用和数学推理语料以 2:2:1 的比例混合。训练时采用多任务范式: -
医疗知识任务:执行标准的下一词元预测任务,促进模型吸收和记忆权威医学知识。同时,在注入了思维链的数据上进行训练,提升模型的复杂推理能力。 -
通用与数学任务:引入 Kullback-Leibler (KL) 散度损失,使用通用基础模型作为参考模型,约束训练后的模型在这些领域的输出分布与原始模型保持一致。
-
总的损失函数可以表示为:
这一阶段旨在实现医学知识深度、推理能力和通用能力维持之间的平衡,为后续的微调和对齐阶段打下坚实的基础。
3.2 有监督微调 (SFT)
直接应用强化学习风险较高,因为模型 foundational capabilities 不足可能导致收敛困难和策略探索效率低下。因此,SFT 阶段旨在建立基础的推理能力,并为后续的多阶段强化学习提供稳定的初始化。
-
数据池构建:从内部数据集和外部开源数据构建了一个超过 400 万样本的候选数据池。 -
数据处理流水线: -
通用指令数据处理:通过高维语义嵌入和聚类分析,进行分层抽样,确保任务类型和难度级别的全面覆盖,同时自动过滤低质量样本。 -
验证驱动的数据分配:对于有可验证答案的样本,使用专门的验证器(辅以多模型共识)进行拒稿抽样,剔除有问题的样本。然后,将剩余的难题进行策略性划分:知识密集型任务分配给 SFT 阶段,而推理密集型问题则留给 RL 阶段。 -
医疗领域专业化:针对现有医疗数据集多为标准化考试场景、缺乏真实世界临床复杂性的问题,团队特别增强了医疗数据的覆盖范围,包括预问诊、智能分诊、电子病历生成等核心医疗场景。
-
最终,构建了一个包含 200 万样本的 SFT 数据集(医疗相关数据约占 20%),在 Qwen2.5-32B-Base 模型上进行训练,为后续的强化学习优化提供了稳定的基础。
3.3 强化学习 (RL)
强化学习是使大模型与人类偏好和领域特定需求对齐的关键环节。在医疗应用中,这种对齐因其对精确性、安全性和专业性的严格要求而尤为重要。
研究团队实现了一个多阶段强化学习框架,通过三个互补的阶段逐步增强模型的医疗能力:
-
基于规则的强化学习:发展基础推理能力。 -
基于评估细则的强化学习:优化结构化的医疗响应质量。 -
多轮对话强化学习:提升动态临床互动能力。
该方法采用了一个改进版的组相对策略优化(Group Relative Policy Optimization, GRPO)算法。其优化目标形式化为:
其中, 表示组相对优势,通过将第 个响应的奖励与组内所有响应的平均奖励进行归一化计算得出。 是重要性采样比率。关键的算法改进包括:
-
移除 KL 散度惩罚:避免约束奖励增长,同时减少参考模型的计算开销。 -
非对称裁剪:使用更高的上界,防止熵过早崩溃,保持策略探索。 -
长度归一化损失:解决不同医疗数据源响应长度变化大的问题。 -
简化的优势归一化:减轻多任务难度偏差,增强训练稳定性。(参考Dr.GRPO)
Rubric-based RL 中的长度惩罚:在由评估细则驱动的优化下,模型倾向于生成“面面俱到”的冗长回复。为了鼓励在保证质量的前提下生成更简洁的答案,研究团队引入了动态长度奖励。
其中 是组内所有响应 rubric 分数的第 80 百分位数。这个长度奖励只有在两个严格条件下才会被激活:1) 整组响应的整体质量()超过预定阈值;2) 单个响应本身的分数也处于组内前 20%。这种双重门控机制确保了长度优化仅在质量达标后才进行,有效避免了“越短越好”的病态行为。
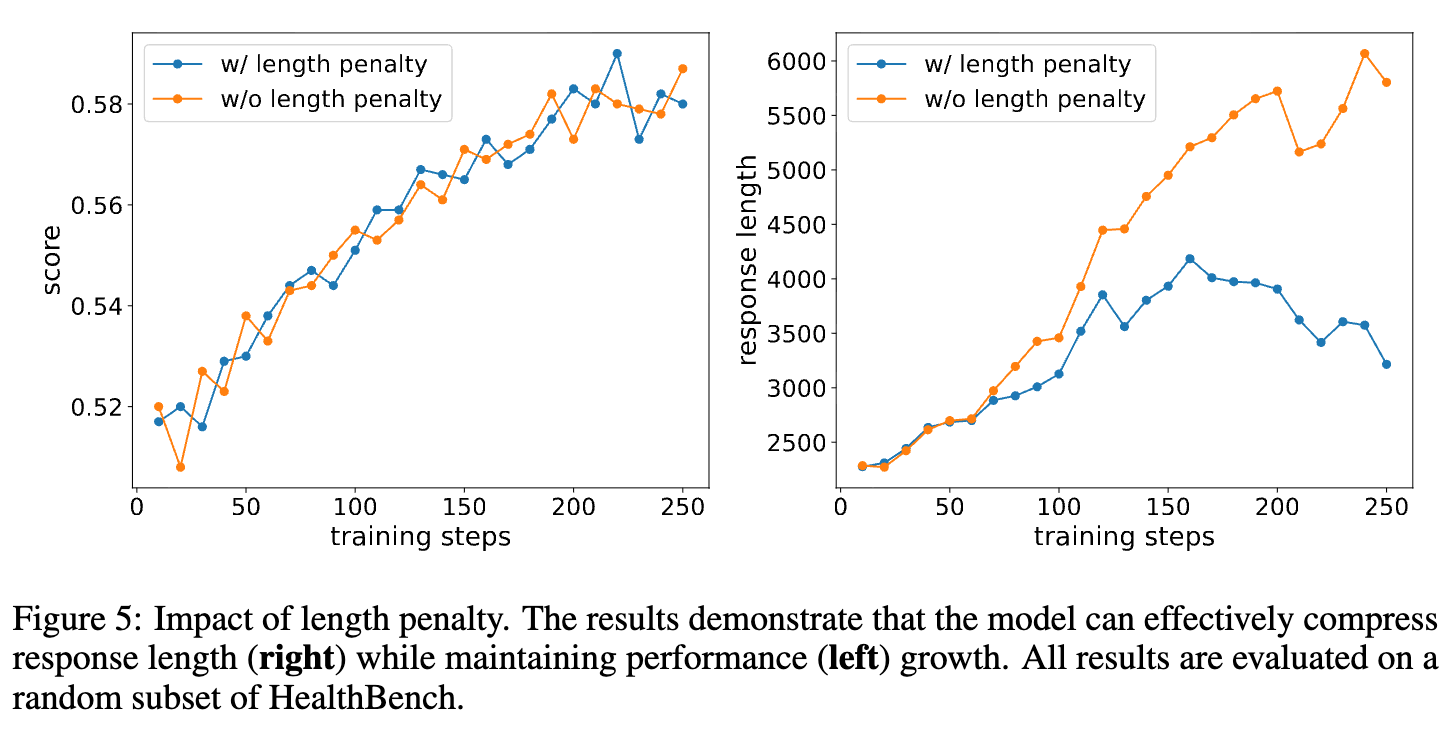
Multi-turn RL:最后一个阶段,模型与患者模拟器进行多轮对话。每一轮交互后,对话历史的一个片段被提取出来,送入评估细则生成器,产出与当前上下文高度相关的评估标准。模型根据这些动态生成的标准进行学习和优化。这种动态的“模拟-评估-优化”闭环,使得模型能够持续对齐医生在信息不完整和嘈杂临床环境中的推理模式。
评估与结果
Baichuan-M2 的性能在一系列权威的医疗和通用能力基准测试中得到了验证。
HealthBench 评测
HealthBench 是由 OpenAI 发布的医疗领域评测集,包含 5,000 个真实的多轮对话场景和由 262 位人类医生编写的 48,562 条评估标准。
-
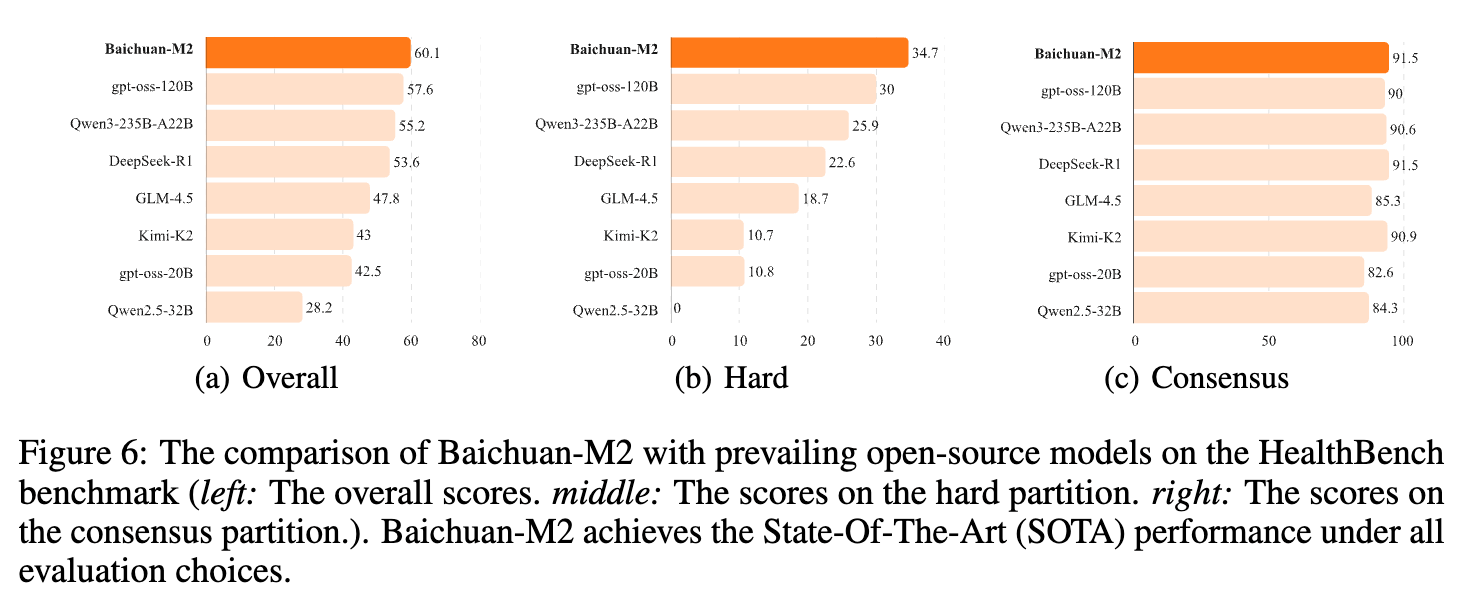
与开源模型的比较:如下图所示,Baichuan-M2 在 HealthBench 的总体得分、困难子集(Hard)得分和共识子集(Consensus)得分上,全面超过了包括 gpt-oss-120B, Qwen3-235B-A22B 在内的所有前沿开源模型。其在 Hard 任务上的优势尤为明显,展现了其解决复杂医疗任务的能力。
-
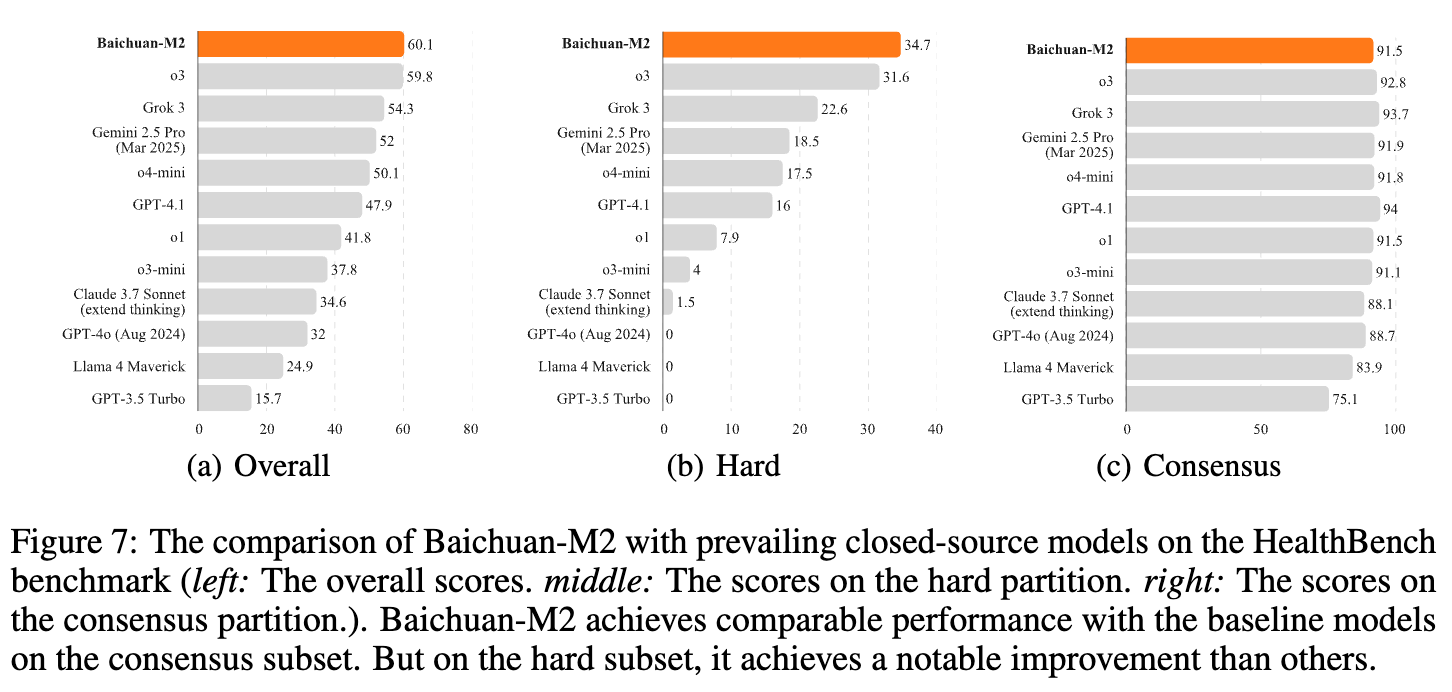
与闭源模型的比较:即使与最先进的闭源模型相比,Baichuan-M2 也显示出竞争力。在 HealthBench 和 HealthBench Hard 上,它超过了 o3, Gemini 2.5 Pro 和 GPT-4.1 等模型。值得注意的是,在 HealthBench Hard 发布时,没有模型能得分超过 32 分,而 Baichuan-M2 (34.7 分) 和 GPT-5 (46.2 分) 是目前全球仅有的两个在该项得分超过 32 分的模型。
-
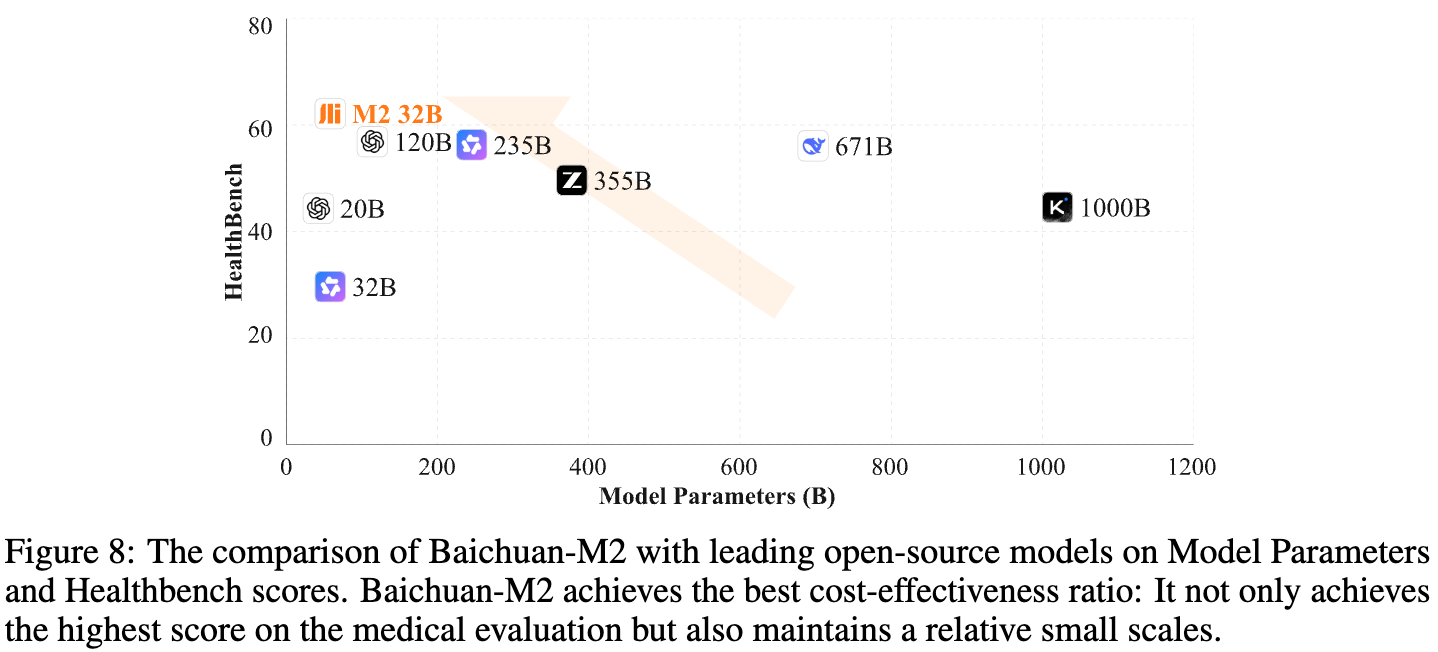
成本效益分析:医疗领域对私有化部署有强烈需求。如下图所示,Baichuan-M2 以 32B 的参数量,在 HealthBench 上取得了最佳的性能表现,实现了优异的成本效益比,推动了性能-参数权衡的帕累托前沿。
-
分维度和分主题分析:进一步的分析显示,Baichuan-M2 在紧急转诊(Emergency Referrals)、沟通(Communication)、全球健康(Global Health)和完整性(Completeness)等核心医疗场景中表现突出。

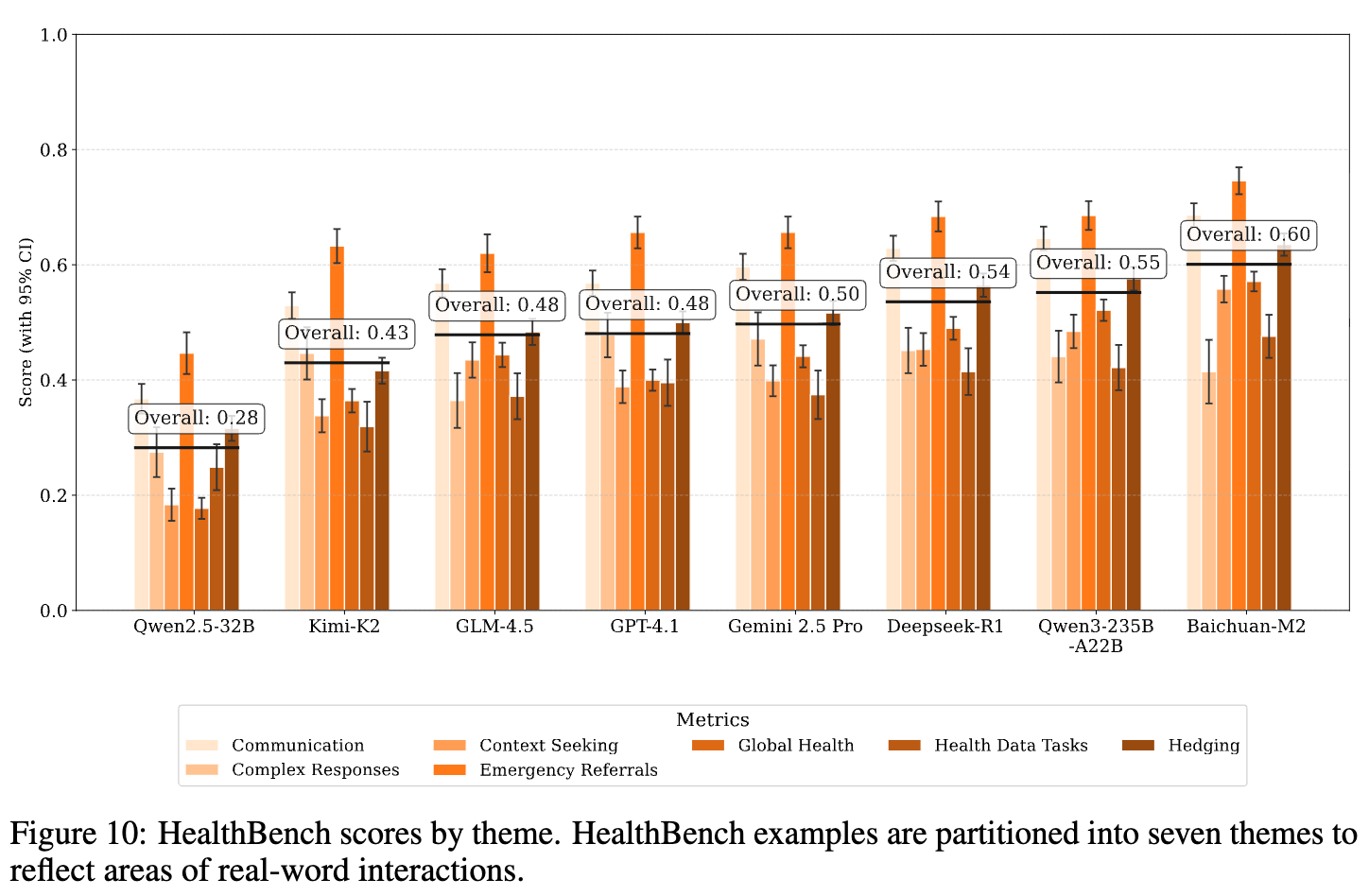
中国医疗场景评测
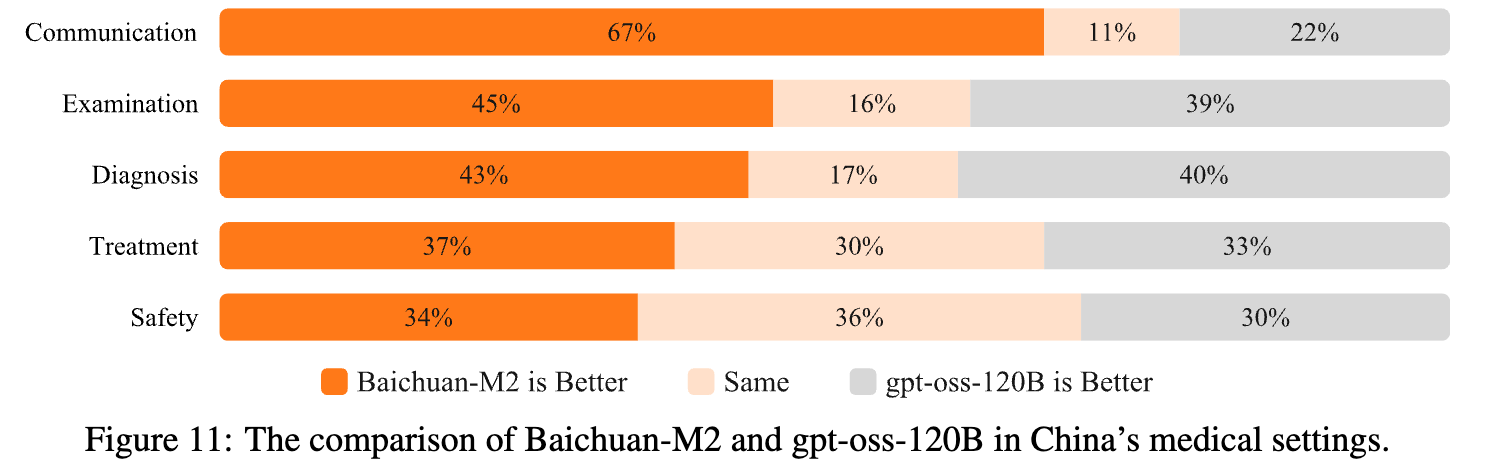
为了评估 Baichuan-M2 在中文医疗环境下的临床表现,研究团队构建了一个包含 57 个源自中国顶尖医院多学科会诊(MDT)的复杂临床案例 benchmark。这些案例的特点是真实、复杂且输入文本长。
评估围绕沟通、检查、诊断、治疗和安全五个维度展开。结果显示,Baichuan-M2 在所有五个维度上均表现出优于 gpt-oss-120B 的性能。尤其是在沟通维度,因其出色的可读性、结构和简洁性,Baichuan-M2 在 67% 的评估中获胜。这部分归因于其对中国医疗环境和临床指南的更好对齐。
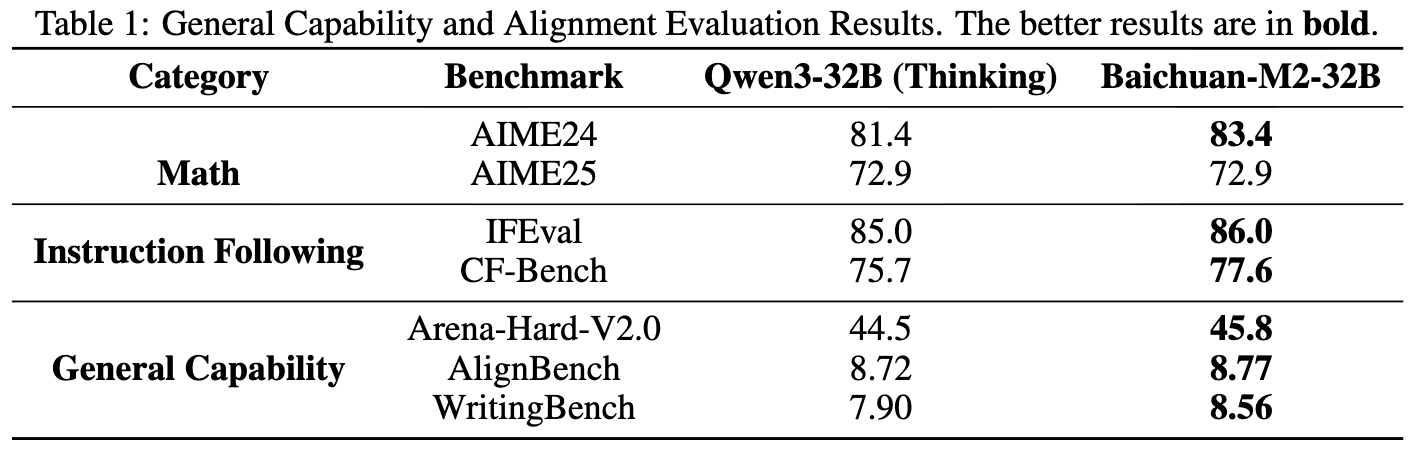
通用能力评测
除了专业的医疗能力,Baichuan-M2 也保持了业界领先的通用任务和指令对齐性能。在数学(AIME24)、指令遵循(IFEval)和通用能力(Arena-Hard-V2.0)等一系列权威基准测试中,Baichuan-M2-32B 表现稳健,验证了其作为一个医疗 AI 系统的综合素质。
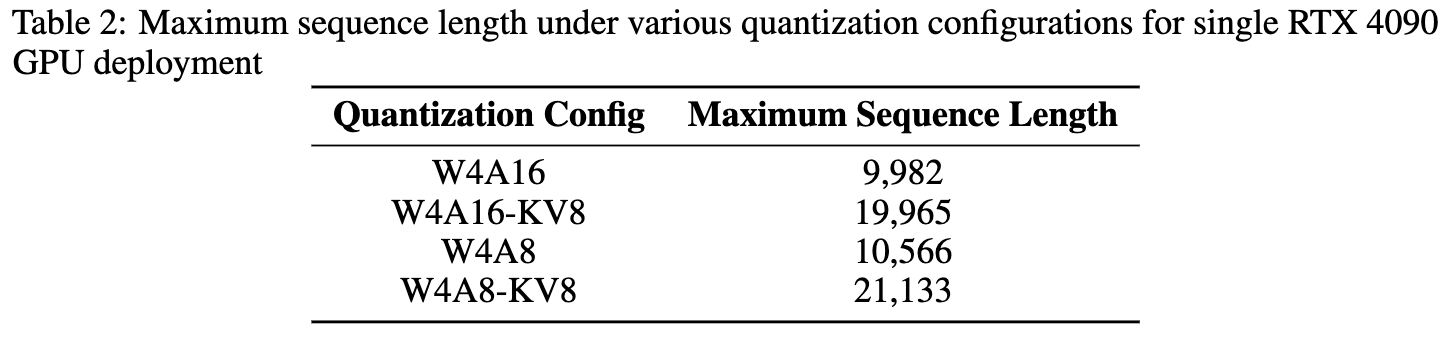
推理优化
为了提升模型在实际部署中的可及性和效率,研究团队实施了两项推理优化策略。
-
训练后量化(Post-training Quantization):采用 W4A16(4位权重,16位激活)和 W4A8 等先进量化技术,显著降低模型的内存占用。例如,在 W4A8-KV8 配置下,模型在单张消费级显卡(RTX 4090)上支持的最大序列长度可达 21,133 个 token。 -
推测解码(Speculative Decoding):通过训练一个轻量级的草稿模型来快速生成候选 token 序列,然后由目标模型并行验证。在单张 RTX 4090 显卡上部署时,该技术使吞吐量从 41.5 tokens/s 提升到 89.9 tokens/s,实现了 2.17 倍的加速。
局限性与未来工作
研究团队也坦诚地指出了当前工作的局限性。尽管 Baichuan-M2 取得了显著进展,但模型在某些边缘案例中仍可能表现出幻觉和推理不稳定的问题。从评测指标来看,无论是 HealthBench 还是真实世界医疗能力评估,Baichuan-M2 的性能远未达到饱和,仍有优化空间。在功能上,此版本尚未对工具调用和外部知识检索等能力进行充分优化。
未来的工作将聚焦于加强对医疗问询技能和幻觉缓解的量化评估与优化。此外,团队计划增强多轮会话强化学习的研究与实施,以提供更完整的临床工作流模拟。探索与医学知识库和临床决策支持系统整合的先进技术,以进一步降低幻觉率并提高诊断准确性,也是未来的重要方向。
往期文章:


