我们知道,预训练 (Pre-training) 赋予了模型世界知识的广度,而后训练 (Post-training) 则像是精雕细琢的过程,旨在激发和增强模型在特定任务上的“思考”能力。
目前,后训练阶段主要由两大技术范式主导:监督微调 (Supervised Fine-Tuning, SFT) 和强化学习微调 (Reinforcement Fine-Tuning, RFT)。SFT 就像是让模型“背诵”标准答案,通过学习高质量的“解题步骤”来模仿人类的推理过程。RFT 则鼓励模型进行“探索性思考”。它不直接提供标准答案,而是让模型自己尝试解决问题,并根据最终结果的好坏给予奖励或惩罚。
我们之前分享过一篇文章:Qwen团队提出CHORD训练流程:动态融合 SFT 与 RL,研究者们已经开始尝试融合不同来源的训练信号,试图在模仿学习和自主探索之间找到平衡。这正反映了一个核心趋势:单一的微调范式可能已无法满足我们对通用人工智能推理能力的极致追求。
正是在这样的背景下,来自麻省理工学院 (MIT) 的研究团队提出了 Unified Fine-Tuning (UFT) ,一个旨在将 SFT 和 RFT 无缝统一到单一集成过程中的新型后训练框架。UFT 的核心思想是模拟人类学习新知识的方式:当我们遇到难题时,会先尝试自己思考(类似 RFT),如果卡住了,会去翻看答案或提示(类似 SFT),然后基于提示继续思考。

-
论文标题:UFT: Unifying Supervised and Reinforcement Fine-Tuning -
论文链接:https://arxiv.org/pdf/2505.16984
UFT 框架深度解析
UFT 的设计哲学是“在指导下探索,在探索中学习”。它并非简单地将 SFT 和 RFT 两个阶段串联起来(即先 SFT 再 RFT,论文中称为 SFT-RFT 模式),而是在一个统一的框架内,动态地、平滑地融合二者。UFT 的实现依赖于两大核心支柱:提示引导的探索 (Exploration with Hint) 和 混合目标函数 (Hybrid Training Objective) 。
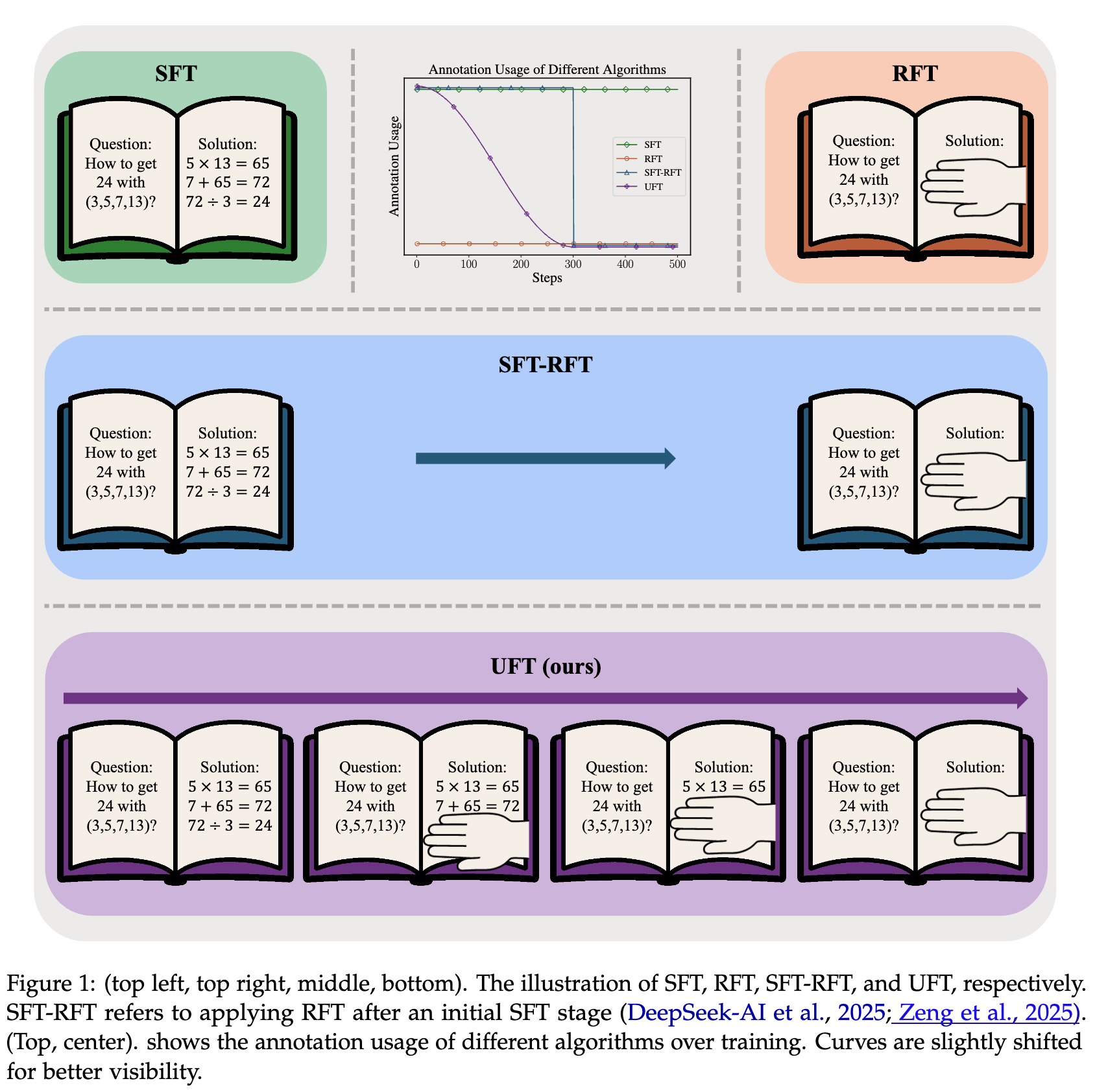
上图直观地展示了四种微调范式的区别。SFT 从头到尾都在使用完整的标准答案。RFT 则完全不使用答案,纯靠自己探索。SFT-RFT 是先用 SFT 训练,然后完全切换到 RFT。而 UFT 则是在训练过程中,动态地为模型提供部分答案(提示),并结合了两种学习信号。
1. 提示引导的探索 (Exploration with Hint)
为了解决 RFT 中因奖励稀疏导致的探索效率低下问题,UFT 引入了“提示”(Hint) 的概念。
什么是提示?
提示,本质上是正确解题步骤的一个前缀。例如,一个完整的解题过程有 5 步,一个长度为 2 的提示就是把前 2 步的正确解答直接提供给模型。
提示如何工作?
在训练的每一步,UFT 不再让模型从零开始解决问题,而是将“问题 + 提示”拼接在一起作为新的输入,让模型从提示的结尾处继续生成剩余的解题步骤。
这种做法带来了显而易见的好处:
-
有效缩减搜索空间:提示将模型直接引导到了一个更有希望的“状态”,极大地降低了探索的难度。模型不再需要在庞大的搜索树的浅层区域进行盲目探索,而是可以专注于更深层次的推理。 -
增加获得正奖励的机会:从一个正确的中间步骤开始,模型最终“撞上”正确答案的概率大大增加。这使得稀疏的奖励信号变得相对“密集”,从而加速了学习过程。
关键问题:提示长度如何控制?
提示的引入虽然巧妙,但也带来一个新的问题:提示应该给多长?如果提示太长(例如,总是提供 99% 的答案),那训练就退化成了 SFT,模型学不到独立推理的能力。如果提示太短(或没有提示),那又回到了 RFT 的困境。更重要的是,在最终评估(测试)时,模型是没有任何提示的。因此,训练过程必须能够平滑地过渡到“无提示”的状态,以避免训练和测试之间的分布不匹配 (distribution mismatch)。
UFT 在这里提出了一种非常精妙的解决方案:基于余弦退火的提示长度调度 (Cosine Annealing for Hint Length Scheduling) 。
该方法不直接控制提示的绝对长度 ,而是维护一个期望提示比例 。这个比例 代表了我们希望提示平均覆盖整个解题过程的百分比。在训练开始时, 接近 1(例如 0.95),意味着模型会看到非常长的提示,学习过程接近 SFT。随着训练的进行, 的值会根据余弦函数平滑地下降,在训练的后期(例如,从第 300 步开始,总步数为 500), 会降至 0.05 甚至为 0,意味着模型几乎或完全得不到任何提示,学习过程接近纯粹的 RFT。
随训练步数 变化的公式如下 (B.1):
其中 和 是比例的上下界(例如 0.95 和 0.05), 是提示完全退火所需的步数。
在确定了期望比例 后,具体的提示长度 通过从二项分布 (Binomial Distribution) 中采样得到:
其中 是完整解题步骤的总长度。使用二项分布采样而不是确定性的长度,可以增加训练的随机性和鲁棒性。
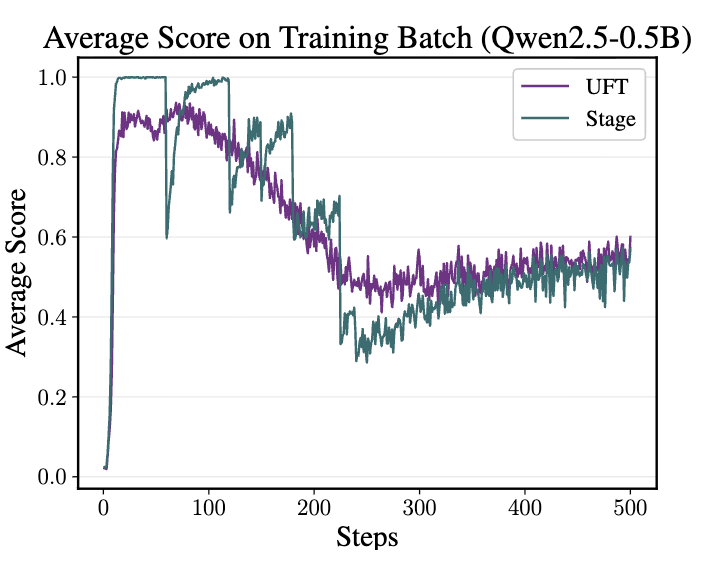
上图清晰地展示了这种平滑调度策略的优势。相比于“分阶段”(Stage) 的方法(即前 300 步给固定长提示,后 200 步完全不给提示),UFT 的训练曲线(紫色)更加平滑,收敛速度更快。这证明了余弦退火策略有效避免了因提示长度突变而导致的剧烈分布偏移。
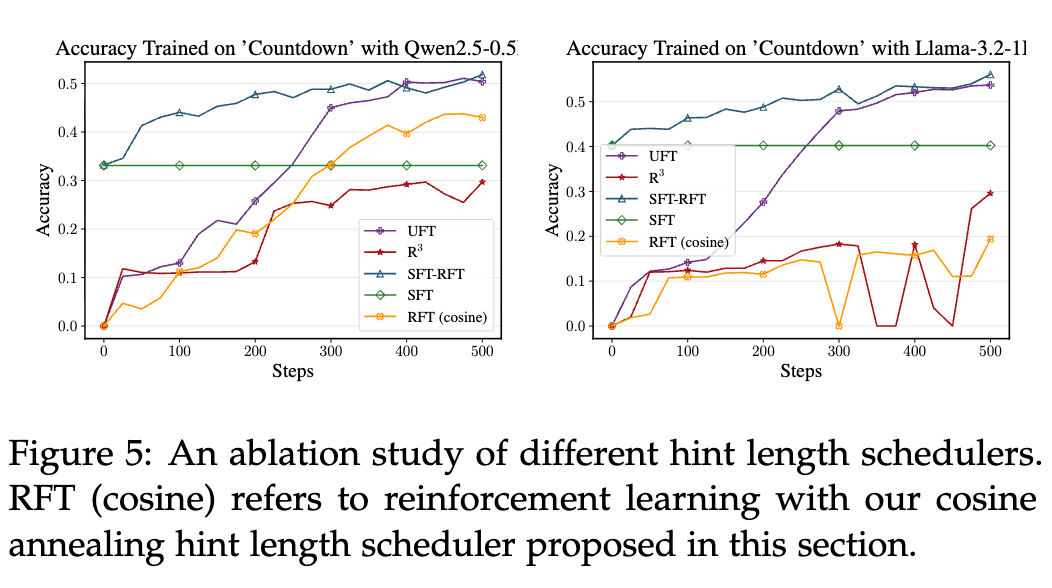
Figure 5 的消融研究进一步凸显了 UFT 设计的完备性。图中 RFT (cosine) 指的是只使用提示引导探索、但没有混合目标函数(即下一节要讲的支柱二)的 RFT。可以看到,即使有了高效的提示调度,RFT (cosine) 的表现仍然不如完整的 UFT,甚至在 Llama 模型上不如 SFT-RFT。这说明,仅仅引导探索是不够的,还需要更丰富、更直接的学习信号。
2. 混合目标函数 (Hybrid Training Objective)
这是 UFT 的另一个核心创新。传统的 RFT 只关心最大化最终的奖励,而忽略了模型在探索过程中接触到的“高质量信息”——也就是我们提供给它的“提示”。提示本身就是正确答案的一部分,蕴含着宝贵的监督信号。如果仅仅把它用作探索的起点,无疑是一种巨大的浪费。
UFT 设计了一个混合目标函数,将 RFT 的奖励最大化和 SFT 的似然最大化巧妙地结合在了一起。
我们来看一下 UFT 的目标函数 (公式 3.2):
这个公式看起来复杂,但我们可以把它拆解成两部分来理解:
-
第一部分:
这部分是强化学习项,和标准 RFT 的目标一致,即最大化智能体(LLM)通过自身策略 采样出的轨迹 所能获得的期望奖励 。这一项驱动模型去“思考”和“探索”,以获得更高的最终得分。 -
第二部分:
这部分是 UFT 新增的监督学习项,也是整个框架的点睛之笔。-
代表最优策略,在 UFT 的设定中,它就是生成我们提供的标准答案(提示)的那个确定性策略。 -
是我们正在训练的模型的当前策略。 -
是KL 散度 (Kullback-Leibler Divergence) ,它衡量了两个概率分布的差异。在这里,它衡量的是在给定提示中的某个状态 后,模型的策略 与最优策略 的差距。 -
最小化 KL 散度,在数学上等价于最大化对数似然。也就是说,让这一项最小,就等同于让模型生成标准提示中下一步动作的概率尽可能大。这不就是 SFT 的目标吗? -
因此,这一项的作用就是让模型“记忆”和“模仿”给定的高质量提示。它提供了一个密集的、每一步都有的监督信号。 -
是一个超参数,用于平衡 RL 项和 SL 项的重要性。
-
目标函数的直观理解:
UFT 的目标函数告诉模型:“你的首要任务是像 RFT 一样,通过探索来最大化最终奖励(学会思考)。但同时,你必须紧紧跟随我给你的提示,不要偏离太远,要努力模仿提示中的每一步操作(学会记忆)。我会通过 来告诉你这两件事哪个更重要一点。”
论文进一步阐释了这个统一性:
-
当提示比例 (全程提供完整答案)时,第一项奖励部分的作用会减弱(因为路径是固定的),目标函数退化为最小化 KL 散度,即SFT。 -
当提示比例 (完全不提供提示)时,第二项 KL 散度项因为没有提示可以计算而变为 0,目标函数退化为最大化期望奖励,即RFT。
通过提示长度调度(动态改变 )和混合目标函数(同时优化两个目标)的协同作用,UFT 实现了一个从 SFT 到 RFT 的平滑、动态的过渡,真正做到了在一个框架内统一两种范式。
UFT 的理论优势
一篇优秀的研究论文不仅要有创新的算法设计和良好的实验效果,还应具备坚实的理论基础。UFT 的作者们为其核心优势——提升样本效率——提供了强有力的理论证明。
在复杂推理任务中,样本效率指的是算法需要多少次探索(采样多少条轨迹)才能学会解决问题。前面提到,这类任务的搜索空间大小为 ,其中 是推理步数(树的高度), 是分支因子。
RFT 的困境:指数级样本复杂度
论文的 Theorem 4.2 指出,对于任何标准的 RFT 算法,在最坏情况下,要达到 50% 的成功率,其所需的探索次数(样本复杂度)的下界是:
这里的 符号表示“至少是”。这个结果是指数级 (exponential) 的。这意味着推理步数 每增加一点,解决问题所需的样本量就会呈指数爆炸式增长。这从理论上解释了为什么 RFT 在长链条推理任务上举步维艰。例如,如果 ,搜索空间是 ;但如果 ,搜索空间就暴增到 ,这对于 RFT 的盲目探索来说是几乎不可能完成的任务。
UFT 的突破:多项式级样本复杂度
与此形成鲜明对比的是,论文的 Theorem 4.3(非正式表述)指出,UFT 算法(在 足够小的情况下)要达到 50% 的成功率,其所需的探索次数的上界是:
这里的 符号表示“至多是”。这个结果最关键的变化在于,推理长度 从指数位置被移到了多项式位置 ()。这是一个指数级的提升 (exponential improvement) 。
这意味着什么?
我们还是用上面的例子:。
-
RFT 的复杂度与 相关。 -
UFT 的复杂度则与 相关(忽略其他项)。
从 到 ,这是一个巨大的飞跃。它意味着 UFT 能够解决比 RFT 长得多的推理问题,而所需的样本量却在可接受的范围内。
理论优势的来源:
这种指数级加速的根本原因,正是 UFT 的提示引导机制。提示的存在,使得模型不必再对整个巨大的搜索树进行探索。理论分析严格地量化了这种“剪枝”效应,证明了通过结合模仿学习(学习提示)和强化学习,可以从根本上降低问题的探索复杂度。
这个理论结果不仅为 UFT 的有效性提供了坚实的数学背书,也为未来设计更高效的 LLM 推理算法提供了重要的理论启示。
实验验证
理论上的优越性最终需要通过实践来检验。UFT 的作者们在一系列模型、数据集和任务上进行了广泛的实验,以验证其有效性和适应性。
实验设置:
-
模型:涵盖了不同规模的模型,包括 Qwen2.5 (0.5B, 1.5B, 3B) 和 Llama-3.2 (1B, 3B)。这有助于评估算法对模型规模的敏感性。 -
数据集/任务: -
Countdown:一个数字游戏,要求用给定的数字和四则运算得到一个目标数。 -
MATH:一个高质量的数学问题数据集 (只使用 level 3-5)。 -
Knights and Knaves (Logic) :一个经典的逻辑谜题任务。 -
这些任务覆盖了数值计算、代数推理和逻辑推理,具有很好的代表性。
-
-
基线方法: -
Base:未经任何微调的预训练模型。 -
SFT:标准的监督微调。 -
RFT:标准的强化学习微调。 -
SFT-RFT:先进行 SFT,再进行 RFT 的两阶段方法,是当前一种常见且强大的基线。 -
R³:一种相关的、使用提示进行课程学习的 RFT 方法,它在整个训练过程中均匀采样提示长度。
-
核心发现一:UFT 的普适优越性
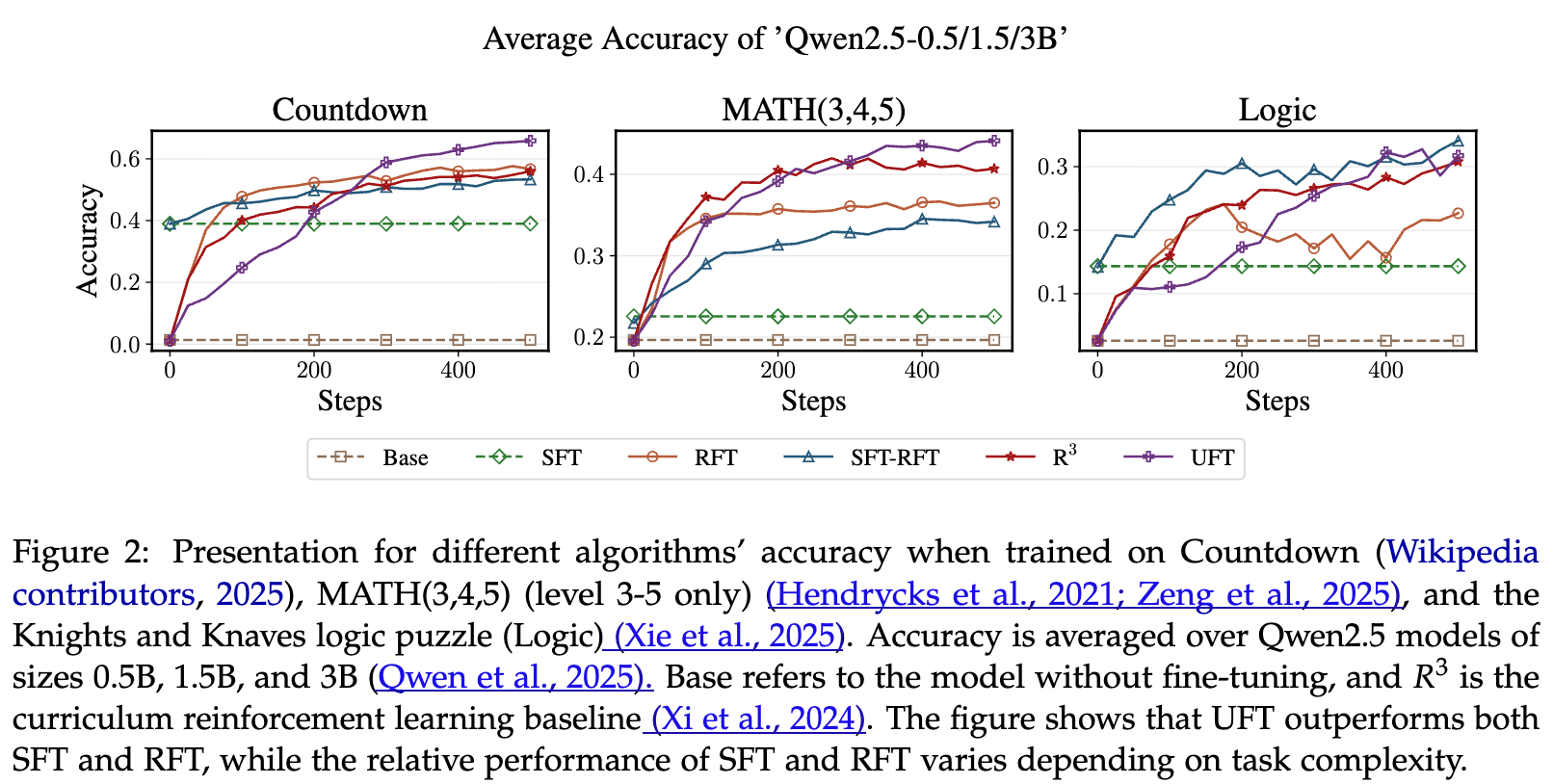
上图展示了在 Qwen2.5 模型族上,不同算法在三个任务上的平均准确率。可以清晰地看到,UFT在绝大多数情况下都取得了最好的性能,稳定地超越了所有基线方法。这初步证明了 UFT 框架的普适性和有效性。
核心发现二:UFT 对模型规模的自适应性
这是 UFT 最引人注目的特性之一。它能够根据基础模型的能力,自动地在“记忆”和“泛化”之间进行权衡。
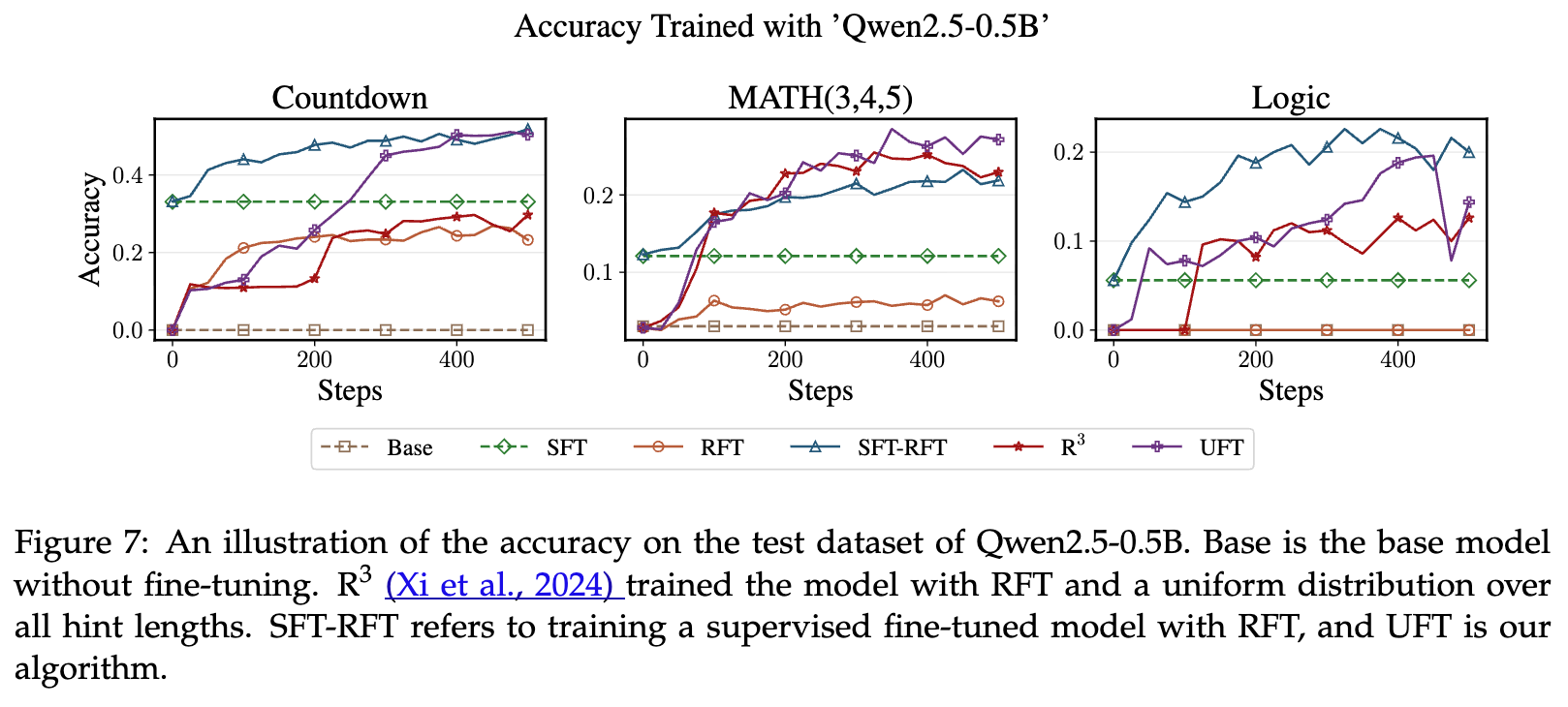
对于小模型 (Qwen2.5-0.5B):
观察上图,在这种规模下,基础模型能力较弱,难以进行有效的自主探索。
-
RFT 的表现非常差,几乎没有提升。这验证了 RFT 严重依赖基础模型的强度。 -
SFT 和 SFT-RFT 的表现要好得多,因为它们通过直接的监督信号强行“教会”了模型。 -
UFT 的表现与 SFT-RFT 非常接近,并最终取得了最佳性能。
结论:当模型较小时,UFT 的行为更偏向于 SFT。其混合目标函数中的监督学习项(KL 散度项)发挥了主导作用,帮助模型有效地“记忆”解决方案,以弥补其自身探索能力的不足。

对于大模型 (Qwen2.5-3B):
观察上图,当模型规模增大,其预训练阶段学到的知识和推理潜力更强。
-
SFT 和 SFT-RFT 的表现反而变差了,出现了明显的过拟合现象。它们强迫模型记忆特定路径,反而损害了模型利用自身强大能力进行泛化的潜力。 -
RFT 的表现大幅提升,成为了最强的基线方法之一,展示了其在激发大模型泛化能力上的优势。 -
UFT 的表现与 RFT 非常接近,甚至在某些点上超越了 RFT。
结论:当模型较大时,UFT 的行为更偏向于 RFT。其目标函数中的强化学习项(奖励最大化项)发挥了主导作用,鼓励模型利用自身强大的基础能力去“思考”和“探索”,从而获得更好的泛化性能。
这两个对比实验极具说服力地证明了 UFT 的自适应性。它不是一个僵化的算法,而是能够根据模型的内在能力,动态调整其学习策略,从而在各种规模的模型上都能“取其精华,去其糟粕”,实现稳定、出色的表现。
核心发现三:UFT 能够帮助模型学习新知识
论文还探讨了一个更深层次的问题:微调究竟是在“激发”模型已有的潜能,还是在“教会”模型全新的知识?
实验发现,Llama-3.2-3B 模型通过 RFT 获得的性能提升非常有限,远不如 Qwen2.5-3B。作者推测这是因为 Llama 系列模型在预训练阶段接触到的推理相关知识(如回溯、子目标设定等)较少。
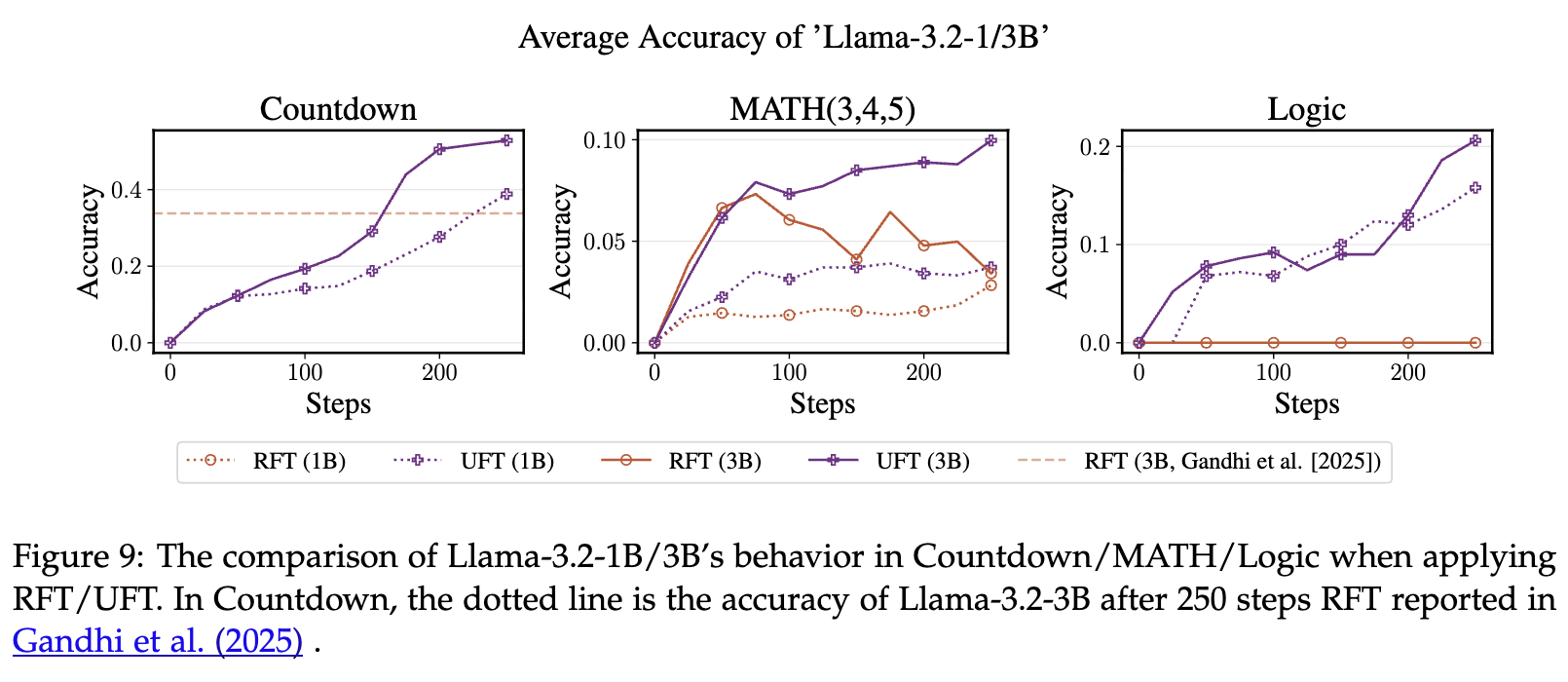
上图的实验结果支持了这一观点。
-
RFT 对 Llama 模型的提升非常微弱。这说明 RFT 更像是“催化剂”,它需要模型本身就有一定的“内功”,才能帮助其打通任督二脉。如果模型内功不足,RFT 也无能为力。 -
UFT 则对 Llama 模型有显著的性能提升。甚至 1B 的 Llama 模型经过 UFT 微调后,在 Countdown 任务上的表现超过了 3B 模型经过 RFT 微调后的表现。
结论:这一结果强有力地证明了,UFT 不仅仅是在利用模型已有的知识。其混合目标函数中的监督学习部分,能够有效地为模型注入新知识和新技能。这使得 UFT 在帮助那些“偏科”的模型补齐短板方面,比纯 RFT 方法更具优势。
量化结果
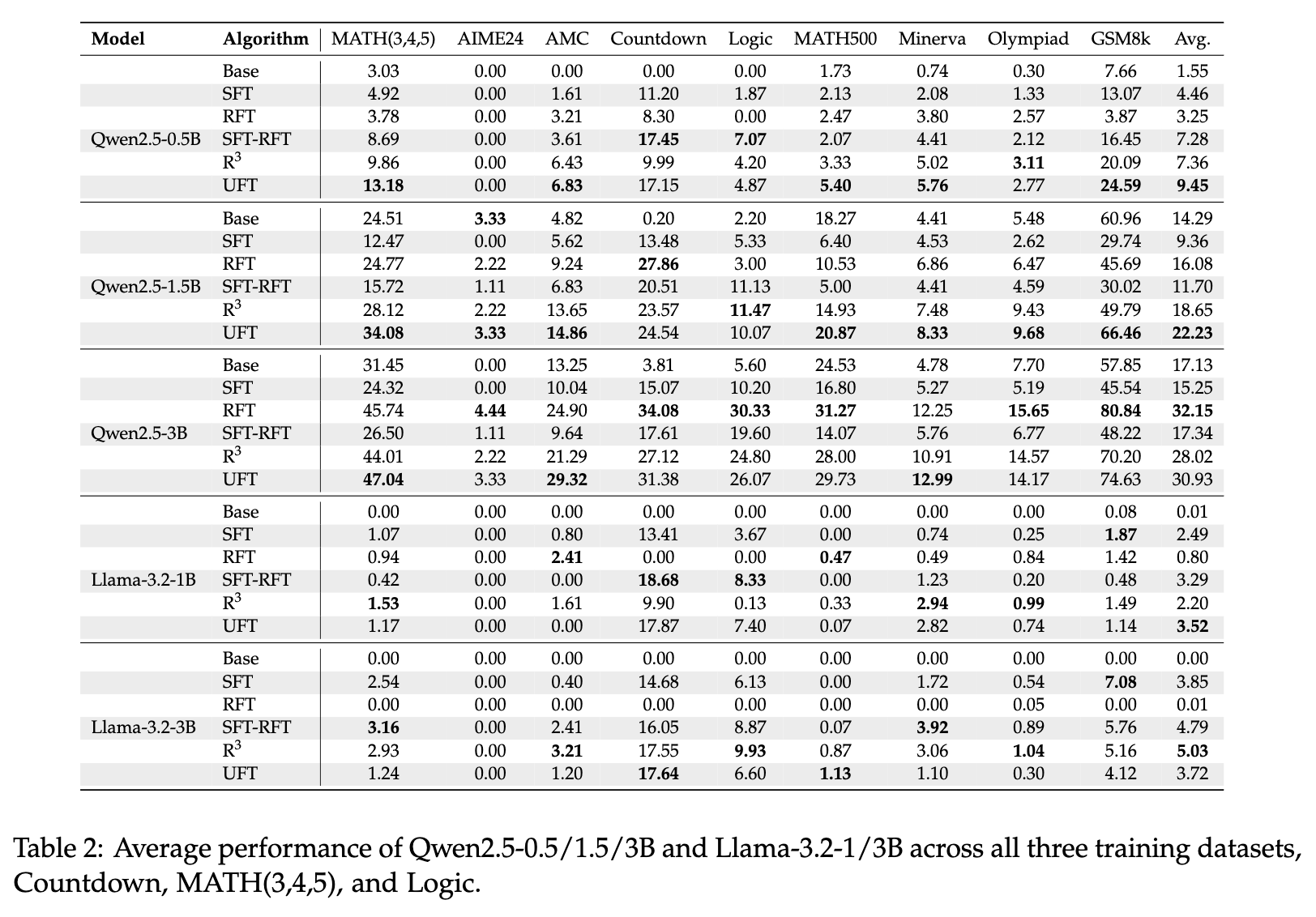
最后,论文中的上表提供了详尽的量化数据。我们摘取几个关键点:
-
对于小模型 Qwen2.5-0.5B,UFT 的平均准确率达到 9.45% ,显著高于 SFT-RFT 的 7.28% 和 RFT 的 3.25%。 -
对于大模型 Qwen2.5-3B,UFT 的平均准确率达到 30.93%
往期文章: