对于大语言模型的后训练(post-training)而言,研究者通常面临两种主流技术路径:监督微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL)。SFT 使用高质量的“指令-回答”对,通过模仿学习的方式直接优化模型,使其行为对齐至特定任务的数据分布。而 RL,特别是带有可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR),则通过定义一个奖励函数(例如,代码执行是否通过、数学题答案是否正确)来激励模型通过试错探索,从而在如数学、代码、复杂推理等任务上取得显著的能力提升。
尽管 RLVR 效果显著,但它也带来了两个看似矛盾的现象:
-
高昂的计算成本:RLVR 需要在线策略(on-policy)学习,涉及大量的样本生成(rollouts)、奖励评估和策略更新,其计算开销远超 SFT。 -
稀疏的参数更新:与高昂的成本形成对比,实证研究发现,经过 RLVR 训练后,模型参数的实际变化量占比很小。相较于 SFT 导致的密集(dense)参数更新,RLVR 的更新呈现出高度的稀疏性(sparsity)。
我们会有几个疑问:一个高成本、高收益的训练过程,为何最终只依赖于对模型权重进行微乎其微的修改?这种稀疏性是随机产生的,还是遵循某种未被发现的规律?更重要的是,理解这一现象能否帮助我们设计出更高效的 RL 算法?
Meta AI 的论文《The Path Not Taken: RLVR Provably Learns Off the Principals》对此进行了系统性的研究。文章揭示了所谓的“稀疏性”仅仅是一个表象,其背后隐藏着一种由预训练模型自身结构决定的、具有持续性的“模型条件优化偏置”(model-conditioned optimization bias)。作者提出了一个名为“三门理论”(Three-Gate Theory)的解释框架,并提供了一系列理论和实验证据来验证该框架。

-
论文标题:The Path Not Taken: RLVR Provably Learns Off the Principals -
论文链接:https://arxiv.org/pdf/2511.08567
1. 从稀疏性表象到优化偏置的本质
论文首先重新审视了 RLVR 训练中的参数更新稀疏性问题,并将其从一个简单的统计现象深化为一个结构化的优化行为。
1.1 对稀疏性的再量化
先前的工作指出 RL 微调只会改变一小部分网络参数。然而,这些研究在量化参数变化时,可能忽略了 bfloat16 这种低精度浮点数格式的特性。bfloat16 只有 7 个尾数位,这意味着其能够表示的最小数值差异(Unit in the Last Place, ULP)是与数值本身的大小相关的。对于绝对值较大的权重,一个微小的相对变化可能低于其 ULP,从而在存储层面不产生任何变化;反之,对于绝对值较小的权重,一个极小的绝对变化也可能被记录。因此,使用固定的绝对容忍度来判断权重是否改变是不可靠的。
为解决此问题,论文作者设计了一个 bfloat16 动态阈值。两个 bfloat16 数值 和 被认为是“未改变”的,当且仅当它们的差值小于由其自身大小决定的一个动态阈值:
这个定义确保了只有在二进制表示发生实际变化时,权重才被视为“已改变”。
基于这个更鲁棒的度量,作者分析了多个公开的模型检查点。
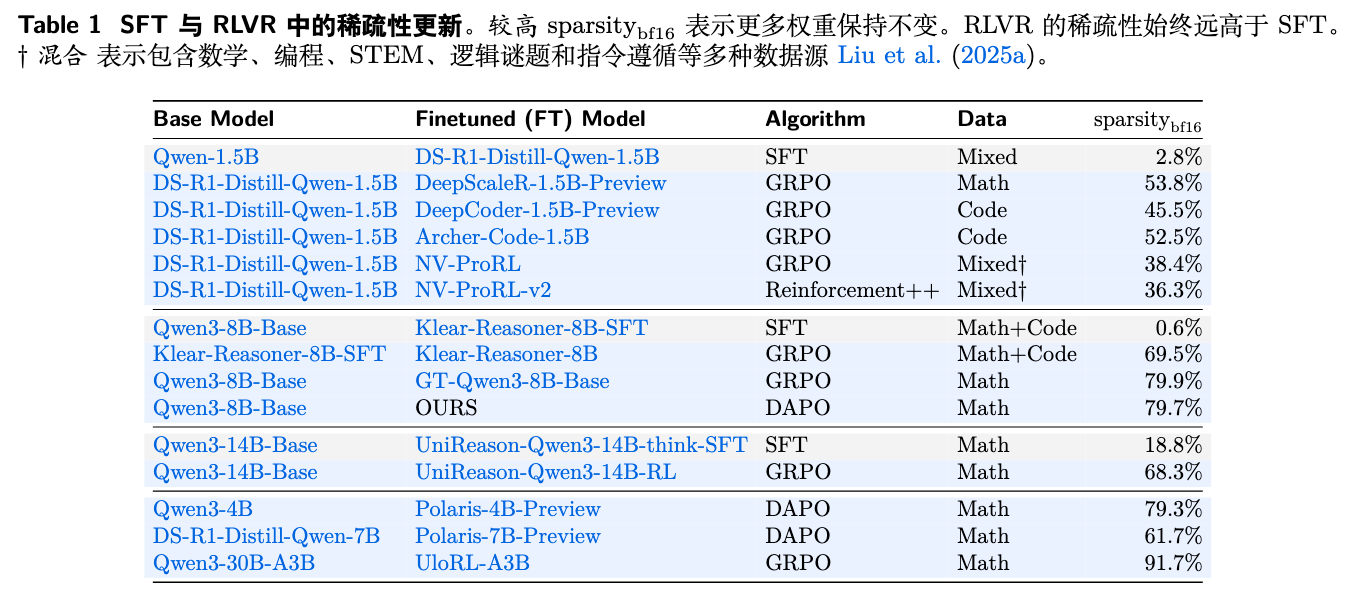
如表 1 所示,分析结果确认了 RLVR 的更新确实比 SFT 稀疏得多。SFT 的稀疏度通常很低(例如 0.6%-18.8%),意味着大部分参数都发生了变化。而 RLVR 的稀疏度则高出一个数量级(36%-92%)。但值得注意的是,在当前这些更新的模型上,绝对的稀疏度水平低于一些早期报告的数值,这凸显了使用 bfloat16 动态阈值进行重新评估的必要性。
1.2 优化偏置
仅仅知道更新是稀疏的是不够的。关键问题在于:这些变化的参数是随机分布的,还是集中在特定的区域?
为了回答这个问题,作者对五个在不同数据集上、使用不同 RLVR 算法(GRPO, Reinforcement++, DAPO)训练的 DS-Qwen-1.5B 模型检查点进行了分析。他们首先为每个模型生成一个二值的“变化掩码”(changed mask),标记出所有发生变化的权重位置。随后,他们计算了这些掩码之间的成对杰卡德相似度(Jaccard Overlap)。
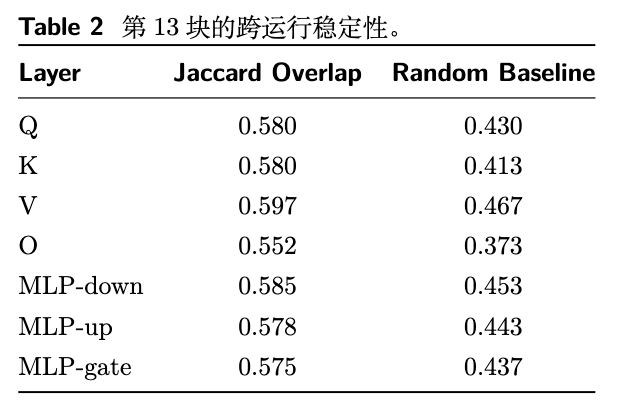
结果如表 2 所示,不同运行之间的 Jaccard Overlap 显著高于随机基线,这证明了 RLVR 的参数更新并非随机,而是具有高度的一致性。无论训练数据和具体 RL 算法如何变化,只要预训练的基座模型固定,更新就会稳定地作用于同一片参数子集上。这揭示了一种“模型条件”(model-conditioned)的特性——优化的路径似乎是由模型自身的初始状态预先“设定”好的。
为了进一步可视化这种偏置,作者计算了“共识率”(Consensus Ratio),即在五个独立运行中,某个特定权重被更新的频率。
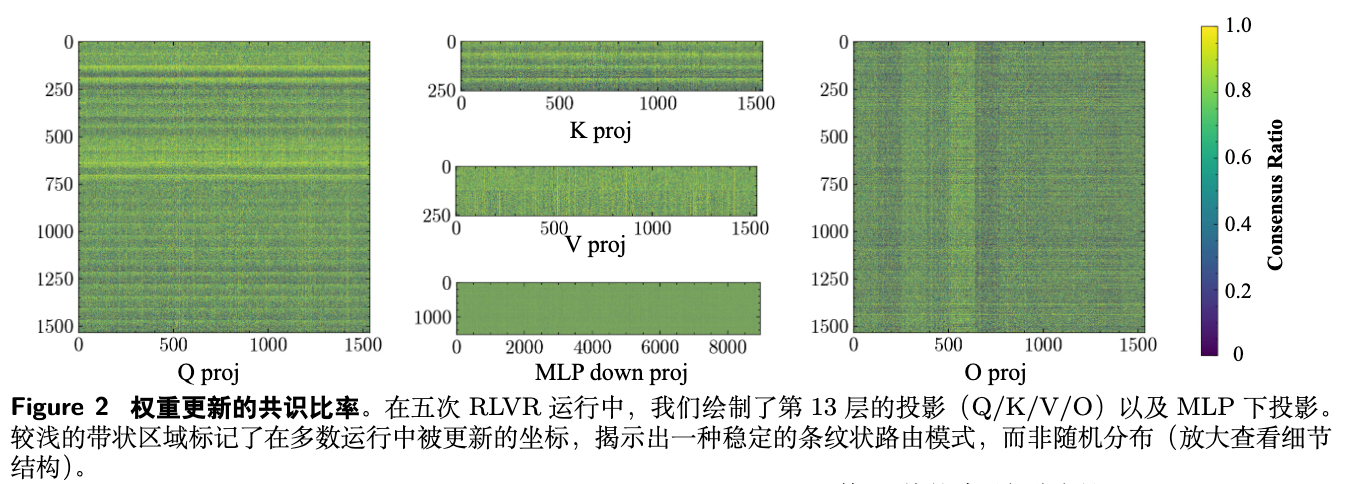
如图 2 所示,共识率高的区域(图中亮带)呈现出清晰的条纹状结构,例如在 Q/K/V 投影中表现为行条纹,在 O 投影中表现为列条纹。这种模式化的、非均匀的分布,进一步证实了更新是沿着模型参数矩阵的特定维度进行的。
1.3 偏置的动态演化
这种优化偏置是在训练的哪个阶段形成的?它会随着训练的进行而改变吗?作者追踪了 DS-Qwen-1.5B 模型在训练过程中(240、720、1200步)的权重更新模式。
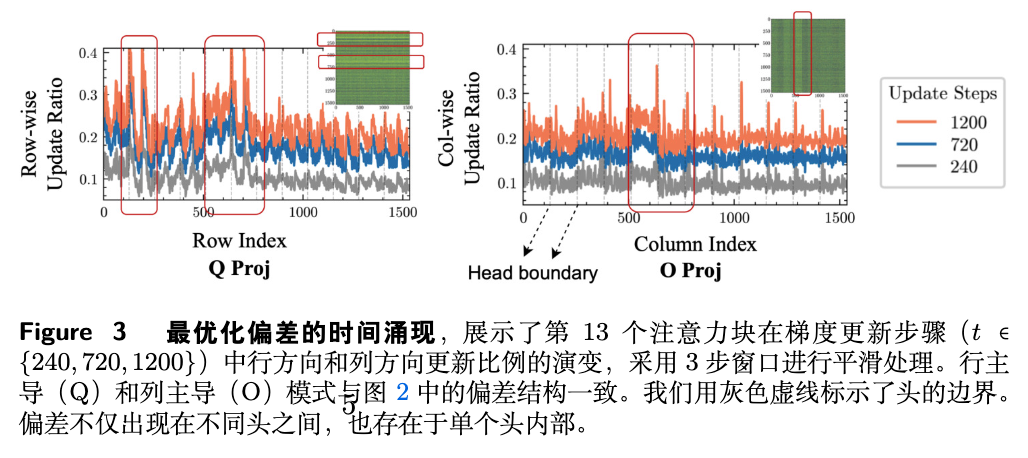
图 3 展示了在第13个注意力块中,按行和按列统计的更新率。可以观察到,更新模式的“峰”和“谷”在训练早期就已经出现,并且随着训练的进行,整体密度虽然增加,但其相对轮廓保持稳定。这表明 优化偏置在训练初期就已确立,并被持续强化,而非一种短暂的瞬态现象。
1.4 稀疏性的再解释
综合以上观察,作者提出了一个核心论点:我们观测到的稀疏性,实际上是底层优化偏置与 bfloat16 有限精度相互作用的结果。
可以想象,RLVR 的优化过程对参数空间的不同区域有着不同的“更新意愿”。在某些“偏好”区域,它会施加较大的更新;而在其他“非偏好”区域,它只会施加微小的、低于 bfloat16 精度阈值(sub-ULP)的更新。由于这些微小更新无法在存储中体现,这些区域的权重值便维持不变,从而在宏观上呈现出“稀疏性”。
因此,稀疏性本身不是目标,也不是原因,它只是一个可见的现象。真正的核心机制是那个决定了更新“落在哪”以及“有多强”的优化偏置。接下来的问题自然是:这个偏置从何而来?
2. 三门理论
为了从机理上解释这个模型条件的优化偏置是如何产生并发挥作用的,作者提出了“三门理论”(Three-Gate Theory)。该理论将 RLVR 的单步更新过程分解为三个连续的门控阶段:约束、引导和过滤。
2.1 KL 散度
第一道门是 KL 散度约束。RLVR 算法,无论是像 PPO 那样带有明确 KL 惩罚项的,还是像 DAPO 那样通过裁剪重要性采样比率(ratio clipping)来实现的,其本质都是在线策略(on-policy)方法。这意味着每一步的策略更新都必须在一个信任域(trust region)内进行,不能与当前策略偏离太远。
作者从理论上证明(命题 3.1 和 3.2),这种对策略空间的 KL 约束,会直接转化为对参数空间中权重更新范数 ||ΔW|| 的一个上界。
其中 是单步策略变化的 KL 预算, 是费雪信息矩阵(Fisher Information Matrix)的最小特征值。
KL 散度确保了 RLVR 的每一步更新都是保守的、局部的。它解释了为什么 RLVR 的参数变化是微小的,但它没有回答这些微小的变化会走向何方。
2.2 模型几何
第二道门是理论的核心。作者认为,在一个由 KL 限定的局部范围内,更新的具体方向是由 预训练模型的几何结构 所决定的。
一个经过良好预训练的语言模型,其 weight landscape 并非随机初始化的模型那样平坦或混乱,而是高度结构化的。其中包含了不同曲率的区域。高曲率方向通常对应着模型学到的关键、稳定的知识,对其进行微小扰动就可能导致模型行为的剧烈变化。而低曲率方向则提供了在不显著改变模型核心功能的前提下进行调整的“冗余空间”。
作者的核心假设是:KL 约束下的 RL 更新,会被引导至远离高曲率方向,而进入那些低曲率的、能够保持预训练模型谱结构(spectral structure)的子空间。
这个假设带来了几个可验证的推论:
-
谱结构保持:RLVR 更新应该倾向于保持权重矩阵的奇异值(singular values)和奇异向量子空间(singular subspaces)的稳定。相比之下,SFT 作为一种将模型强行拉向外部数据分布的监督学习方法,则会更剧烈地改变模型的谱结构。 -
有限的子空间旋转:权重矩阵的主奇异子空间(principal singular subspaces)在更新后应该只发生微小的旋转。 -
奇异值的稳定性:主要的奇异值的大小应该保持相对稳定。
这种引导机制解释了优化偏置的“模型条件”特性:因为是预训练模型的几何结构在起作用,所以偏置对于固定的模型是稳定的,而与下游的数据集或 RL 算法无关。
2.3 精度
第三道门是 bfloat16 的有限精度。
在模型几何引导下,更新被分配到不同区域。在低曲率的“偏好”区域,更新幅度较大,超过了 bfloat16 的表示阈值,因此被记录下来。而在高曲率的“非偏好”区域,模型只愿意进行微小的、sub-ULP 级别的调整,这些调整由于精度限制而被“过滤”掉了,使得这些权重看起来没有发生任何变化。
需要再次强调论文的观点:精度是偏置的放大器(amplifier),而非原因(cause)。优化器状态(如 Adam 的一阶和二阶矩)通常以 float32 存储,梯度累积也是在高精度下进行的。因此,稀疏性不能简单地归咎于精度本身,而是优化偏置与有限精度相互作用的必然结果。
3. 实验
为了验证“三门理论”,尤其是核心的“模型几何”门,作者设计了一系列实验。
3.1 谱几何分析
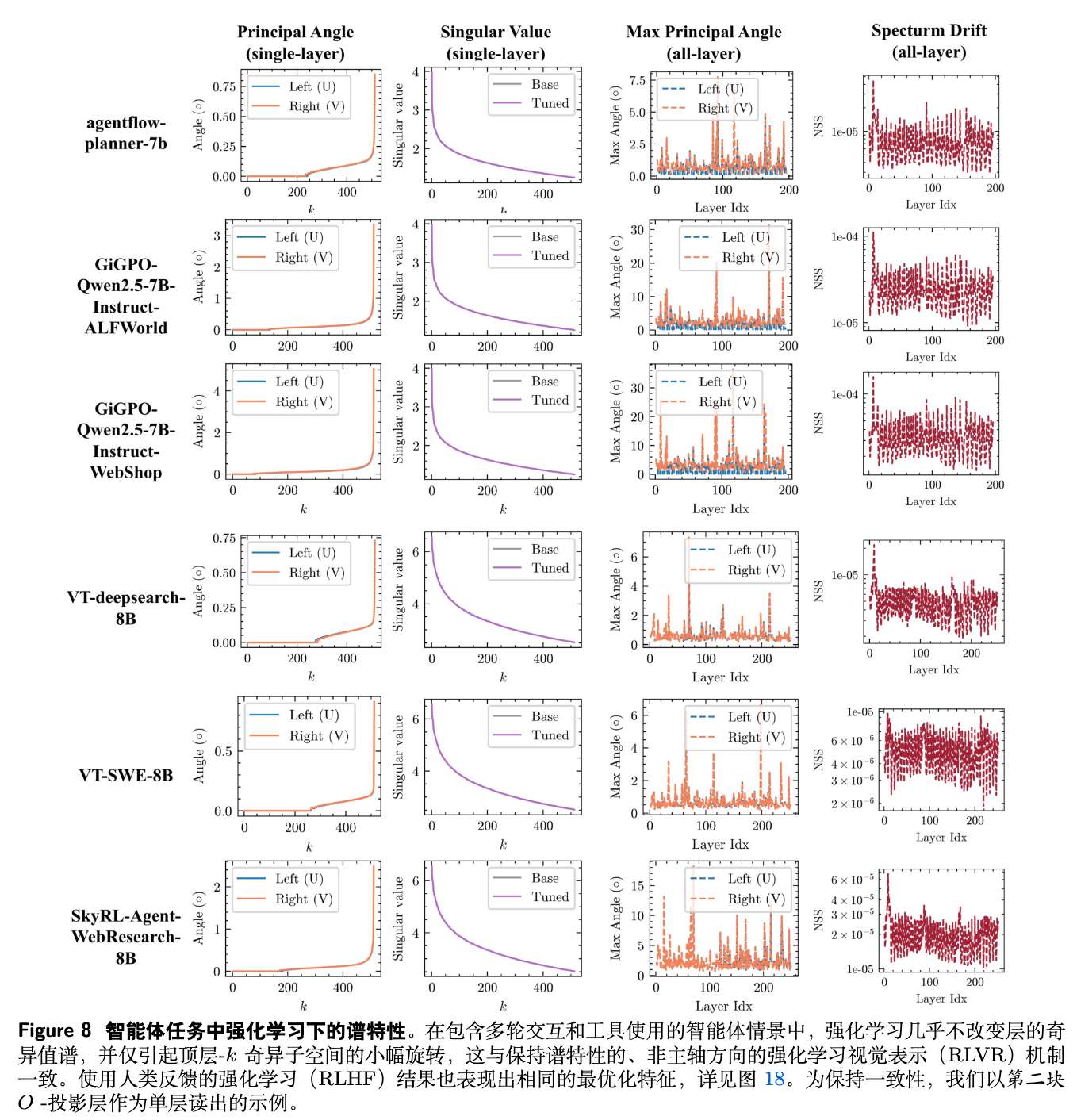
作者对比了在 Qwen3-8B 模型上分别进行 SFT 和 RLVR 训练后,模型各层权重矩阵的谱结构变化。
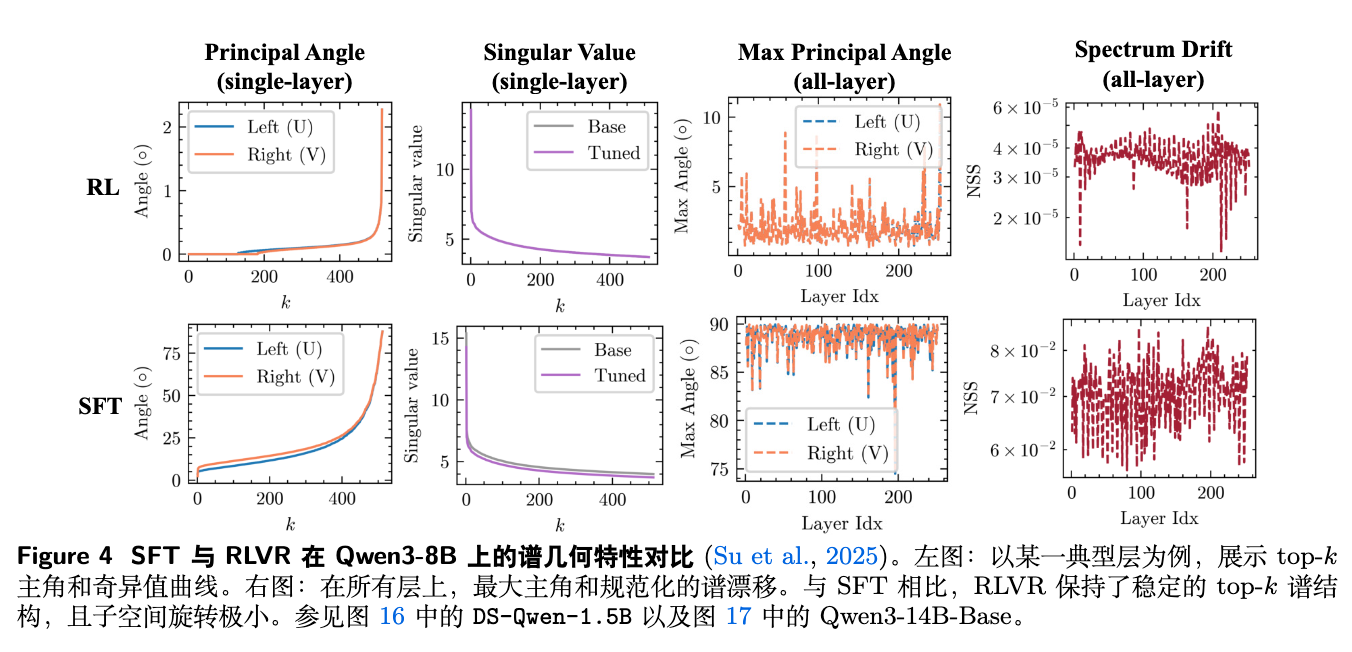
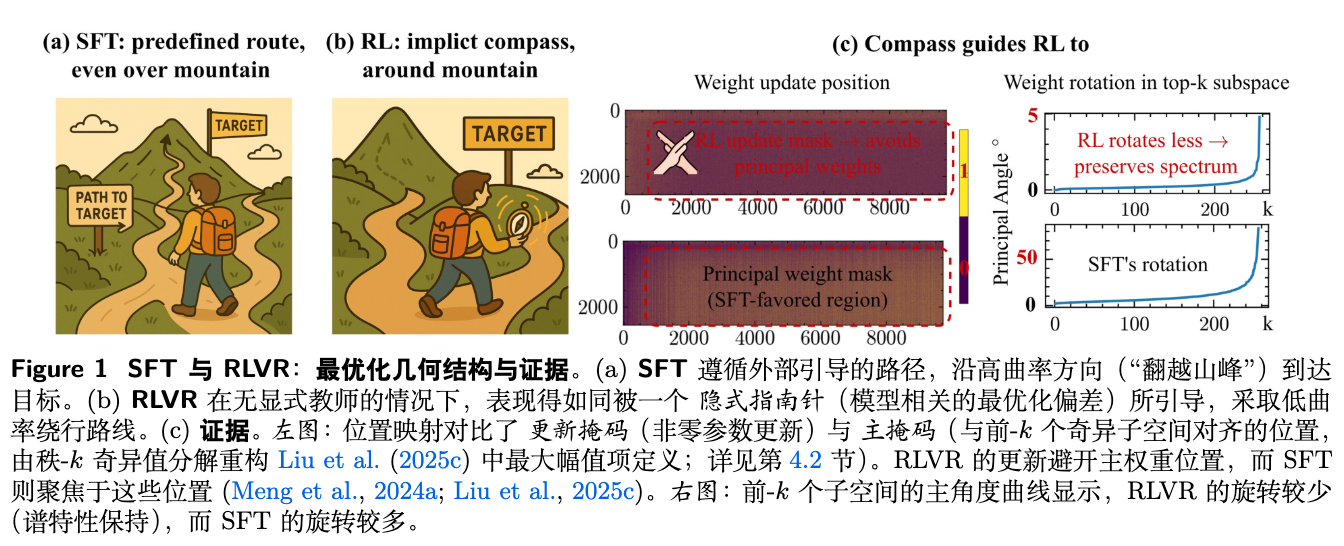
图 4 的结果清晰地支持了理论预测。对于 RLVR:
-
单层分析:主奇异角(principal angle)非常小,表明奇异子空间几乎没有旋转。奇异值曲线(singular value curve)在训练后与训练前(Base)几乎完全重合。 -
跨层分析:所有层的最大主奇异角和归一化谱漂移(normalized spectral drift, NSS)都维持在非常低的水平。
而 SFT 则呈现出截然不同的现象:主奇异角和谱漂移都大得多,表明 SFT 显著地扭曲了预训练模型的谱结构。
这一结果有力地证明了 RLVR 确实在沿着“谱保持”的路径进行优化。
3.2 更新位置分析
直接量化高维空间中的曲率是极其困难的。因此,作者采用了一个高效的代理(proxy):主权重(principal weights)。主权重被定义为通过低秩奇异值分解(SVD)重构的权重矩阵中,绝对值最大的那些权重。近期的研究表明,这些权重构成了模型中最重要的计算通路,扰动它们会对模型性能(特别是推理能力)造成严重影响。因此,可以合理地认为,主权重所在的方向对应着模型权重景观中的高曲率方向。
基于此代理,作者分析了 RL 更新掩码 M 与主权重掩码 M_princ 以及低幅值权重掩码 M_low 之间的重叠关系。
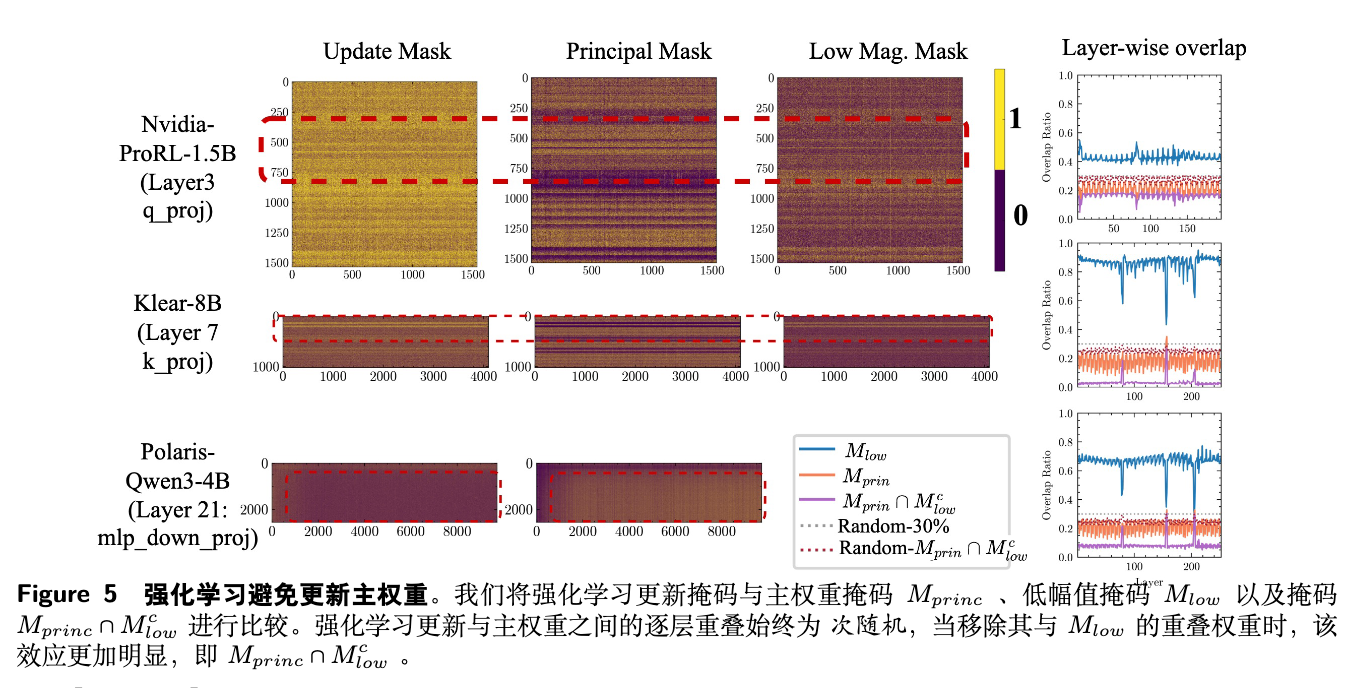
图 5 的结果揭示了一个明确的二分现象:
-
RL 更新与 主权重 的重叠度持续性地 低于随机基线。这意味着 RLVR 在主动地“规避”这些被认为是高曲率、高重要性的区域。 -
相反,RL 更新与 低幅值权重 的重叠度则 高于随机基线。这符合精度门的逻辑:幅值越低的权重,其 sub-ULP 阈值也越低,因此更容易被微小的更新所改变,成为“低阻力”路径。
这一发现为“模型几何”门提供了第二个关键证据,并深刻地揭示了 RLVR 和 SFT 在参数空间中的优化动态是截然不同的:SFT 倾向于调整最重要的主权重,而 RLVR 则在其他“非主”区域进行修改。
3.3 因果干预
为了建立模型几何与优化偏置之间的因果关系,作者进行了一项干预实验。他们选择 Qwen3-4B 模型中的特定层(例如第20层和第25层),并对其几何结构进行“置乱”(scramble)。具体方法是,对 V/O 投影矩阵应用一个随机的正交旋转(不改变其范数和计算功能),并对 Q/K/V/O 的注意力头进行置换。这种操作在保持层功能不变的前提下,破坏了其原始的几何结构(例如奇异向量的方向)。
然后,他们在一个新的 RLVR 任务上进行训练,并观察更新掩码的重叠度。
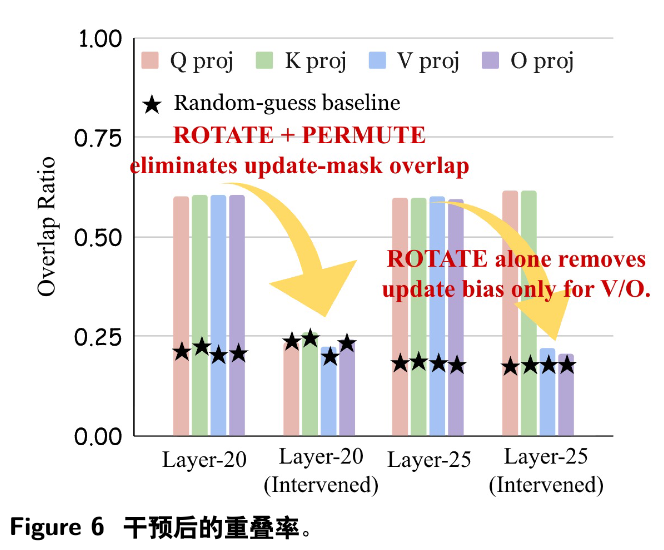
结果如图 6 所示,在未经干预的层,不同运行之间的更新重叠度依然很高。但在被施加了正交旋转的层,更新重叠度骤降至随机水平。这提供了因果证据,证明了 预训练模型的几何结构正是引导优化偏置的根源。一旦几何结构被破坏,引导作用消失,更新模式就退化为随机。
3.4 泛化验证
上述发现是否仅限于基于可验证奖励的数学和代码任务?作者将分析扩展到了更广泛的场景,包括:
-
Agent 任务:分析了 AgentFlow、SKYRL-Agent 等执行多轮交互和工具使用的模型。 -
人类反馈强化学习(RLHF):分析了使用 DPO 和 SimPO 算法训练的指令遵循模型(Llama-3-Instruct)。
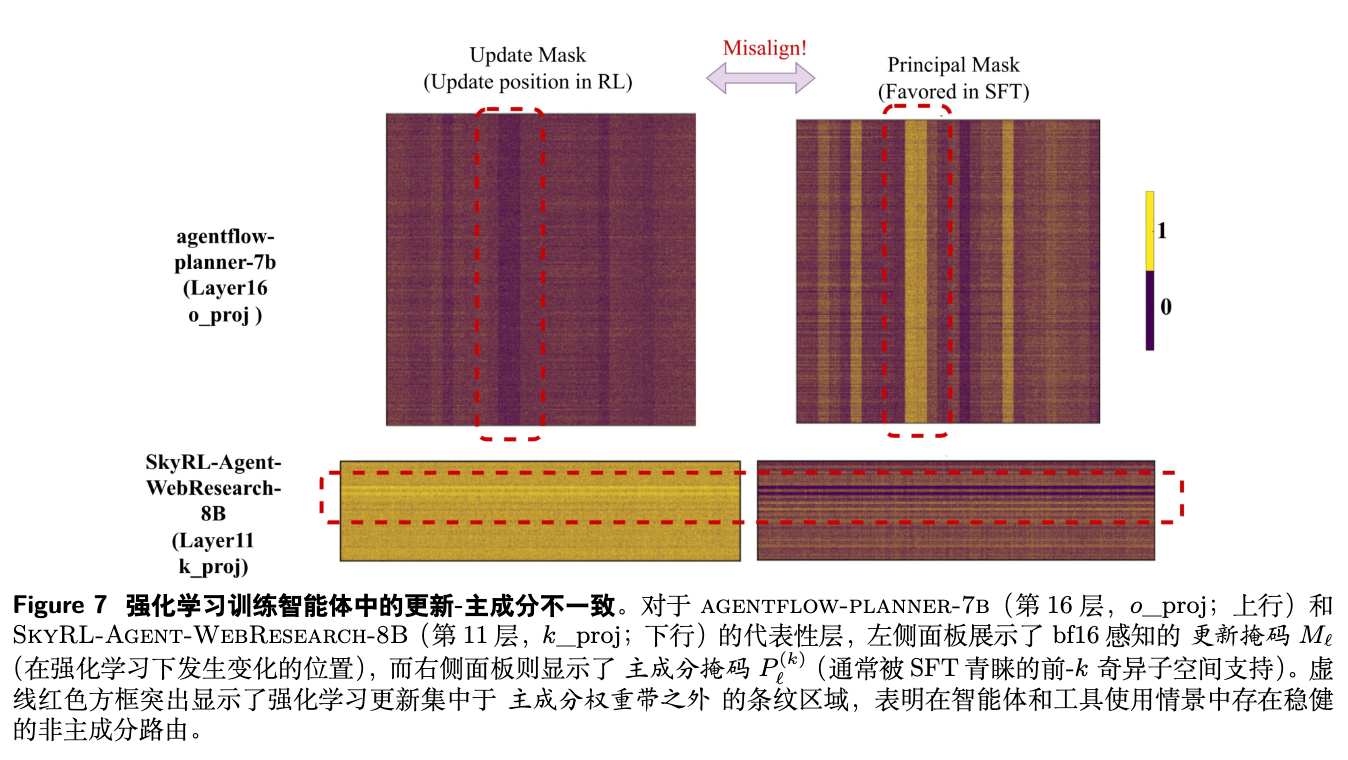
分析结果表明,在这些更多样化的 RL 场景中,同样的优化特征依然存在:谱结构保持稳定,奇异子空间旋转微小,并且更新位置持续地与主权重区域错开(misaligned)。这说明,本文发现的“规避主权重、保持谱结构”的优化动态,可能是 KL 锚定的 RL 后训练方法(包括 RLVR 和 RLHF)的一个普遍特征。
4. 实践启示
这项研究不仅提供了一个解释性的理论,更对如何为 RL 设计参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法提出了深刻的见解。
论文的核心实践论点是:既然 RLVR 和 SFT 的优化动态在根本上是分离的,那么为 SFT 时代设计的、与 SFT 优化几何对齐的 PEFT 方法,很可能不适用于 RLVR,甚至会产生负面效果。
作者通过两个案例研究来验证这一论点。
4.1 案例一:稀疏微调的探针实验
作者设计了不同的固定掩码(mask)来进行稀疏 RL 微调,并观察其训练动态(通过与基座模型的 KL 散度来衡量学习进程)。
-
M_princ:只更新 top-50% 的主权重(SFT 偏好的方向)。 -
M_princ_complement:只更新另外 50% 的非主权重。 -
M_low U M_princ_complement(安全掩码):只更新非主且低幅值的权重(理论上 RLVR 偏好的方向)。
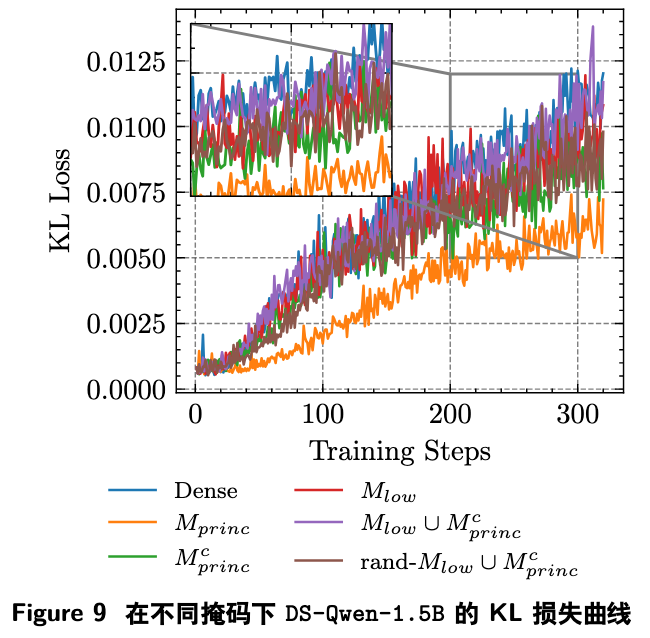
结果如图 9 所示,只更新主权重的 M_princ 策略,其 KL 曲线增长最慢,最终精度也最低,表明学习受到了严重阻碍。这证实了强迫 RLVR 沿着 SFT 的路径走是低效的。与之形成鲜明对比的是,“安全掩码”策略的 KL 曲线与全参数微调(Dense)的轨迹最为接近,最终也取得了相当的性能。
这不仅验证了理论的正确性,还提供了一个简单有效的实践指导:在 RL 中,冻结主权重和高幅值权重,而只更新非主、低幅值的权重,可能是一种高效的稀疏微调策略。
4.2 案例二:重新审视 LoRA 及其变体
近期有报告(https://thinkingmachines.ai/blog/lora/)指出,即使是极低秩(如 rank-1)的 LoRA 也能在 RL 中匹配全参数微调的性能。作者的理论为此提供了解释:全参数 RL 的有效更新本身就发生在低曲率、谱保持的“非主”方向上,这种更新天然具有低秩特性。因此,一个低秩的 LoRA 适配器足以近似这种更新,而冻结的基座权重则天然地起到了正则化作用,阻止了向主方向的移动。
然而,该报告也暗示,像 PiSSA 这样为 SFT 设计的、旨在将更新更精确地对齐到主奇异向量方向的 LoRA 变体,可能会带来进一步的收益。作者的理论对此提出了反对意见:PiSSA 的设计理念与 RLVR 的内在几何偏好完全相悖。
为了验证这一点,作者在数学任务上对比了标准 LoRA 和 PiSSA 的性能。
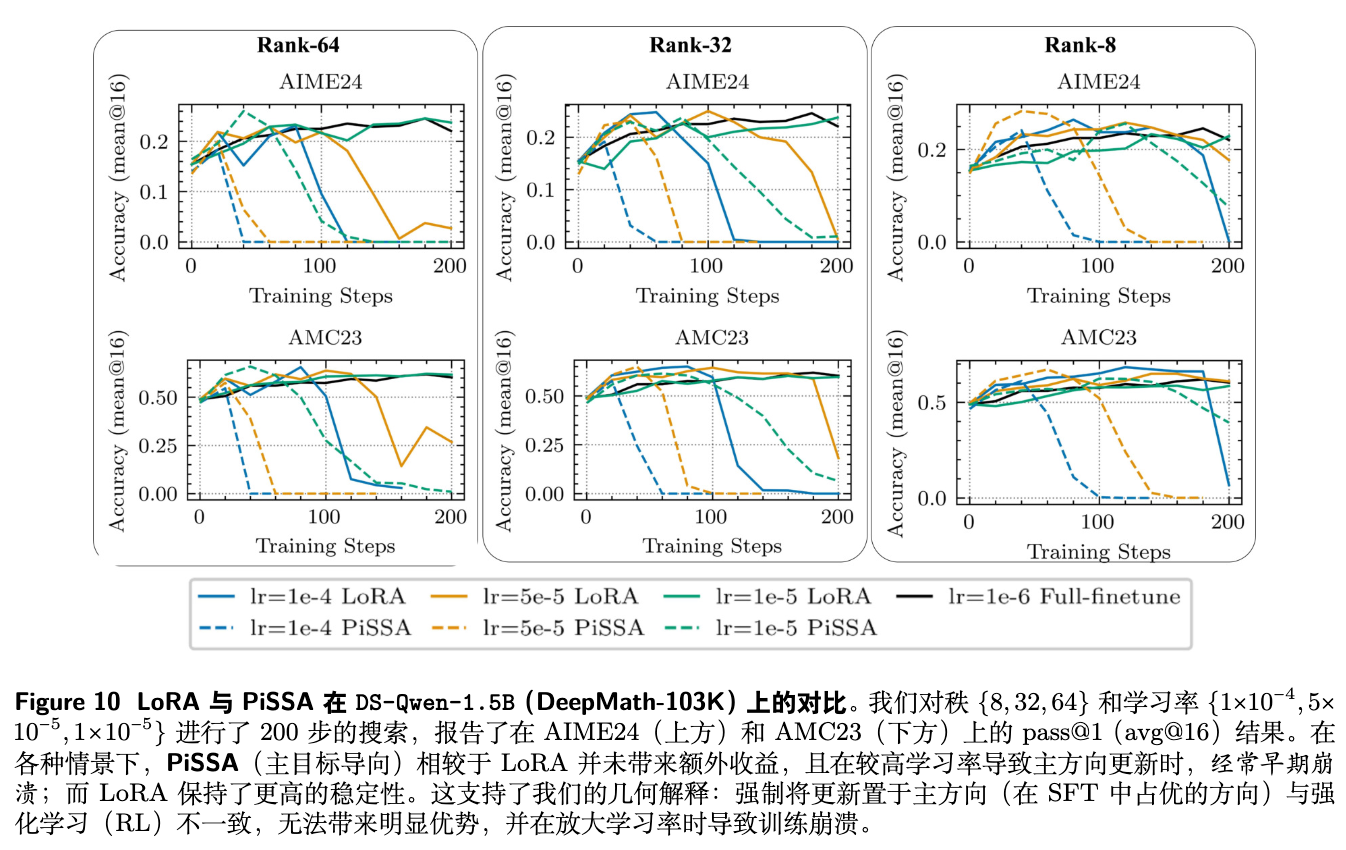
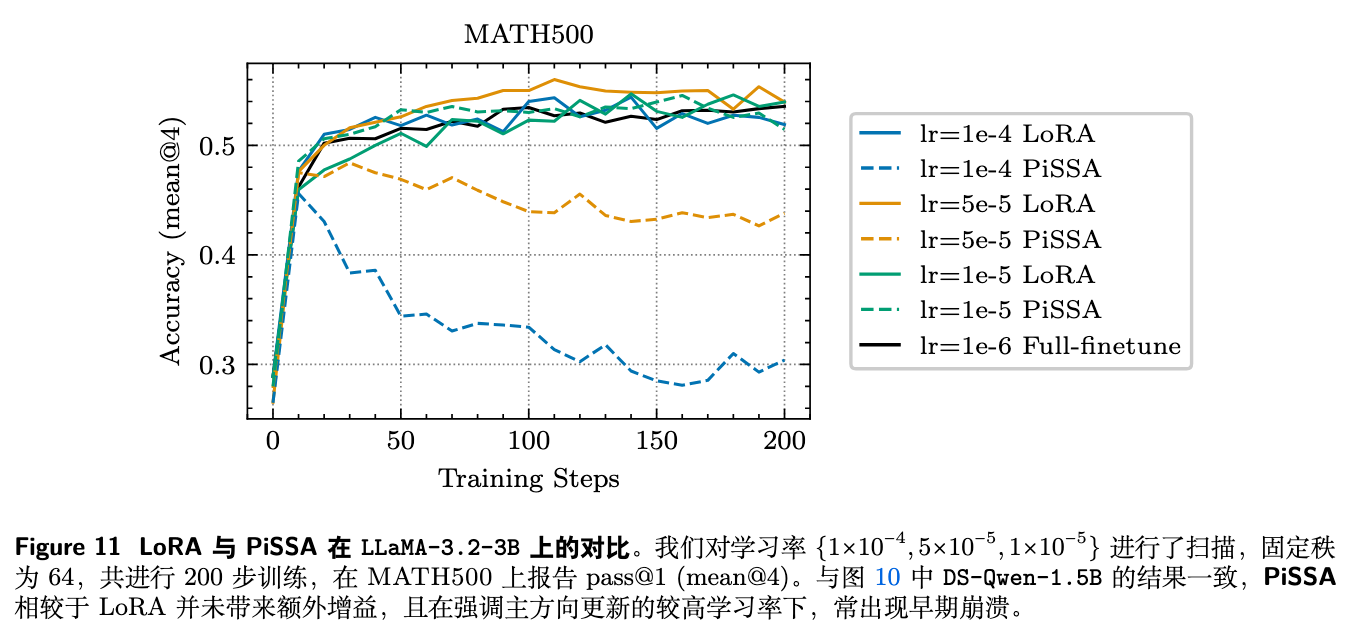
实验结果如图 10 和图 11 所示,在所有配置下,PiSSA 相比标准 LoRA 都没有提供任何明显的增益。更糟糕的是,在需要较高学习率来匹配全参数性能时,PiSSA 往往会变得不稳定,训练过程提前崩溃。这是因为提高学习率会强制更新沿着主方向进行,而这正是 RLVR 倾向于规避的高曲率、谱扭曲方向,从而导致优化过程的脆化。
这个案例研究发出了一个明确的警示:不能想当然地将 SFT 时代的 PEFT “最佳实践”平移到 RL 场景中。为 RL 设计 PEFT 算法,需要考虑其独特的、由几何驱动的优化动态。
5. 点评
尽管这篇论文为理解 RLVR 的工作机制提供了深刻的洞见,但我们仍需从批判性的角度审视其理论和结论。
5.1 “主权重”作为“高曲率”代理的局限性
论文的一个核心假设是使用“主权重”作为高维权重景观中“高曲率方向”的代理。这个代理是基于经验观察(扰动主权重导致性能急剧下降)和直觉,但其理论上的严谨性仍有待商榷。
-
代理的普适性:主权重是否在所有模型架构、所有任务中都能可靠地代表高曲率方向?权重景观的几何结构可能比单一的 SVD 分解所能捕捉的更为复杂。 -
曲率与重要性的混淆:性能敏感度高(重要性)是否等同于几何上的高曲率?二者可能相关,但未必是等价概念。需要更直接的、计算上可行的曲率度量方法(如 Hessian 的特征值分析,尽管在 LLM 规模下不现实)来进一步验证这一联系。
5.2 理论的描述性与预测性
“三门理论”目前更多是一个解释性的、描述性的框架。它很好地“事后”解释了已观察到的现象。但一个更强大的理论应该具备预测能力。该理论指出 RLVR 会规避主权重,但能否在训练开始前,就根据预训练模型的几何结构,更精确地预测出哪些参数子集(例如具体的行、列或注意力头)最有可能被更新?这对于设计真正“几何感知”的、非固定的 PEFT 模块至关重要。
5.3 对 PEFT 方法的讨论是否过于绝对?
论文有力地论证了 SFT 时代的主权重对齐型 PEFT(如 PiSSA)不适用于 RLVR。但这是否意味着所有源于 SFT 时代的 PEFT 思想都应被抛弃?像 DoRA 这样将 LoRA 更新分解为幅值和方向分量的技术,或者其他旨在提升 LoRA 表达能力的变体,它们如何与 RLVR 的几何动态相互作用?情况可能比“对齐主权重”或“不对齐”的二元划分更为复杂。
往期文章:


