在信息检索(IR)领域,我们一直在追求一个终极目标:让机器像人一样理解查询背后的复杂意图,并从海量信息中精准地筛选出最相关的答案。近年来,基于大语言模型(LLM)的排序方法,特别是列表式(Listwise)排序,已经在许多任务中展现了卓越的性能。然而,当面对需要多步骤、深层次推理才能解决的复杂问题时,现有的模型往往会遇到瓶颈。
想象一下,你不再是简单地问“珠穆朗玛峰有多高”,而是提出一个更复杂的问题,比如:“考虑到我正在开发一个使用Python异步框架的Web应用,并且遇到了特定的数据库死锁问题,在Stack Overflow的这些解决方案中,哪一个不仅语法相似,而且在逻辑上最能解决我这个多线程冲突的根源?”
这类问题无法通过简单的关键词或语义匹配来回答。它要求模型能够理解代码逻辑、分析因果关系,并进行一步步的推理。这正是当前信息检索领域面临的“推理鸿沟”。大多数先进的重排器(reranker)由于缺乏针对性的“推理密集型”训练数据,很难在这种复杂场景下表现出色。
为了应对这一挑战,来自中国人民大学、百度和卡内基梅隆大学的研究者们共同提出了一种名为 ReasonRank 的新型段落重排器。 这项工作不仅直面了推理密集型排序任务中训练数据稀缺的核心难题,还提出了一套完整的解决方案,在效果和效率上都取得了显著的突破,甚至在权威的BRIGHT排行榜上达到了SOTA水平。

-
论文题目: ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability -
论文链接:https://arxiv.org/pdf/2508.07050
本文将深入剖析ReasonRank的技术细节、核心思想及其深远影响。我们将探讨:
-
问题的核心:为什么现有排序模型在复杂推理任务上表现不佳? -
ReasonRank的“炼金术”:如何凭空创造出高质量的推理密集型训练数据? -
两阶段训练框架:如何分步骤、有侧重地教会模型“思考”和“排序”? -
创新的奖励机制:在强化学习中,如何设计一个更全面的“指挥棒”来引导模型优化? -
