InternVL3.5 无论是从官方发布的结果,还是实际体验上来说都是比较有亮点的,今天着重解读一下InternVL3.5用到的后训练技术。

-
论文标题:InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency -
论文链接:https://arxiv.org/pdf/2508.18265
1. SFT
监督微调是模型预训练之后、进行更复杂对齐之前的关键一步。其核心目标是利用高质量、多样化的指令数据,使模型适应下游任务的特定格式和要求,初步具备遵循指令和进行对话的能力。相较于其前身 InternVL3,InternVL3.5 在 SFT 阶段的数据策略上进行了显著的优化和扩展,为其后续的推理能力提升奠定了坚实的基础。
1.1 SFT 阶段的目标与方法
在训练目标上,SFT 阶段与预训练阶段保持一致,继续采用下一个词元预测(Next Token Prediction)作为损失函数。具体而言,模型的目标是最大化在给定上文(包括图像和文本)的条件下,生成正确回复序列的概率。为了平衡长短回复的训练权重,避免模型产生偏见,InternVL3.5 沿用了平方根平均策略(square averaging strategy)来计算最终损失。这一策略对损失进行了重加权,其计算方式如下:
其中 ,这里的 是第 个词元的下一个词元预测损失,而 是当前训练样本中需要计算损失的词元总数。通过这种方式,可以缓解模型在训练过程中对较长或较短回复的偏好问题。
此外,为了适应需要处理长篇文档或复杂视觉场景的任务,SFT 阶段的上下文窗口被设置为 32K 词元,这使得模型能够处理和理解更长的上下文信息。
1.2 高质量、多样化的数据来源
InternVL3.5 SFT 阶段的核心优势在于其构建了一个比以往版本更优质、更多样化的训练数据集。这些数据主要来自三个方面:
-
继承与复用的指令遵循数据:研究团队复用了 InternVL3 中的指令遵循数据。这些数据覆盖了广泛的视觉-语言任务,确保了模型在进行能力扩展的同时,不会遗忘其在基础任务上的表现,维持了其全面的视觉语言理解能力。这部分数据构成了模型通用能力的基本盘。
-
引入“思考”模式的多模态推理数据:为了提升模型的复杂推理能力,特别是长链条思考的能力,InternVL3.5 引入了一种“Thinking”模式的训练数据。这些数据的构建过程是:首先利用一个大规模的推理模型,针对一系列复杂问题生成带有详细推理过程的“思维链”式回复。随后,数据团队不仅仅验证最终答案的正确性,还对推理过程本身进行了严格的筛选和过滤。筛选标准包括:
-
逻辑清晰度:推理步骤是否逻辑连贯,思路是否清晰易懂。 -
内容简洁性:去除冗余、重复的思考过程,确保推理路径的高效。 -
格式一致性:保证所有推理数据的格式统一,便于模型学习。
这些问题覆盖了数学、科学等多个需要深度推理的专业领域,通过学习这些高质量的推理过程,模型被引导去模仿一种结构化、步骤化的思考方式,从而在面对新的复杂问题时,能够进行更深入、更可靠的推理。
-
-
面向新技能的能力扩展数据集:为了让模型具备更多现实世界中的实用技能,InternVL3.5 还引入了能力扩展数据集。这部分数据旨在为模型注入新的能力,主要包括:
-
GUI(图形用户界面)交互:训练模型理解并操作图形用户界面,例如识别按钮、输入框并执行相应操作。 -
具身交互(Embodied Interaction):让模型理解物理世界中的指令和场景,为在机器人等具身智能体上的应用打下基础。 -
SVG(可缩放矢量图形)理解与生成:训练模型解析和生成 SVG 格式的图像,这对于网页理解、图表生成等任务至关重要。
-
通过整合这三类数据,InternVL3.5 的 SFT 阶段不仅巩固了基础能力,还针对性地强化了模型的推理深度和技能广度。整个 SFT 阶段的数据量达到了约 5600 万个样本,对应约 1300 亿个词元,其中文本数据与多模态数据的比例约为 1:3.5,这样的配比确保了模型在增强语言能力的同时,视觉理解能力也得到充分的训练。
二、 级联强化学习(Cascade Reinforcement Learning, Cascade RL)
强化学习(RL)被认为是提升大型语言模型与人类偏好对齐,特别是优化其推理能力的关键技术。与监督学习不同,强化学习能够引入负样本,通过奖励信号引导模型探索并优化其输出空间,从而“修剪”掉那些质量较低的回答区域,提升整体的回复质量。然而,传统的在线强化学习方法(如 PPO)虽然有效,但通常计算成本高昂且训练过程不稳定。离线强化学习方法(如 DPO)虽然效率更高,但其性能上限往往受到离线数据质量的限制。
为了结合两者的优点,同时规避其缺点,InternVL3.5 团队提出了创新的级联强化学习(Cascade RL)框架。这是一个分为两个阶段的、由粗到精的对齐过程,旨在以一种高效、稳定且可扩展的方式,逐步提升多模态模型的推理能力。
2.1 Cascade RL 框架的核心思想
Cascade RL 的核心思想是将复杂的对齐任务分解为两个循序渐进的子阶段:
-
离线 RL 预热阶段:首先使用一个离线强化学习算法对 SFT 后的模型进行微调。这一阶段利用固定的、预先收集好的偏好数据集进行训练,效率高且稳定性好。其目标是快速将模型调整到一个“满意”的性能水平,为下一阶段的在线学习提供一个高质量的初始模型(或者说,能够生成高质量 rollouts 的策略模型)。这个阶段可以看作是一个高效的“热身”过程。
-
在线 RL 精调阶段:在离线 RL 的基础上,接着使用一个在线强化学习算法,利用模型自身生成的 rollouts(即对给定问题的多次采样回答)进行进一步的优化。由于初始模型已经具备了较高的水平,因此生成的 rollouts 质量也相对较高,这使得在线 RL 阶段的训练更加稳定和高效,能够在一个更高的起点上继续探索和优化,从而突破离线 RL 的性能瓶颈,进一步提升模型的表现上限。
相较于单一的 RL 范式,Cascade RL 框架具有以下优势:
-
更好的训练稳定性:离线阶段将 rollouts 收集与参数更新解耦,有效缓解了在线 RL 中常见的“奖励黑客”(reward hacking)等问题。同时,一个更强大的初始模型进入在线阶段后,其训练动态也表现得更为稳定和鲁棒,对算法超参数的敏感度降低。 -
更高的训练效率:在离线 MPO 阶段,rollouts 可以在不同模型间共享,分摊了在线 RL 中成本高昂的采样开销。 -
更高的性能上限:实验证明,经过 MPO 微调的模型在进入在线 RL 阶段后,能够以更少的训练步数达到更高的性能水平,从而降低了整体的训练开销。
2.2 离线阶段:混合偏好优化(Mixed Preference Optimization, MPO)
在 Cascade RL 的第一阶段,InternVL3.5 采用了混合偏好优化(MPO)算法。MPO 是一种离线 RL 方法,其训练目标由三个部分组合而成,旨在从不同维度对模型的输出进行优化:
其中, 分别是各部分损失的权重。
-
偏好损失 () :这部分采用了直接偏好优化(DPO)损失。DPO 的核心思想是将奖励模型隐式地包含在优化目标中,直接利用成对的偏好数据(即对于同一个问题,一个“更优”的回答和一个“次优”的回答)来调整模型的概率分布,使其更倾向于生成“更优”的回答。 -
质量损失 () :这部分采用了二元分类器优化(BCO)损失。BCO 将问题看作是训练一个二元分类器,来判断一个回答是“好”的还是“坏”的。这部分损失有助于模型学习到高质量回答的普遍特征。 -
生成损失 () :这部分是传统的语言模型损失(LM Loss),即下一个词元预测损失。它的作用是保持模型的基础语言能力,防止在偏好优化过程中发生灾难性遗忘。
通过这三种损失的结合,MPO 能够稳定地提升模型的对齐水平,为在线阶段打下良好基础。训练数据方面,离线阶段使用了 MMPR-v1.2 数据集,包含约 20 万个样本对。
2.3 在线阶段:GSPO(Group Sequence Policy Optimization)
在 Cascade RL 的第二阶段,InternVL3.5 采用了 GSPO 算法(之前一篇文章介绍过:阿里通义千问放大招,告别训练崩溃!新算法 GSPO 碾压 GRPO,Qwen3 模型性能暴涨的幕后功臣
),这是一种在线 RL 方法。与传统的 PPO 算法不同,GSPO 在训练密集型(Dense)和专家混合(MoE)模型时表现得更为有效,并且不依赖于参考模型(reference model)的约束。
GSPO 的核心在于其优势(Advantage)的定义方式。对于同一个查询(query),模型会生成 个不同的回复 。每个回复 会通过一个奖励模型得到一个分数 。GSPO 的优势 被定义为标准化后的奖励:
这种标准化的优势函数使得模型能够更稳定地学习。GSPO 的训练目标函数如下:
其中, 是重要性采样比率,定义为新旧策略生成回复 的概率比:
通过这个目标函数,GSPO 能够有效地利用模型自身生成的 rollouts 来优化策略,进一步提升性能。在线阶段的数据来源于对 MMPR-v1.2 数据集的筛选和扩展,形成了一个约 7 万个查询的 MMPR-Tiny 数据集。
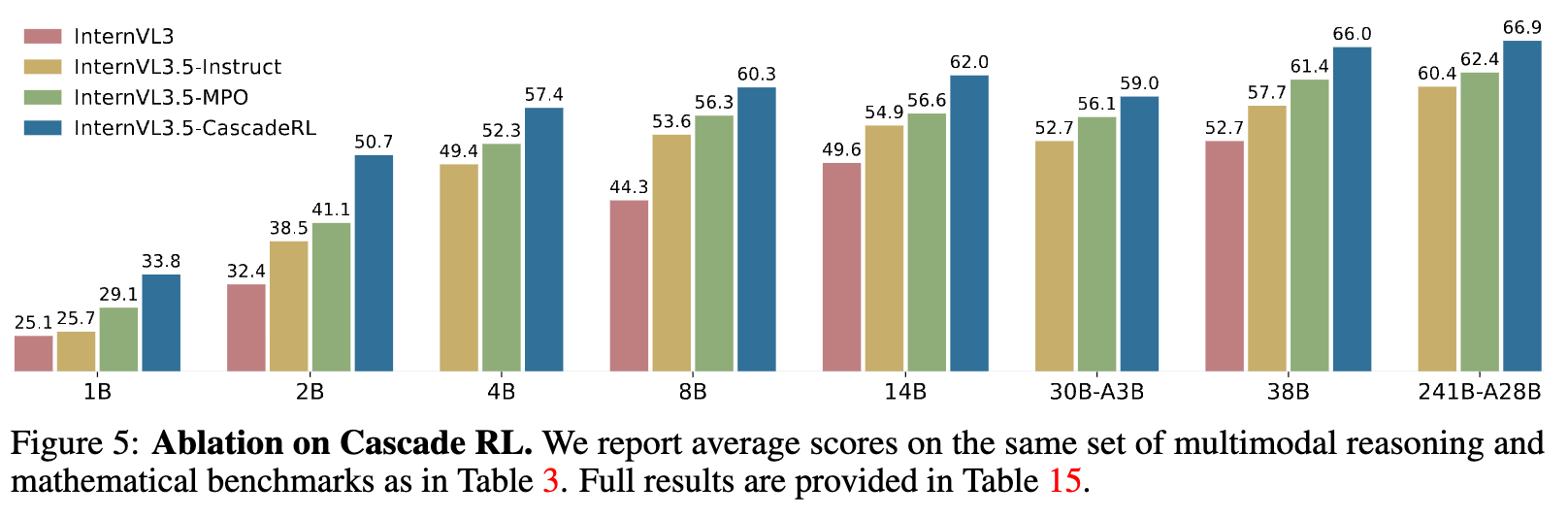
实验结果(如图 5 所示)清晰地展示了 Cascade RL 的有效性。从 SFT 后的 Instruct 模型,到经过 MPO 优化的模型,再到最终经过 Cascade RL 完整流程训练的模型,在各个模型尺寸上,其推理能力(以多个推理基准的平均分衡量)都得到了逐级、显著的提升。例如,在 8B 模型上,Instruct 版本的评分为 53.6,MPO 版本提升至 56.3,而完整的 Cascade RL 版本则达到了 60.3。这充分证明了 Cascade RL 框架在提升模型推理能力方面的有效性、稳定性和可扩展性。
3. 提升推理效率的技术创新
除了追求更高的性能,InternVL3.5 也投入了大量的精力来优化模型的推理效率,使其在实际应用中更具可行性。为此,团队提出了两项核心技术:视觉分辨率路由器(Visual Resolution Router, ViR)和解耦的视觉-语言部署(Decoupled Vision-Language Deployment, DvD)。而 ViR 的集成则依赖于一个额外的训练阶段——视觉一致性学习(Visual Consistency Learning, ViCO)。
3.1 视觉分辨率路由器(ViR)与视觉一致性学习(ViCO)
背景与动机:多模态模型在处理高分辨率图像时,通常会将其切割成多个图像块(patches),每个图像块会被编码成一定数量的视觉词元(visual tokens)。更多的视觉词元意味着更精细的图像信息,但也带来了更高的计算开销。然而,并非图像的每个区域都包含同等重要的信息。例如,一张图片中的大片蓝天或纯色背景,其信息密度远低于包含复杂文字或物体的区域。动态高分辨率策略虽然可以根据图像尺寸调整切块数量,但它并未考虑图像内容的语义信息。
基于此,InternVL3.5 提出了 ViR,一个能够根据图像块的语义丰富度动态决定使用高分辨率还是低分辨率表示的模块。其目标是在不显著牺牲性能的前提下,尽可能减少送入语言模型的视觉词元数量。集成了 ViR 的模型版本被称为 InternVL3.5-Flash。
ViCO 训练流程:为了让模型能够在不同分辨率的视觉输入下保持输出的一致性,并成功训练 ViR 这个“路由器”,团队设计了 ViCO 训练流程,它包含两个阶段:
-
一致性训练(Consistency Training):
在这个阶段,模型被训练来最小化其在看到高分辨率视觉词元和低分辨率视觉词元时,输出分布的差异。具体来说,每个图像块可以被表示为 256 个词元(高分辨率,压缩率 )或 64 个词元(低分辨率,压缩率 )。训练时,会随机选择一个压缩率,并要求模型的输出分布尽可能接近一个固定的、始终使用高分辨率输入的参考模型(reference model)的输出分布。
训练目标是最小化两者输出分布之间的 KL 散度:其中, 是以压缩率 表示的图像, 是压缩率的采样集合 。通过这种方式,模型学会了即使在输入信息被压缩(使用 64 个词元)的情况下,也能生成与未压缩时(使用 256 个词元)相似的回答。
-
路由器训练(Router Training):
在模型具备了处理不同分辨率输入的能力后,就需要训练 ViR 来智能地为每个图像块选择合适的分辨率。ViR 被实现为一个二元分类器。为了得到训练 ViR 所需的标签(即每个图像块应该被压缩还是不被压缩),团队设计了一种巧妙的方法:
首先,计算每个图像块在被压缩后,对模型输出造成的损失增加程度。这个损失增加的比率 定义为:其中 表示第 个图像块。这个比率 量化了压缩对这个特定图像块信息的损害程度。如果 很大,说明压缩导致了严重的性能下降,这个图像块很重要,不应该被压缩。反之,如果 很小,说明压缩影响不大,可以安全地使用低分辨率表示。
然后,根据这个比率 和一个动态阈值 ,为每个图像块生成一个二元标签 :这个动态阈值 是根据历史 值的 -百分位数计算得出的,以确保训练标签的平衡。在训练 ViR 时,主模型(ViT, MLP, LLM)的参数被冻结,只更新 ViR 分类器的参数。
数据方面,路由器训练主要使用 OCR 和 VQA 样本,因为这些任务通常包含丰富的视觉信息,需要高分辨率的理解,非常适合训练路由器学习如何区分信息密集区域。
通过 ViCO 训练,InternVL3.5-Flash 能够在推理时,由 ViR 动态决定每个图像块的压缩率,平均减少 50% 的视觉词元数量,同时保持接近 100% 的原始模型性能,实现了效率与性能的平衡。
3.2 解耦的视觉-语言部署(Decoupled Vision-Language Deployment, DvD)
背景与动机:在传统的多模态模型推理部署方案中,视觉编码器(如 ViT)和语言模型(LLM)通常串行执行,部署在同一个或同一组 GPU 上。然而,这两部分的计算特性截然不同:
-
视觉编码器:处理图像,计算密集,高度可并行化,且不依赖历史状态。 -
语言模型:自回归生成文本,计算过程是序列化的,对内存带宽和延迟敏感。
当两者串行执行时,尤其是在处理高分辨率或多张图像导致视觉计算量大增时,视觉编码器的计算会阻塞语言模型的执行,造成 GPU 资源的等待和浪费,从而降低了整体的推理吞吐量和响应速度。
为了解决这个问题,InternVL3.5 提出了 DvD 框架,将视觉处理和语言处理解耦,部署在不同的服务器(或 GPU 集群)上。
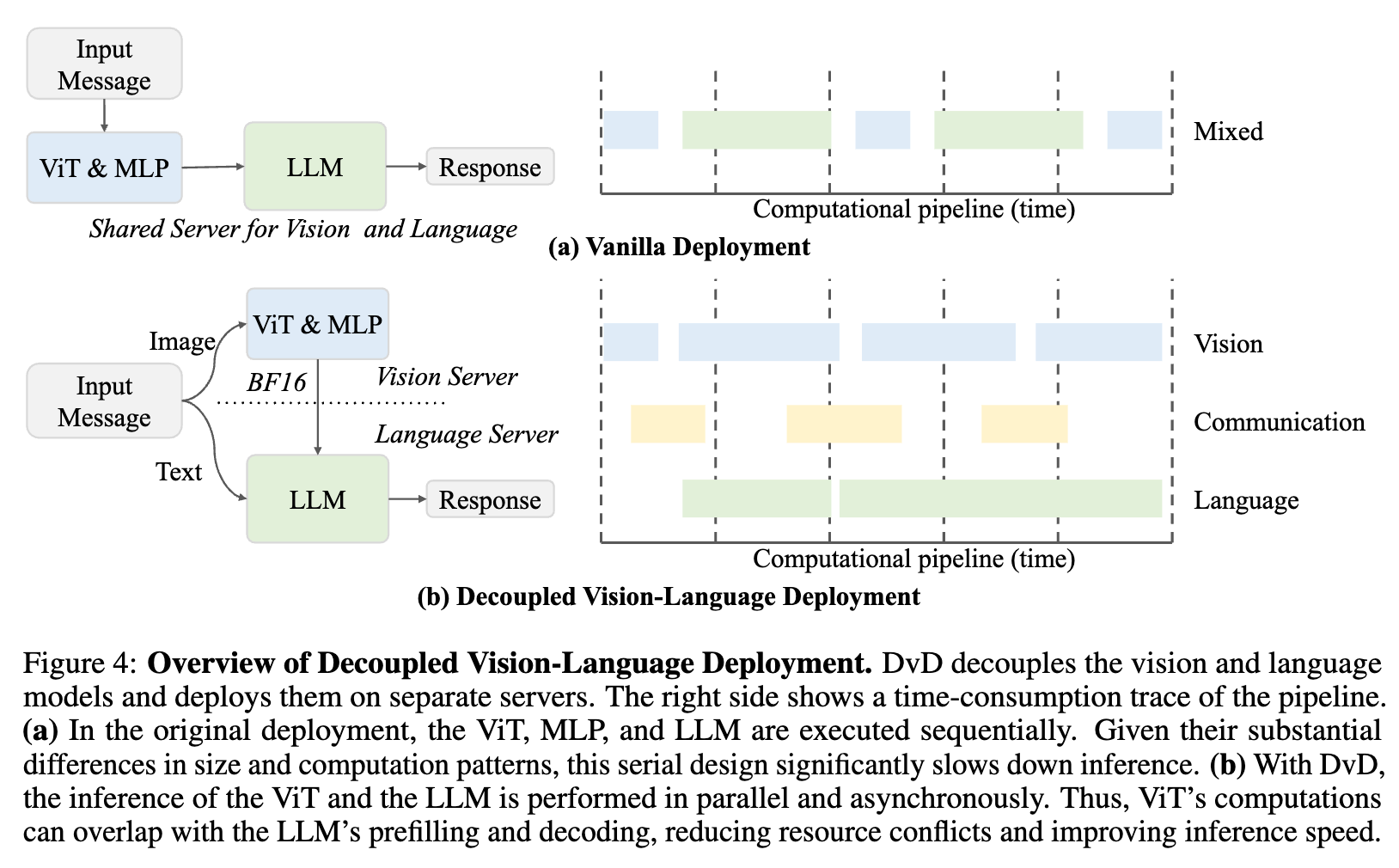
DvD 工作流程:
-
并行处理:当一个多模态请求到达时,图像和文本被分发到不同的服务。视觉服务器上的 ViT 开始处理图像,同时语言服务器上的 LLM 开始处理文本提示(prefilling 阶段)。 -
异步通信:视觉服务器将图像编码成的紧凑特征嵌入(feature embeddings),通过网络(如 TCP,可选 RDMA 加速)异步地传输给语言服务器。 -
特征融合与解码:语言服务器在完成文本 prefilling 后,会接收到视觉特征,并将其与文本上下文融合,然后开始自回归解码,生成最终的回复。
DvD 带来的优势:
-
提升 GPU 利用率:通过将视觉和语言的计算并行化,ViT 的计算可以与 LLM 的 prefilling 阶段重叠,减少了等待时间,提高了两侧 GPU 的利用率和处理效率。 -
优化系统吞吐量和响应:解耦的设计避免了视觉计算对语言生成的阻塞,从而提高了系统的整体吞-吐量和对用户请求的响应速度。 -
独立的硬件优化:视觉和语言模块可以根据其不同的计算特性,选择最适合的硬件进行部署和优化,例如为视觉服务器配置计算密集型 GPU,为语言服务器配置高带宽内存的 GPU。 -
部署灵活性:新的视觉模块或语言模块可以无缝集成到系统中,而无需修改对方的部署,提高了系统的可扩展性和可维护性。
如表 18 所示,DvD 带来了显著的推理加速。例如,对于 InternVL3.5-38B 模型,在处理 1344x1344 分辨率的图像时,使用 DvD 可以将吞吐量提升 1.97 倍。而当 DvD 与 ViR 结合使用时,加速效果更为显著,最高可达 4.05 倍。这证明了 DvD 框架在优化大规模多模态模型实际部署效率方面的巨大价值。

四、 测试时扩展(Test-Time Scaling, TTS):进一步挖掘推理潜力
为了在处理复杂推理任务时进一步提升模型的性能,InternVL3.5 还实现了一套全面的测试时扩展(TTS)策略。TTS 不改变模型参数,而是在推理阶段通过增加计算量来换取更好的结果。需要注意的是,除非特别说明,论文中报告的大部分实验结果并未启用 TTS。TTS 主要应用于对性能要求高的推理基准测试上。
InternVL3.5 的 TTS 策略包含两个方面,分别从推理的深度和广度上进行增强:
4.1 深度思考(Deep Thinking)
通过激活“Thinking”模式,模型被引导在生成最终答案之前,先进行一步一步的链式思考。这个过程类似于人类解决复杂问题时的草稿演算,模型会显式地分解问题、列出逻辑步骤并验证中间结论。这种方法系统性地改善了复杂问题解决方案的逻辑结构,特别是对于需要多步推理的任务,能够显著提升推理的深度和可靠性。
4.2 并行思考(Parallel Thinking)
并行思考借鉴了 Best-of-N(BoN)策略。在推理时,模型针对同一个问题生成 N 个不同的候选答案(或推理路径)。然后,利用一个独立的、更小的“评判”模型(critic model),在 InternVL3.5 中使用的是 VisualPRM-v1.1,来对这 N 个候选答案进行打分和评估,并选出最优的一个作为最终输出。这种方法通过探索多个可能性,增加了找到正确答案的概率,从而提升了推理的广度。
通过深度思考和并行思考的结合,InternVL3.5 能够在不重新训练的情况下,在推理阶段动态地提升其在复杂任务上的表现,展现了其强大的潜力。
往期文章:


