
-
论文标题:Black-Box On-Policy Distillation of Large Language Models -
论文链接:https://arxiv.org/pdf/2511.10643
TL;DR
今天分享一篇微软研究院发布的最新论文《Black-Box On-Policy Distillation of Large Language Models》。针对大语言模型(LLM)蒸馏中常见的黑盒场景(只能获取教师模型的输出文本,无法获取Logits或梯度),作者提出了一种名为 GAD (Generative Adversarial Distillation) 的生成对抗蒸馏框架。
GAD 将学生模型视为生成器(Generator),将一个判别器(Discriminator)视为动态奖励模型,通过极小极大博弈(Minimax Game)进行训练。该方法在不访问教师模型内部参数的情况下,实现了 On-Policy(在线策略) 学习。实验表明,GAD 在 LMSYS-Chat 等基准测试上稳定超越了传统的序列级知识蒸馏(SeqKD),并在域外(OOD)泛化任务上表现出更强的鲁棒性。值得注意的是,经过 GAD 蒸馏的 Qwen2.5-14B-Instruct 在自动评估中表现接近其教师模型 GPT-5-Chat。
1. 背景与研究动机
1.1 大模型蒸馏的两种范式
知识蒸馏(Knowledge Distillation, KD)是提升小模型(Student)性能、使其具备大模型(Teacher)能力的常用手段。根据学生模型对教师模型访问权限的不同,KD 主要分为两类:
-
白盒蒸馏(White-box Distillation): 学生模型可以访问教师模型的内部状态,如 Logits(预测概率分布)、Hidden States(隐藏层状态)或 Attention Maps。经典方法包括最小化正向 KL 散度(Forward KLD)或逆向 KL 散度(Reverse KLD)。 -
黑盒蒸馏(Black-box Distillation): 教师模型通常是专有的 API 模型(如 GPT-5, Claude 等),学生模型仅能获取教师生成的文本回复,无法访问概率分布。
1.2 现有黑盒方法的局限性
在黑盒场景下,最主流的方法是 序列级知识蒸馏(Sequence-Level Knowledge Distillation, SeqKD)。其本质是在教师生成的“指令-回复”对上进行有监督微调(Supervised Fine-Tuning, SFT)。
尽管 SeqKD 简单有效,但它存在显著的理论和实践缺陷:
-
模仿学习的局限: SeqKD 属于离线策略(Off-Policy)学习,学生模型仅模仿教师的固定输出。 -
暴露偏差(Exposure Bias): 训练时学生由教师强制引导(Teacher Forcing),但在推理时学生需基于自己生成的历史进行预测。这种不一致导致分布偏移。 -
缺乏自身反馈: 白盒蒸馏中的 On-Policy 方法(如 MiniLLM)表明,让学生模型从自身生成的样本中学习(即 Mode-Seeking)能显著提升性能。但在黑盒设置下,由于缺乏教师的 Logits 作为细粒度反馈,学生模型难以评估自身生成内容的质量,导致 On-Policy 学习难以实施。
1.3 核心问题
如何在没有任何概率级监督信号(Logits)的黑盒条件下,让学生模型实现 On-Policy 学习,从而提取更深层的教师知识并具备更好的泛化能力?
这正是 GAD 框架试图解决的问题。
2. GAD:生成对抗蒸馏框架
作者提出了 Generative Adversarial Distillation (GAD) ,借鉴生成对抗网络(GANs)的思想,结合强化学习(RL)框架,构建了一个适用于 LLM 的黑盒蒸馏范式。
2.1 核心定义
我们将蒸馏过程建模为条件文本生成任务。
-
输入提示(Prompt): ,采样自数据集 。 -
教师回复(Teacher Response): ,由教师模型生成。 -
学生模型(Generator): ,参数化为策略,生成回复 。 -
判别器(Discriminator): ,一个打分模型,用于区分教师回复和学生回复的质量。
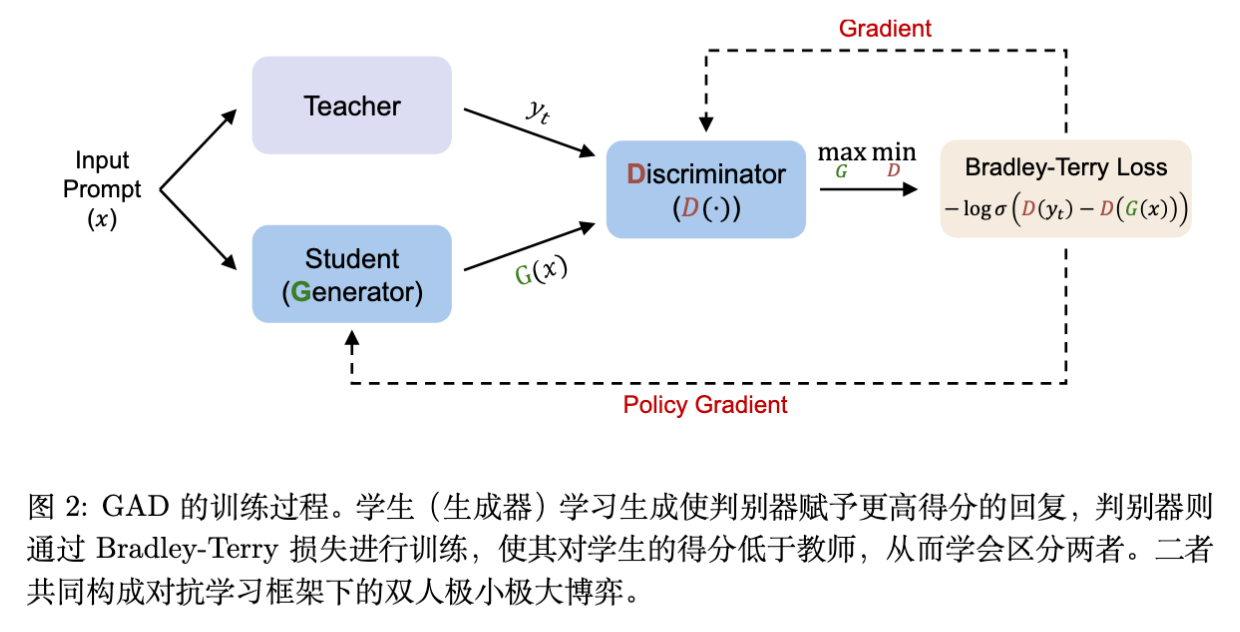
2.2 理论形式化:极小极大博弈
GAD 建立了一个极小极大博弈(Minimax Game)。
-
判别器 的目标: 尽可能准确地识别出哪个回复来自教师(高质量),哪个来自学生(低质量)。 -
生成器 的目标: 生成能够“欺骗”判别器的回复,使其生成的回复被判别器判定为与教师回复同等质量或更高。
价值函数 定义如下:
其中, 是 Sigmoid 函数。判别器 输出一个标量分数,表示回复 相对于提示 的质量。
为了优化上述目标,作者采用了 Bradley-Terry (BT) 模型来建模成对偏好(Pairwise Preference)。这意味着判别器的训练目标是最大化教师回复得分高于学生回复得分的概率。
2.3 与强化学习的联系
GAD 可以被无缝映射到强化学习(RL)框架中,具体对应关系如下:
| RL 概念 | GAD 对应组件 |
|---|---|
| Policy Model (策略) | 学生模型 (Generator) |
| Reward Model (奖励模型) | 判别器 (Discriminator) |
| Reward (奖励值) |
关键区别:
在传统的 RLHF(Reinforcement Learning from Human Feedback)中,奖励模型通常在训练前基于静态偏好数据训练好,并在随后的 PPO 阶段保持 冻结(Fixed)。
而在 GAD 中,判别器(奖励模型)是 On-Policy 的,它与学生模型 共同进化(Co-evolves)。
-
学生模型在变强,生成的回复越来越像教师。 -
判别器必须不断适应新的学生分布,挖掘更细微的特征来区分二者。 -
这种动态对抗过程提供了持续且适应性强的反馈信号,有效防止了固定奖励模型常见的 Reward Hacking(奖励劫持) 问题。
3. 算法实现细节
3.1 判别器训练
判别器 通常基于与学生模型相同的架构初始化,并在最后一层增加一个标量预测头(Prediction Head)。对于输入对 ,取序列最后一个 Token 的输出作为分数。
判别器的损失函数:
这等价于优化判别器,使其给教师回复 的打分显著高于学生回复 。
3.2 生成器训练
由于 的采样过程是不可导的,无法直接通过反向传播优化生成器。因此,作者采用策略梯度(Policy Gradient)方法。生成器的优化目标是最大化判别器给出的奖励:
在实验中,作者使用了 GRPO (Group Relative Policy Optimization) 算法(DeepSeekMath 提出的 PPO 变体)。具体来说,对于每个提示 ,采样一组学生回复 ,并计算其相对优势(Advantage)。
第 个回复的奖励 ,其优势 计算为:
生成器的梯度更新目标为(省略 KL 惩罚项):
3.3 训练流程与 Warmup 策略
为了保证对抗训练的稳定性,预热(Warmup) 阶段至关重要。如果直接从零开始对抗,判别器很容易区分两者,或者生成器输出质量太差导致训练坍塌。
Warmup 阶段:
-
生成器: 使用 SeqKD(即在教师回复 上进行 Cross-Entropy Loss 训练)微调 1 个 epoch。这为学生模型提供了一个较好的初始策略,使其具备基本的指令遵循能力。 -
判别器: 使用预热后的生成器生成的样本与教师样本构建配对数据,使用 Bradley-Terry Loss 训练。
GAD 训练阶段:
交替进行以下步骤直至收敛:
-
采样一批数据,学生模型生成回复。 -
使用生成的回复计算奖励,利用 GRPO 更新生成器 。 -
利用同一批生成数据和教师数据,更新判别器 。
算法伪代码如下:
Algorithm 1: GAD
输入: 蒸馏数据集 T={(x, yt)}, 学生 G, 判别器 D
输出: 训练好的学生 G
# Warmup Stage
For batch (x, yt) in T:
Update G with CE loss on yt
Update D with BT loss (Eq 3)
# GAD Training Stage
Repeat until convergence:
For batch (x, yt) in T:
y_s = Sample(G(x))
Reward = D(y_s)
Update G using Reward via RL (GRPO)
Update D using (yt, y_s) via BT loss
End For
Return G
4. 实验设置
为了验证 GAD 的有效性,作者进行了广泛的实验。
-
数据集: LMSYS-Chat-1M-Clean(从 LMSYS-Chat-1M 清洗得到的高质量指令集)。 -
训练集:200K 样本。 -
测试集:LMSYS-Chat(500条),以及 OOD 测试集 Dolly, SelfInst, Vicuna。
-
-
教师模型: -
GPT-5-Chat(OpenAI 的专有模型,在论文截稿时 Chatbot Arena 排名第九,代表强黑盒教师)。 -
Qwen2.5-14B-Instruct(作为开源教师的对照实验)。
-
-
学生模型: -
Qwen2.5 系列 (3B, 7B, 14B Instruct)。 -
Llama3 系列 (Llama-3.2-3B, Llama-3.1-8B Instruct)。
-
-
基准对比 (Baselines): -
Before Distill: 原始的 Instruction Tuned 模型。 -
SeqKD: 标准的序列级知识蒸馏(SFT on teacher outputs)。
-
-
评估指标: -
GPT-4o Score: 使用 GPT-4o 作为裁判,对输出进行 1-10 打分。 -
Human Evaluation: 人工成对评估(Win/Tie/Loss)。
-
5. 实验结果
5.1 主实验结果:全面超越 SeqKD
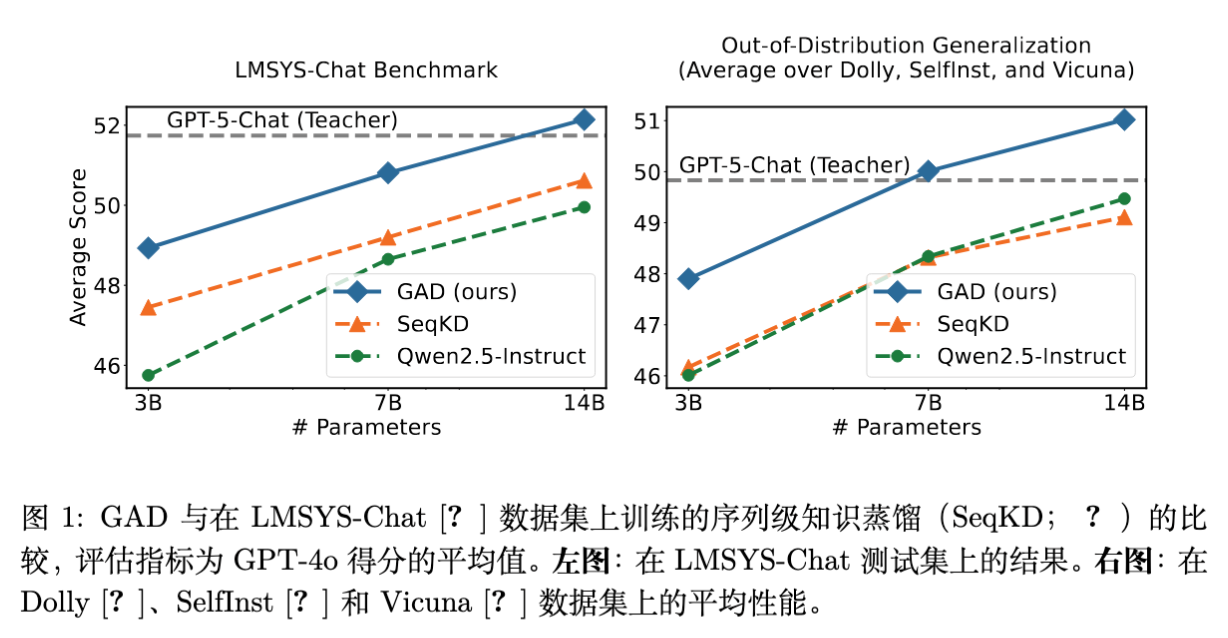
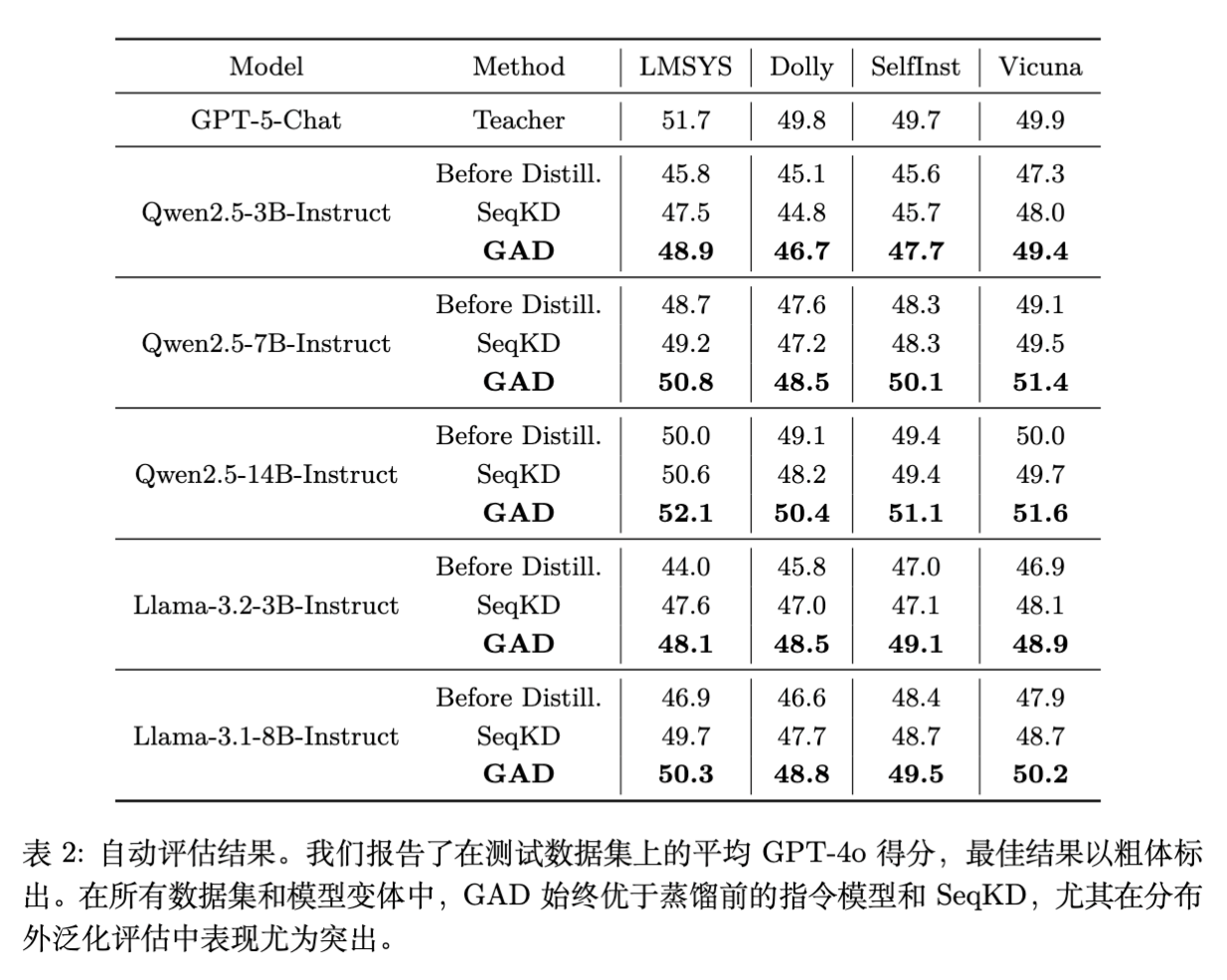
实验结果显示 GAD 在所有模型尺寸和数据集上均优于基线。
-
LMSYS-Chat (In-Domain):
-
Qwen2.5-7B-Instruct 使用 GAD 后,得分为 50.8,超过了使用 SeqKD 的同模型 (49.2),甚至逼近了使用 SeqKD 的 Qwen2.5-14B (50.6)。 -
Qwen2.5-14B-Instruct 使用 GAD 后得分达到 52.1,超过了教师模型 GPT-5-Chat 的 51.7(注:这在自动评估中是可能的,通常意味着学生模型更好地迎合了裁判的偏好,或者在格式上更规范,同时也说明 GAD 极好地提取了教师能力)。
-
-
OOD 泛化能力 (Dolly, SelfInst, Vicuna):
-
SeqKD 在某些 OOD 数据集上相较于“蒸馏前”的模型提升微小,甚至出现负增长(例如 Qwen2.5-3B 在 Dolly 上:Before 45.1 -> SeqKD 44.8)。这证实了 SFT 容易过拟合训练数据的分布,导致泛化能力受损。 -
相比之下,GAD 在 OOD 数据集上保持了显著的增长。例如 Qwen2.5-3B 在 Dolly 上提升至 46.7。这归功于 RL 探索机制带来的策略稳健性。
-
5.2 人工评估
在人工评估中,针对 Qwen2.5-7B/14B 和 Llama-3.1-8B,GAD 产生的回复在超过 50% 的情况下优于基线模型,失败率(Loss Rate)低于 30%。这与自动评估结果一致。
6. 深入分析与讨论
为了探究 GAD 为什么比 SeqKD 好,作者进行了多项深入分析,这是论文最精彩的部分。
6.1 局部模式 vs. 全局风格
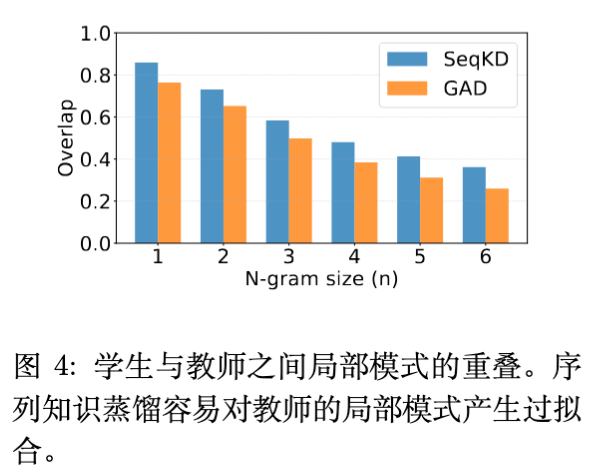
作者计算了学生模型输出与教师模型输出的 N-gram 重叠率(F1 Score)。
-
现象: SeqKD 模型的 N-gram 重叠率显著 高于 GAD 模型。 -
结论: 较高的 N-gram 重叠率并不代表更好的质量。这说明 SeqKD 倾向于机械地记忆教师的词汇搭配和局部短语(Local Lexical Patterns)。相反,GAD 虽然在逐词匹配上不如 SeqKD,但在语义评分上更高,说明 GAD 学习到了教师的 全局推理模式和风格特性,而非死记硬背。
6.2 Mode-Seeking vs. Mode-Covering
为了从理论直觉上解释二者区别,作者设计了一个基于高斯混合分布的玩具实验。
-
教师分布: 一个离散的高斯混合分布(多峰)。 -
学生任务: 在没有概率访问权的情况下拟合教师分布。
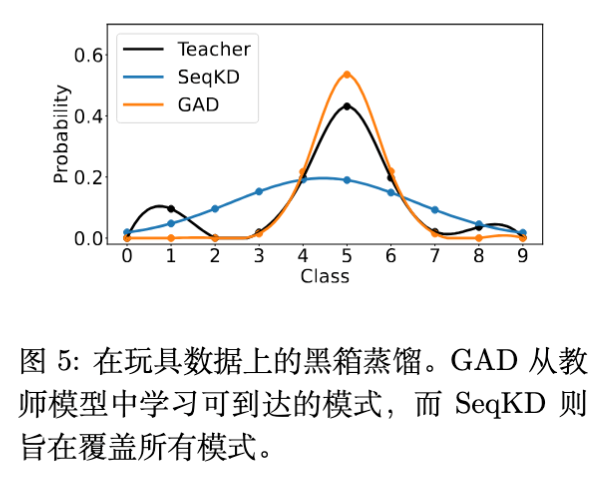
-
SeqKD (SFT) 的行为: 表现出 Mode-Covering(模式覆盖) 行为。它试图用自己的概率质量去覆盖教师的所有峰值。由于学生模型容量或表达能力有限,这种“平均化”策略导致它在很多低概率区域分配了概率,导致生成的回复平庸且缺乏锐度。这符合 Forward KL () 的特性(Mean-seeking)。 -
GAD 的行为: 表现出 Mode-Seeking(模式寻找) 行为。它集中概率密度在教师概率最高的那些峰值上(Reachable Modes),而忽略低概率区域。这符合 Reverse KL () 的特性。 -
在 LLM 中的意义: 对于生成任务,Mode-Seeking 更好。我们希望模型生成一个“最好”的答案,而不是涵盖所有可能的答案。GAD 让学生模型专注于生成那些它既能生成、又是教师认为高质量的回复。
6.3 动态判别器 vs. 静态奖励模型
为了验证 On-Policy 判别器的必要性,作者做了一个消融实验:
-
Off-Policy 设置: 预先训练好判别器,然后在蒸馏过程中冻结它(类似传统 RLHF)。 -
On-Policy 设置 (GAD): 判别器同步更新。
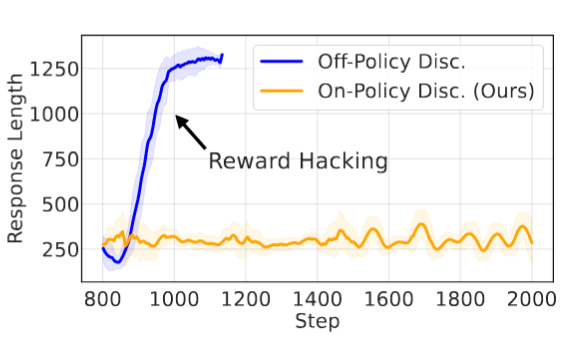
结果显示,Off-Policy 判别器在大约 300 步后就遭遇了严重的 Reward Hacking。学生模型学会了生成极长(1300+ tokens)、无意义但能骗过固定判别器的回复。
而 GAD (On-Policy) 的奖励曲线保持平稳上升,生成的长度也与教师分布保持一致。这证明了对抗训练中“判别器与生成器共同进化”对于维持监督信号有效性的关键作用。
6.4 Warmup 的重要性
消融研究表明,去掉生成器或判别器的 Warmup 都会导致性能显著下降。
-
若无生成器 Warmup:初始策略太差,判别器极其容易区分,导致梯度消失或训练不稳定。 -
若无判别器 Warmup:判别器初始也是随机的,无法提供有效指导,导致生成器在初期迷失方向。
7. 相关工作
-
白盒蒸馏: 经典如 MiniLLM (Gu et al., 2024) 强调了 Reverse KLD 的重要性,但依赖 Logits。 -
黑盒蒸馏: 除了 SeqKD,最近有工作尝试利用教师的 Reasoning Traces(思维链)进行蒸馏(如 DeepSeek-R1 相关的蒸馏工作),这与本文是正交且互补的。 -
On-Policy Distillation: 这是一个新兴趋势。早期的 On-Policy 方法主要在白盒场景下探索(如 Agarwal et al., 2024),本文将其成功拓展到了黑盒场景。
8. 总结与展望
8.1 结论
GAD 提出了一种在黑盒限制下进行 On-Policy 蒸馏的有效范式。通过引入对抗训练,利用判别器作为动态、自适应的奖励模型,GAD 成功解决了传统 SeqKD 方法中的暴露偏差和模式平均问题。
GAD 的核心优势在于:
-
不需要 Logits: 完美适配 API 型专有教师模型。 -
On-Policy 探索: 学生模型通过自身生成样本的反馈进行学习,实现了 Mode-Seeking。 -
鲁棒的泛化能力: 在域外数据上表现优异,避免了 SFT 的过拟合。 -
抗 Reward Hacking: 动态判别器提供了持续且准确的监督信号。
8.2 启示
GAD 提供了一个重要的思路:当无法获取强监督信号(如 Logits)时,可以通过构建对抗环境,利用辅助模型(判别器)来模拟环境反馈,从而将模仿学习问题转化为强化学习问题。
此外,该文章也暗示了在 Post-training 阶段,单纯的 SFT(Supervised Fine-Tuning)可能已经触及天花板。通过引入 RL 机制让模型自我探索和优化(即使是在蒸馏场景下),是提升模型性能上限的必经之路。这与近期 DeepSeek-R1 等强化学习驱动的推理模型的研究方向是不谋而合的。
附录:技术细节补充
A.1 超参数设置
-
Batch Size: 256 (对于 Policy 和 Critic 都是). -
Epochs: 3 (1 Warmup + 2 GAD). -
Learning Rate: Policy 1e-6 ~ 5e-6. -
RL 算法: GRPO,Group Size ,KL 系数 . -
Context Length: Prompt 2048, Response 1536.
A.2 硬件消耗
蒸馏 Qwen2.5-14B(从 GPT-5-Chat)大约需要在 16 张 H100 GPU 上运行 30 小时。这表明 GAD 的训练成本虽然高于简单的 SFT,但在可接受范围内,且带来的性能提升证明了其性价比。
A.3 关于 Tokenizer
由于 GPT-5 和 Qwen/Llama 的 Tokenizer 完全不同,这使得任何试图对齐 Token 级别概率分布的尝试在物理上都变得极其复杂或不可能。GAD 基于文本级别的判别,天然规避了 Tokenizer 不匹配的问题,具有极好的通用性。
往期文章:


