26
2025/08

上交 & 腾讯提出 PSFT:借鉴PPO,为SFT引入近端约束,告别泛化能力差与“熵坍塌”
大模型的优化手段之一SFT (Supervised Fine-Tuning) 简单有效,但它也带来了两个严重的问题:泛化能力差和“熵坍塌”问题。为了解决这两个
...

字节Seed&南大提出DuPO:基于广义对偶的自监督大模型优化算法
传统的优化范式,如依赖人类反馈的强化学习(RLHF)和依赖可验证奖励的强化学习(RLVR),尽管在特定任务上取得了显著成效,但它们普遍面临着标注成本高昂、适用
...
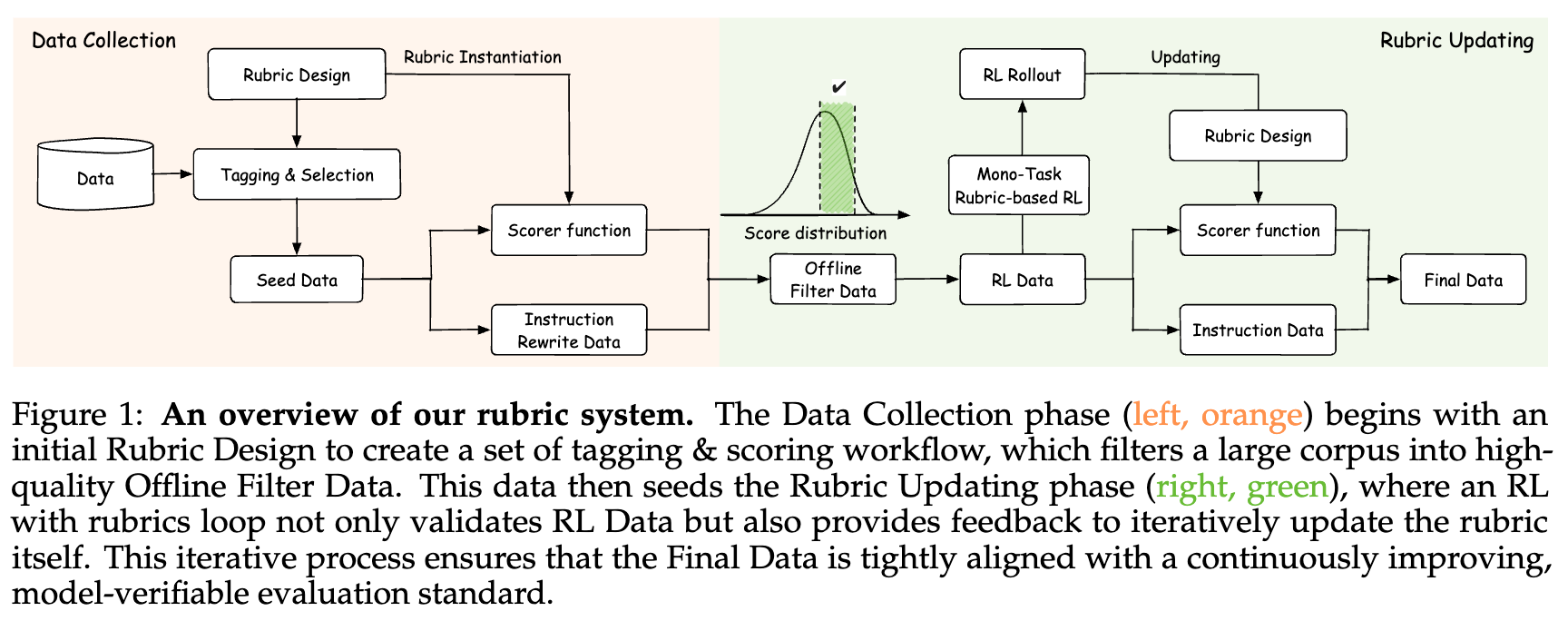
蚂蚁浙大提出基于“评分细则”(Rubric)的奖励机制,仅靠5000+样本,让30B轻松击败671B
RLVR 严重依赖于那些拥有客观、程序化可验证解的任务。这种结构性的依赖,为模型能力的扩展设置了一个“硬上限”。毕竟,在人类知识和交流里,充满了大量开放式的、
...