惊艳的实验结果:ReasonRank的性能究竟有多强大,它又是如何实现“又快又好”的?
一、 “推理鸿沟”
在深入了解ReasonRank之前,我们必须先理解它试图解决的问题。大语言模型,特别是采用列表式方法的重排器,其优势在于能够同时评估一个段落列表,从而捕捉到比逐点式(Pointwise)或成对式(Pairwise)方法更全局的上下文和相关性模式。 这使得它们在传统的信息检索基准测试中表现优异。
然而,这些模型的训练数据,例如经典的MSMARCO数据集,其相关性判断大多依赖于词汇或语义的直接匹配。 这种训练模式导致模型擅长“匹配”,却不擅长“推理”。当查询变得复杂,答案不再是简单的信息陈述,而是需要逻辑推导、证据链支持或方法论上的相似性判断时,模型的短板就暴露无遗了。
许多真实世界的场景都属于这种推理密集型查询,例如:
-
开发者社区(如Stack Exchange):用户提出的问题往往包含复杂的逻辑和代码上下文,最佳答案需要提供具有相似方法论或逻辑的解决方案。 -
科学研究:判断一篇论文是否与某个研究问题相关,需要理解其核心论点、实验方法和证据链。 -
法律文书检索:寻找支持某个案件的先例,需要对法律条文和判例进行深入的逻辑分析。
由于缺乏能够训练模型进行这种复杂推理的、大规模、高质量的数据集,现有重排器在这些领域举步维艰。它们就像是只为选择题考试训练过的学生,突然要面对需要写出详细解题步骤的论述题,自然会力不从心。
二、 自动化数据合成
既然问题的根源在于缺少高质量的推理训练数据,那么最直接的解决方案就是——创造数据。然而,通过人工标注来构建这样一个数据集成本极高且不切实际。 ReasonRank的第一个核心贡献,就是设计了一套自动化的推理密集型训练数据合成框架。
这个框架的目标是生成包含三个关键要素的训练样本:查询(Query)、段落列表(Passage List),以及最重要的高质量标签(Label),标签本身又包含推理链(Reasoning Chain)和黄金排序列表(Gold Ranking List)。
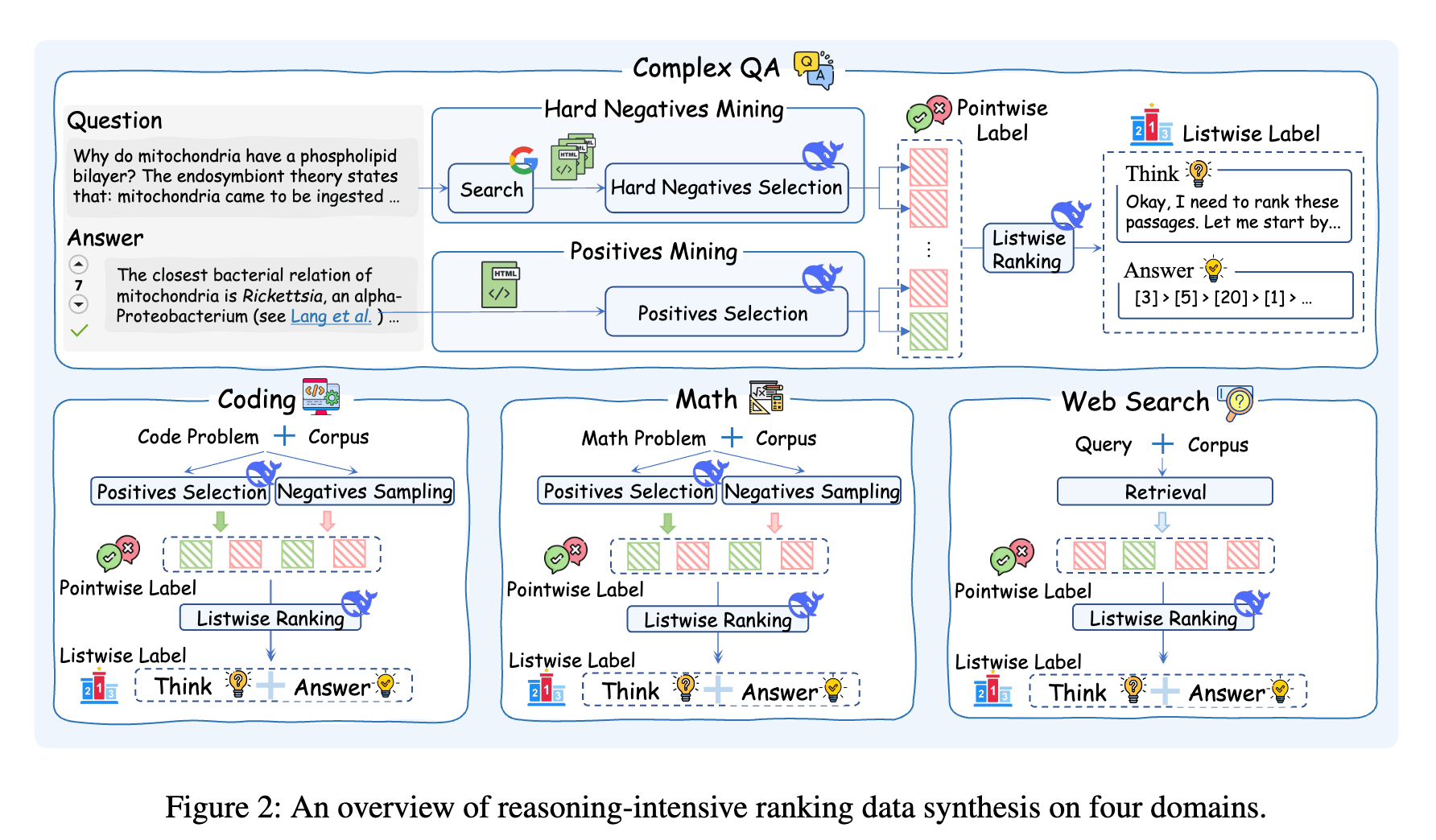
整个合成过程可以概括为以下几个步骤:
1. 多样化的数据源
为了保证训练数据的多样性和泛化能力,框架从四个不同的领域搜集查询和段落,覆盖了典型的复杂推理场景:
-
复杂问答(Complex QA):主要来源于StackExchange的六个子领域(如生物学、地球科学、经济学等)。这类查询通常很长,需要深入理解和复杂推理。 -
编程(Coding):使用Leetcode的数据集作为查询,相关的代码片段作为段落。 -
数学(Math):使用MATH数据集中的问题作为查询,相关的问题解答或定理证明作为段落。 -
网页搜索(Web Search):从MSMARCO数据集中采样查询,以确保模型在简单搜索场景下依然保持良好的排序能力。
2. 强大的“教师模型”:DeepSeek-R1
数据合成的核心是一位强大的“教师”——DeepSeek-R1,这是一个大型推理模型(LRM)。 与传统的模型蒸馏不同,ReasonRank不仅仅是让学生模型模仿教师模型的输出。在这里,研究者们采取了一种更巧妙的策略:在生成标签时,为教师模型提供“标准答案”(Gold Answer)。
例如,在处理StackExchange的查询时,框架会先找到被用户接受的“黄金答案”,并爬取答案中链接的外部文档作为候选段落。然后,将查询、黄金答案和候选段落列表一同输入给DeepSeek-R1。这种做法极大地提升了教师模型对查询意图的理解,使其能够生成远比“无答案”蒸馏更准确、更可靠的排序标签。 这就像是让一位专家带着答案解析来批改作业,其标注质量自然更高。
3. 精心设计的正负样本挖掘
一个好的排序模型不仅要能识别“好的”答案,还要能区分“看起来好但实际不好”的迷惑性答案。因此,训练数据中需要包含高质量的正样本(Positives)和难负样本(Hard Negatives)。
-
正样本挖掘:利用提供了黄金答案的DeepSeek-R1,从候选段落中精准地挑选出那些包含回答问题的关键概念、证据或理论的核心段落。 -
难负样本挖掘:为了增加训练难度,框架还会使用Google Search API检索与查询主题相似但并不能真正解决问题的文档。 再让DeepSeek-R1从中挑选出那些具有迷惑性的难负样本。这些样本通常与查询共享一些关键词,但缺乏解决问题的核心逻辑。
4. 自洽性数据过滤机制
自动化生成的数据难免存在噪声。为了确保最终训练数据的质量,ReasonRank引入了一种自洽性数据过滤机制。 受到LLM自洽性研究的启发,研究者们认为,如果教师模型(DeepSeek-R1)生成的列表式标签(包含推理链和排序结果)与通过挖掘正负样本得到的逐点式标签(每个段落是相关还是不相关)之间的一致性很高,那么这个生成的标签质量就越可靠。
具体来说,他们会使用逐点式标签作为参考,计算列表式标签中黄金排序的NDCG@10分数。只有当这个分数高于某个阈值(例如0.4)时,这个训练样本才会被保留下来。 这种机制像一个质量过滤器,有效地剔除了低质量和有冲突的训练数据。
最终,通过这个精密的自动化流程,ReasonRank成功构建了一个包含约13,000个样本的高质量、多样化的推理密集型训练数据集,为后续的模型训练奠定了坚实的基础。
三、 两阶段训练框架
拥有了高质量的“教材”后,接下来的问题就是如何设计一个高效的“教学方案”来训练ReasonRank模型。研究者们为此提出了一个两阶段训练框架,旨在让模型先学会基本的推理模式,再通过探索和试错来进一步提升其排序能力。
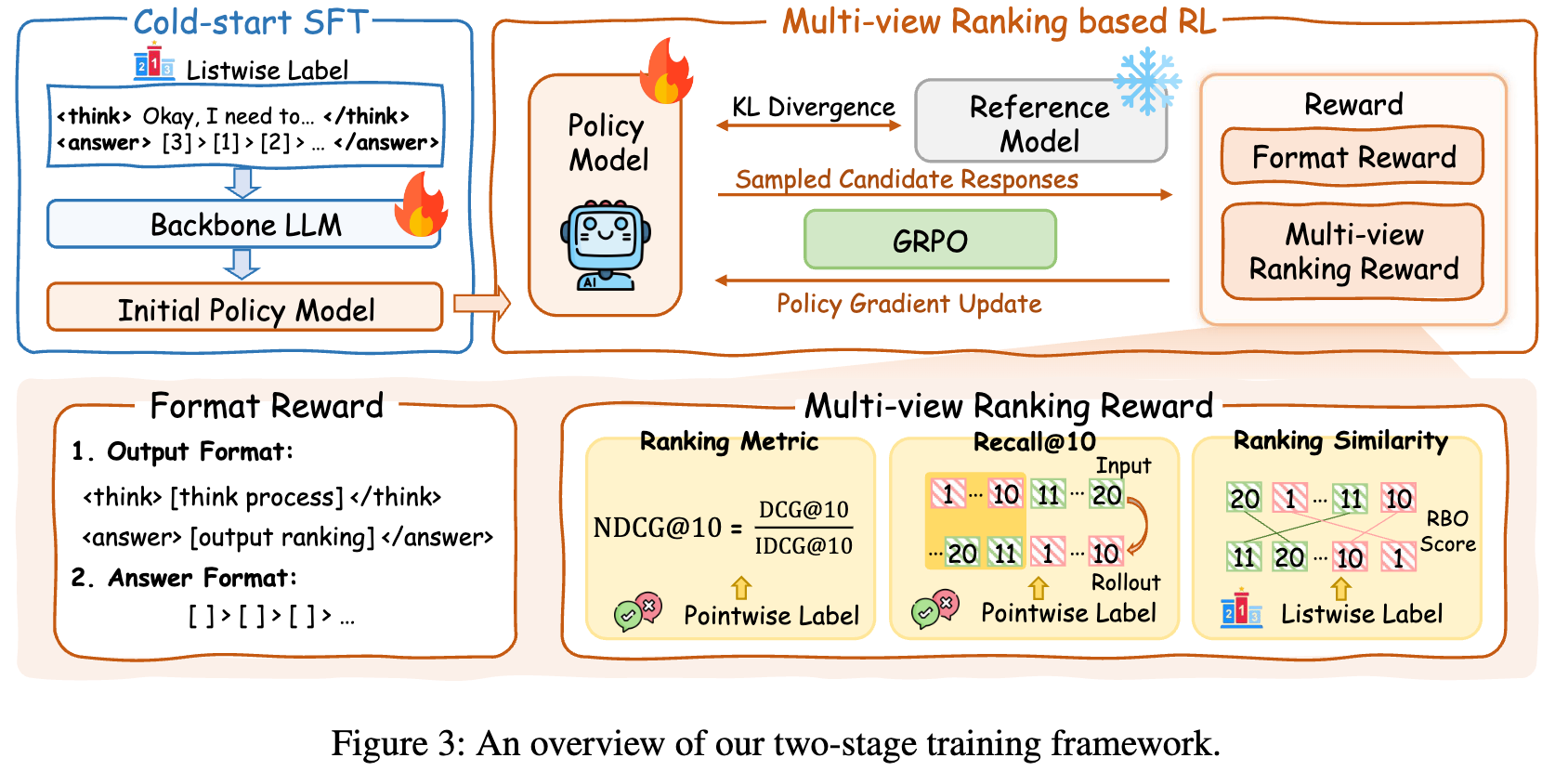
阶段一:冷启动监督微调(Cold-Start SFT)
这个阶段的目标是让一个基础的LLM(论文中使用了Qwen2.5-7B和Qwen2.5-32B)学会列表式推理的基本模式。 训练数据就是前一步合成的列表式标签,包含了推理链和黄金排序列表。
模型接收一个查询和段落列表作为输入,然后被训练去生成一个结构化的输出,这个输出包含了用<think>和</think>标签包裹的推理过程,以及用<answer>和</answer>标签包裹的最终排序结果。
<think>
Okay, I need to rank these passages for the user's query about X.
Passage [3] directly addresses the core concept of Y mentioned in the query.
Passage [1] provides supporting evidence for the argument in passage [3].
...
Therefore, the optimal order should be [3] > [1] > ...
</think>
<answer>
[3] > [1] > [5] > ...
</answer>
通过在这种结构化数据上进行标准的语言建模损失优化,模型不仅学会了如何对段落进行排序,更重要的是,它内化了“先思考,后回答”的行为模式。 这个“冷启动”阶段为模型注入了初步的推理能力,使其为下一阶段更高级的训练做好了准备。
阶段二:基于多视角奖励的强化学习(RL)
监督微调让模型学会了模仿,但要成为真正的“大师”,模型需要学会探索和发现比教师提供的更优的推理路径和排序策略。这就是强化学习(RL)阶段的用武之地。
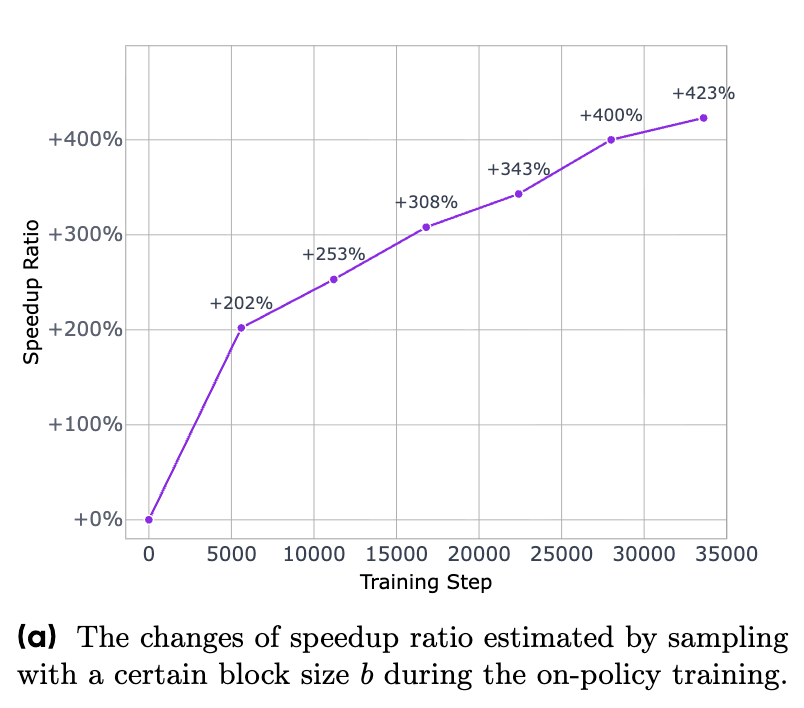
在RL中,最关键的要素是奖励信号(Reward Signal),它告诉模型什么样的行为是“好”的,应该被鼓励。以往的RL排序模型通常只使用单一的排序指标(如NDCG@10)作为奖励。 然而,ReasonRank的作者们认为,这种单一的奖励对于基于滑动窗口的列表式排序来说是次优的。
为什么呢?列表式排序通常因为LLM的上下文长度限制而采用滑动窗口策略,即一次只处理一小部分段落。 仅仅优化单个窗口内的NDCG@10,不一定能保证最终全局排序的最优。例如,在一个大小为20,步长为10的窗口中,将两个相关段落排在第2和第11位,其NDCG@10分数可能高于将它们排在第9和第10位。但是,后一种排法能确保这两个相关段落都保留在前10名,并有机会在下一个窗口中继续向前传播,从而可能带来更好的最终结果。
因此,ReasonRank设计了一种新颖的多视角排名奖励(Multi-view Ranking Reward),它从多个维度来评估一次排序的好坏:
-
NDCG@10:这仍然是核心指标,用于衡量头部结果的质量。 -
Recall@10:引入召回率指标,鼓励模型将尽可能多的相关段落排入前10名,这对于滑动窗口策略至关重要。 -
Rank-Biased Overlap (RBO) :NDCG和Recall主要依赖于二元的逐点式标签。为了利用列表式标签中更细粒度的排序信息,ReasonRank引入了RBO。RBO可以衡量模型生成的排序列表与教师模型给出的黄金排序列表之间的相似度,捕捉更丰富的排序信号。 -
格式奖励(Format Reward):这是一个辅助性的奖励,确保模型的输出格式正确(例如,包含 <think>和<answer>标签),保证了模型的可用性。
最终的奖励是这几个部分的加权和。通过优化这个更全面、更贴合列表式排序本质的奖励信号,并使用GRPO算法进行强化学习训练,ReasonRank能够探索到更有效的推理模式,并显著提升其最终的排序性能。
四、 实验结果与分析:效果与效率的双重胜利
ReasonRank的创新设计最终是否有效,还需要通过严格的实验来验证。研究者们在两个极具挑战性的推理密集型IR基准——BRIGHT和R2MED——上对ReasonRank进行了全面的评估,并与当前主流的非推理重排器(如RankT5, RankZephyr)和推理重排器(如Rank1, Rank-R1, Rank-K)进行了比较。
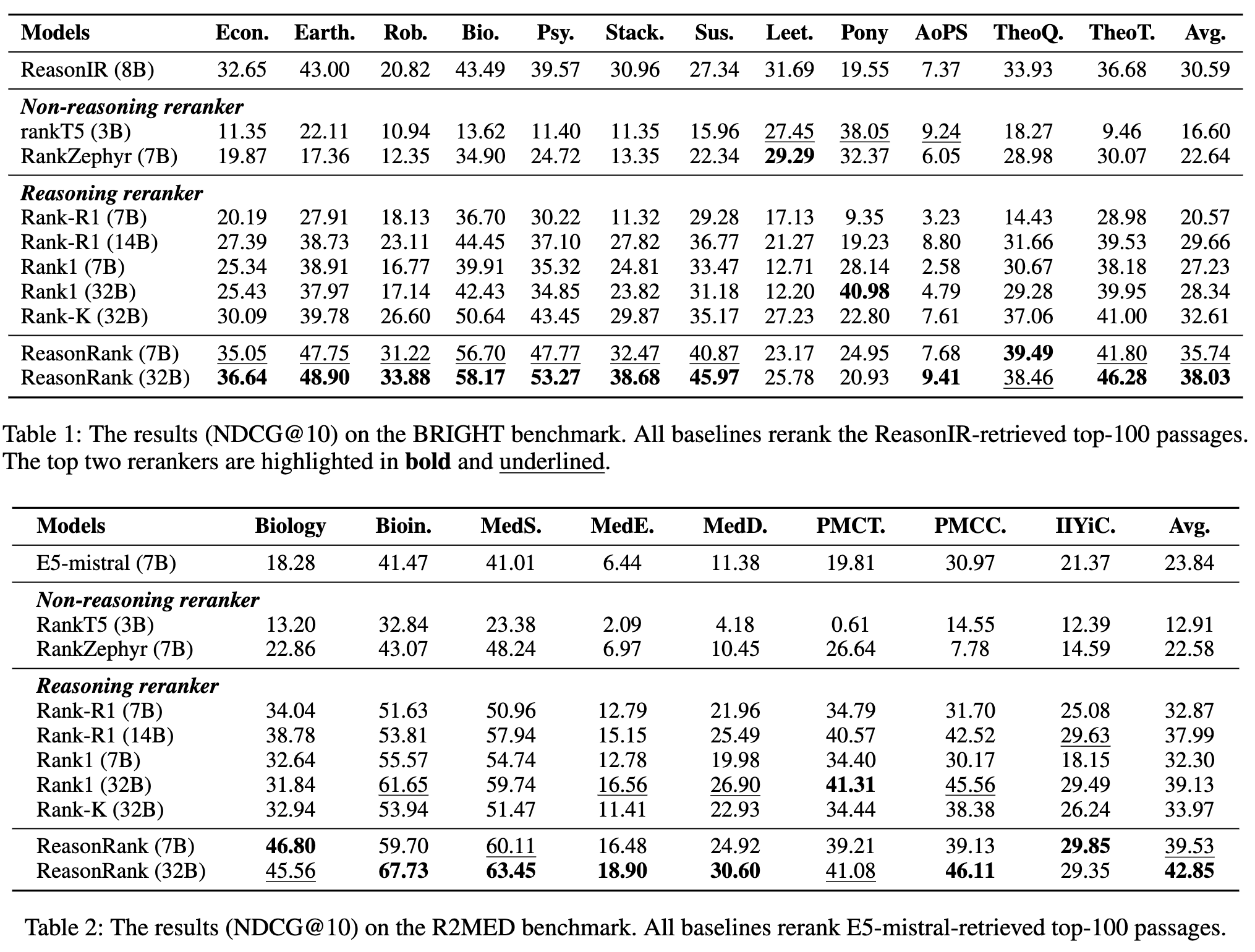
实验结果非常亮眼,主要可以总结为以下几点:
1. 性能全面超越,SOTA水平
在两个基准测试的平均性能上,ReasonRank(无论是7B还是32B版本)都显著优于所有基线模型。 特别是在BRIGHT基准上,ReasonRank (32B) 比当时最好的基线模型Rank-K (32B) 高出约5个NDCG点。 更令人印象深刻的是,7B版本的ReasonRank甚至超越了所有32B规模的基线模型,这充分证明了其数据合成和训练框架的巨大优势,而不仅仅是依赖于模型规模的提升。
通过使用更强的初始检索器并微调滑动窗口参数,ReasonRank (32B) 在BRIGHT官方排行榜上取得了40.6分的SOTA成绩,证明了其在这一领域的领先地位。
2. 现有基线在推理任务上的挣扎
实验结果也反向印证了“推理鸿沟”的存在。在BRIGHT基准上,除了Rank-K (32B)外,大多数基线模型几乎无法在初始检索结果的基础上带来任何提升。 在R2MED基准上,两个非推理重排器的表现甚至不如初始的检索器,这表明传统的训练数据和方法难以培养出有效的推理密集型重排器。
3. “越大越好”的规模效应
实验同样显示,重排器的性能与其模型规模正相关。例如,Rank-R1 (32B) 比 Rank-R1 (7B) 平均高出9个点,而ReasonRank (32B) 也比ReasonRank (7B) 高出约2.3个点。 这说明,在拥有了有效的训练方法后,更大的模型能够带来更强的推理和排序能力。
4. 效率优势
通常的认知是,增加推理步骤会降低模型的运行速度。然而,ReasonRank给出了一个令人意外的答案:它比同等规模的逐点式推理重排器Rank1快得多。
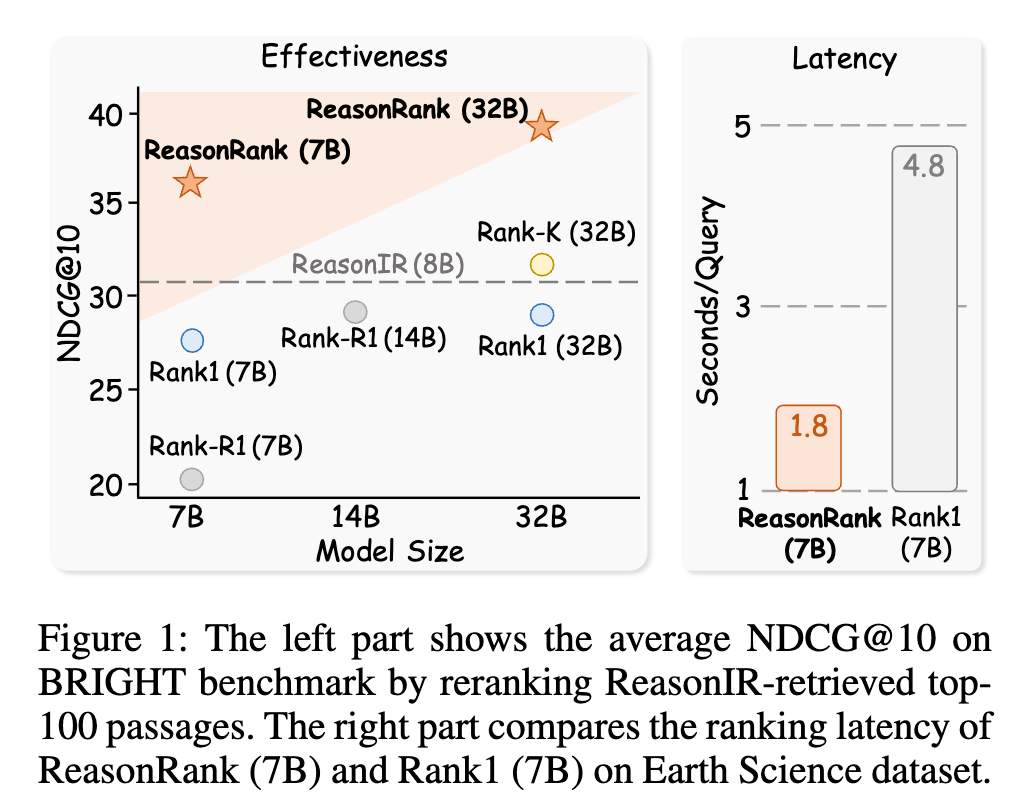
实验数据显示,在地球科学数据集上,ReasonRank (7B) 的查询延迟仅为1.8秒,而Rank1 (7B) 则需要4.8秒。在其他多个数据集上,ReasonRank (7B) 的速度是Rank1 (7B) 的2到2.7倍。
这是如何实现的呢?原因在于列表式推理(Listwise Reasoning)和逐点式推理(Pointwise Reasoning)在计算模式上的根本差异:
-
Rank1 (逐点式):为列表中的每一个段落都生成一个独立的推理链来判断其相关性。处理20个段落,就需要生成20次推理输出。 -
ReasonRank (列表式):为整个段落列表(或一个窗口内的段落)生成一个统一的、全局的推理链,来比较和排序所有段落。处理20个段落,只需要生成1次推理输出。
这种模式极大地减少了模型需要生成的Token数量,从而显著降低了计算开销和延迟。ReasonRank用实践证明了,通过更聪明的设计,“思考”不仅可以更准确,还可以更高效。
点评
这篇论文最大的贡献在于其系统性地解决了推理密集型排序任务中训练数据稀缺的问题。这不仅仅是一个模型上的改进,而是从数据根源上推动了领域的发展。
-
“带答案的教师”模式:传统的模型蒸馏是让学生模仿教师的输出,但ReasonRank的框架在生成标签时为教师模型(DeepSeek-R1)提供了“黄金答案”。这是一个非常聪明的设计,极大地降低了教师模型理解复杂查询的难度,从而生成了质量远高于纯粹无监督蒸馏的标签。
-
多样化的数据源与难负样本挖掘:框架覆盖了复杂问答、编程、数学和通用网页搜索四个领域,保证了模型泛化能力。同时,通过引入外部搜索引擎来挖掘与查询主题相似但逻辑不符的“难负样本”,显著增加了训练的难度和模型的辨别能力。
-
自洽性过滤机制:自动化生成的数据难免有噪声。引入自洽性过滤机制,通过对比列表式标签和逐点式标签的一致性(以NDCG@10衡量)来筛选高质量样本,相当于为数据生产线增加了一个“质检”环节,确保了训练数据的可靠性。
局限性:
整个ReasonRank的流程相当复杂,涉及多个数据源的获取、多个阶段的模型调用(用于挖掘正负样本、生成列表标签)、数据过滤以及两阶段的训练。
复现成本:这使得整个流程的复现成本(包括计算资源和API调用成本)相对较高,可能会对一些研究者构成一定的障碍。
鲁棒性:如此长的流水线中,任何一个环节出现问题都可能影响最终的数据质量。虽然有过滤机制,但系统的整体鲁棒性仍是一个潜在的关注点。
往期文章: