以思维链(Chain-of-Thought, CoT)为代表的技术,通过让模型在给出最终答案前,先生成一系列中间推理步骤,极大地增强了模型的透明度和推理能力。
然而,这种“过程透明化”也带来了新的挑战:我们如何判断这些中间步骤的逻辑有效性?仅仅依赖最终答案的正确与否(即“结果导向奖励”)是远远不够的。
为了解决这个问题,研究界提出了“过程奖励模型”(Process Reward Models, PRMs)。它的核心思想是,不对整个推理过程只给一个总分,而是对每一个中间步骤进行打分。
但是,当前的过程奖励模型普遍存在两大核心局限:
-
“黑盒”分类器:大多数 PRMs 的工作方式类似于一个分类器,它们对一个推理步骤只能给出一个简单的分数或标签(例如“正确”或“错误”),却无法解释为什么这个步骤是错的。这种反馈信息量有限,对于模型的深入修正和我们对模型行为的理解都帮助不大。 -
依赖静态监督数据:这些模型通常依赖于通过监督微调(Supervised Fine-Tuning, SFT)在静态数据集上进行训练。这些数据集的构建成本高昂(通常需要大量人工标注),且难以覆盖所有可能的推理模式。因此,模型容易在训练数据上过拟合,泛化能力受限,遇到新的推理路径时便可能束手无策。
面对这些挑战,来自 Meta FAIR、UIUC 和 NYU 的研究团队发表了一篇名为《STEPWISER: STEPWISE GENERATIVE JUDGES FOR WISER REASONING》的论文。该研究提出了一个全新的框架,旨在从根本上改变我们监督模型推理过程的方式。它的核心思想是:将对推理步骤的“评判”本身,也重新定义为一个“推理”任务。

-
论文标题:STEPWISER: STEPWISE GENERATIVE JUDGES FOR WISER REASONING -
论文链接:https://arxiv.org/abs/2508.19229
这篇论文引入了一个名为 STEPWISER 的“逐步生成式评判”(stepwise generative judge)。这个“评判”模型在对另一个模型(称为“策略模型”)的推理步骤做出最终裁决之前,会首先生成一段自己的分析和推理(即“元推理”或“元认知”),解释它为什么认为这一步是对是错。更重要的是,这个“评判模型”是通过强化学习(Reinforcement Learning, RL)在线训练的,使其能够不断适应和泛化。
1. 背景
在深入 STEPWISER 的技术细节之前,我们有必要先理解它所要解决的问题的根源,以及现有方法的不足之处。
1.1 从思维链(CoT)到对过程的监督
思维链(CoT)的出现,是 LLM 发展史上的一个重要节点。它让模型的“思维”过程从一个完全的黑箱,变得部分可见。当我们给模型一个问题,比如:“一个农场里有15只鸡和12头猪,请问一共有多少条腿?”
-
没有 CoT 的模型可能直接输出:“108条腿。” 我们不知道它是如何计算的。 -
有 CoT 的模型会输出:“好的,我们来计算一下。鸡有2条腿,所以15只鸡有 15 * 2 = 30条腿。猪有4条腿,所以12头猪有 12 * 4 = 48条腿。总共有 30 + 48 = 78条腿。所以答案是78。”
这个过程的展示,为我们监督和干预模型的推理提供了可能。于是,两种主要的奖励模型应运而生:
-
结果奖励模型 (Outcome Reward Models, ORMs) :只关心最终答案。在上面的例子中,只要最终答案是78,ORM 就会给出正向奖励。这种方式简单直接,但正如前文所述,它无法区分“侥幸正确”和“逻辑严谨”。 -
过程奖励模型 (Process Reward Models, PRMs) :关心每一个中间步骤。它会检查“15 * 2 = 30”是否正确,“12 * 4 = 48”是否正确,以及“30 + 48 = 78”是否正确。任何一步出错,PRM 都能识别并给出反馈。这显然是一种更精细、更有效的监督方式。Lightman 等人在2023年的研究首次证明,经过过程监督的模型在指导 best-of-n 采样时,性能显著优于结果监督的模型。
1.2 当前过程奖励模型(PRM)的局限性
尽管 PRM 的理念先进,但实践中的主流方法却存在着难以回避的缺陷。
局限一:无法自证其明的“黑盒”分类器
当前大多数 PRM 的架构本质上是一个分类器。它接收一个推理步骤作为输入,然后输出一个预定义的标签,比如一个代表“好”的 + token 或一个代表“坏”的 - token。虽然这个标签可以用来训练策略模型,但它本身是不透明的。
想象一下,一个模型在解一道复杂的微积分题目时,其中一步写道:“应用分部积分法,我们得到...”。如果一个 PRM 仅仅标记这一步为“错误”,我们无从知晓问题到底出在哪里:是模型根本不应该用分部积分法?还是公式用错了?抑或是计算出现了偏差?
这种“知其然,而不知其所以然”的反馈,使得调试和改进模型变得困难。我们希望得到的反馈更像是:“这一步应用分部积分法的思路是正确的,但是你在计算积分时遗漏了一个负号,导致结果错误。” 这种带有解释性的反馈,对于模型的学习效率和最终性能至关重要。
局限二:静态SFT
构建 PRM 的传统方法是监督微调(SFT)。这需要一个带有步骤级别标注的数据集。例如,著名的 PRM800K 数据集就包含了大量由人类标注员为每个推理步骤打上的标签。
这种方法的弊端显而易见:
-
成本高昂:为大规模、多样化的推理任务进行细致的人工标注,是一项耗时耗力的工作,成本高,通常只有大型研究机构能够承担。 -
泛化性差:静态数据集的内容是有限的。模型在学习时,可能会记住或过拟合数据集中的特定推理模式。当遇到一个全新的、在训练集中前所未见的推理路径时,模型的判断能力就可能急剧下降。推理的世界是广阔且充满变化的,试图用一个固定的数据集去穷尽所有的可能性,无异于刻舟求剑。
因此,研究界迫切需要一种新的方法,它既能提供可解释的反馈,又能摆脱对大规模静态标注数据的依赖,从而实现更好的泛化能力。STEPWISER 正是在这样的背景下应运而生,它试图用一种“以子之矛,攻子之盾”的思路,让模型学会自我监督。
2. STEPWISER 方法详解
STEPWISER 的整体框架可以概括为三个核心阶段:首先,教会策略模型如何有意义地“断句”,将其连续的思维链切分成逻辑连贯的“思维块”;其次,设计一套自动化流程,为这些“思维块”的优劣进行标注;最后,利用这些标注数据,通过强化学习训练一个能够生成推理式评判的评判模型。
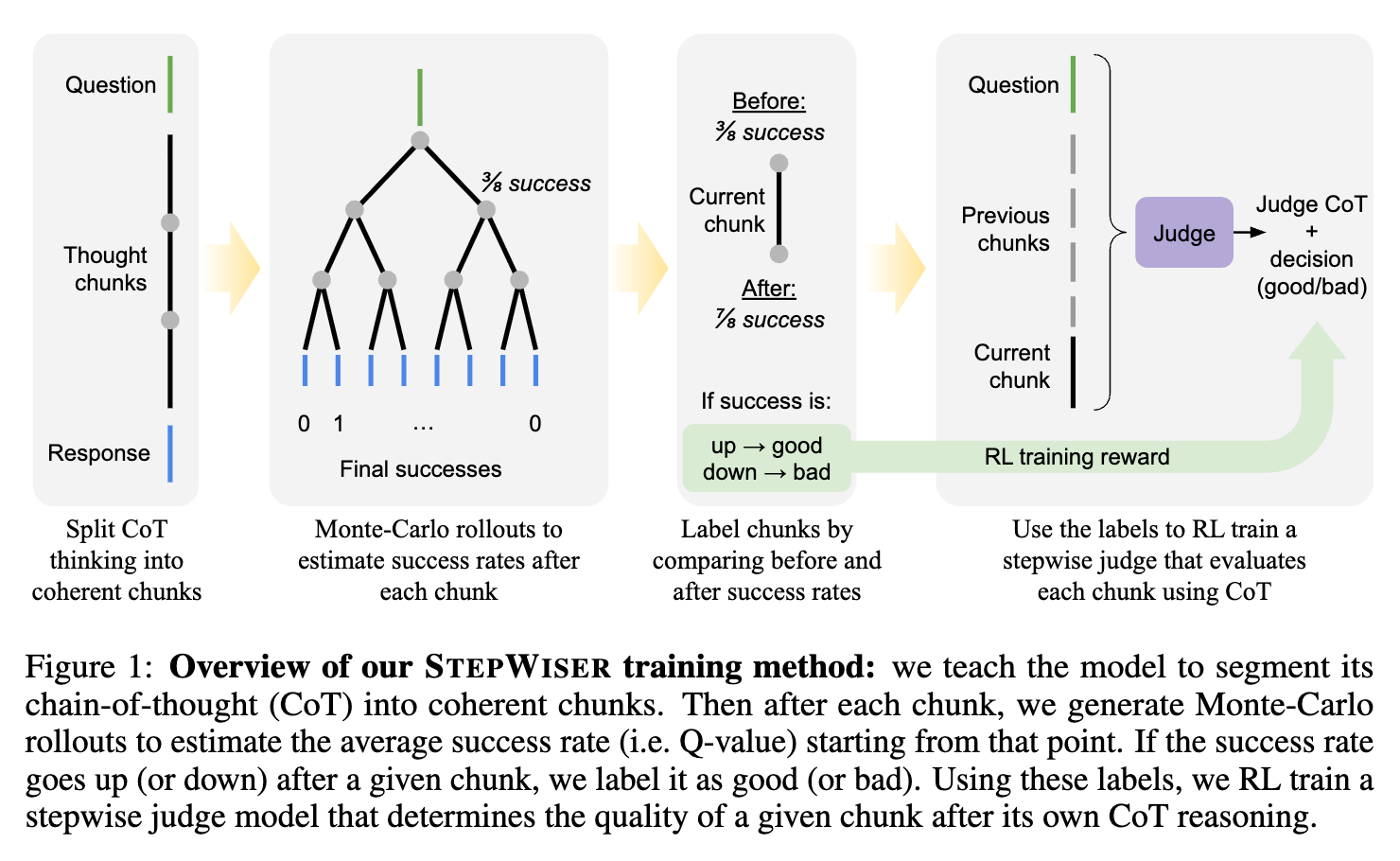
上图直观地展示了整个流程,下面我们将对每个阶段进行详细的拆解。
2.1 第一步:思维链的切分
在评价一个推理过程之前,我们首先要定义什么是“一个步骤”。传统的 PRM 通常采用简单粗暴的启发式规则,比如根据换行符 \n\n 来切分步骤。这种方法看似简单,但往往会导致逻辑上的割裂。
一个完整的逻辑单元,可能会因为排版习惯被 \n\n 切割成三个毫无意义的片段。这样的片段信息不完整,让评判模型难以独立地进行有效评估。

为了解决这个问题,STEPWISER 提出了一种 “自分割”(self-segmentation) 的方法,旨在让策略模型自己学会生成逻辑上完整且信息丰富的推理单元,论文中称之为 “思维块”(Chunks-of-Thought)。
其具体实现过程如下:
-
定义高质量“思维块”的标准:首先,研究者制定了一套清晰的规则,用于指导如何将一个完整的 CoT 分割成高质量的“思维块”:
-
目标统一(Unified purpose):每个“块”应该只服务于一个明确的目标,比如建立一个方程、完成一次独立的计算、或陈述一个结论。 -
逻辑内聚(Logical Cohesion):一个“块”内的所有句子必须形成连续且不间断的逻辑流。当推理的焦点或目的发生转换时,就应该开始一个新的“块”。 -
清晰过渡(Clear Transition):当解题过程进入一个新阶段时(例如,从“求解变量”过渡到“验证答案”),必须开启一个新的“块”。
-
-
构建自分割 SFT 数据集:研究者们使用一个强大的教师模型(如论文中使用的 Llama-3.1-70B),让它遵循上述规则,将一批已有的、正确的 CoT 推理样本自动地进行分割,并用
<chunk>...</chunk>标签包裹起来。这样就自动构建了一个用于微调的“自分割”数据集。 -
微调基础模型:最后,用这个新构建的数据集来微调基础的策略模型。经过微调后,这个策略模型就获得了“自分割”的能力,它在生成 CoT 时,会自然而然地将自己的推理过程组织成一个个逻辑连贯的“思维块”。
这种方法带来了两个显著的好处:
-
提升了评估单元的质量:“思维块”比按换行符分割的片段信息更完整、逻辑更清晰,为后续评判模型的准确评估提供了坚实的基础。 -
降低了后续计算成本:由于每个“思维块”承载了更丰富的逻辑内容,整个推理轨迹的总“块”数显著减少(例如,在实验中,1.5B 模型的平均步骤数从9.6降至6.0)。我们将在下一节看到,为每个步骤进行标注的成本高,因此减少步骤总数可以直接节省大量的计算资源和时间。
2.2 第二步:为“思维块”打标签
现在我们有了一系列逻辑连贯的“思维块”,下一步就是为它们分配一个质量标签(比如“好”或“坏”),以便后续训练评判模型。考虑到人工标注的巨大成本,STEPWISER 采用了一种基于蒙特卡洛(Monte Carlo) rollout 的全自动化标注流程。
其核心思想是估计每个推理步骤的 Q-value。在强化学习中,Q-value (Q值) 通常指在某个状态下采取某个动作后,未来能够获得的期望总回报。在这里,研究者将其概念迁移过来:一个推理“思维块”的 Q-value,就是从这个“块”开始继续推理,直到最终能够得到正确答案的期望概率。
一个好的“思维块”应该能够维持或提升解题的成功率,而一个坏的“思维块”则会降低成功率。
具体的估算过程如下:对于一个给定的问题和已经生成到第 个“思维块” 的推理历史 ,模型会从这里开始,独立地、随机地(通过采样)生成 次完整的后续推理过程(rollouts)。然后,统计这 次中有多少次最终得到了正确的答案。这个比例,就是对 Q-value 的一个估计。
其中, 是最终奖励函数(答案正确为1,错误为0), 是 rollout 的次数(论文中为16)。
有了 Q-value 的估计值,接下来的问题就是如何根据它来定义“好”与“坏”的标签。论文探索了三种不同的标注策略,这三种策略的差异体现了对“什么是一个好步骤”的不同理解。
2.2.1 绝对质量评估:Abs-Q (Absolute Q value thresholding)
这是最直观的一种方法。如果一个步骤执行后,未来成功的概率大于零,那么就认为它是一个“好”步骤。
-
优点:简单明了。只要推理没有走上“绝路”(成功率为0),就给予肯定。 -
缺点:对“进步”不敏感。它无法区分一个将成功率从10%提升到50%的优秀步骤,和一个将成功率从60%降低到55%的平庸步骤。只要最终的成功率不为零,它们都会被标记为“好”,这显然不够精细。
2.2.2 奖励“进步”:Rel-Effective (Relative Effective Reward Thresholding)
为了解决 Abs-Q 的问题,研究者引入了更能体现“进步”的标注方法。这种方法的核心是结合了 Q-value 和优势函数(Advantage Function)。优势函数 定义为执行步骤 之后的新 Q-value 与执行前 Q-value 的差值,即 。它直接衡量了当前步骤 带来了多大的“提升”。
标签的分配基于一个“有效奖励”的判断,即 Q-value 和优势函数的一个加权组合。
其中 是一个超参数,用于平衡绝对质量和相对进步的重要性。这种方法不仅关注当前是否在正确的道路上,更关注是否在向着正确的方向前进。
2.2.3 相对改进评估:Rel-Ratio (Relative Ratio)
这是一种更简洁地捕捉相对改进思想的方法。它直接计算当前步骤之后和之前的 Q-value 的比率。
其中 是一个阈值(例如0.8)。这个公式的含义是:只要当前步骤没有让成功率出现大幅下降(例如,下降超过20%),就认为它是一个“好”的步骤。这种方法同样鼓励模型取得进步,或者至少保持稳定。
后续的实验表明,后两种奖励“进步”的相对信号(Rel-Effective 和 Rel-Ratio),在训练评判模型时,通常比只看绝对值的 Abs-Q 信号更有效。
2.3 第三步:训练评判模型
拥有了带标签的“思维块”数据后,我们就可以开始训练我们的核心——STEPWISER评判模型了。与传统方法不同,STEPWISER 并没有将这个任务当作一个简单的分类任务来处理。
2.3.1 任务设定:从“分类”到“推理”的范式转变
STEPWISER 的核心创新在于,它将“评判”本身定义为一个生成式的推理任务。
-
传统方法(判别式):输入 [问题, 历史, 待评估块]-> 输出[+]或[-]。 -
STEPWISER 方法(生成式):输入 [问题, 历史, 待评估块]-> 输出[分析过程 CoT]... [最终结论]。

如上表所示,评判模型被要求首先进行一步一步的分析(Analysis),验证待评估块的逻辑、方法和计算,明确指出其中可能存在的错误。在完成这段“元推理”之后,再给出一个装在方框里的最终判断(Final Judgment),如 \boxed{Positive} 或 \boxed{Negative}。
这种设计的精妙之处在于:
-
强制模型“思考”:它迫使评判模型必须“说出理由”,而不能凭感觉“投票”。这充分利用了 LLM 本身的强大推理能力。 -
提升透明度和可解释性:输出的分析过程 CoT 为我们理解评判的决策提供了清晰的窗口,使其不再是一个黑盒。 -
提供更丰富的学习信号:对于模型本身而言,生成一段有理有据的文本,比单纯输出一个 +/-token,是更复杂也更具结构性的任务,这有助于其学习到更鲁棒的评判能力。
2.3.2 关键技巧:提示数据集的平衡
这是实践中一个至关重要但又常常被忽视的细节。通过第二步的自动化标注流程得到的数据,正负样本的比例往往是不均衡的。例如,在一个相对简单的任务上,一个不错的策略模型可能 70% 以上的步骤都是正确的。
如果直接用这样不均衡的数据进行训练,模型会迅速“退化”,因为它会发现一个投机取巧的捷径:无论输入是什么,一概预测为“Positive”,就能获得较高的平均准确率。这对于需要模型具备辨别能力的 RL 训练是致命的。
因此,STEPWISER 在方法中明确加入了数据集平衡这一步:在训练时,通过降采样(down-sample)多数类(通常是正样本),使得正负样本的比例达到 1:1 的平衡状态。实验证明,这一步对于保证 RL 训练的稳定性和最终模型的性能至关重要。
2.3.3 奖励与强化学习训练
训练的信号直接和直观。对于每一个评判任务,评判模型会生成自己的分析和最终结论。
-
如果最终结论( Positive或Negative)与第二步中由蒙特卡洛 rollout 产生的标签 一致,则评判模型获得奖励 1。 -
如果不一致,则获得奖励 0。
研究者使用 GRPO (Generalized Reward Policy Optimization) 算法,根据这个奖励信号对评判模型进行在线的强化学习训练。在线学习意味着模型可以不断地与策略模型互动,看到新的推理路径并从中学习,这使得它比依赖静态数据集的离线 SFT 方法具有好得多的泛化潜力。
通过这三个环环相扣的步骤,STEPWISER 成功地构建了一个会“思考”、能“解释”、并且通过在线学习不断进化的“生成式评判模型”。
3. 实验与结果分析
3.1 基准测试:在 ProcessBench 上的压倒性优势
为了评估“评判模型”准确识别推理错误的能力,研究者们在 ProcessBench 这个权威基准上进行了测试。ProcessBench 是一个专门用于评测模型定位推理过程中第一个错误步骤能力的数据集,其标注由人类专家完成,覆盖了 GSM8K、MATH 等多个数学数据集。
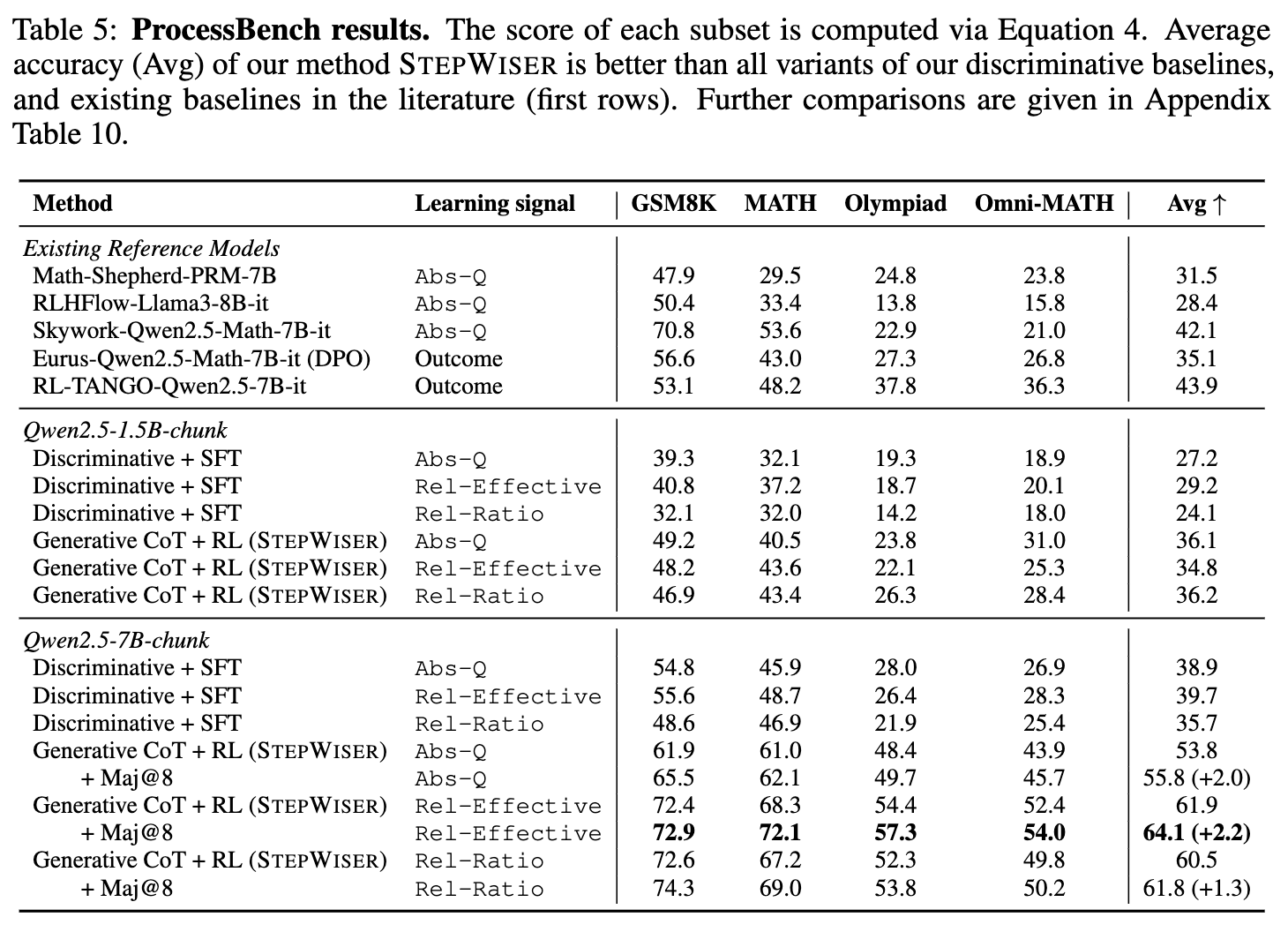
实验结果(如 Table 5 所示)清晰地揭示了几个关键信息:
-
STEPWISER 显著优于 SFT 判别式基线:无论是 1.5B 还是 7B 规模的模型,也无论使用哪种学习信号(Abs-Q, Rel-Effective, Rel-Ratio),STEPWISER 的 RL 训练生成式评判模型都远远超过了传统的 SFT 训练判别式模型。以 7B 模型和 Rel-Effective 信号为例,STEPWISER 的平均分达到了 61.9,而 SFT 基线只有 39.7,差距巨大。这证明了“生成式推理 + 在线RL”的组合是一种更有效的策略。 -
STEPWISER 优于其他 RL 训练的模型:论文还与其他一些同样使用 RL 训练的开源模型进行了比较,例如 Eurus-7B 和 RL-TANGO-7B。这些模型的共同点是,它们虽然也用 RL,但其监督信号是稀疏的、基于最终结果的(Outcome-level)。结果显示,STEPWISER(最优 61.9)同样大幅领先于它们(RL-TANGO 为 43.9)。这有力地证明了,STEPWISER 所使用的那种密集的、步骤级别的(step-level)监督信号,比稀疏的、轨迹级别的(trajectory-level)信号,是更丰富、更有效的学习信号。
3.2 消融实验
为了进一步探究 STEPWISER 性能提升的来源,研究者进行了一系列消融实验,即分别去掉方法中的某个关键组件,观察性能会受到多大影响。
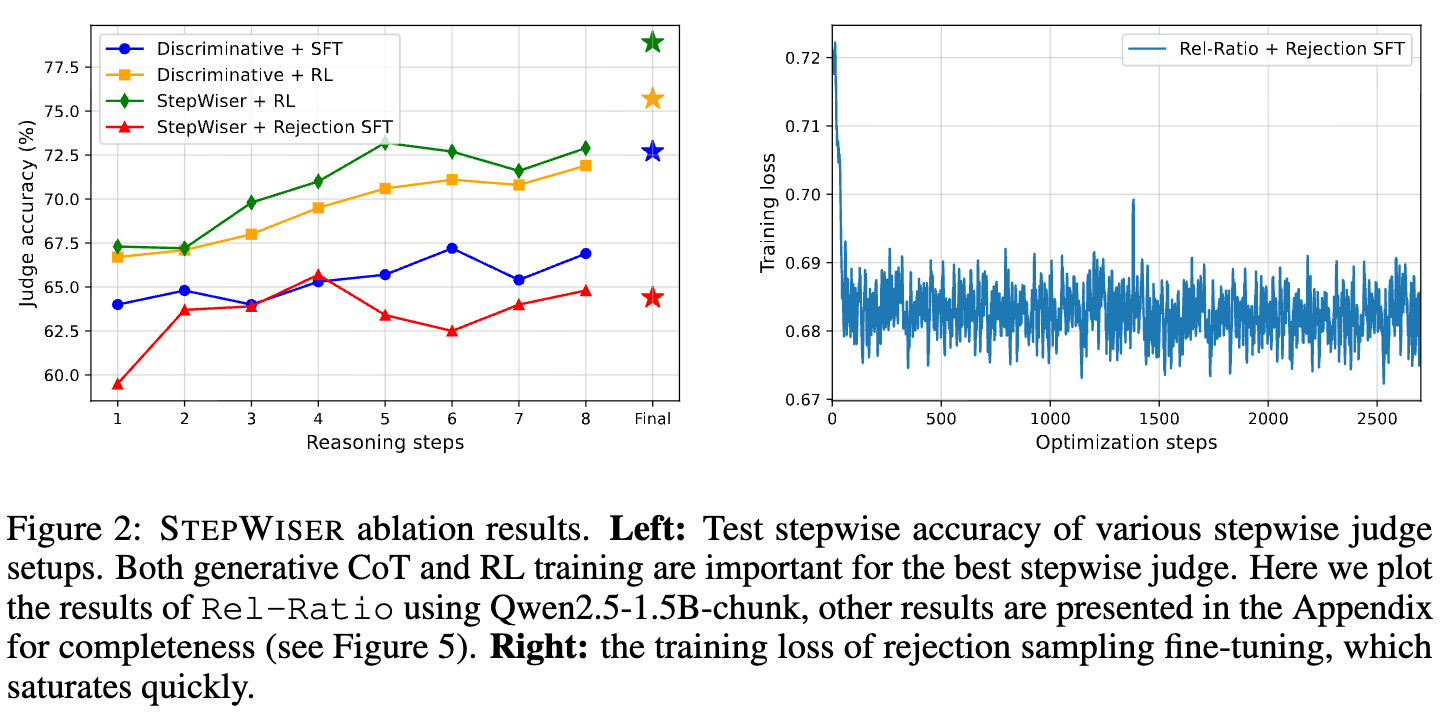
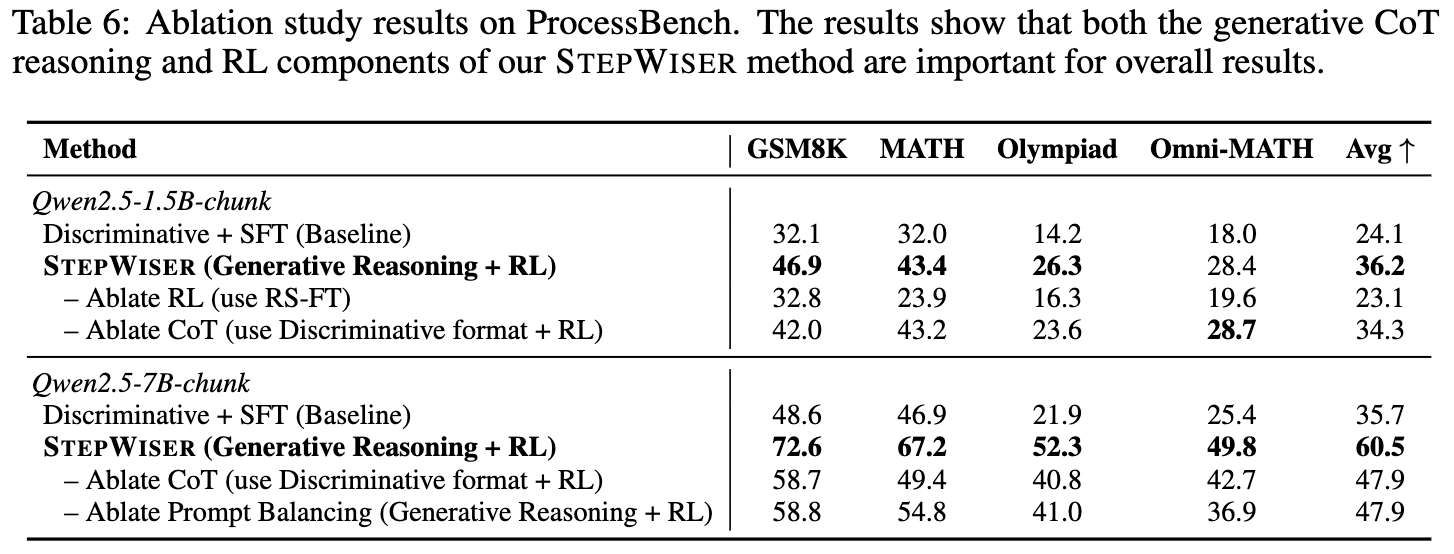
实验结果(Table 6)验证了 STEPWISER 设计中每个环节的必要性:
-
在线 RL (Ablate RL) :当把在线 RL 训练换成离线的“拒绝采样微调”(RS-FT)后,模型性能出现断崖式下跌,甚至不如最基础的 SFT 判别式基线。从训练曲线(Figure 2 右图)可以看出,离线方法的训练损失较快就饱和了,无法从庞大的静态数据中学习到复杂的评判逻辑。这表明,在线学习对于捕捉奖励建模的复杂性至关重要。 -
生成式 CoT (Ablate CoT) :如果去掉生成式 CoT,让模型直接输出判决(即一个判别式模型,但用 RL 训练),性能虽然比 SFT 有所提升,但仍然远低于完整的 STEPWISER。这说明,生成评判理由(元推理)的过程本身,调用和增强了模型内在的推理能力,从而做出了更准确的判断。对于更强大的 7B 模型,这种优势更加明显,因为更强的基础模型意味着更强的元推理能力。 -
数据平衡 (Ablate Prompt Balancing) :如果不进行提示数据集的平衡,模型的性能同样会大幅下降(从 60.5 降至 47.9)。深入分析发现,其失败模式与“Ablate CoT”不同。不平衡的数据集会让模型变得“乐观”,它会倾向于将任何步骤都判断为“正确”,从而丧失了识别错误的能力。
这些消融实验证明了 STEPWISER 的成功并非偶然,而是其三大核心设计——在线RL、生成式CoT、数据平衡——协同作用的结果。
3.3 实际应用
一个好的评判模型,其最终价值体现在能否帮助策略模型(“学生”)提升其自身的解题能力。论文从两个实际应用场景验证了 STEPWISER 的实用价值。
3.3.1 应用一:推理时搜索与自我修正(Chunk-Reset Reasoning)
这是一种在推理时利用评判进行动态纠错的策略。策略模型逐“块”地生成其解题思路。每生成一个“块”,STEPWISER评判模型就立即对其进行评判。
-
如果评判为“好”,则接受该“块”,继续生成下一步。 -
如果评判为“坏”,则抛弃这个有问题的“块”,然后让策略模型从上一个节点重新生成一个不同的“块”(最多尝试5次)。
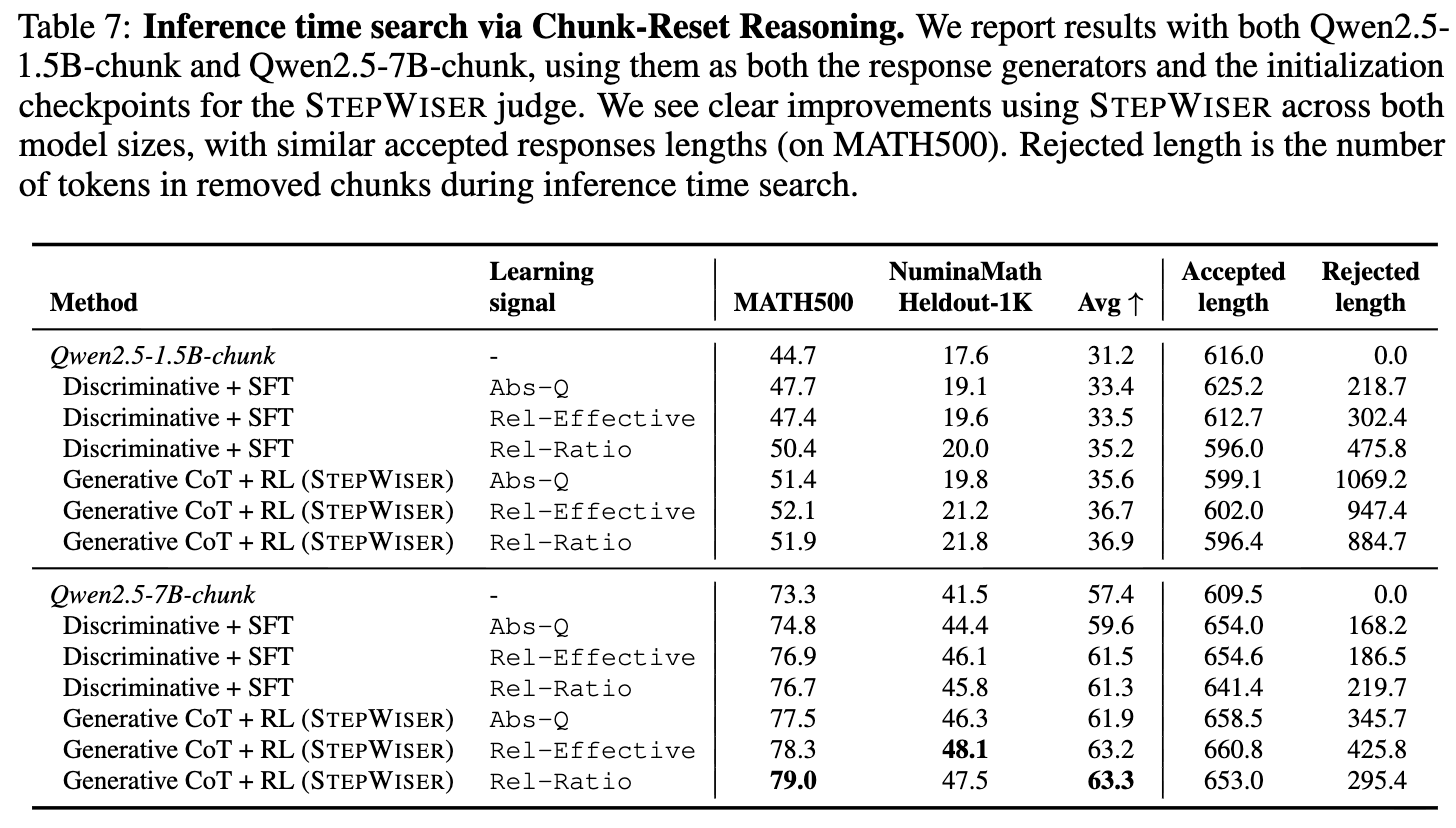
实验结果(Table 7)显示,在 STEPWISER 的指导下,无论模型大小,最终的解题准确率都得到了稳定提升。特别值得关注的是 "Rejected Length" 这一列,它记录了在推理过程中被评判模型拒绝并抛弃的 token 总长度。这个数值越高,说明评判模型识别并修正了越多的潜在错误,这直接证明了 STEPWISER 卓越的错误检测能力。
3.3.2 应用二:高质量训练数据的筛选
这是在模型训练阶段的应用。我们知道,通过让模型自己生成大量答案,然后从中挑选出最好的部分来对自己进行微调(Rejection Sampling Fine-tuning),是一种提升模型能力的常用技巧。但如何定义“最好”的答案呢?
传统方法通常只看最终答案是否正确。但这又回到了老问题:很多答案虽然最终结果对了,但过程可能存在瑕疵。STEPWISER 提供了一种更精细的筛选标准:对于一个完整的解题过程,用评判模型为它的每一个“思维块”打分,然后计算平均分。这个平均分可以更全面地反映整个推理过程的质量。
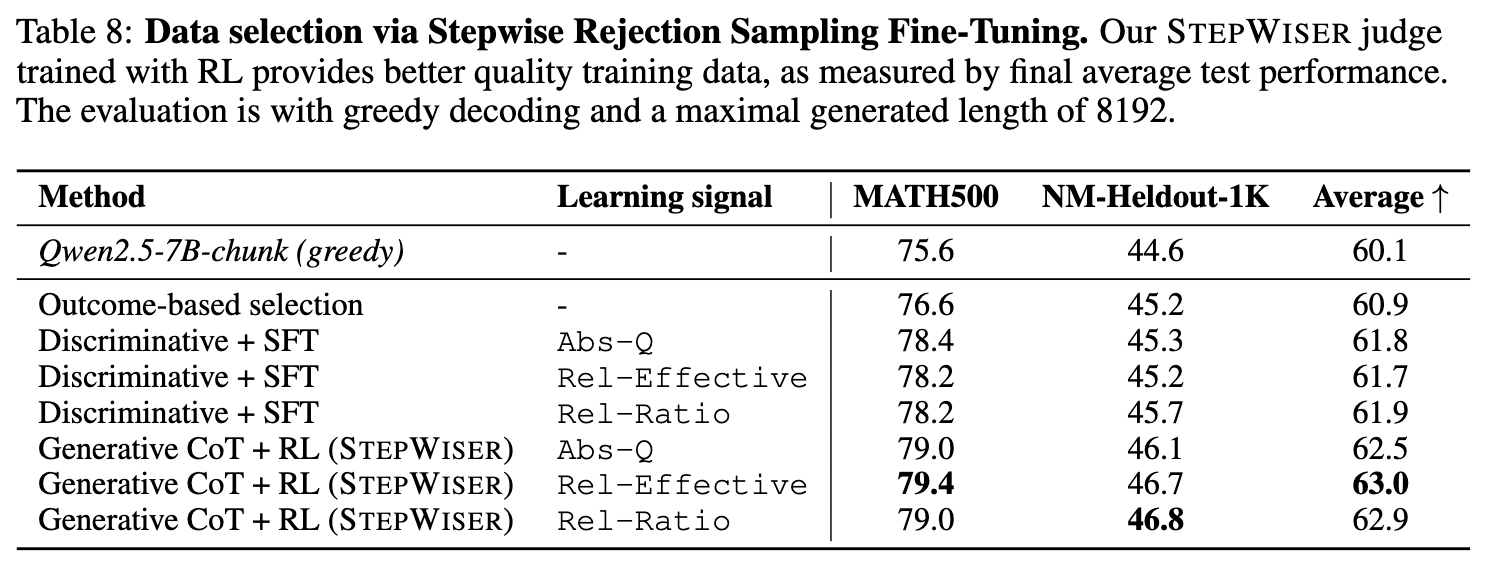
实验结果(Table 8)再次证明了 STEPWISER 的优越性。使用 STEPWISER 筛选出的数据进行微调的模型,其最终性能超过了所有基线方法,包括使用原始模型、使用结果导向筛选,或使用判别式模型进行筛选的模型。这说明,一个好的过程监督评判模型,是生产高质量训练数据的利器。
3.4 奖励“进步”比评判“绝对好坏”更有效
在所有的实验表格中,我们可以观察到一个一致的模式:使用相对信号(Rel-Effective 和 Rel-Ratio)训练出的评判模型,其性能总是稳定地优于或持平于使用绝对信号(Abs-Q)训练的评判模型。
这揭示了一个深刻的道理:在复杂的、多步骤的推理任务中,通往成功的路径并非只有一条。有时,一个看似普通的步骤,其价值在于它为后续的关键突破铺平了道路,或者成功地避开了一个“陷阱”。奖励这种动态的“进步”,比刻板地评判每一步的“绝对好坏”,更能引导模型学习到鲁棒且灵活的推理策略。
点评
论文有两个贡献:
-
“思维块 (Chunks-of-Thought)”:如何定义一个“步骤”一直是个模糊的问题。通过“自分割”让模型学会生成逻辑连贯的单元,STEPWISER 找到了一个比简单按换行符切分更符合语义逻辑、更有效的解决方案。这不仅提升了评判单元的质量,还显著降低了后续标注的计算量。
-
相对奖励信号 (Relative Reward Signals):论文没有满足于最简单的“绝对Q值(Abs-Q)”标注法,而是深入探索了更能体现“进步”的相对信号(Rel-Effective, Rel-Ratio)。实验证明,奖励“进步”比评判“绝对好坏”更有效,这符合复杂问题解决的直觉,是一个深刻的洞察。
短板也很明显,标注成本依然很高。为了给一个训练样本中的每一个“思维块”打上标签,都需要进行 M 次蒙特卡洛(Monte Carlo)rollout,即从该点开始完整地生成 M 次后续推理。如果一个问题有6个“块”,就需要 6 * 16 = 96 次完整的模型推理才能完成标注。
DeepSeek-R1 的成功让 PRM 路线显得有些“不香了”。即便如此,仍有研究者持续深耕这一领域,对于这种 “坚持”你怎么看?欢迎在评论区留言。


