
-
论文标题:Schoenfeld’s Anatomy of Mathematical Reasoning by Language Models -
论文链接:https://arxiv.org/pdf/2512.19995
TL;DR
今天解读一篇关于语言模型数学推理的结构分析的论文《Schoenfeld’s Anatomy of Mathematical Reasoning by Language Models》。该研究并未采用传统的准确率或 token 数量等结果导向指标,而是引入认知科学中的 Schoenfeld 片段理论,提出了 ThinkARM (Anatomy of Reasoning in Models) 框架。该框架将大语言模型(LLM)的推理思维链(CoT)抽象为 Read、Analyze、Plan、Implement、Explore、Verify、Monitor 和 Answer 等八个功能性片段。
通过对 15 个模型(包括 DeepSeek-R1、OpenAI o1/o3-mini 等)的推理轨迹进行句子级标注与量化分析,研究揭示了推理模型与非推理模型在结构上的本质差异:推理模型呈现出一种从抽象分析到具体执行再到评估控制的“心跳”模式(Heartbeat Pattern),并包含大量的迭代循环。研究进一步发现,Explore(探索)片段是不确定性的关键分支点,其后续流向(转向 Monitor 还是继续 Implement)与最终答案的正确性高度相关。此外,效率导向的模型优化(如蒸馏或长度惩罚)往往倾向于压缩评估性片段,从而改变了基础模型的推理拓扑结构。
1. 引言
随着大语言模型在复杂推理任务中表现的提升,尤其是思维链(Chain-of-Thought, CoT)技术的普及,模型生成的推理轨迹变得越来越长。当前的评估体系主要依赖于结果导向的指标,例如最终答案的准确率(Accuracy)、解决方案的长度或生成的总 Token 数。然而,这些宏观指标存在明显的局限性:
-
无法解释过程:由于缺乏中间层面的抽象,研究人员难以确定 CoT 中的哪些部分对应于问题理解、策略探索、具体执行或自我验证。 -
“过度思考”现象的不可解释性:近期的研究观察到,更长或更复杂的推理并不总是转化为更高的正确率。在缺乏结构化分析工具的情况下,难以界定何为有效的推理扩展,何为无效的冗余循环。 -
模型行为差异的模糊性:不同模型(如 DeepSeek-R1 与 GPT-4o)在生成风格上的差异,仅凭 Token 统计难以进行严格的定量比较。通常讨论的“抽象规划”与“具体执行”、“开放探索”与“评估检查”等概念,缺乏严谨的形式化定义。
为了解决上述问题,论文作者从认知科学中汲取灵感,采用了 Alan Schoenfeld 于 1985 年提出的片段理论(Episode Theory)作为归纳透镜。Schoenfeld 的理论最初用于分析人类(学生与数学家)解决数学问题的过程,将其概念化为一系列功能性片段。
2. 理论基础
2.1 认知科学的视角
Schoenfeld 的片段理论是数学教育和认知科学领域的经典框架。通过分析数百小时的人类“有声思维(think-aloud)”协议,Schoenfeld 发现,区分专家与新手的关键往往不在于领域知识的多少,而在于对知识的动态调节(Metacognitive Regulation)。该理论将解题过程描述为时间上排序的“片段(Episodes)”序列,这些片段揭示了解决者不断演变的目标结构和元认知决策。
原始的 Schoenfeld 框架包含 6 个主要片段:Read(读题)、Analyze(分析)、Plan(计划)、Implement(执行)、Explore(探索)和 Verify(验证)。后来增加了一个 Monitor(监控)片段,专门捕捉解决者的元认知行为。
2.2 ThinkARM 的分类学定义

鉴于 LLM 的训练目标通常包括生成特定格式的最终答案,论文在 Schoenfeld 原有 7 个片段的基础上,增加了 Answer(作答) 片段,形成了包含 8 个片段的完整分类学。这种细粒度的划分使得研究人员能够将结构性收敛(Answer)与过程性验证(Verify/Monitor)区分开来。
以下是 ThinkARM 框架中 8 个核心片段的详细定义与特征(基于论文附录及正文内容整理):
1. Read (读题)
-
定义:通常是初始阶段,专注于提取或重述给定的信息、条件和问题目标。它涉及对问题的理解,而不涉及推理策略的推断。 -
特征:直接复述问题内容,不包含分析或评估。通常出现在推理的开头,但也可能在中间出现以确认信息。 -
关键词:"The question asks...", "We are given...", "The goal is to..."
2. Analyze (分析)
-
定义:涉及构建或回忆相关理论,引入必要的符号,并根据问题陈述和现有知识推导关系。核心活动是解释或逻辑推断,为解决方案搭建舞台,但尚未涉及具体计算。 -
特征:强调概念和结构元素(如 "coprime", "boundary")。与 Explore 不同,Analyze 包含确定性的推断;与 Implement 不同,它不涉及具体数值计算。 -
关键词:"According to...", "We can define...", "This implies that..."
3. Plan (计划)
-
定义:宣布下一步骤或概述整个解决方案策略。它代表在实际执行之前对特定行动方案的承诺。 -
特征:由指令性动词和目标导向的语言主导。明确指出意图,通常使用第一人称或命令式语气。 -
关键词:"Next, we will...", "The plan is to...", "We should first..."
4. Implement (执行)
-
定义:操作阶段,执行已计划的策略。涉及设置基本符号、执行特定计算、构建图表、枚举可能性或使用数值、符号进行推导。 -
特征:由程序性和符号级语言主导。关注“做”数学,产生中间结果。 -
关键词:"Substituting x = 2...", "Therefore, P(1) = -1", "Expanding the expression..."
5. Explore (探索)
-
定义:以产生潜在想法、猜测、类比或尝试性计算为特征,这些尝试后来可能被放弃。模型在未承诺特定解决路径的情况下探索不同途径。 -
特征:以前瞻性的、假设驱动的表达为主,标记为不确定性和缺乏承诺。通常涉及头脑风暴。 -
关键词:"Maybe we can try...", "Perhaps we could use...", "What if we consider..."
6. Verify (验证)
-
定义:涉及判断所得结果或所用方法的正确性、有效性或简单性。可能包括检查答案、使用替代方法计算或估计边界。 -
特征:具有决定性的评估语言(如 "wrong", "consistent"),明确检查逻辑正确性。 -
关键词:"Let me double-check...", "This is consistent with...", "Does this make sense?"
7. Monitor (监控)
-
定义:捕捉典型的短语或感叹词,指示模型的自我监控、犹豫或在不同片段交界处的反思。通常不包含实质性的解题内容。 -
特征:与元认知层面的不确定性或进度跟踪相关。作为连接内容密集型阶段的桥梁。 -
关键词:"Hmm...", "Wait...", "Let me think.", "Okay..."
8. Answer (作答)
-
定义:用于明确陈述问题的答案或结论的句子。 -
特征:直接提供结果,标志着收敛。 -
关键词:"Therefore, the answer is...", "Hence, the result is..."
3. 数据集构建与自动化标注流程
为了在大规模数据集上应用上述分类学,研究团队构建了一个自动化、可扩展的标注管道。
3.1 数据采样与模型覆盖
研究从 Omni-MATH 基准测试集中按领域分层采样了 100 个问题,以保持领域覆盖率和问题多样性。针对这 100 个问题,研究使用了 15 个广泛使用的 LLM 生成推理轨迹,包括:
-
推理模型 (Reasoning Models) :DeepSeek-R1, DeepSeek-R1-Distill-Qwen 系列 (1.5B, 7B, 32B), QwQ-32B, Phi-4-Reasoning, GPT-o1-mini, GPT-o3-mini 等。 -
非推理模型 (Non-Reasoning Models) :GPT-4o, Gemini-2.5-Flash, Qwen-2.5-32B 等。
这涵盖了开源与闭源、原生推理与蒸馏变体、以及标准指令遵循模型。
3.2 黄金数据集与自动标注器验证
为了确保自动标注的可靠性,研究者首先构建了一个人工验证的黄金数据集(Gold Set)。
-
人工标注:从 100 个问题中选取 9 个代表性问题,人工标注了所有模型生成的推理轨迹,共计 7,067 个句子。 -
模型评估:评估了 GPT-4o, GPT-5 (OpenAI, 2025b), Gemini-2.5 等模型作为自动标注器的性能。
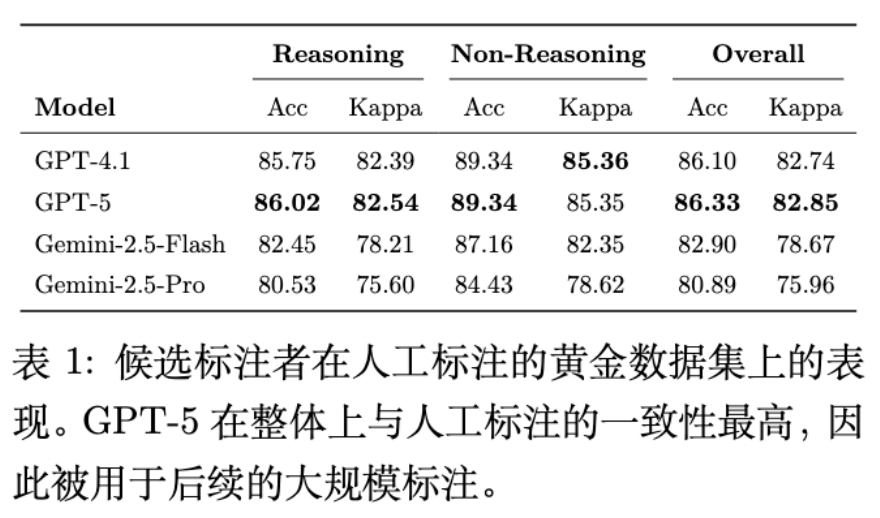
结果显示,GPT-5 在与人工标注的一致性上表现最佳(Overall Kappa 约为 82.85),因此被选定为全规模标注的工具。
3.3 标注机制
ThinkARM 的标注过程采用了批处理提示(Batch Prompting)策略。在标注每个句子时,模型不仅被要求生成类别标签,还需生成理由(Rationale),以确保标注的可靠性。每个句子会结合其上下文(Guidebook 定义、先前句子的标注结果)进行分类。
最终,该研究生成了包含 410,991 个句子的标注语料库,这也是目前首个大规模的、基于认知理论的 LLM 推理行为数据集。
4. 推理动态的定量分析 (RQ1 & RQ2)
基于 ThinkARM 框架,研究者深入分析了 LLM 的认知动态,揭示了推理模型与非推理模型在行为上的显著差异。
4.1 词汇与语义分布
通过对不同片段的高频 Token 进行词云可视化,研究证实了 ThinkARM 捕捉到了具有明显语义区分度的认知模式。

-
Analyze vs. Implement:Analyze 充满了 "boundary", "coprime" 等概念性词汇,反映了抽象问题的表征构建;而 Implement 则由具体变量和数值计算主导。这表明模型在推理过程中确实发生了从概念思维到具体实现的转变。 -
Verify vs. Monitor:Verify 包含 "wrong", "correct" 等明确的判断词;而 Monitor 更多是 "confusing", "messy" 等反映状态感知的词汇。这种区分支持了将验证与监控作为两种不同的元认知模式处理。
4.2 时间动态
通过将推理轨迹归一化为 0-100% 的进度刻度,研究发现所有推理模型在片段分布上表现出一种一致的粗粒度时间组织模式,作者称之为“机器推理的心跳(Cognitive Heartbeat)”。
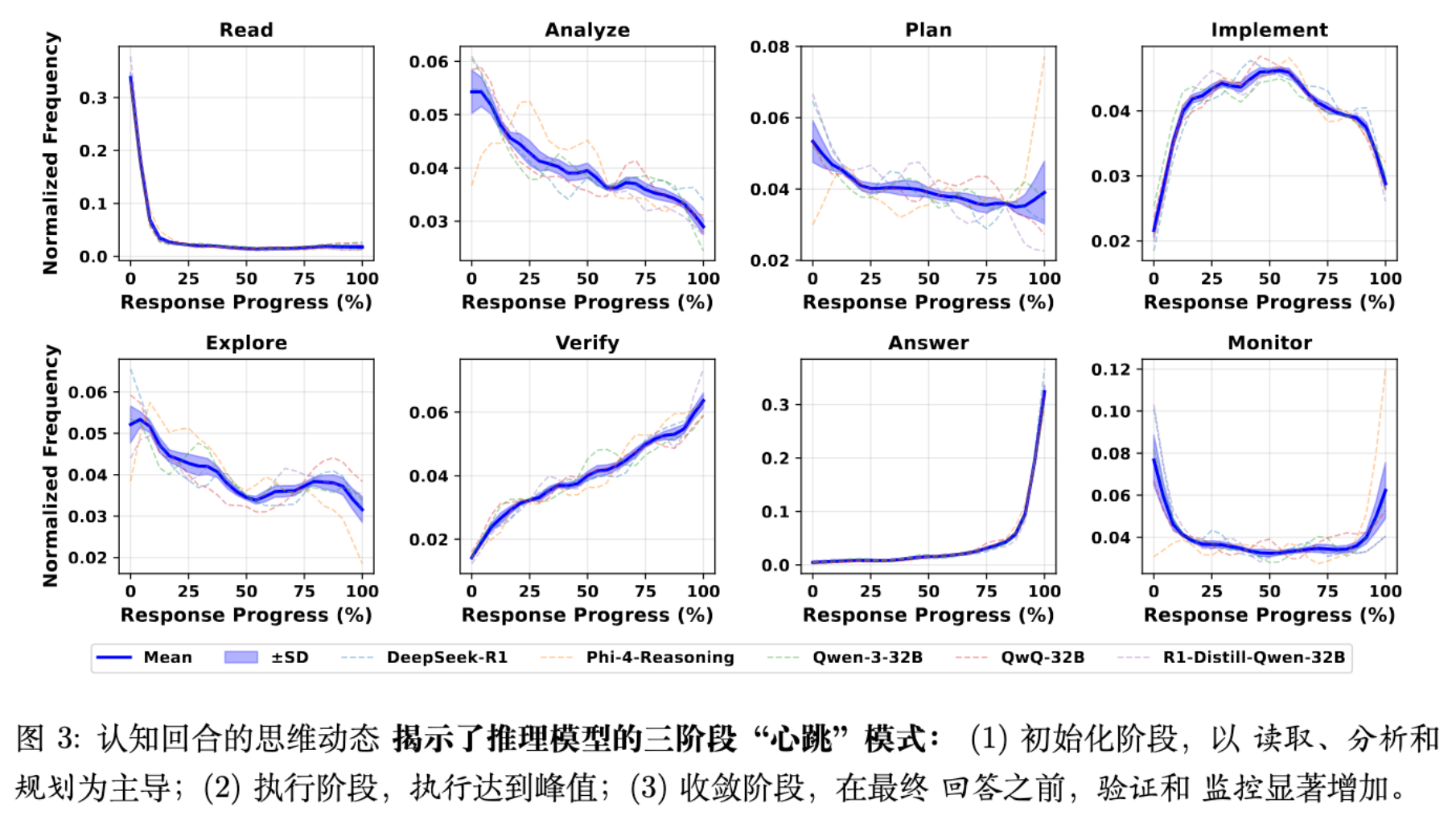
该模式主要分为三个阶段:
-
早期脚手架(Early-stage Scaffolding):
-
Read:在起始阶段急剧下降。 -
Analyze & Plan:逐渐衰减,表明结构化推理不仅限于开头的规划,而是延伸到前段。 -
Explore:通常前置,符合“早期假设搜索”的特征。
-
-
中期执行(Mid-stage Execution):
-
Implement:呈现特征性的钟形曲线(Bell Shape),在推理轨迹的中部达到峰值。这构成了响应的“骨干”,连接了早期的探索和后期的验证。
-
-
晚期收敛(Late-stage Convergence):
-
Verify:随着进度推进稳步上升。 -
Monitor:呈现 U 型分布,在开头和结尾较高。 -
Answer:在接近尾声时急剧上升。
-
这种从抽象推理(Abstract Reasoning)到具体执行(Concrete Execution),最后到评估控制(Evaluative Control)的功能演进,在不同推理模型中具有高度的一致性。
4.3 推理模型 vs. 非推理模型
研究对比了推理模型(如 DeepSeek-R1)与标准指令遵循模型(如 GPT-4o)在片段资源分配上的差异。
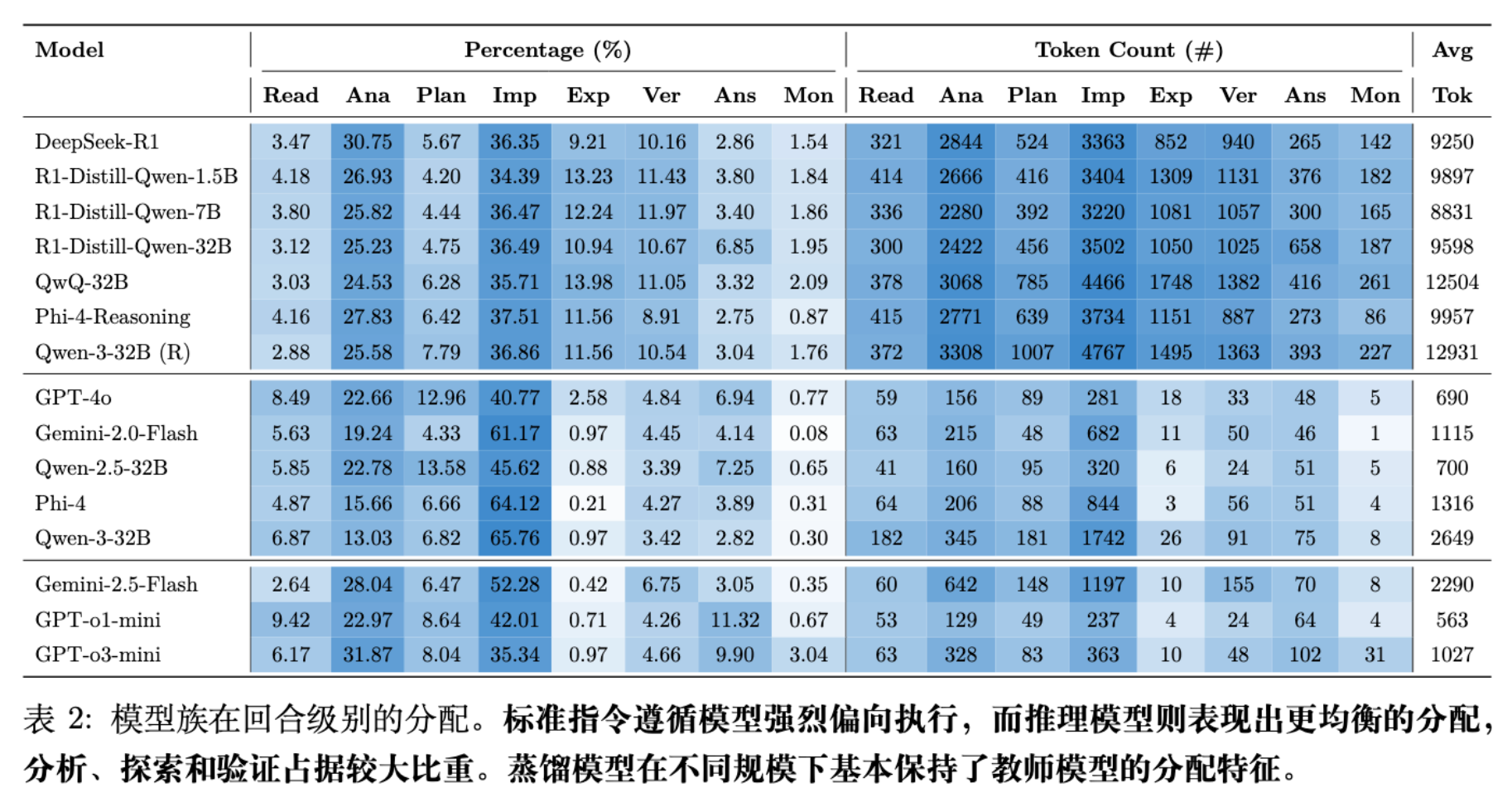
-
非推理模型(Standard Instruction-Following Models):
-
呈现强烈的 Implement-heavy 特征。例如,GPT-4o 将约 40% 的 Token 分配给 Implement,而 Explore 和 Verify 的比例极低。 -
行为模式主要是“前馈(Feed-forward)”的,即理解问题后直接转向执行,缺乏回溯和检查。
-
-
推理模型(Reasoning Models):
-
分配更加均衡。它们将大量预算分配给 Analyze(约 20-30%)和 Explore(约 10-14%),同时保持了可观的 Verify 比例。 -
关键发现:区分推理模型与非推理模型的关键不仅仅是响应的长度,而是预算如何在推理行为之间分配。推理模型并非简单地拉长执行过程,而是插入了大量的分析、探索和验证环节。
-
-
蒸馏模型(Distilled Models):
-
观察到蒸馏模型(如 R1-Distill-Qwen-1.5B)保留了与其“教师”模型相似的片段分配概况。这表明蒸馏过程不仅传递了答案,还传递了情节层面的推理结构。
-
4.4 转换模式与 N-gram 分析
为了捕捉片段之间的微观交互结构,研究计算了片段序列的 N-gram 模式与模型组别之间的互信息(Mutual Information, MI)。
公式定义如下:
其中 表示特定的片段 N-gram 是否存在, 表示模型组别。
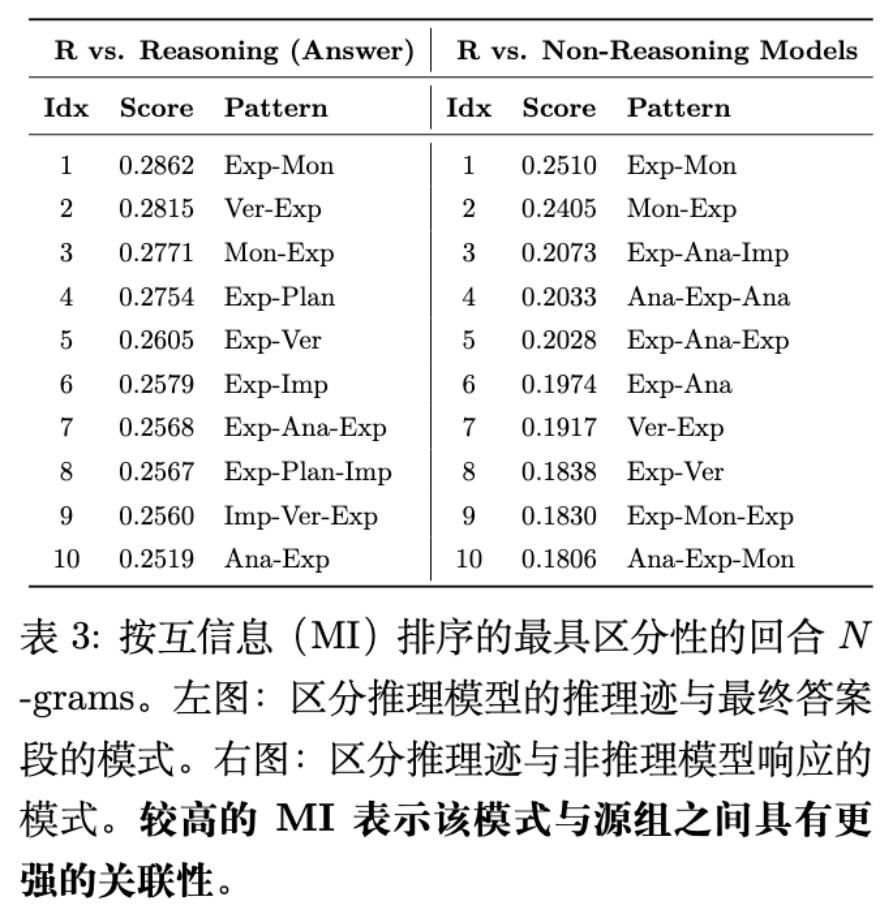
分析结果显示:
-
循环结构(Loops):推理模型的轨迹中频繁出现涉及 Explore, Monitor, 和 Verify 的短反馈循环。例如,Exp-Mon(探索-监控)和 Ver-Exp(验证-探索)是区分推理模型的显著特征。这表明验证往往不是终点,而是引发新一轮探索的契机。 -
线性结构:非推理模型的响应由前馈转换主导,缺乏这种交织的探索-评估循环。
5. 应用案例研究 (RQ3)
ThinkARM 框架不仅用于描述性分析,还可用于诊断模型性能与效率优化的深层影响。
5.1 正确性诊断
研究者通过构建逻辑回归模型(Lasso Logistic Regression),利用提取的片段特征(如片段占比、转换矩阵)来预测推理结果的正确性。
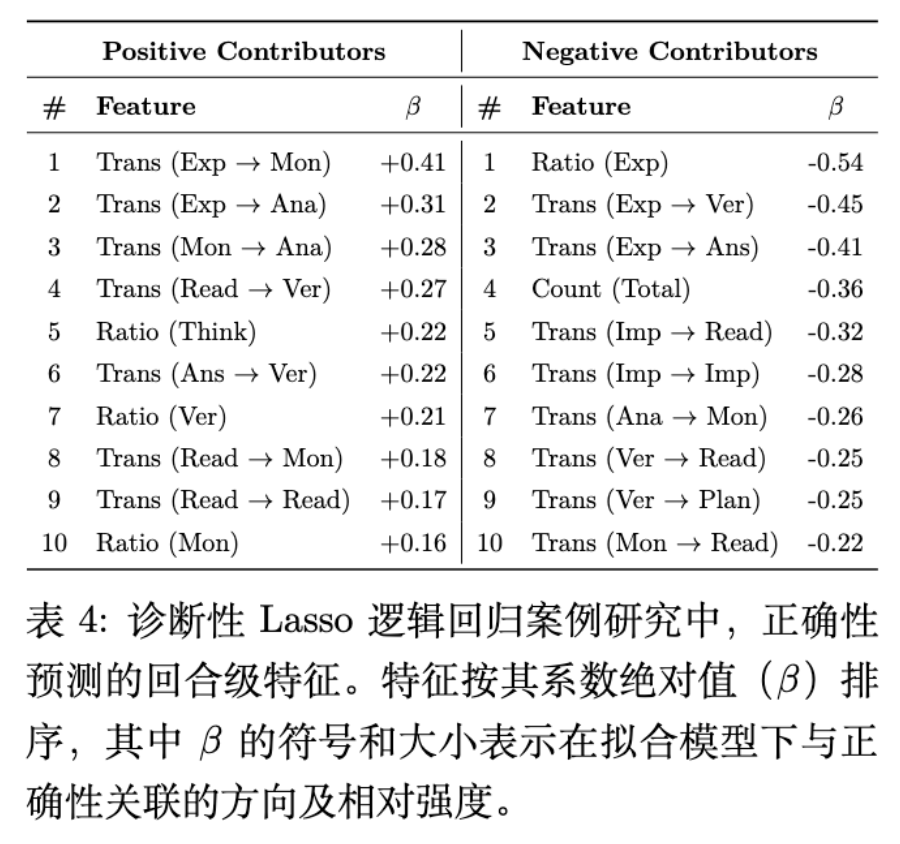
主要发现:
-
Explore → Monitor / Analyze (正向) :当 Explore 紧接着 Monitor 或 Analyze 时,与正确结果强相关。这表明,当模型在探索中遇到不确定性时,如果能够通过元认知监控(Monitor)暂停并重新进行概念分析(Analyze),往往能通向正确路径。 -
Explore → Verify (负向):反之,Explore → Verify 是一个负向指标。这可能反映了模型在尚未形成连贯假设的情况下就过早进行验证,或者验证了错误的探索路径。 -
Explore 占比 (负向) :过高的 Explore 比例本身是高风险指标,暗示模型陷入了无休止的尝试而未能收敛。 -
首尾验证:Read → Verify 和 Answer → Verify 是正向特征,表明在推理开始(确认理解)和结束(确认答案)时的显式检查有助于提升正确率。
这一结论强调了 Explore 作为一个关键的分支点(Branching Point):正确解通常将探索路由至监控或重分析,而错误解则倾向于继续执行或过早终止。
5.2 效率模型分析:被压缩的是什么?
针对当前流行的提高推理效率的方法(如 L1 长度惩罚、ThinkPrune 剪枝、动态计算分配),ThinkARM 提供了独特的分析视角。研究对比了基线模型(R1-Distill-Qwen-1.5B)与三种效率优化策略:
研究者以 R1-Distill-Qwen-1.5B 为基线,对比了三种代表性的效率优化策略,并利用 ThinkARM 揭示了它们在认知结构上的显著差异:
-
L1 Regularization (Aggarwal and Welleck, 2025a) :
-
原理:这是一种基于强化学习的方法,在其奖励函数中引入了显式的长度惩罚项(即 )。它直接迫使模型用更少的 Token 答对问题。 -
后果:该方法最为“激进”。ThinkARM 分析显示,它为了追求短长度,大幅削减了 Verify(验证) 和 Analyze(分析) 片段,因为这些片段往往不直接产出最终答案。结果导致模型变成了一个线性执行器(Implement-heavy),丧失了通过回溯检查错误的能力。
-
-
ThinkPrune (Hou et al., 2025) :
-
原理:该方法同样利用强化学习,旨在剪枝长思维链。它通过训练模型识别并移除对最终答案无贡献的中间步骤,同时施加 Token 预算限制。 -
后果:与 L1 类似,ThinkPrune 显著抑制了复杂的循环结构(如 Analyze Verify Analyze)。数据表明,它倾向于切断那些探索性和验证性的思维回路。
-
-
Dynamic Compute (Arora and Zanette, 2025) :
-
原理:该策略侧重于根据任务难度动态分配计算资源,或通过训练让模型学习更高效的推理路径,而非单纯地惩罚长度。 -
后果:这是三种方法中表现最好的。它虽然也减少了总 Token 数,但较好地保留了基础模型的片段分布和拓扑结构(如表 5 所示,Verify 的比例下降较少)。这表明它实现了一种更“智能”的压缩,保留了必要的认知骨架。
-
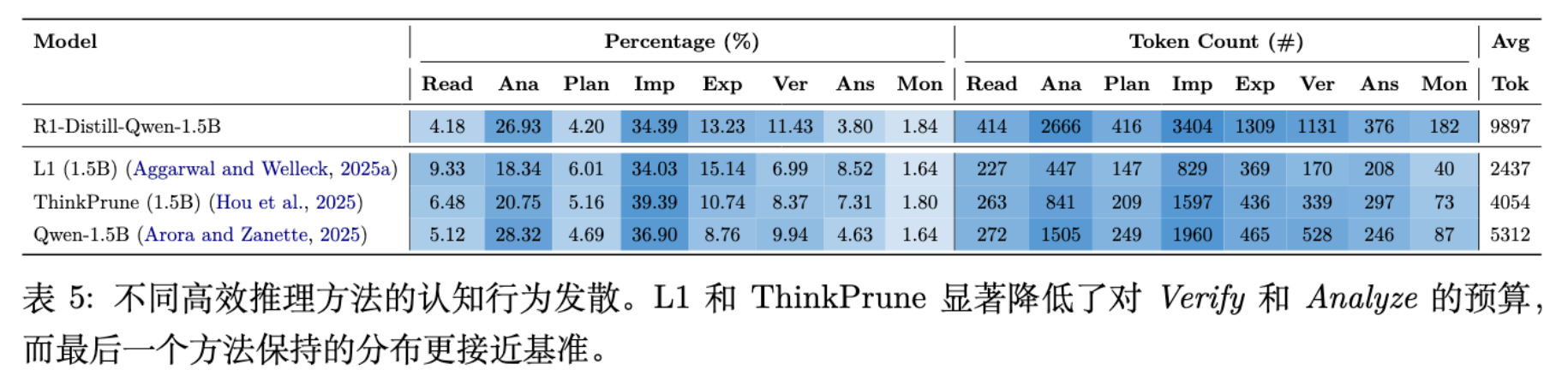
核心结论:
效率优化并非行为中立(Not Behaviorally Neutral)。 简单的长度惩罚(如 L1)倾向于以牺牲模型的元认知能力(验证与反思) 为代价来换取速度。这种优化虽然在表面指标(Token 数)上很漂亮,但实质上破坏了推理的稳健性结构,使得模型在面对需要反复推敲的难题时可能更加脆弱。
更多细节请阅读原文。
往期文章:


