
Rollout 生成是强化学习(RL)训练中的主要瓶颈,在 DAPO-32B 模型中约占总训练时间的 70%。FlashRL 提供了首个开源且可用的 RL 方法,它应用了量化 Rollout 生成,加速了 RL 的训练过程,同时通过 TIS 技术保持了下游任务的性能。用户可以通过 pip install flash-llm-rl 轻松使用,并且它支持在最新的 GPU(H100)和旧款 GPU(A100)上进行 INT8 和 FP8 量化。
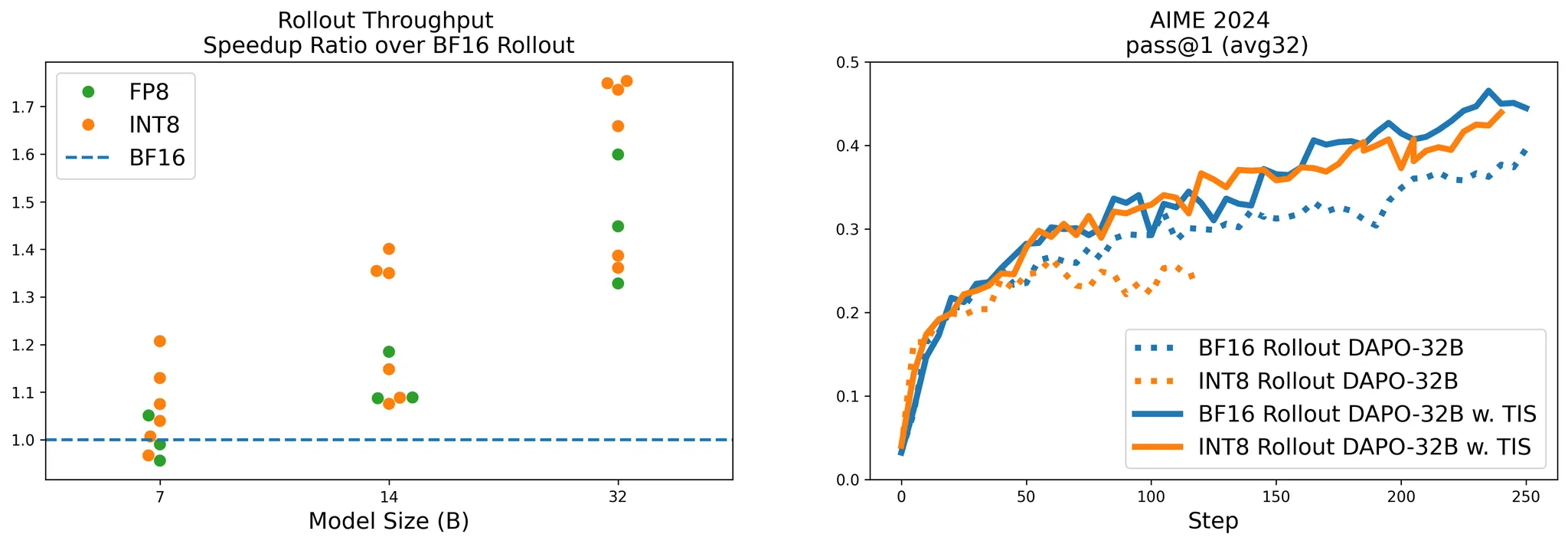
图 1 左图: 吞吐量加速比。FP8* 结果在 H100 上测量;INT8 结果在 H100 和 A100 上测试。结果是基于不同响应长度获得的。右图: 使用 BF16 Rollout 和 INT8 Rollout 的 Qwen2.5-32B 模型的 AIME 准确率。所有运行都使用 BF16 FSDP 训练后端。“TIS” 表示我们提出的 截断重要性采样 技术。[wandb]*
Rollout 量化可能会损害性能
如图 1 和 2 中的“”线所示,在没有 TIS 的情况下使用 Rollout 量化(FP8, INT8)会导致与 BF16 Rollout 相比显著的性能下降。
这是预料之中的,因为它放大了Rollout-训练不匹配问题:Rollout 是从量化策略 中采样的,但梯度是使用高精度策略 计算的:
这种不匹配使得强化学习更加“离策略”(off-policy),从而削弱了 RL 训练的有效性。
FlashRL 的秘密武器
据我们所知,FlashRL 提供了首个开源且可用的 RL 方法,它在采用量化 Rollout 的同时不牺牲下游任务的性能。
秘密武器是什么?
-
修复 Rollout-训练不匹配问题。 我们应用 截断重要性采样 (TIS) 来缓解 Rollout 和训练之间的差距。如图 1 和 2 中的实线所示,TIS 将量化 Rollout 训练的性能提升到与使用 TIS 的 BF16 Rollout 训练相同的水平——甚至超越了不使用 TIS 的朴素 BF16 Rollout 训练。 -
支持在线量化。 现有的推理引擎(如 vLLM)主要为 LLM 服务优化,对模型量化和参数更新的支持有限。我们提供了 Flash-LLM-RL包,它通过补丁方式使 vLLM 支持此功能。
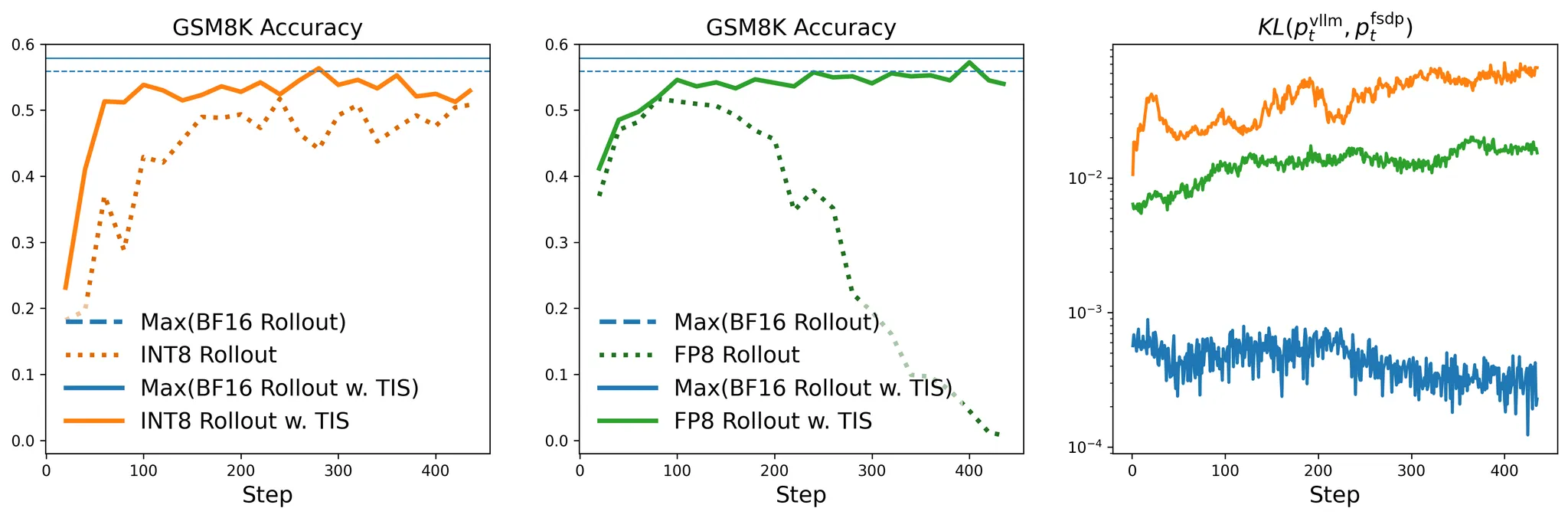
图 2 左图和中图:* 使用量化 Rollout 生成进行 RL LLM 训练的 GSM8K 准确率。请注意,TIS 对于缓解分布差距至关重要。右图: 和 之间的 KL 散度。请注意,INT8 Rollout 的 KL 散度大于 FP8 Rollout 的 KL 散度。[int8][fp8]*
FlashRL 的速度和效果如何?
比较在 RL 训练中应用不同 Rollout 精度的吞吐量具有挑战性,因为模型在不断更新,对于相同的查询,不同的量化策略在经过一定的 RL 训练更新后可能导致不同长度的响应。
在这里,我们探讨了 FlashRL 实现的加速效果及其对训练有效性的影响。
Rollout 加速
常规设置下的加速
我们记录了对 7B、14B 和 32B 的 Deepseek-R1-Distill-Qwen 模型使用 INT8、FP8 和 BF16 精度的 Rollout 吞吐量。8 位量化模型相对于 BF16 的加速比如图 1 所示。对于较小的 7B 模型,加速不到 1.2×,而对于 32B 模型,加速可达 1.75×。这表明量化对大模型的好处远大于小模型。根据我们的性能分析结果,我们建议仅在模型规模超过 14B 参数时应用量化。
内存受限设置下的加速
我们还量化了在标准的纯推理设置(RL 之外)中,应用 8 位量化可以实现的吞吐量。具体来说,我们测量了 INT8 的加速作为压力测试,以展示其在 A100/A6000 和 H100 GPU 上的适用性。
我们使用 vLLM 来服务于 BF16 和 INT8 量化的 Deepseek-R1-Distill-Qwen-32B 模型,并使用 A100/A6000 和 H100 GPU 在相同的数据集上记录吞吐量。
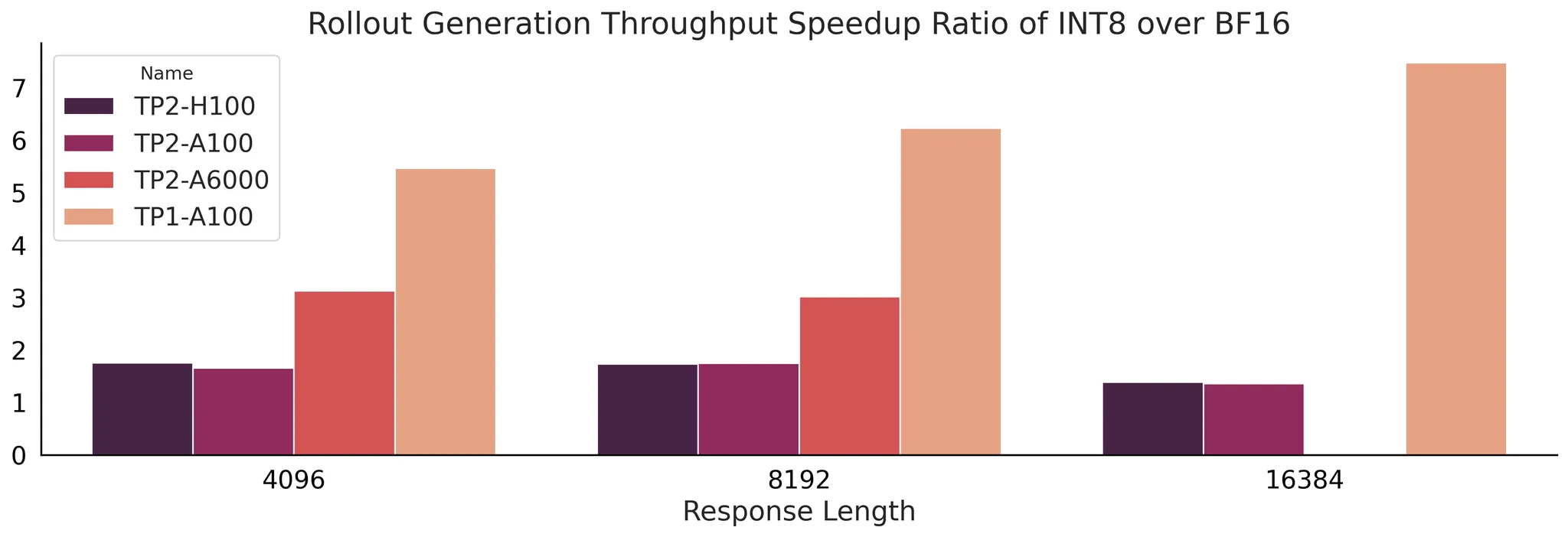
图 3 在 4 种纯推理配置中,INT8 量化的 Deepseek-R1-Distill-Qwen-32B 相对于 BF16 的吞吐量加速比,测量于不同响应长度
如图 3 所示,在 GPU 内存成为瓶颈的情况下,量化带来了极高的加速比——在 TP2-A6000 设置下生成速度提高了 3 倍以上,在 TP1-A100 设置下提高了 5 倍以上。这突显了量化在 GPU 内存受限场景(例如服务于更大的模型)中的巨大潜力。
端到端加速与有效性
我们部署了 FlashRL 来训练 DAPO-32B,并验证了我们所提方法的有效性。由于图 2 中 FP8 的分布差距小于 INT8,我们特意选择 INT8 进行此实验,作为一个更具挑战性的测试案例。
图 4 显示了在比较 BF16 和 INT8 Rollout 时的下游性能和训练加速。两种配置在 AIME 基准测试中均达到了相当的准确率,而 INT8 提供了显著的速度优势。这些结果证实,FlashRL 在不牺牲训练有效性的前提下,带来了显著的训练加速。
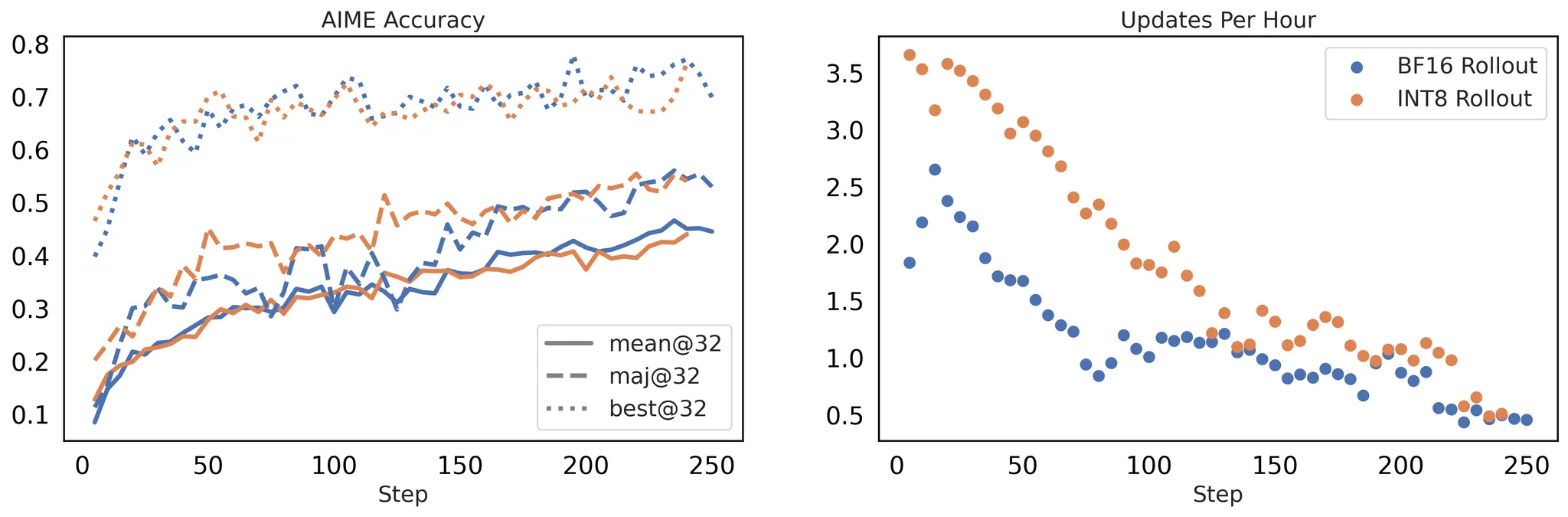
图 4。 左图: 使用 BF16 与 INT8 Rollout 精度的 RL 训练的下游性能。右图:* 使用 BF16 和 INT8 Rollout 实现的每小时更新次数。所有实验均在 Qwen2.5-32B 上使用 DAPO 方法,在 4 个节点、每个节点 8×H100 GPU 的配置下训练 250 步。[wandb]*
快速开始
以下是如何快速将 FlashRL 集成到您的 RL 训练项目中。[阅读更多]
pip install flash-llm-rl # 在所有节点上安装
export FLASHRL_CONFIG='fp8' # 如果通过 `ray submit` 提交作业,将 FLASHRL_CONFIG 添加到 runtime_env
bash your-rl-training-script # 无需更改代码!一个可行的示例:https://github.com/yaof20/verl/blob/flash-rl/recipe/flash_rl/gsm8k_qwen0_5b_fp8.sh
FlashRL 以完全即插即用的方式工作。您无需对训练代码进行任何更改——只需安装该包并设置环境变量即可。
作为一个研究项目,FlashRL 目前是作为 vLLM 的一个补丁实现的。从长远来看,我们欢迎社区努力将这些功能直接引入 vLLM / SGLang。
详细解析
对于那些对这神奇技术背后的机制及其实现方式感到好奇的读者,我们提供了 FlashRL 的详细解析。
缓解 Rollout-训练不匹配问题
截断重要性采样 (TIS)
在我们的早期博客中,我们解释了截断重要性采样如何减少由推理和训练引擎差异引起的 Rollout-训练不匹配问题。在这里,我们应用相同的技术来解决一个更大的不匹配问题,即 Rollout 使用低精度以提高速度,而训练引擎保持高精度。
我们下面提供了一个高级速查表,并强烈建议读者查看我们之前的博客以获取更多细节和见解。
-
理解 TIS 的速查表 -
期望策略梯度 (Expected Policy Gradient)
-
VeRL/OpenRLHF 的实现 (重计算)
-
截断重要性比 (TIS):
-
与两种 TIS 变体的比较
我们还总结了两种用于缓解分布差距的替代方案。
-
PPO 重要性采样 (PPO-IS)
*注意:Colossal 框架使用此实现。
-
普通重要性采样 (vanilla-IS)
*注意:Nemo-RL 使用此实现。
为了评估 TIS 的有效性并理解其设计选择的影响,我们进行了实验,将 TIS 与上述两种变体进行了比较。TIS 的表现始终优于这两种变体,尤其是在差距较大(例如 FP8/INT8)的情况下。
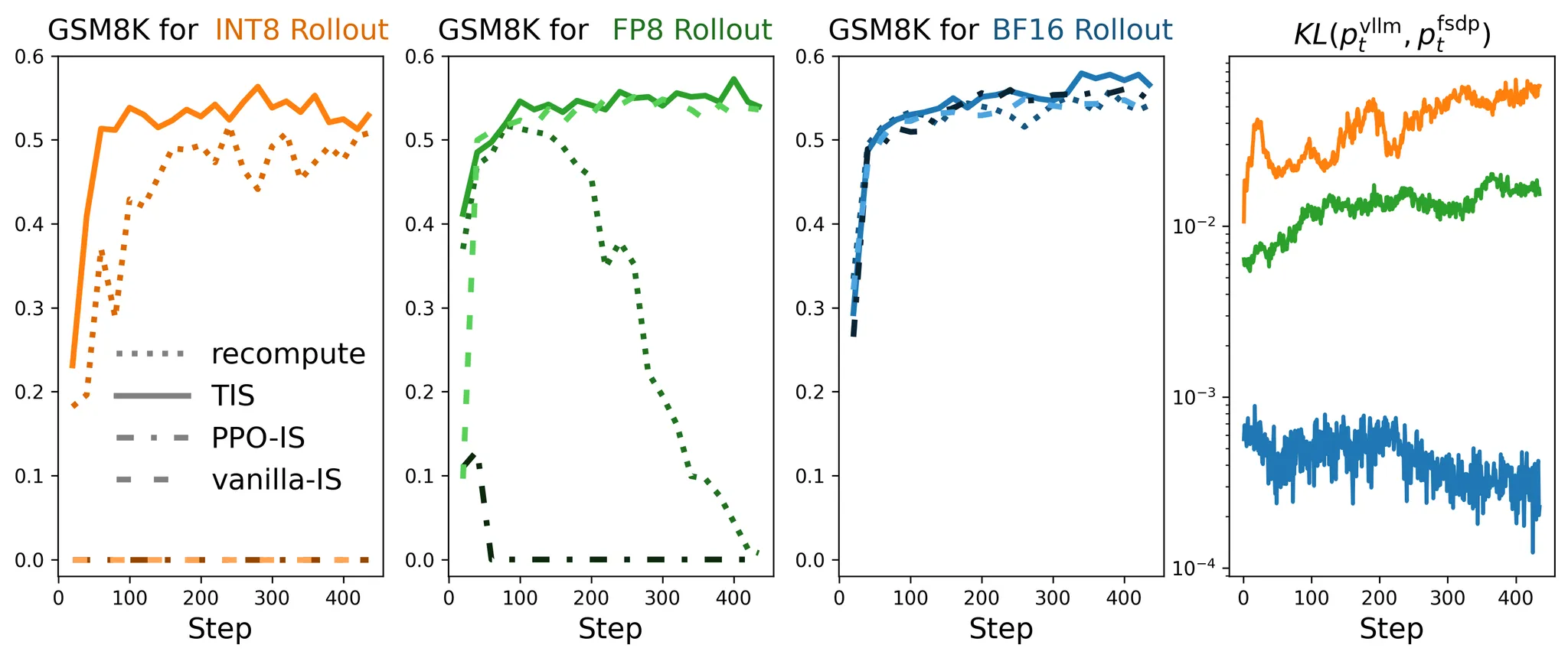
图 5 我们在 Qwen2.5-0.5B 上使用 GSM8k 对不同的 Rollout-训练不匹配缓解策略进行了消融实验。请注意,PPO-IS 和 Vanilla-IS 对于 INT8 Rollout 的准确率接近 0,因此高度重叠。我们还在右侧绘制了 vLLM 采样分布与 FSDP 分布之间的 KL 散度。*[int8 wandb][fp8 wandb][bf16wandb]*
通过校准转移实现实时 INT8 量化
虽然 FP8 量化可以很自然地以在线方式进行,但 INT8 量化通常需要对不同的模型进行复杂的校准过程,这很难实时完成。 以前的做法通常是在需要时一次性进行 INT8 量化,并且不用于像 RL 这样的在线更新设置。
据我们所知,我们是第一个以在线和高性能的方式执行 INT8 量化的。这很困难,因为校准过程非常慢(需要数小时),因此我们无法在每个 RL 步骤都进行校准。相反,我们在训练开始时计算一次校准结果,并在每个在线步骤中重复使用它。这是基于我们的一个观察:与 SFT 相比,RL 对模型权重的改变不那么剧烈。为了证明这一点,我们对 SFT 和 RL 的校准结果的可转移性进行了分析:
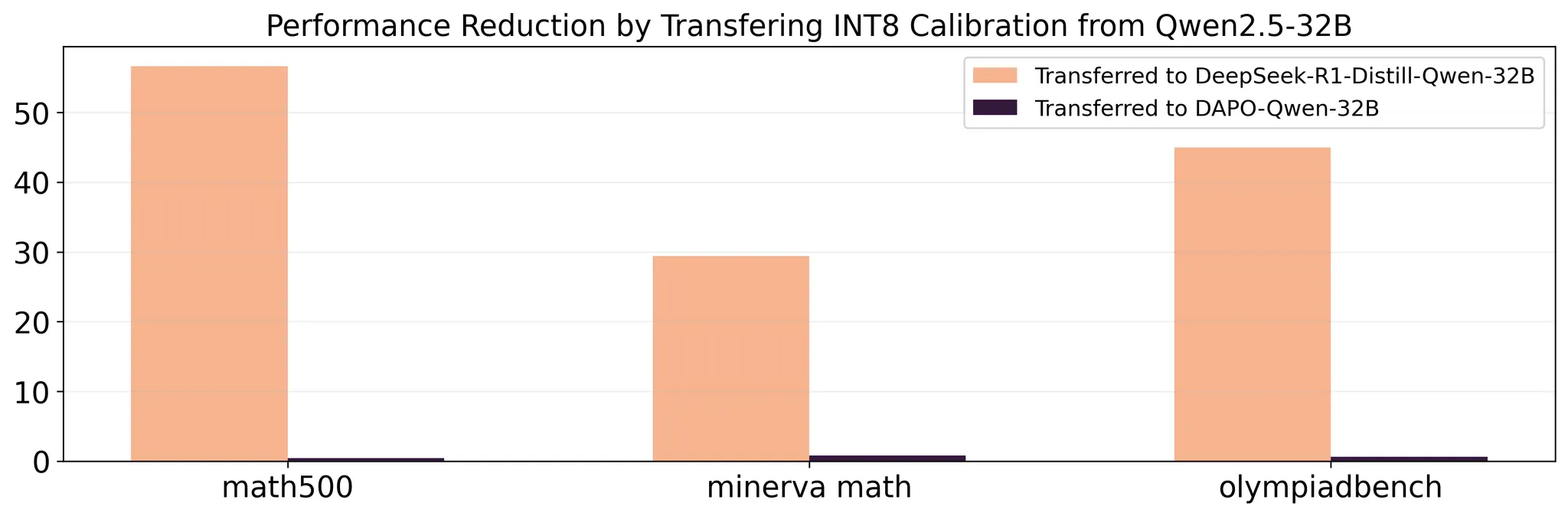
图 6 我们对从 Qwen2.5-32B 基础模型通过 SFT / RL 微调的模型进行了实验。我们发现,与 SFT 相比,将基础模型的校准结果重用于 RL 微调模型几乎不会改变性能。这表明,通过重用先前的校准结果,INT8 在线量化在 RL 中是切实可行的。
-
关于 SFT / RL 分析的详细信息
我们从 DeepSeek-R1-Distill-Qwen-32B 模型开始,该模型是从 Qwen2.5-32B 基础模型进行 SFT 训练得到的。作为基线,我们首先以标准方式量化了 DeepSeek-R1-Distill-Qwen-32B 模型。然后,我们使用 Qwen2.5-32B 基础模型的校准结果来量化 DeepSeek-R1-Distill-Qwen-32B 模型,这与前面提到的量化基线相比导致了显著的性能下降;例如,在 Math-500 中,将校准结果重用于 SFT 训练的模型导致了 62.5% 的性能恶化。这表明 SFT 会大幅改变模型参数,因此校准重用是不切实际的。
接下来,我们对从 Qwen2.5-32B 基础模型进行 RL 训练的 DAPO-Qwen-32B 进行了类似的实验。我们发现,与直接量化 DAPO-Qwen-32B 模型相比,应用从 Qwen2.5-32B 基础模型计算的校准结果来量化 DAPO-Qwen-32B 模型仅对性能产生轻微影响(例如,在 minerva math 中仅带来 1.9% 的下降)。
原文:https://fengyao.notion.site/flash-rl
往期文章:


