
-
论文标题:Dr. Zero: Self-Evolving Search Agents without Training Data -
论文链接:https://arxiv.org/pdf/2601.07055
TL;DR
Dr. Zero 是一项针对搜索智能体(Search Agents)的零数据(Data-Free)自进化框架研究。该工作由 Meta Superintelligence Labs 和 UIUC 的研究人员提出。该框架的核心在于解决开放域问答中,高质量训练数据(问题-检索路径-答案)获取困难的问题。Dr. Zero 通过提议者(Proposer)与求解者(Solver)的协同进化,实现了从零开始的能力提升。
其主要技术贡献包括:
-
自进化反馈闭环:提议者基于文档生成具有不同推理跳数(Hops)的问题,求解者利用搜索工具进行解答。求解者的反馈(是否答对)被用来训练提议者生成难度适中且可解的问题,而生成的数据反过来用于训练求解者。 -
分组相对策略优化(HRPO):针对提议者训练,提出了一种基于跳数分组(Hop-Grouped)的相对策略优化方法,解决了不同难度问题导致的回报方差过大问题,并大幅降低了采样成本。 -
难度引导的奖励机制:设计了基于求解者通过率的奖励函数,鼓励提议者生成处于求解者能力边界上的问题(非平凡且可验证)。
实验表明,在 Qwen2.5-3B/7B 模型上,Dr. Zero 在不需要任何人工标注数据的情况下,在 HotpotQA、Natural Questions 等多个基准测试中匹配甚至超越了全监督微调的搜索智能体(如 Search-R1)。
1. 引言
1.1 大语言模型的自进化范式
近年来,大语言模型(LLM)的后训练(Post-training)范式正在从单纯的监督微调(SFT)向基于强化学习(RL)的自进化转变。在数学推理和代码生成领域,DeepSeek-R1、Self-Rewarding LM 等工作展示了模型可以通过自我探索(Self-play)和自我验证(Self-verification)来提升性能。这些领域的一个共同特征是:答案的正确性通常容易验证(例如通过代码执行器或数学规则)。
然而,对于开放域问答(Open-Domain QA)和搜索智能体而言,自进化面临着独特的挑战:
-
验证困难:开放域问题的答案往往是非唯一的、语义相关的,且缺乏像代码编译器那样的确定性验证器。 -
数据多样性匮乏:现有的自进化方法若仅依赖模型自身生成问题,往往会陷入同质化,倾向于生成简单的单跳(One-hop)问题,难以覆盖复杂的多跳推理(Multi-hop reasoning)场景。 -
计算成本高昂:搜索智能体涉及多轮工具调用(Tool-use)。标准的强化学习方法(如 PPO 或 GRPO)通常需要对每个提示(Prompt)进行多次采样以估计基线,这在涉及慢速搜索API调用的场景下,训练成本极高。
1.2 Dr. Zero 的切入点
针对上述痛点,Dr. Zero 提出了一种完全脱离人类标注数据的解决方案。它不再依赖人工编写的问题或答案,而是利用现有的外部搜索引擎作为唯一的外部信号源。
该框架包含两个从同一基座模型初始化的智能体:
-
提议者(Proposer ):负责生成问题。它阅读随机文档,构建推理链,并提出需要搜索才能回答的问题。 -
求解者(Solver ):负责解决问题。它接收问题,使用搜索工具检索信息,并给出答案。
通过精心设计的奖励机制和优化算法,两者在训练过程中相互促进:求解者的能力提升迫使提议者生成更难的问题以获取高分,而更难的问题又反过来锻炼了求解者的搜索与推理能力,形成了一个自动化的课程学习(Curriculum Learning)过程。
2. Dr. Zero 框架详解
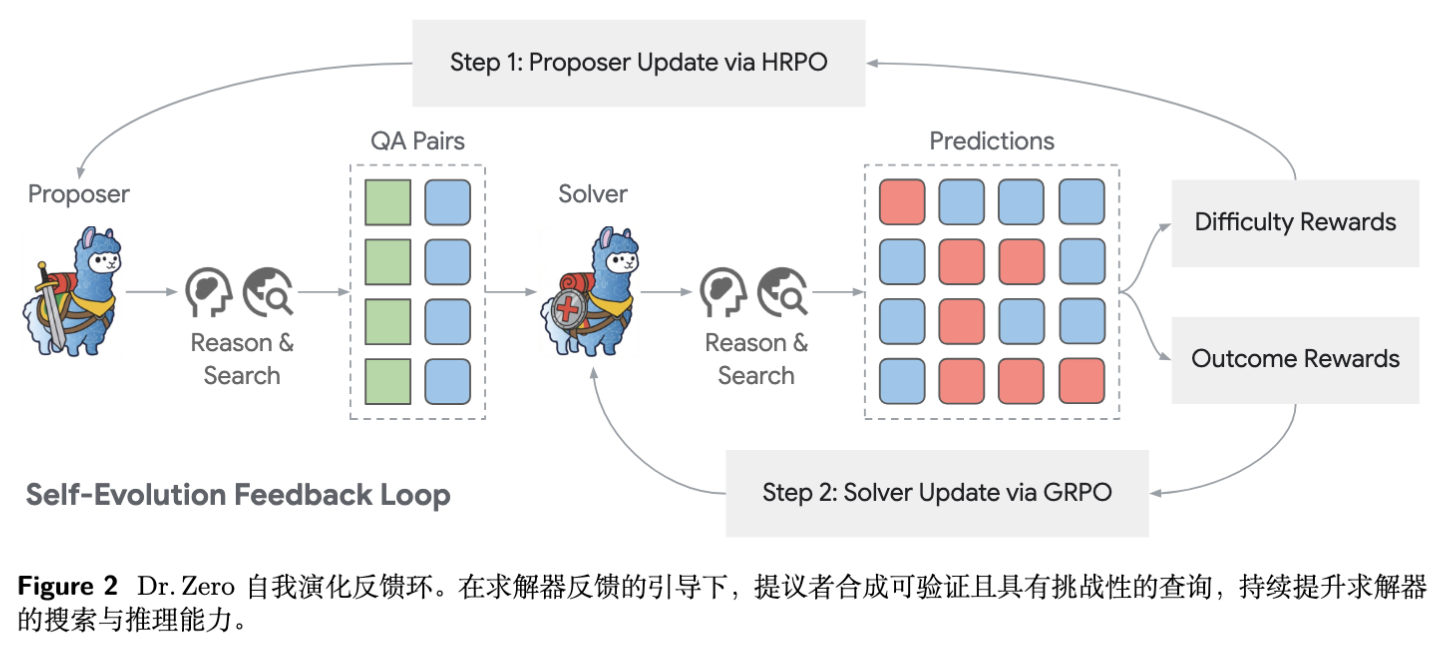
2.1 总体架构
Dr. Zero 的训练过程是一个迭代的闭环。假设我们有外部搜索引擎 。我们的目标是最大化两个智能体的期望回报:
其中, 是生成的问题, 是合成的“标准答案”(由提议者生成), 是求解者的预测答案。 是指示函数,表示预测是否正确。
注意,这里存在一个非对称的奖励结构:
-
求解者仅关注结果的正确性(Outcome Reward)。 -
提议者关注问题的质量、难度和可解性(Difficulty & Solvability Reward)。
2.2 提议者(Proposer)的设计与训练
提议者的核心任务是生成高质量的训练数据。为了避免生成无意义或过于简单的问题,Dr. Zero 引入了基于工具调用的多轮生成管线。
2.2.1 生成管线
提议者并非直接生成问题,而是模拟了一个逆向的推理过程:
-
输入:随机采样的一篇文档。 -
推理链构建:模型被要求从该文档中的实体出发(Hop 1),通过调用搜索工具寻找相关联的外部实体(Hop 2...Hop n),构建一条多跳推理链。 -
输出:基于这条推理链,生成一个需要 步推理的问题 及其答案 。
这种设计确保了生成的问题在逻辑上是连贯的,并且答案在搜索空间中是存在的(Verifiable)。
2.2.2 难度引导的奖励函数 (Difficulty-Guided Reward)
这是 Dr. Zero 的关键设计之一。为了训练提议者,需要评估它生成的问题好不好。评估标准基于求解者 的表现。
假设求解者对问题 采样了 次回答,其中有 次回答正确(即与 匹配)。提议者的奖励函数设计如下:
其中 。
解读该公式:
-
:这是一个门控条件。如果 (求解者全错),说明问题太难或无解,奖励为 0。如果 (求解者全对),说明问题太简单,奖励也为 0。 -
:当问题处于“可解但有挑战性”的区间时, 越小(即答对的次数越少,越难),奖励越高。这激励提议者探索求解者的能力边界。 -
:格式奖励(Format Reward),用于约束提议者遵循 <think>...</think>和<tool_call>...的结构规范。
2.2.3 分组相对策略优化 (Hop-Grouped Relative Policy Optimization, HRPO)
在训练提议者时,作者发现直接使用 GRPO(Group Relative Policy Optimization)效率极低。因为 GRPO 需要对同一个 Prompt 生成多条数据(Queries),然后对每个 Query 又需要求解者进行多次采样来评估奖励。对于涉及搜索的智能体,这会导致推理成本呈指数级增长。
此外,不同难度(跳数)的问题,其天然的通过率差异很大,直接混合计算基线(Baseline)会导致方差过大。
为此,Dr. Zero 提出了 HRPO。其核心思想是:不针对同一个 Prompt 进行多次采样,而是利用不同 Prompt 生成的数据,按“跳数(Hop)”进行分组,在组内计算相对优势。
HRPO 的目标函数为:
其中优势函数 定义为:
HRPO 的优势:
-
降低采样成本:对于每个文档 Prompt,提议者只需生成一个 QA 对。 -
降低方差:将 1-hop、2-hop、3-hop 的问题分开归一化。避免了用简单问题的奖励去惩罚复杂问题(复杂问题得分天然低,若与简单问题混在一起比较,会被错误地抑制)。
2.3 求解者(Solver)的训练
求解者的训练相对标准,使用了 GRPO 算法。
求解者的输入是提议者生成的 。求解者生成 条推理路径 。
其优势函数计算基于简单的二值奖励:
目标函数为:
这一步的关键在于:尽管数据是合成的,但通过 GRPO 的组内对比,求解者学会了哪种搜索路径和推理逻辑更有可能导出正确的合成答案。
3. 实验设置与实施细节
3.1 实验环境
-
基座模型:Qwen2.5-3B-Instruct 和 Qwen2.5-7B-Instruct。 -
搜索引擎:构建了一个基于 English Wikipedia 的本地搜索引擎。 -
检索器:E5-base 模型。 -
索引:Wiki 语料库。 -
Top-k:推理时检索 Top-3 文档。
-
-
训练参数: -
迭代轮次:3 轮自进化(Proposer 和 Solver 交替训练)。 -
Proposer 混合比例:1/2/3/4-hop 的问题比例默认为 4:3:2:1。 -
优化器:AdamW。
-
3.2 评测基准
为了全面评估,使用了两类数据集:
-
单跳问答 (One-hop): Natural Questions (NQ), TriviaQA, PopQA。 -
多跳问答 (Multi-hop): HotpotQA, 2WikiMultihopQA, MuSiQue, Bamboogle。
3.3 基线模型 (Baselines)
实验对比了多种范式:
-
Few-shot: Prompting, IRCoT, Search-o1, RAG。 -
Supervised: SFT, R1-Instruct (RL without search), Search-R1 (Supervised RL with search)。 -
Data-Free Baselines: SQLM* (Self-Questioning), R-Zero* (Self-Evolving Reasoning)。
注意:Dr. Zero 是其中唯一一个既不使用人工标注问题,也不使用人工标注答案的“真·零数据”方法。
4. 实验结果与分析
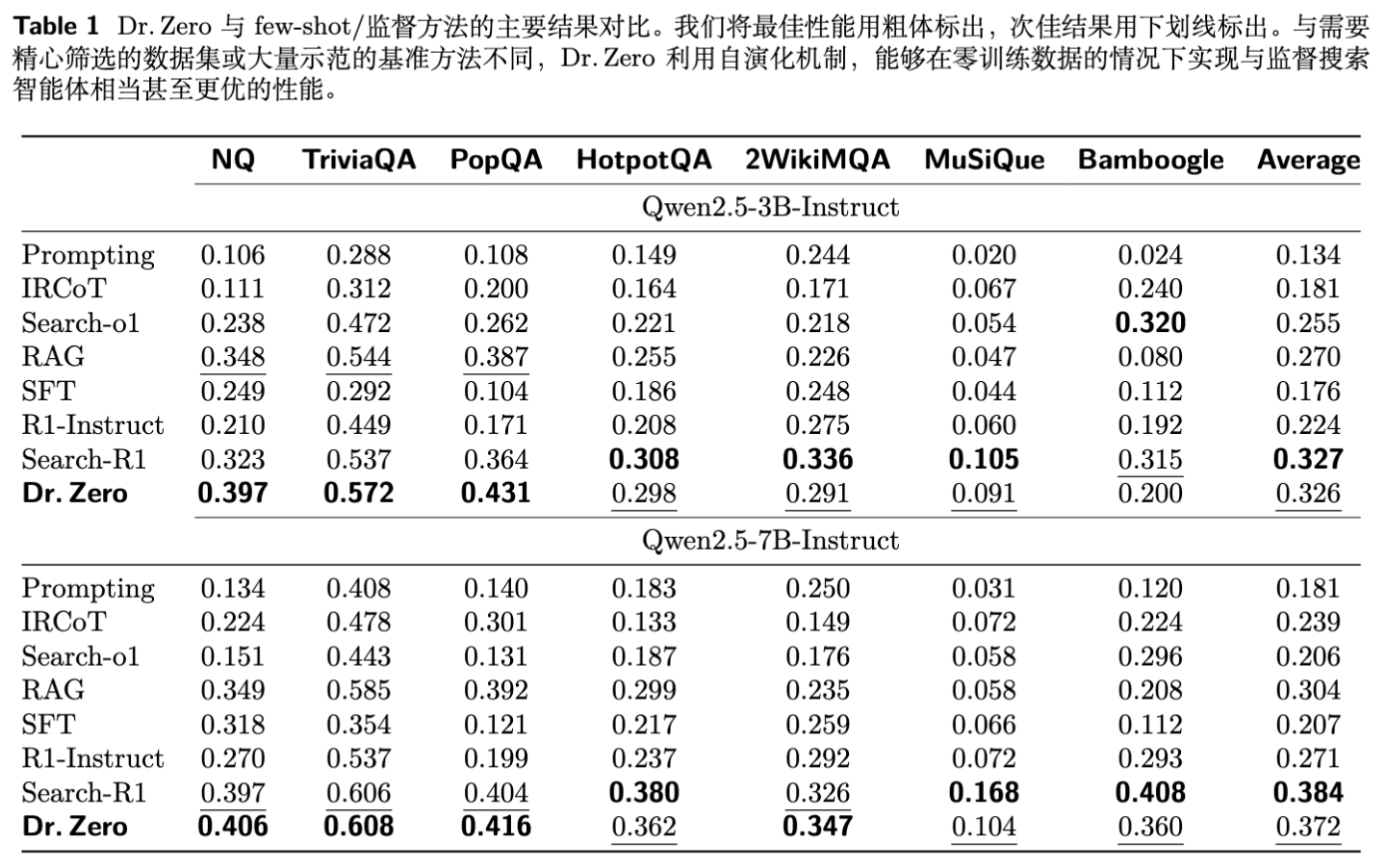
4.1 整体性能表现
实验结果令人印象深刻。Dr. Zero 在 Qwen2.5-3B 和 7B 模型上均取得了显著的性能提升。
-
超越监督基线:
-
在 Qwen2.5-3B 上,Dr. Zero 的平均得分(32.6%)与全监督的 Search-R1(32.7%)几乎持平。 -
在单跳任务(NQ, TriviaQA, PopQA)上,Dr. Zero 甚至超越了 Search-R1。例如在 NQ 上,Dr. Zero (39.7%) 显著优于 Search-R1 (32.3%)。这表明自进化生成的训练数据在覆盖面上可能比有限的监督数据更广。
-
-
多跳能力的涌现:
-
尽管没有见过任何人工编写的复杂多跳问题,Dr. Zero 在 HotpotQA 等数据集上依然表现出色,大幅领先于传统的 RAG 和 IRCoT 方法。 -
这验证了 Proposer 通过“逆向链式生成”构造的多跳数据,有效地迁移到了正向的问答推理中。
-
-
模型规模扩展性:
-
从 3B 到 7B,Dr. Zero 保持了性能增益。特别是在 2WikiMQA 这种极具挑战性的数据集上,7B 版本的 Dr. Zero (34.7%) 击败了 Search-R1 (32.6%)。
-
4.2 迭代训练的动态变化
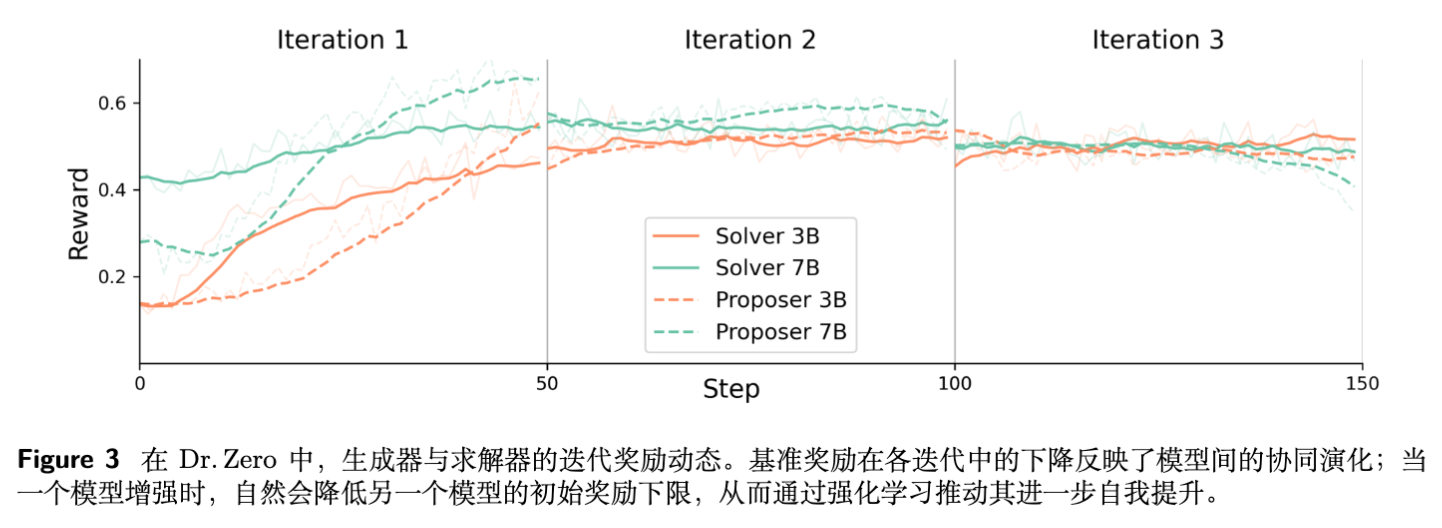
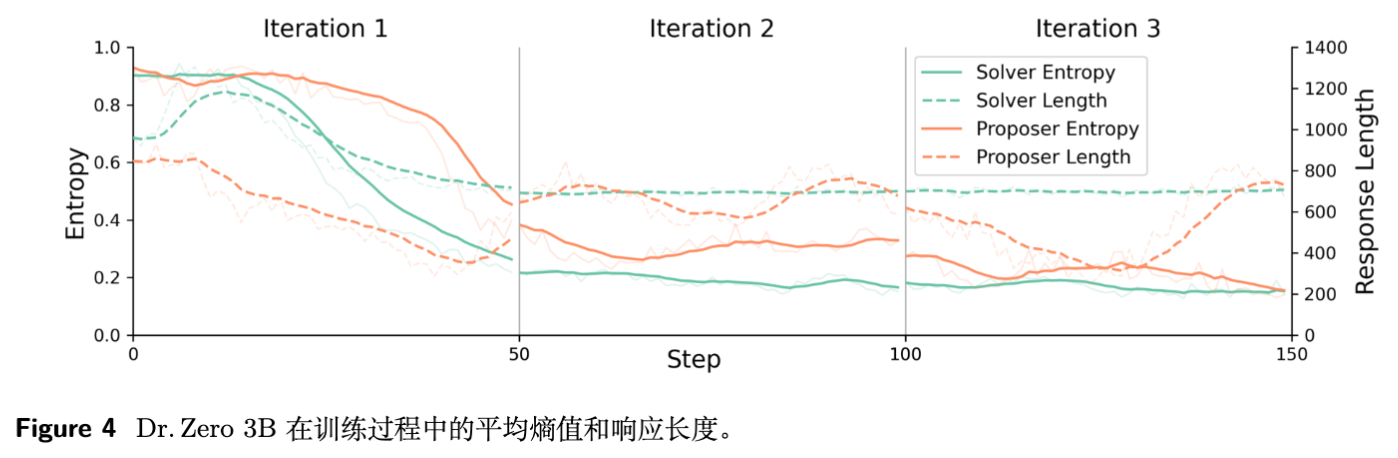
研究人员分析了三轮迭代中的性能变化:
-
Iter 1: 提升最显著。求解者迅速适应了搜索工具的使用。 -
Iter 2: 性能继续稳步提升,平均提升约 1.6% - 4.9%。 -
Iter 3: 性能开始趋于平稳,甚至在 7B 模型上出现轻微波动。
这揭示了自进化的局限性:随着迭代进行,模型生成的样本可能开始出现“自噬”或模式坍塌,且 Token ID 的不一致性(主要由于长文本生成的不稳定性)导致训练不稳。但总体而言,前两轮的增益证实了课程学习的有效性。
4.3 HRPO vs GRPO 的消融研究
这是一个非常关键的技术对比。
-
效率:HRPO 每个 Prompt 仅需生成 1 个问题,而 GRPO 需要生成多个(例如 4 个)并分别采样。实验显示,HRPO 将 Proposer 的采样计算成本降低了约 75%。 -
性能:尽管计算量大幅减少,HRPO 在下游任务上的平均得分(32.6%)甚至略高于使用标准 GRPO 训练的变体(32.0%)。 -
结论:按难度(Hops)分组进行基线归一化,比对同一 Prompt 进行多次采样的方差更小,且更能反映模型在特定难度层级上的相对优势。
4.4 奖励设计的有效性
作者对比了不同的 Proposer 奖励函数:
-
Dr. Zero (完整版): 30.4% (Iter 1 avg) -
去除格式奖励: 降至 28.9%。说明结构化输出(Think/Tool tags)对智能体至关重要。 -
使用抛物线奖励 (Parabolic): 略降。说明 Dr. Zero 提出的线性衰减奖励(鼓励 尽可能小但不为 0)比单纯追求 50% 通过率更有效,更能推动生成具有挑战性的样本。 -
去除初始文档: 性能大幅下降至 24.5%。这证明了基于文档(Seed Document)生成问题的必要性,它提供了事实的基础(Grounding),防止模型产生幻觉。
5. 深入讨论:为什么 Dr. Zero 能成功?
5.1 逆向生成的智慧
传统的问答数据构建是:人看到文档 -> 提出问题 -> 标注答案。
Dr. Zero 的 Proposer 实际上做的是:看到文档 -> 抽取实体 A -> 搜索关联实体 B -> 搜索关联实体 C -> 构造一条 A->B->C 的路径 -> 提出一个“从 A 出发找 C”的问题。
这种构造性(Constructive)的数据生成方式,天然地保证了逻辑链条的存在性和答案的确定性,避开了开放域生成中“不知答案对错”的验证难题。
5.2 难度与能力的动态平衡
Dr. Zero 的奖励函数 起到了动态调节阀的作用:
-
如果求解者太弱,大部分问题都答错 (),提议者得不到奖励,被迫降低难度。 -
如果求解者变强,原本的问题都答对 (),提议者奖励归零,被迫去寻找更偏僻的实体关联、更长的推理链。
这种对抗性的协同进化(Co-evolution)防止了训练停滞在低水平。
5.3 搜索作为唯一的监督信号
Dr. Zero 的成功挑战了“高质量推理必须依赖人类数据”的假设。它证明了:外部世界的知识(通过搜索引擎访问)加上模型自身的逻辑组合能力,足以通过强化学习引导出复杂的搜索和推理行为。 搜索引擎在这里充当了客观真理的裁决者。
6. 局限性与未来展望
尽管 Dr. Zero 效果显著,但论文也诚实地指出了当前的限制:
-
迭代稳定性:在第 3 轮及以后,性能提升边际递减,甚至出现不稳定。这可能与 RL 训练中的“奖励欺骗(Reward Hacking)”或样本多样性枯竭有关。如何实现无限的自进化(Open-ended Evolution)仍是未解之谜。 -
上下文长度限制:随着 Hop 数增加,搜索结果的上下文越来越长,容易超出模型的处理窗口或导致注意力分散。 -
依赖搜索引擎质量:模型的上限受限于搜索引擎的召回率和准确率。 -
长文本生成的格式崩坏:在生成极复杂的多跳推理链时,小参数模型(如 3B)容易丢失 XML 标签或截断输出。
未来的工作可能会集中在防止熵坍塌(Entropy Collapse)、引入更稳健的偏好优化算法,以及探索多模态搜索场景。
更多细节请阅读原文。
往期文章:


