尽管 GRPO 效果显著,学术界和工业界对其内在机制和潜在局限性的探索从未停止。一些研究尝试复现或改进 GRPO,但往往依赖于启发式或临时的技巧,缺乏对问题根源的深入剖析。来自 Texas A&M University 发表于 NeurIPS 2025 的高分论文《DisCO: Reinforcing Large Reasoning Models with Discriminative Constrained Optimization》,对 GRPO 的目标函数进行了系统性分析,揭示了其固有的“难度偏差”(difficulty bias)问题,并由此提出了一个基于判别式学习原则的强化学习框架——判别式约束优化(Discriminative Constrained Optimization, DisCO)。

-
论文标题:DisCO: Reinforcing Large Reasoning Models with Discriminative Constrained Optimization -
论文链接:https://arxiv.org/pdf/2505.12366
1. GRPO 中的难度偏差
要理解 DisCO 的动机,我们必须首先理解 GRPO 的工作原理及其内在缺陷。GRPO 的核心思想是,对于一个给定的问题(prompt),模型会生成多个候选答案。然后,一个基于规则的奖励机制(例如,检查最终答案是否正确)会为每个答案分配一个奖励值。GRPO 利用这些奖励来更新模型策略,使其倾向于生成高奖励的答案。
其目标函数(在期望形式下)可以表示为:
其中:
-
是当前需要优化的策略模型。 -
是用于生成答案的旧策略模型。 -
是一个固定的参考模型,用于 KL 散度正则化。 -
是“组相对优势函数”,它衡量一个答案 的奖励相对于同一问题 下其他答案平均奖励的优势。 -
是一个包含裁剪(clipping)操作的函数,类似于 PPO(Proximal Policy Optimization)。
这篇论文的第一个关键贡献在于,它在二元奖励(binary reward,即答案要么正确得 1 分,要么错误得 0 分)的设定下,对 GRPO 的目标函数进行了数学上的重构。通过一系列推导(详见论文附录 B.1),作者在命题 1 (Proposition 1) 中指出,GRPO 的目标函数可以等价地表示为一个判别式目标:
这个公式揭示了 GRPO 的本质。让我们来解析一下:
-
代表了在旧模型 下,问题 得到正确答案的概率。这可以看作是问题 的“难度”度量: 越接近 1,问题越简单; 越接近 0,问题越困难。 -
和 分别代表生成正确答案和错误答案的条件分布。 -
和 是与模型 相关的评分函数(scoring functions),分别用于评估正确答案 和错误答案 。 -
优化的核心在于最大化正确答案的得分,同时最小化错误答案的得分,这是一个经典的判别式学习目标,与 AUC (Area Under the Curve) 最大化在概念上紧密相连。
然而,这个等价形式暴露了一个此前未被清晰阐明的问题。注意到判别式目标前的权重项 。这个权重项完全由问题的难度 决定。
如图 1 (a) 所示,当问题非常简单()或非常困难()时,权重 都趋近于 0。权重仅在问题难度适中()时达到最大值。
这就是作者所定义的“难度偏差”(difficulty bias)。其直接后果是,GRPO 在训练过程中,会不成比例地关注那些难度中等的“模棱两可”的问题,而对那些模型已经基本掌握(但仍有小概率犯错)的简单问题,以及那些模型几乎无法解决的困难问题,赋予了非常小的学习权重。
这种机制在直觉上是不合理的。对于一个困难问题(例如 ),即使模型在 10 次尝试中只成功了 1 次,我们也应该抓住这次宝贵的成功经验来强化模型,而不是因为其权重小而忽视它。同样,对于一个简单问题(例如 ),我们应该致力于消除那 10% 的错误,追求完美,而不是因为权重小就满足于现状。
论文通过实验验证了这一偏差的负面影响。
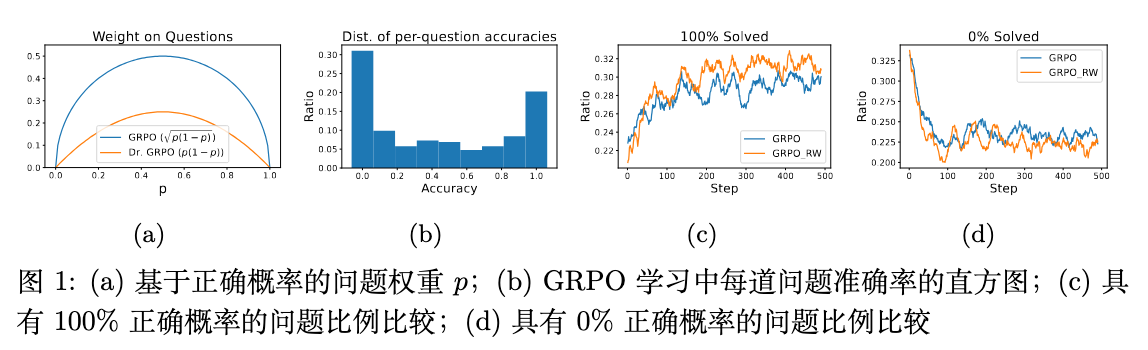
实验显示,在 GRPO 训练过程中,问题的正确率分布广泛,存在大量接近 0 或 1 的情况(图 b)。作者设计了一个移除了权重项 的 GRPO 变体(GRPO_RW)进行对比。结果发现,GRPO_RW 能够更快地提升 100% 正确率问题的比例(图 c),并降低 0% 正确率问题的比例(图 d),这证实了 权重确实对学习效率造成了损害。
作者还指出,最近提出的 Dr. GRPO 算法虽然试图通过使用未归一化的优势函数来缓解偏差,但经过类似的分析,其目标函数前依然存在一个 的权重项,该权重项虽然形式不同,但同样存在两端低、中间高的问题,因此并未从根本上消除难度偏差。
2. DisCO
在深刻理解了 GRPO 的局限性后,作者没有选择在原有框架上进行修补,而是彻底地重新设计了目标函数,提出了 DisCO 框架。DisCO 的设计基于以下几个核心原则:
-
消除难度偏差:用一个纯粹的判别式目标取代 GRPO 的组相对目标。 -
提升训练稳定性:用非裁剪的评分函数和约束优化取代裁剪代理和 KL 正则化。 -
处理数据不平衡:引入先进的判别式学习技术来解决 RL rollouts 中正负样本严重不平衡的问题。
下面我们来逐一解析 DisCO 框架的四大关键部分。
2.1 基础判别式目标 (A Basic Approach)
DisCO 的出发点是直接优化一个旨在区分正负样本的判别式目标。对于每个问题 ,其目标是最大化模型对正确答案 的评分,同时最小化对错误答案 的评分。这可以形式化为以下目标函数,我们称之为 DisCO-b (DisCO-basic):
其中:
-
是一个统一的评分函数,用于评估模型 对输出 的“偏好”程度。 -
是一个单调递增的代理函数(surrogate function)。在最简单的情况下,,此时目标就是直接最大化正负样本的平均分差。
这个目标函数直接移除了与问题难度 相关的权重项,从根本上解决了“难度偏差”问题。
2.2 非裁剪评分函数 (Non-Clipping Scoring Functions)
GRPO 及其变种(如 DAPO)中的评分函数隐式地来源于其裁剪操作,这种裁剪虽然借鉴自 PPO,但近期研究(如 DAPO 论文)指出,它可能导致熵崩塌(entropy collapse),即模型策略过早地变得确定化,丧失探索能力。此外,裁剪还可能导致梯度消失,减缓学习进程。
为了避免这些问题,DisCO 采用了两种经典的、非裁剪的评分函数:
-
对数似然 (Log-Likelihood, log-L) :
这等价于整个序列的对数概率,是生成模型中最自然的评分方式之一。作者在论文附录 B.2 中指出,该评分函数与经典强化学习算法 Vanilla Policy Gradient (VPG) 的代理目标有直接关联。
-
似然比 (Likelihood-Ratio, L-ratio) :
这个评分函数衡量了新策略相对于旧策略在生成序列上的概率比。它与 TRPO (Trust Region Policy Optimization) 算法的代理目标紧密相关。
通过使用这些非裁剪的函数,DisCO 旨在获得更稳定和高效的训练动态。
2.3 通过约束优化稳定训练 (Stabilize with Constrained Optimization)
训练不稳定性是强化学习中的一个长期挑战。为了约束策略更新的步长,防止灾难性遗忘,现有方法通常采用两种策略:PPO 式的裁剪或 KL 散度正则化。DisCO 已经摒弃了裁剪,而对于 KL 正则化(即在目标函数中减去一项 ),作者认为它也非最优。正则化项无论何时都会产生一个梯度,即使策略更新已经很小(在“信任区域”内),它依然会“惩罚”模型,这可能阻碍学习。
DisCO 借鉴了 TRPO 的思想,重新启用信任区域约束 (trust region constraint) 。具体来说,它将策略更新问题形式化为一个约束优化问题:
这个公式的含义是:在最大化判别式目标 的同时,必须保证新旧策略之间的 KL 散度不超过一个预设的阈值 。
直接求解这个约束优化问题计算成本很高。因此,作者采用了一种高效的替代方法:使用平方铰链惩罚函数 (squared-hinge penalty function) 将其转化为一个无约束优化问题:
其中 。这种惩罚函数有一个特性:
-
当约束被满足时(),,惩罚项完全不起作用,梯度完全由主目标 驱动。 -
只有当约束被违反时(),惩罚项才会被激活,产生一个将策略拉回信任区域的梯度。
2.4 用分布鲁棒优化处理不平衡 Rollouts (Tackling Imbalanced Rollouts with DRO)
判别式学习框架的一个优势在于它可以借鉴该领域成熟的技术来解决特定问题。在 LRM 的 RL 微调中,一个关键挑战是稀疏奖励(sparse rewards)导致的不平衡 rollouts。对于许多难题,模型生成的绝大多数答案都是错误的,只有极少数是正确的。这意味着负样本的数量远超正样本。
在这种严重的数据不平衡下,基础的 AUC 式目标 可能表现不佳。例如,假设有 1 个正样本和 100 个负样本。只要模型给这个正样本的评分高于 99 个负样本,AUC 就能达到 0.99,看起来很高。但如果模型给那个得分最高的负样本的评分依然高于正样本,那么在实际应用中,模型仍然会犯错。
为了解决这个问题,DisCO 引入了分布鲁棒优化 (Distributionally Robust Optimization, DRO) 的思想,来优化一个更具鲁棒性的部分 AUC (partial AUC) 指标。其核心思想是,对于一个正样本,我们不关心它与所有负样本的排序,而是更关心它与那些“最顽固”(即得分最高)的负样本的排序。
最终,这导出了 DisCO 的完整目标函数:
这个目标函数,也称为优化确定性等价 (Optimized Certainty Equivalents, OCE),可以看作是 的一个下界。最大化 会自动提升 ,但反之不成立。因此,优化 是一个更强的目标,能够更有效地处理不平衡数据,迫使模型关注那些困难的负样本。
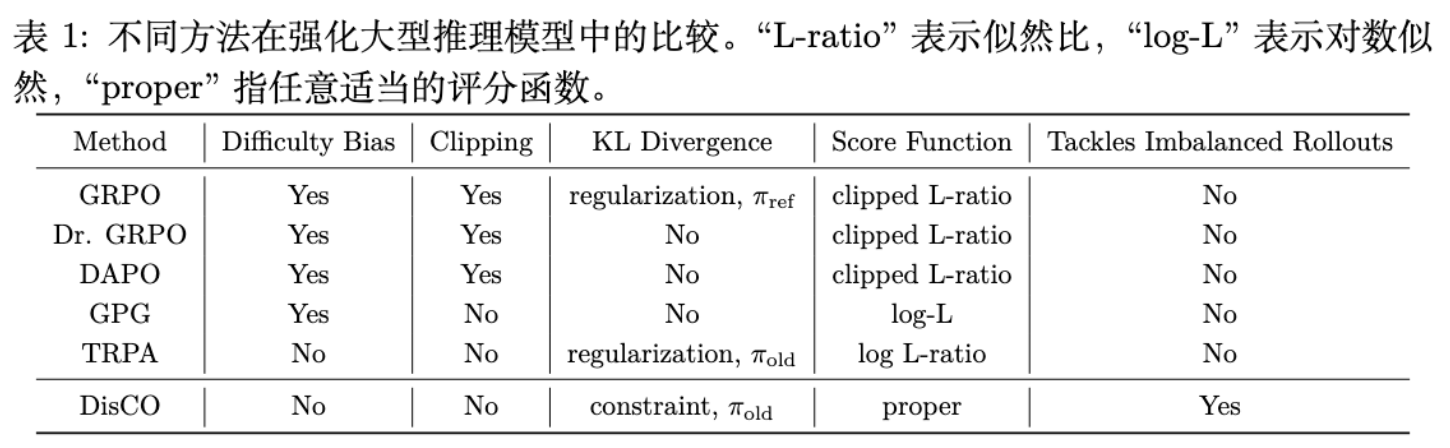
上表总结了 DisCO 与 GRPO、Dr. GRPO、DAPO 等方法的关键区别。DisCO 是唯一一个同时解决了难度偏差、裁剪问题,并能处理不平衡 rollouts 的方法。
3. 实验
作者在三个不同尺寸的开源模型(DeepSeek-R1-Distill-Qwen-1.5B/7B, DeepSeek-R1-Distill-Llama-8B)上,对 DisCO 和一系列最新的基线方法进行了全面的比较。
实验设置:
-
训练数据:DeepScaleR-Preview-Dataset,一个包含约 4 万个数学问题-答案对的数据集。 -
评估基准:涵盖六个主流的数学推理基准测试,包括 AIME 2024/2025, MATH 500, AMC 2023, Minerva, 和 Olympiad Bench。 -
基线方法:GRPO, GRPO-ER (带熵正则化), Dr. GRPO, DAPO, TRPA (一种基于 DPO 的方法)。
3.1 性能对比
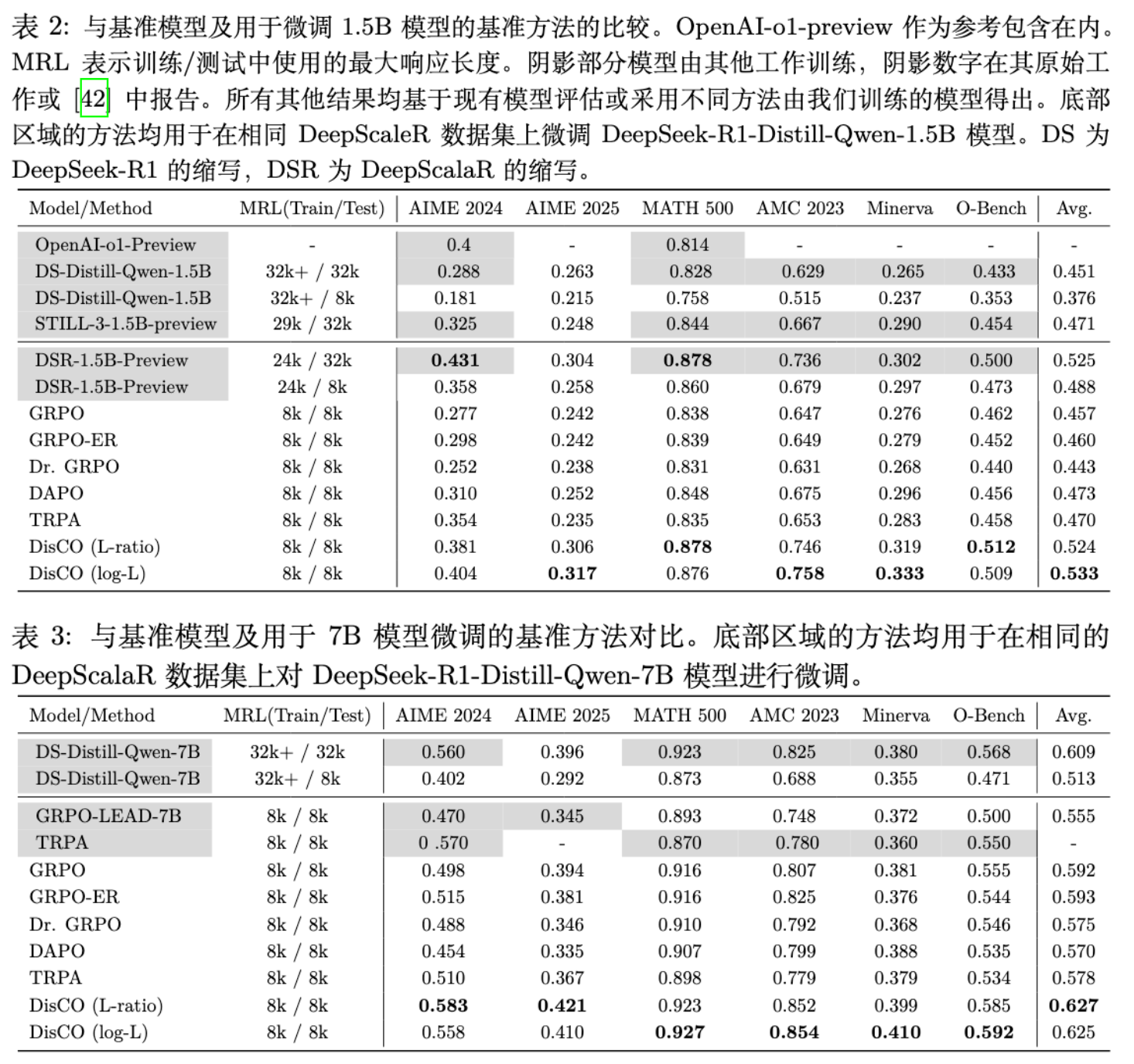

实验结果非常清晰且一致:
-
全面超越:在所有三个模型尺寸和六个评估基准上,DisCO 的两个版本(L-ratio 和 log-L)均显著优于所有基线方法。 -
效率优势:以 1.5B 模型为例,DisCO (log-L) 使用 8k 的训练和推理长度,其平均分(0.533)不仅远超同样使用 8k 长度的 GRPO(0.457,提升了约 7%),甚至超过了使用 24k 训练长度和 32k 推理长度的 DeepScaleR-1.5B-Preview 模型(0.525)。这表明 DisCO 框架能够更有效地利用数据和上下文。 -
稳定性:这种性能优势随着模型规模的增长而持续存在,在 7B 和 8B 模型上也观察到了类似的趋势,证明了 DisCO 框架的普适性。
3.2 训练动态分析
除了最终的性能指标,训练过程的动态更能揭示不同算法的内在行为。
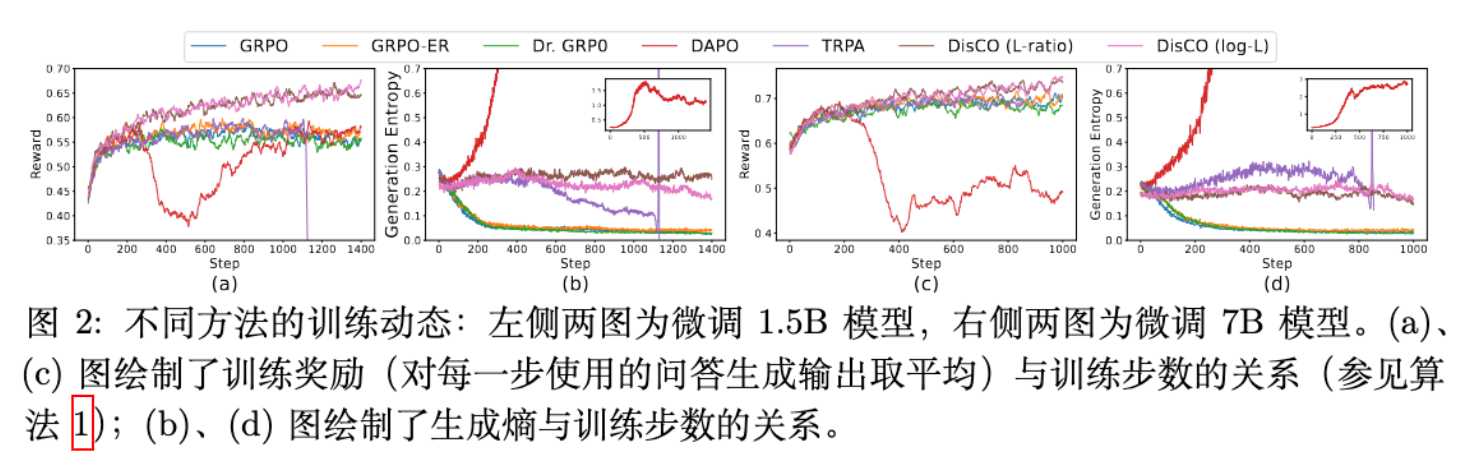
上图展示了 1.5B 和 7B 模型在训练过程中的奖励和生成熵的变化:
-
基线方法的困境:GRPO、GRPO-ER 和 Dr. GRPO 的生成熵在训练早期就迅速下降,即发生了熵崩塌。这表明它们的策略过早地收敛到一个次优的确定性状态,失去了进一步探索和提升的空间,导致训练奖励过早饱和。 -
DAPO 的问题:DAPO 虽然通过一些技巧缓解了熵崩塌,但却走向了另一个极端——熵的过度增长。这导致其策略过于随机,同样无法有效学习,奖励也很快停滞。 -
TRPA 的不稳定性:TRPA 使用了 KL 正则化,其熵在训练后期表现出不稳定性,这印证了作者关于 KL 正则化不足以稳定训练的判断。 -
DisCO 的稳定表现:与之形成鲜明对比的是,DisCO 的两个版本在整个训练过程中都保持了非常稳定的生成熵(维持在 0.22 左右),同时训练奖励持续稳步上升。这表明 DisCO 的约束优化机制成功地维持了策略的探索性,实现了健康、持久的学习过程。
4. 消融研究
为了进一步验证 DisCO 各个设计组件的必要性,作者进行了一系列详尽的消融实验。
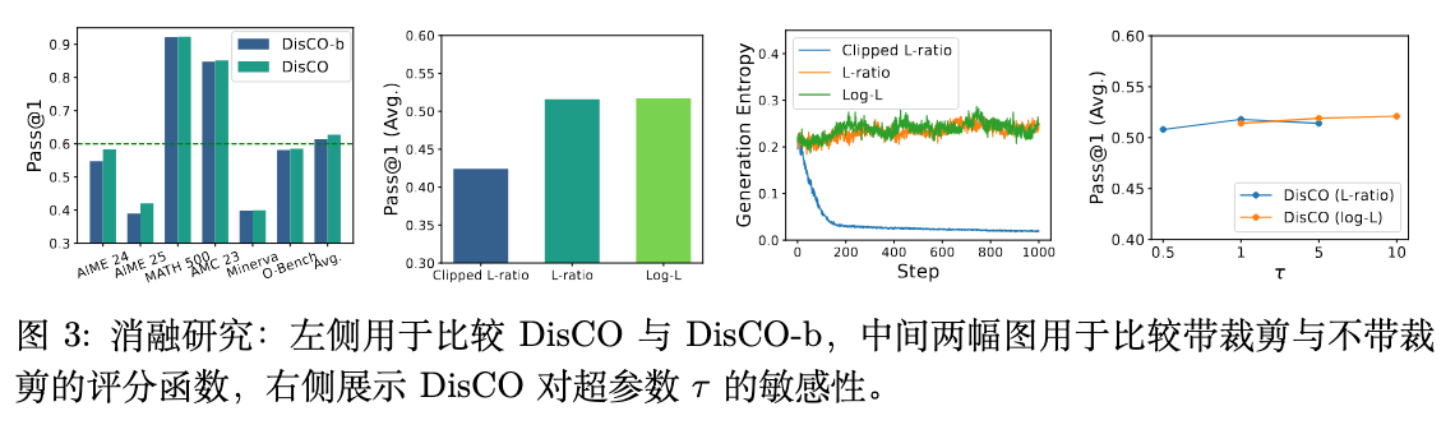
-
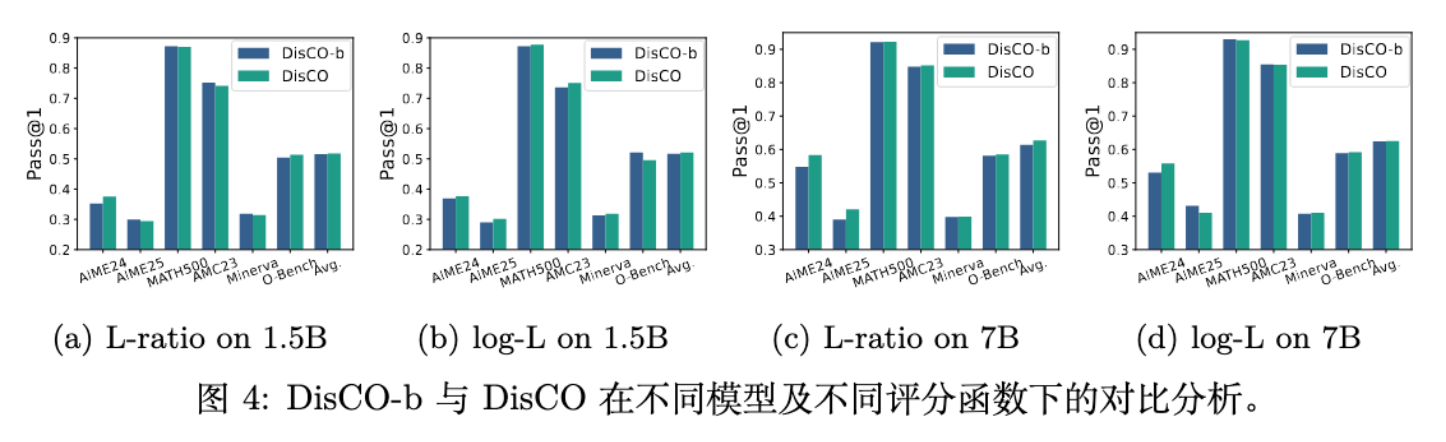
DisCO vs. DisCO-b:[图 3 (左)] 比较了完整的 DisCO (基于 DRO) 和基础版 DisCO-b。结果显示,在所有基准上,尤其是在更困难的 AIME 数据集上,DisCO 均优于 DisCO-b。这证明了通过 DRO 处理不平衡 rollouts 的设计是有效且重要的。
-
裁剪 vs. 非裁剪评分函数:[图 3 (中、右)] 在 DisCO-b 框架下比较了非裁剪的 L-ratio/log-L 和裁剪的 L-ratio(与 GRPO/DAPO 类似)。结果显示,非裁剪函数性能更优。裁剪的 L-ratio()导致了熵崩塌,而放宽裁剪的版本()则导致了过高的熵,两者性能都不及非裁剪版本。这证实了作者关于裁剪操作负面影响的假设。
-
KL 正则化 vs. 约束优化:[图 4 (左)] 比较了 DisCO 的约束优化和传统的 KL 正则化。结果表明,约束优化在两个模型上都取得了更好的性能,并且在 7B 模型上,KL 正则化会导致训练不稳定,而约束优化则表现稳健。
-
各设计选择的贡献:[图 4 (右)] 进行了一项终极消融实验,从 DisCO-b 出发,逐一替换掉 DisCO 的核心组件。结果显示,(1)移除难度偏差、(2)使用非裁剪评分函数、(3)将 KL 正则化换为约束优化,这三者都对最终性能有正向贡献。其中,使用非裁剪的评分函数是提升最为关键的一步。
5. 总结
判别式目标:DisCO 彻底抛弃了 GRPO 的加权机制,直接优化一个旨在最大化正确答案评分、最小化错误答案评分的判别式目标。这从根本上消除了“难度偏差”,让模型平等地从所有问题中学习。
非裁剪评分函数与约束优化:GRPO 及其变种(如DAPO)依赖于 PPO 式的裁剪操作,但这易导致“熵崩塌”(模型过早丧失探索性)和训练不稳定。DisCO 采用更经典的对数似然(log-L)和似然比(L-ratio)作为评分函数,并借鉴 TRPO 的思想,用 KL 散度约束 取代了 KL 正则化。这种“按需惩罚”的约束机制,在保证策略更新不过于激进的同时,提供了比固定正则化更稳定、更健康的训练动态。
应对数据不平衡:通过引入分布鲁棒优化 (DRO),DisCO 能够有效处理强化学习中因稀疏奖励导致的“正负样本严重不平衡”问题,迫使模型关注那些最难分辨的错误答案,从而提升模型的鲁棒性。
往期文章:


