对于 LLM 的 post-training 过程,一个核心的挑战在于如何获取高质量的监督信号。无论是 SFT 还是从人类反馈中进行强化学习 RLHF,其效果都严重依赖于外部提供的“标准答案”或“偏好标签”。SFT 需要大量的标注数据,而 RLHF 则依赖昂贵且可能存在偏见的人类标注。在许多专业领域,例如高等数学、医疗咨询或法律文书撰写,获取这样的高质量监督信号成本高昂,甚至是不可能的。
这一困境引出了一系列关键问题:
-
数据瓶颈:当特定领域的专家知识难以获取或标注成本过高时,我们如何继续提升模型在该领域的能力? -
可验证性难题:对于那些没有唯一正确答案的非可验证任务(non-verifiable tasks),例如提供生活建议或进行创意写作,我们如何定义一个可靠的学习目标? -
自我提升的上限:模型能否在没有外部新知识输入的情况下,通过自身的“思考”和“探索”来实现能力的持续提升?
前天 Meta AI 发表了新论文《Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision》,为解决上述问题提供了一个新颖且实用的框架。他们提出的方法 Compute as Teacher (CaT) ,其核心思想是:将模型在强化时的若干 rollouts 进行“总结”,生成高质量答案,转化为一种无需外部参考的、自我生成的监督信号,从而实现优化。

-
论文标题:Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision -
论文链接:https://arxiv.org/abs/2509.14234
1. CaT 的核心思想与框架
CaT 的出发点是一个简单而深刻的问题:“推理阶段的计算能否替代缺失的监督信号?”。传统的 LLM 使用范式中,推理(inference)和训练(training)是两个独立的阶段。推理是为了获得结果,而训练是为了更新模型参数。CaT 则打破了这道壁垒,将推理过程本身变成了训练信号的来源。
其核心框架可以概括为一个三步走的流水线:探索 (Exploration) -> 合成 (Synthesis) -> 验证 (Verification) 。
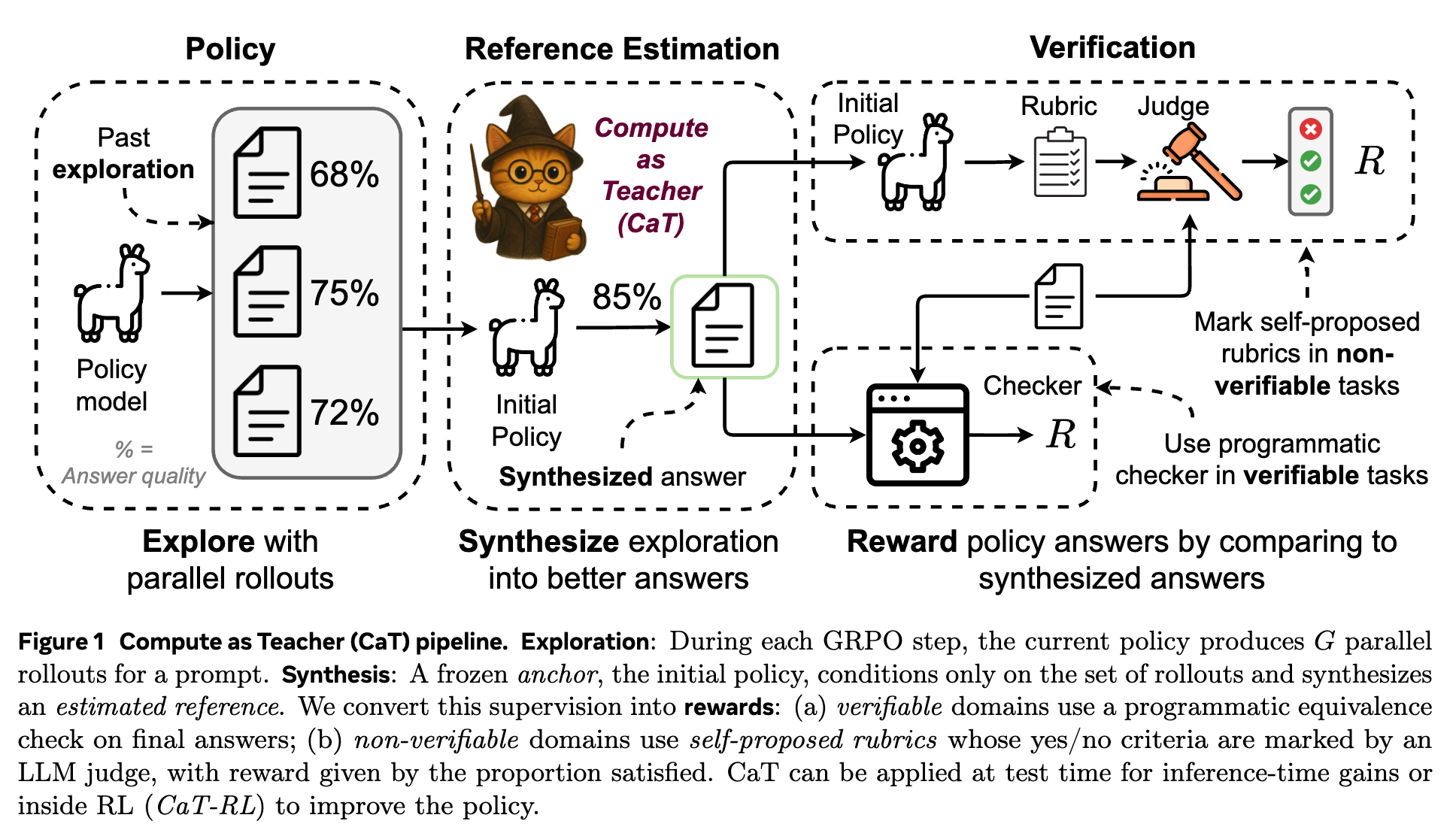
上图清晰地展示了 CaT 的工作流程,我们可以将其拆解为以下几个关键步骤:
-
探索 (Exploration) :
对于一个给定的输入提示(prompt),当前正在被训练的策略模型(policy) 会并行生成 个不同的输出,这组输出被称为“rollouts”,记为 。这一步利用了 LLM 生成过程的随机性(例如,通过 temperature sampling),从而对可能的答案空间进行多样化的探索。每个 rollout 都代表了模型对问题的一种可能的解决方案或回答。 -
合成 (Synthesis):
这是 CaT 的精髓所在。研究者引入了一个“锚点模型”(anchor),记为 。这个锚点模型通常是未经训练的初始模型(即 时的策略模型 ),并且在整个训练过程中其参数保持冻结。合成步骤的核心操作是:将前一步生成的 个 rollouts 作为输入,提供给锚点模型 ,让它生成一个全新的、综合性的回答 。这个 被称为“合成参考”(synthesized reference)。
值得注意的是,在这一步中,锚点模型 看不到原始的输入提示 。它只能基于这 个 rollouts 来进行“再创作”。这个设计的目的是迫使锚点模型去主动地整合、调和、纠正这组 rollouts 中的信息,而不是简单地对原始问题 重新生成一个答案。它需要识别出 rollouts 之间的一致性、发现并解决它们之间的矛盾、补充被忽略的细节,最终产出一个质量可能超越任何单个 rollout 的新答案。
这一过程,本质上是将额外的推理计算(生成 个 rollouts 和 1 个合成参考)转化为了一个高质量的“教师信号”(teacher signal)。
-
验证 (Verification) / 奖励生成 (Reward Generation) :
有了合成参考 这个“伪标签”后,我们就可以用它来评估第一步中生成的每个 rollout 的质量,并为之打分。这个分数将作为强化学习中的奖励信号(reward)。CaT 巧妙地为两种不同类型的任务设计了不同的奖励生成机制:
-
对于可验证任务(如数学计算),可以直接通过程序化的检查器(programmatic checker)来比较 和 的最终答案是否一致。 -
对于不可验证任务(如医疗建议),则采用一种“自提议准则”(self-proposed rubrics)的机制,由模型自己为合成参考 生成一套评估标准,再用一个独立的 LLM 裁判来根据这套标准为 打分。
-
通过这三个步骤的循环,CaT 构建了一个完全不依赖外部标注的自我学习闭环。
关键设计
CaT 框架的一个核心设计是角色分离。
-
当前策略 扮演“学生”的角色。它的任务是不断探索,生成多样的解决方案。随着训练的进行, 的参数会不断更新,其能力也随之提升。 -
初始策略 扮演“老师”的角色。它的参数被冻结,始终保持稳定。它的任务是作为一个公正、稳定的评估者,将“学生”的探索结果提炼成更高质量的教学材料(即合成参考 )。
为什么这个设计如此重要?
-
稳定性:如果“老师”也随着训练而变化,那么学习目标就会变得不稳定,可能导致训练过程难以收敛。冻结的锚点 提供了一个稳定的“真北”,确保了监督信号的一致性。 -
解耦探索与评估:让 专注于探索,而 专注于评估和合成,避免了角色混淆。如果让 自己合成参考,可能会导致它简单地强化自己已有的认知,陷入“确认偏误”,从而抑制了真正的改进。 -
防止漂移:强化学习容易受到策略漂移(policy drift)的影响。冻结的锚点 作为参照物,可以在一定程度上约束 的更新,使其不至于偏离初始能力太远,从而保证了训练的稳定性。
2. 可验证与不可验证领域
现实世界的任务多种多样,CaT 的一个重要贡献在于它为两类性质截然不同的任务——可验证任务和不可验证任务——提供了定制化的奖励生成方案。
2.1 可验证领域 (Verifiable Domains)
在数学、编程、事实问答等领域,答案的正确性通常可以通过一个确定性的程序来验证。例如,数学题的最终答案可以通过数值计算来检验。
对于这类任务,CaT 的奖励生成方式非常直接:
其中, 是一个程序化验证器(programmatic verifier),它判断 rollout 的答案是否与合成参考 的答案等价。如果等价,则返回奖励 1,否则返回 0。
在论文的实验中,针对 MATH-500 数据集,验证器 的工作方式是从 和 的文本中抽取出用 \boxed{...} 标记的最终答案,然后进行字符串匹配。
这种方法的优点是客观、高效且成本低廉。一旦合成参考 被生成,奖励的计算几乎是零成本的。
2.2 不可验证领域 (Non-Verifiable Domains)
这是 CaT 更具创新性的部分。在许多开放式、创造性或主观性强的任务中,例如撰写医疗建议、提供心理咨询或进行文学创作,不存在简单的程序化验证方法。直接让一个 LLM 裁判来给 rollouts 打一个笼统的分数(例如 1-5 分),又会面临裁判模型偏见、评分不稳定、奖励信号过于稀疏等问题(即所谓的 reward hacking)。
为了解决这个难题,CaT 引入了自提议准则奖励 (Self-proposed Rubric Rewards) 机制。这个过程分为两步:
-
生成准则 (Rubric Generation) :
锚点模型 在生成合成参考 之后,会接到一个新的任务:为这个参考答案 量身定做一套详细、具体、可被二元(是/否)判断的评估标准(rubrics)。例如,如果 是一份关于如何处理脚踝扭伤的医疗建议, 可能会生成如下的准则 :
-
: 是否建议了 RICE 原则(休息、冰敷、加压、抬高)? -
: 是否提醒用户在何种情况下(如剧烈疼痛、无法站立)应寻求专业医疗帮助? -
: 是否解释了冰敷的正确时长和频率? -
: 语气是否专业、富有同理心?
这个过程可以用公式表示为:
其中 是生成准则的提示。
-
-
裁判打分 (Judge Scoring) :
接下来,引入一个独立的、强大的 LLM 作为裁判(Judge),记为 (例如 GPT-4o)。对于每一个 rollout ,裁判 会逐一根据准则 中的每一条 进行判断,给出一个“是”或“否”的结论。最终,rollout 的奖励分数是其满足的准则所占的比例:
其中 是指示函数。
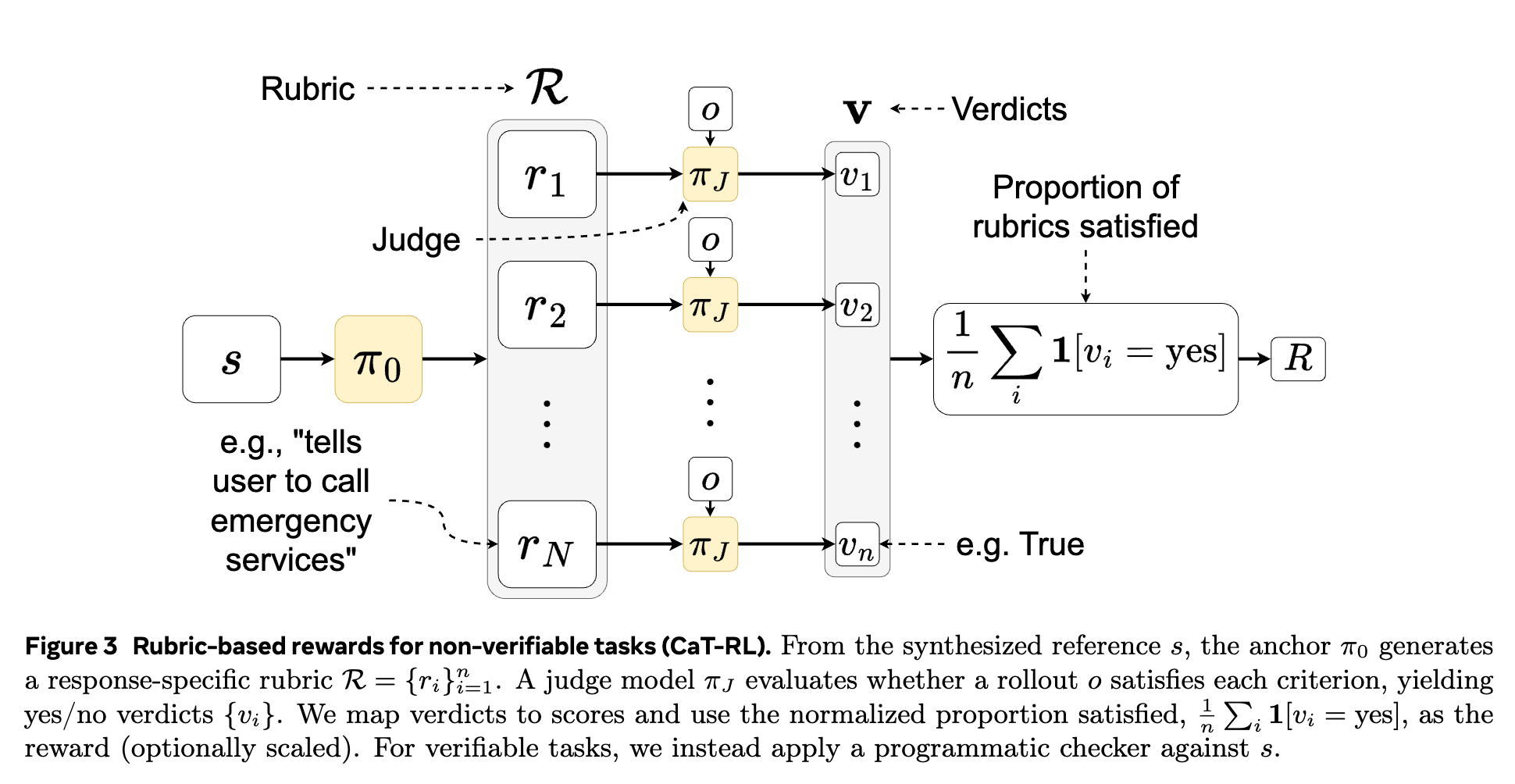
这种方法的巧妙之处在于:
-
分解复杂性:它将一个模糊、笼统的“好坏”判断,分解成了一系列清晰、具体、可审计的子任务。这大大降低了裁判模型打分的难度和不确定性。 -
减少偏见:相比于直接对输出内容打分,判断是否满足某个具体标准(如“是否包含 RICE 原则”)更不容易受到输出的长度、文采等表面形式的影响(即 verbosity and formatting bias)。 -
提供细粒度反馈:奖励不再是一个稀疏的 0/1 信号,而是一个介于 0 和 1 之间的连续值,这为强化学习提供了更丰富、更有指导性的学习信号。
通过这套机制,CaT 成功地将监督信号的生成扩展到了 ранее难以处理的非可验证领域,并且整个过程同样无需任何人工标注。
3. CaT-RL
生成了奖励信号后,下一步就是利用这些信号来更新策略模型 的参数。CaT 采用强化学习,具体而言是组相对策略优化 (Group Relative Policy Optimization, GRPO) 算法来完成这一步。GRPO 是近端策略优化 (Proximal Policy Optimization, PPO) 的一个内存高效变体。
3.1 GRPO 算法简介
PPO 是 LLM 强化学习中的主流算法,它通过一个“裁剪”的目标函数来确保每次策略更新的步子不会太大,从而保证训练的稳定性。标准的 PPO 通常需要训练一个独立的价值网络(value network)来估计在某个状态下可能获得的未来奖励总和,并以此计算优势函数(advantage function)。
GRPO 的一个改进在于它无需价值网络。在一个批次中,对于同一个 prompt 生成的 个 rollouts,GRPO 直接使用这组 rollouts 的平均奖励作为基线(baseline)。某个 rollout 的优势(advantage)就是它的实际奖励与这个组平均奖励的差值。
-
组平均奖励: -
组奖励标准差: -
第 个 rollout 在第 个 token 处的优势:
这种设计的优势是:
-
内存高效:省去了价值网络,大大减少了训练所需的显存。 -
简单有效:对于许多 LLM 任务,这种简单的基线已经足够有效,可以显著简化 RL 的流程。
GRPO 的优化目标函数与 PPO 类似,是一个裁剪后的代理目标:
其中, 是新旧策略的比率, 是裁剪系数。
3.2 CaT-RL 完整算法流程
结合前面的步骤,我们可以总结出 CaT-RL 在处理一个问题时的完整流程(对应论文中的 Algorithm 1):

-
输入:锚点模型 (冻结),当前策略模型 ,各类提示(合成、准则生成、裁判),以及一个问题 。 -
探索:使用当前策略 对问题 采样,生成 个 rollouts: 。 -
合成:调用锚点模型 ,以 为条件,生成合成参考 。 -
计算奖励 (对每个 rollout ): -
If 问题 是可验证的: -
(程序化验证)
-
-
Else (问题 是不可验证的): -
生成准则: -
裁判打分:
-
-
-
更新策略:使用计算出的所有奖励 ,通过 GRPO 算法更新策略模型 的参数。
这个循环不断重复,策略模型 的能力也随之逐步提升。一个有趣且重要的现象是,CaT-RL 可能会形成一个“良性循环” (virtuous cycle) :
变强 生成的 rollouts 质量更高、多样性更合理 能合成出更好的参考 提供了更强的教师信号 得到更好的训练,变得更强。
4. 实验
为了验证 CaT 的有效性,研究者在两个具有代表性的数据集上,对三种不同规模的模型家族(Gemma 3 4B, Qwen 3 4B, Llama 3.1 8B)进行了全面的评估。
-
数据集: -
MATH-500(可验证领域): 一个包含 500 道数学问题的基准测试,用于衡量模型的数学推理能力。 -
HealthBench(不可验证领域): 一个包含 5000 个自由形式的医患对话数据集,旨在评估模型提供医疗建议的质量。
-
-
评估模式: -
CaT (Inference-time): 不进行 RL 训练,仅在推理时使用 CaT 的合成步骤来提升单次回答的质量。此时,策略模型和锚点模型是同一个,即 。 -
CaT-RL (Training): 运行完整的 RL 训练流程,得到一个经过优化的新模型。
-
核心结果 (RQ1): CaT-RL 是否优于初始策略和推理时 CaT?
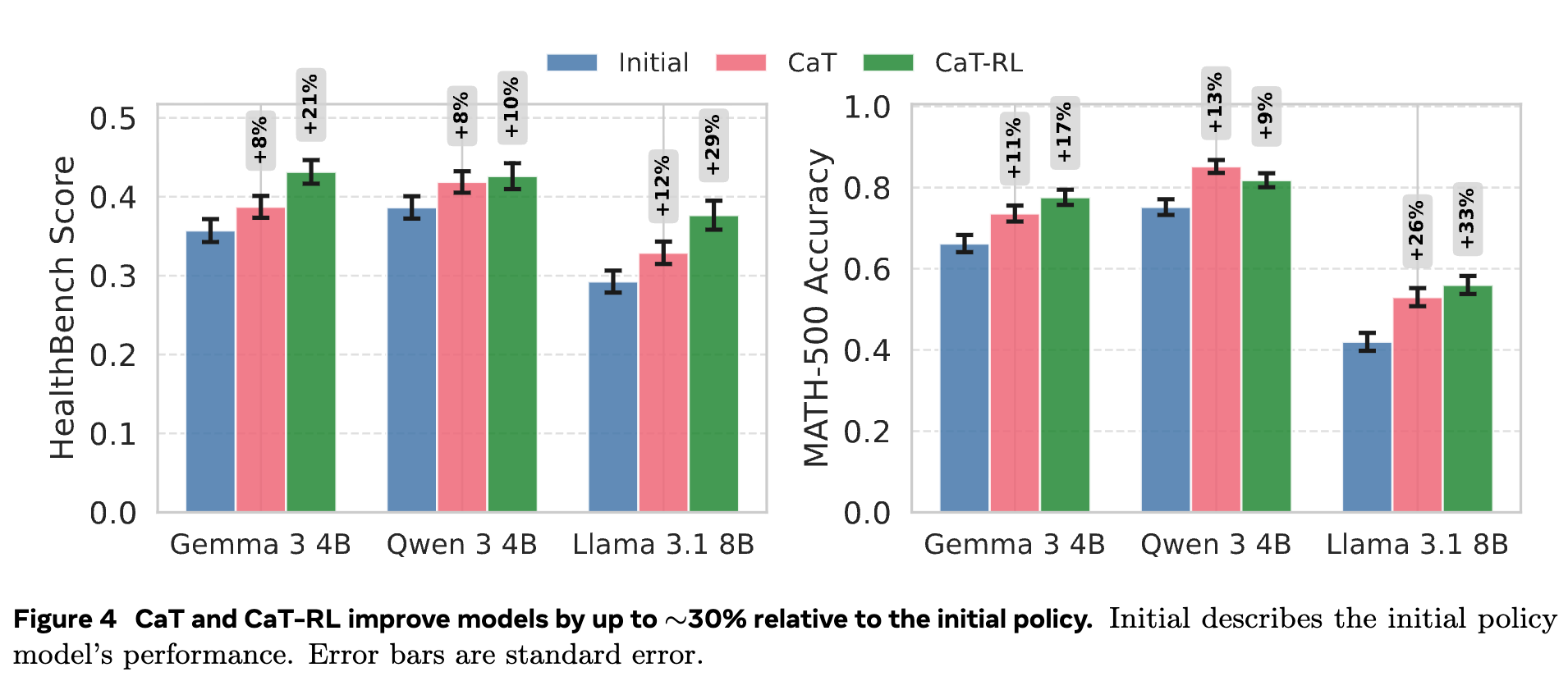
图 4 展示了核心的实验结果。可以清晰地看到:
-
普遍有效性: 无论是 CaT 还是 CaT-RL,在所有三个模型和两个数据集上,都比初始模型(Initial)取得了性能提升。这证明了 CaT 框架的普适性。 -
训练带来显著增益: CaT-RL 的性能始终高于仅在推理时使用的 CaT。这表明通过 RL 进行持续的策略优化,能够将 CaT 产生的教师信号内化为模型自身的能力,而不仅仅是作为一种一次性的推理技巧。 -
提升幅度可观: 在 Llama 3.1 8B 模型上,CaT-RL 相较于初始策略,在 MATH-500上实现了高达 33% 的相对提升,在HealthBench上也实现了 30% 的相对提升。 -
超越教师信号: 一个有趣的发现是,在大多数情况下(除了 Qwen 3 4B on math),CaT-RL 训练出的最终模型的性能,甚至超过了由初始模型 生成的教师信号(即 CaT at inference)的水平。这印证了前述的“良性循环”理论:学生最终超越了最初的老师。
5. CaT 为何有效?
除了展示优异的性能,论文还进行了一系列深入的分析性实验,以揭示 CaT 成功的内在机制。
5.1 合成 vs. 选择
一个很自然的问题是:CaT 的优势仅仅来自于从多个答案中选了一个最好的吗?还是它真的“创造”了新的、更好的答案?为了回答这个问题,研究者将 CaT 与多种基于“选择”的基线方法进行了比较(如图 6 所示):
-
Single: 单次采样,作为基准。 -
min(PPL): 从多个 rollouts 中选择困惑度(perplexity)最低的那个。 -
Self-BoN: (Self-selected Best-of-N) 模型自己判断哪个 rollout 最好。 -
Majority: (Majority Vote) 仅用于数学任务,选择多个 rollouts 中出现频率最高的答案。
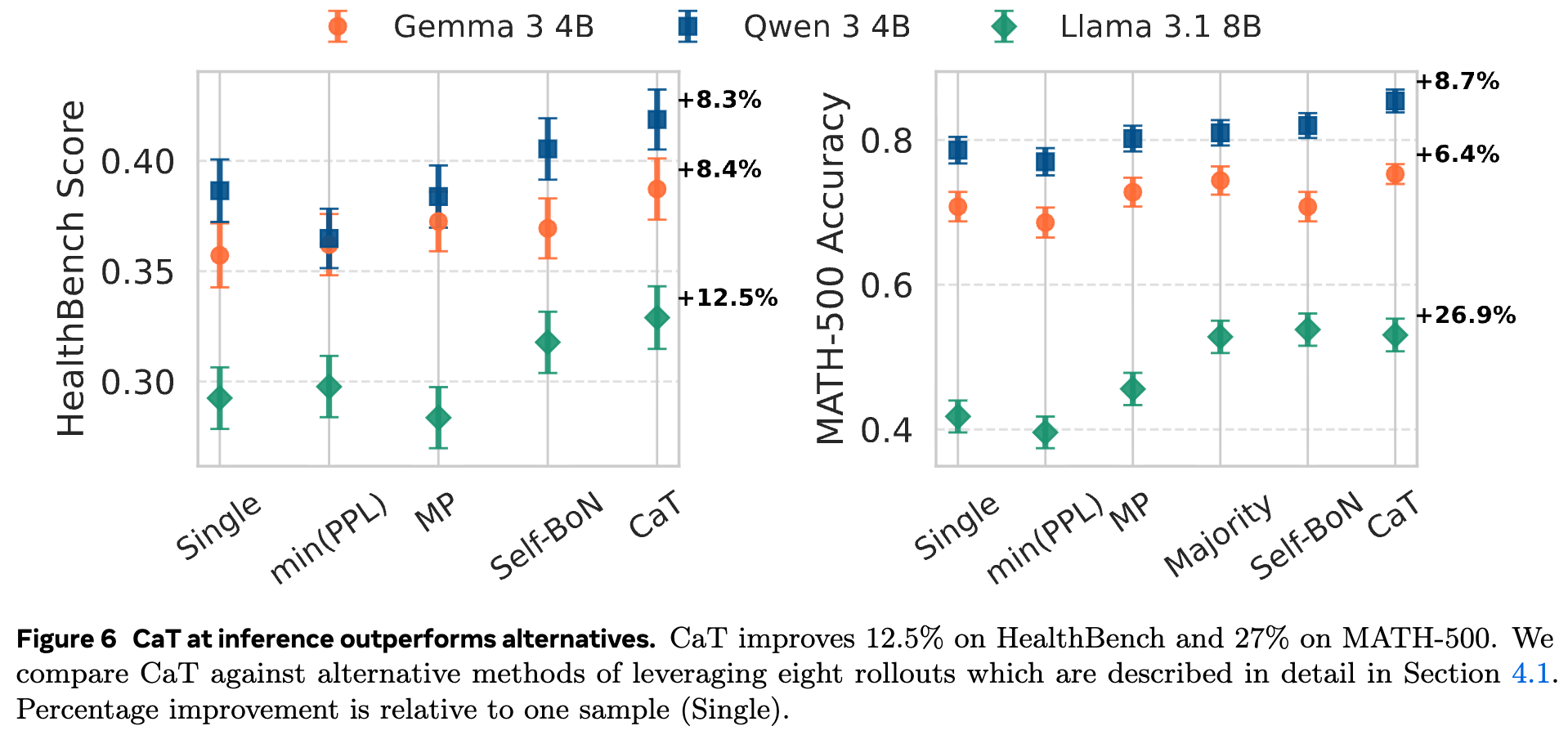
实验结果表明,CaT 的性能显著优于所有基于选择的基线方法。这说明 CaT 的核心优势在于合成,而非选择。
更具说服力的证据是:
-
在 MATH-500数据集上,CaT 合成的答案有 14% 的情况与多数投票(Majority Vote)的结果不一致。这表明 CaT 并非简单地“随大流”,而是有自己独立的判断和整合能力。 -
最引人注目的是,研究者发现有约 1% 的情况,CaT 能够生成正确的答案,即使所有提供给它的 rollouts 都是错误的!

上面这个例子,在一个复数计算问题中,所有的 rollouts 都因为各种计算错误而失败了。然而,CaT 在分析了这些错误的尝试后,识别出了正确的解题思路,并规避了计算陷阱,最终给出了正确的答案。这强有力地证明了 CaT 的合成过程是一种深度的推理和纠错,而不是简单的拼接或选择。
5.2 Self-proposed rubrics 的有效性
在不可验证领域,自提议准则()是 CaT 的一大创新。它真的比传统的 LLM-as-Judge 更好吗?甚至能媲美人类专家设计的准则吗?
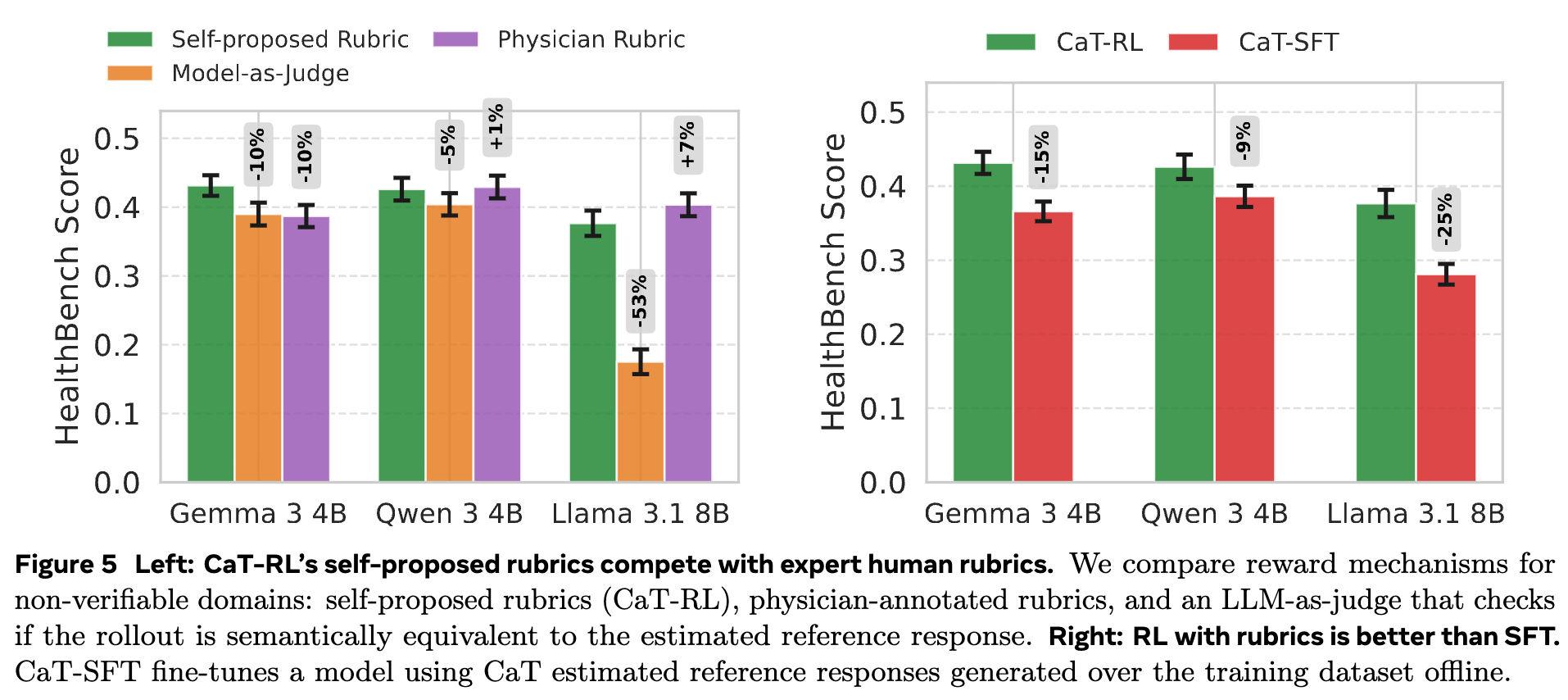
图 5 左侧的实验给出了答案:
-
优于直接判断: 基于自提议准则的 CaT-RL 性能,一致性地优于直接让 LLM 裁判判断语义等价性的 Model-as-Judge方法。这验证了将复杂判断分解为简单准则的有效性。 -
媲美人类专家: CaT-RL 的性能与使用 HealthBench数据集中由人类医生设计的专家准则(Physician Rubric)作为奖励信号的性能相当,在 Gemma 3 4B 上甚至有所超越。这是一个重要的结论,意味着我们可以在没有领域专家的情况下,自动地为复杂任务生成高质量的评估体系,极大地提升了方法的可扩展性。
5.3 RL vs. SFT
既然 CaT 能生成高质量的合成参考 ,我们为什么不直接用这些 作为标签,对模型进行监督微调(SFT)呢?这种方法被称为 CaT-SFT。
图 5 右侧的实验显示,CaT-RL 的性能 consistently 优于 CaT-SFT。这可能是因为:
-
奖励信号的粒度: SFT 的学习信号是基于整个序列的交叉熵损失,是一种“要么全对,要么全错”的信号。而 RL,特别是基于准则的 RL,提供的是一个更细粒度的、按“点”给分的奖励,能够更精确地指导模型的改进方向。 -
探索的价值: RL 鼓励模型进行探索,而 SFT 只是在模仿给定的参考答案。通过探索,模型可能会发现参考答案之外的同样有效甚至更好的解决方案。
5.4 性能与 Rollout 数量
CaT 的核心是将计算量转化为监督信号,那么是否计算量越大(即 rollouts 数量 越多),效果就越好呢?
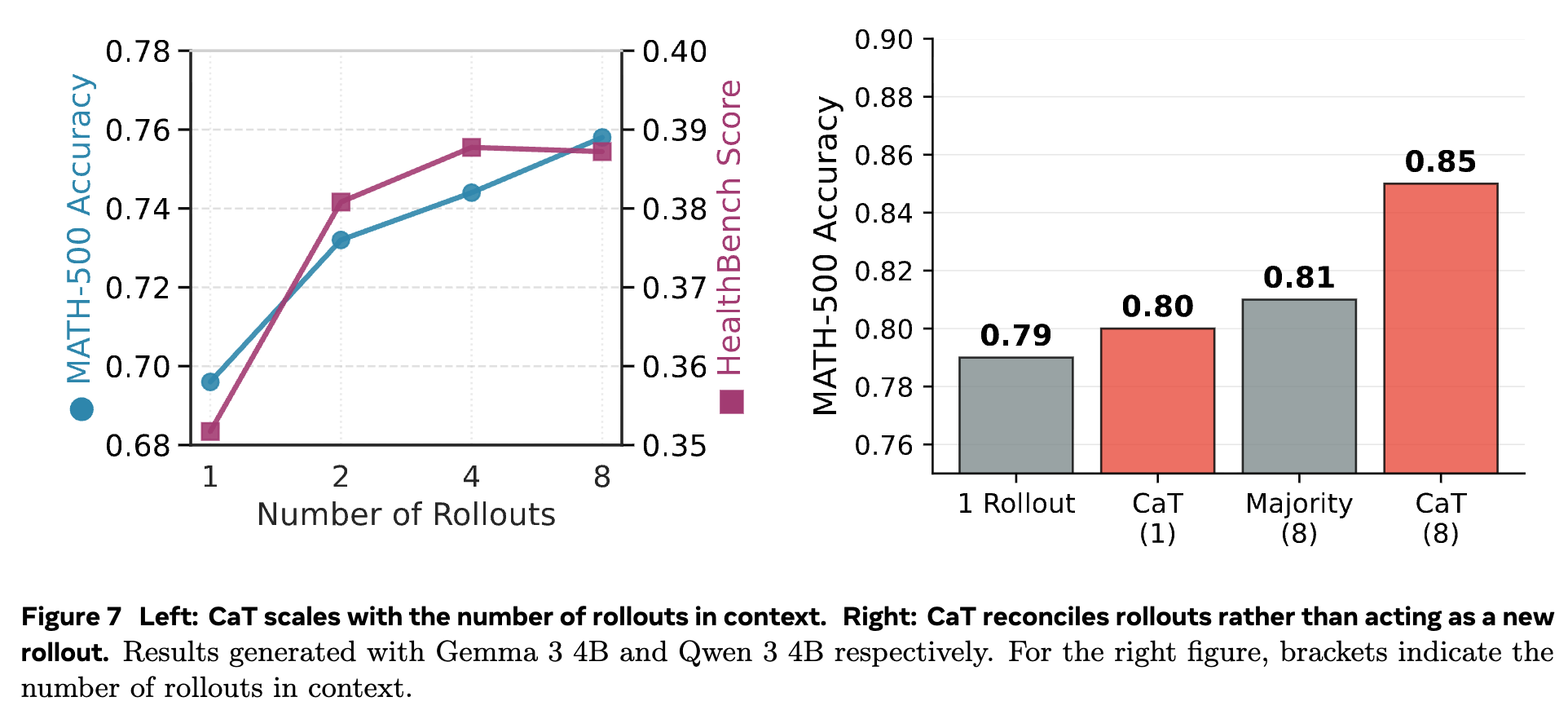
图 7 左侧的图表显示:
-
在 MATH-500上,性能随着 的增加单调提升。这表明对于结构化推理任务,更多的样本能提供更丰富的解题路径和错误示例,帮助合成过程更好地去伪存真。 -
在 HealthBench上,性能在 之后趋于饱和。这可能是因为在自由形式的生成任务中,rollouts 之间的有效信息差异(useful diversity)在 较大时会达到收益递减的瓶颈。
这个结果为实践提供了一个指导:我们可以根据任务的性质来权衡计算成本和性能收益,选择一个合适的 值。
点评
该方法强依赖于 ,如果 非常弱,它生成的 rollouts 可能缺乏有价值的多样性,也无法有效地从一堆低质量的 rollouts 中合成出高质量的参考。
随着 的能力趋于收敛,其生成的多样性会自然下降,导致 rollouts 之间越来越相似。此时,合成步骤能带来的提升空间也随之减小,教师信号变弱,CaT-RL 的学习过程会逐渐停滞。
往期文章:


