RLVR 的核心挑战还在于数据选择。现有的数据选择方法,大多依赖于启发式规则,例如根据问题的难度、模型输出的不确定性或通过率等指标来筛选训练数据。这类方法虽然在特定场景下取得了一定的效果,但普遍存在以下问题:
-
缺乏理论保障:启发式方法通常源于经验和直觉,其有效性难以从理论上得到证明,导致其泛化能力和稳定性不足。在不同的模型、任务或数据集上,这些方法的表现可能会有较大波动。 -
计算成本高昂:许多启发式指标的计算依赖于模型对每个数据点进行多次前向推理(即“rollouts”),以收集统计信息(如通过率)。对于参数规模动辄数十亿甚至上百亿的 LLM 而言,为整个训练集执行这一过程的计算开销是巨大的。 -
静态与动态的矛盾:一些方法在训练开始前,基于初始模型进行一次性的全局数据筛选。这种静态策略无法适应模型在训练过程中能力的变化。而另一些方法在每个批次(batch)内进行动态筛选,虽然能捕捉模型动态,但缺乏长远规划,容易导致训练过程不稳定。
来自清华大学和 Z.AI 的论文《Data-Efficient RLVR via Off-Policy Influence Guidance》为此提供了一个新的解决方案。他们提出的 CROPI (Curriculum RL with Off-Policy Influence guidance) 框架,首次将经典的统计学工具——影响函数(Influence Functions)——引入到 RLVR 的数据选择中,从根本上改变了评估数据价值的方式。它不再依赖于表层的启发式指标,而是深入到底层的梯度信息,通过理论坚实的方法来估计每个数据点对模型学习目标的贡献,从而实现高效的课程学习。

-
论文标题:Data-Efficient RLVR via Off-Policy Influence Guidance -
论文链接:https://arxiv.org/pdf/2510.26491
1. RLVR 与影响函数
在深入了解 CROPI 的机制之前,我们首先需要回顾两个核心的基础概念:作为训练范式的 RLVR 和作为数据归因工具的影响函数。
1.1 可验证奖励的强化学习 (RLVR)
在 RLVR 的框架下,LLM 的推理过程被建模为一个马尔可夫决策过程(Markov Decision Process, MDP)。
-
状态 (State, ): 状态 是在时间步 已经生成的 token 序列。 -
动作 (Action, ): 动作 是在当前序列 之后生成下一个 token。 -
奖励 (Reward, ): 奖励函数是基于最终结果的。只有在生成完整的解答序列 后,才会根据其正确性给予一个确定性的奖励,例如正确为 1,错误为 0。在中间的生成步骤,奖励均为 0。 -
策略 (Policy, ): 模型的策略 是一个基于模型参数 的函数,它在给定当前状态 的情况下,输出下一个 token 的概率分布。
RLVR 的目标是优化策略 ,以最大化在一系列任务(prompts)上所能获得的累积奖励的期望值。近年来,随着 DeepSeek-R1 等模型的开源,其使用的 RL 算法 GRPO 已成为 RLVR 的主流方法。GRPO 通过对一批次内的 returns 进行分组归一化来估计优势函数(advantage),从而省去了 PPO 中需要的额外 critic 模型,简化了训练流程。其优化目标(忽略 KL 散度和裁剪项)可以表示为:
其中:
-
是初始的 prompt。 -
是从旧策略 采样得到的一条完整轨迹(即生成过程)。 -
是重要性采样权重,表示新旧策略在同一步骤上采取相同动作的概率比。 -
是分组归一化的优势函数,其中 是轨迹 的总回报(即最终答案是否正确), 和 分别是当前批次内所有轨迹回报的经验均值和标准差。
这个目标函数的核心思想是:如果一条轨迹获得了高于平均水平的回报(),就增大这条轨迹上所有动作的概率;反之则减小。
1.2 影响函数 (Influence Functions)
影响函数是统计学中用于进行数据归因的经典工具,由 Hampel 在 1974 年提出,并由 Koh 和 Liang 在 2017 年引入机器学习领域。它的核心作用是:在不需要重新训练模型的情况下,估计单个训练数据点对于模型预测或学习目标的影响。
从直观上理解,影响函数回答了这样一个问题:“如果我们从训练集中移除(或稍微加权)某个数据点,模型的参数会如何变化?这种变化又将如何影响模型在某个特定测试点上的表现?”
在实践中,我们可以使用一阶近似来估计一个训练数据点 对模型在测试数据点 上的性能影响。这种影响可以通过它们各自对模型参数的策略梯度 (policy gradients) 的内积来衡量:
其中, 是模型在处理训练数据 时产生的策略梯度。这个梯度的方向指示了为了在 上获得更高奖励,模型参数 应该更新的方向。
如果训练数据 的梯度与测试数据 的梯度方向一致(内积为正且较大),这意味着在 上进行训练,有助于模型在 上表现得更好。反之,如果方向相反(内积为负),则在 上的训练可能会损害在 上的性能。
尽管影响函数在监督学习(如预训练和指令微调)的数据选择中已被证明非常有效,但将其直接应用于 LLM 的 RLVR 场景,却面临着两个严峻的实践挑战。
2. 在 LLM 的 RL 场景中估算影响函数的两大挑战
将上述影响函数的理论公式应用到实践中,我们需要为数据集中的每一个训练点和验证点计算其策略梯度。然而,在 LLM 的 RLVR setting 下,这一过程困难重重。
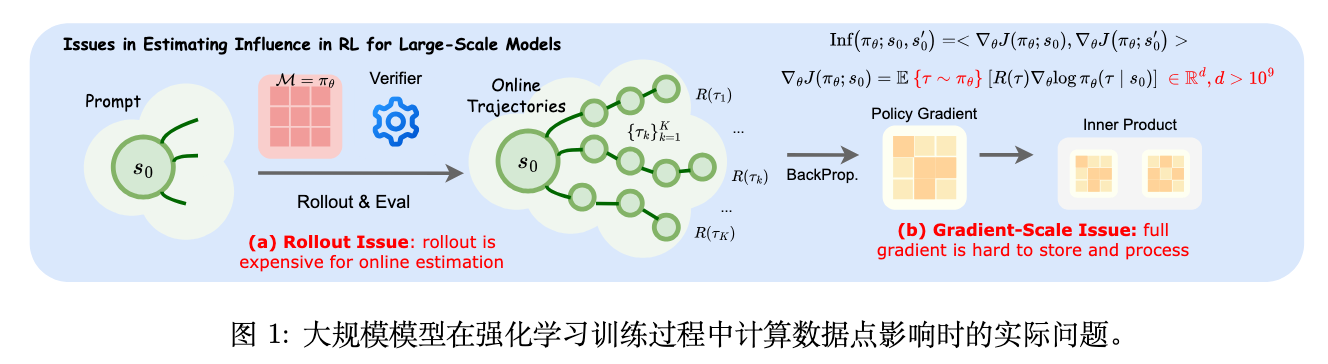
如上图所示,论文将这些困难归结为两大核心问题:Rollout 问题和梯度规模问题。
2.1 Rollout 问题
策略梯度 的计算,依赖于一个期望值 ,这个期望需要通过从当前策略 中采样多条轨迹(rollouts)来近似。与监督学习不同,RL 的训练过程是动态的,策略 在不断演进。这意味着,为了准确评估每个数据点在当前检查点 (checkpoint) 的影响,我们必须使用当前的模型版本去生成全新的 rollouts。
对于 LLM 而言,这个过程的计算成本是极其高昂的。假设我们有一个包含 5 万个训练样本的数据集,每个样本需要采样 8 条轨迹来估算梯度。仅仅为了进行一轮数据选择,就需要执行 40 万次的模型前向推理。
2.2 梯度规模问题
LLM 的参数量通常在数十亿以上,这导致其梯度向量 的维度同样巨大。例如,一个 7B 参数的模型,其全参数梯度如果以 bfloat16 格式存储,将占用约 14 GB 的空间。
为数据集中的每个样本都存储这样一个庞大的梯度向量,对存储资源提出了巨大的挑战。更重要的是,后续计算这些高维向量之间的内积(或余弦相似度)本身也是一个计算密集型任务。如果我们需要计算 N 个训练样本和 M 个验证样本之间的两两影响力,就需要进行 N x M 次高维向量内积运算,这在计算上是难以承受的。
3. CROPI
为了解决上述两大挑战,论文提出了一个由三部分组成的核心解决方案,最终构成了 CROPI 框架。
3.1 离策略梯度估算
为了解决 Rollout 问题,CROPI 的第一个创新是采用了一种离策略(Off-Policy) 的方法来估算梯度,从而避免了在线 rollouts。
其核心思想是:我们不再使用当前不断变化的策略 去生成轨迹,而是利用一组预先收集好的、由一个固定的行为策略 (behavior policy) 生成的离线轨迹 (offline trajectories) 。在实践中,这个行为策略 可以简单地设置为训练开始前的初始策略 。
通过引入重要性采样(Importance Sampling),我们可以在使用 生成的轨迹的经验期望上,来估算在策略 下的梯度。论文采用了 TRPO 和 PPO 中使用的 token 级别的重要性采样,推导出了如下的离策略梯度估算器:
其中, 是从行为策略 采样得到的离线轨迹。 是重要性权重,而 是基于行为策略 的轨迹回报计算出的优势函数。
这一近似的合理性在于,RLVR 训练中通常会包含一个 KL 散度约束项,来防止训练中的策略 与初始策略 (即这里的 ) 偏离过远。这种约束保证了重要性采样的方差不会过大,使得离策略估算相对准确。
通过这种方式,CROPI 只需要在训练开始前,为数据集中的每个 prompt 生成一次离线轨迹。在之后的所有数据选择阶段,都可以重复利用这批离线数据来估算梯度,避免了在线 rollout。
3.2 稀疏随机投影
为了解决梯度规模问题,CROPI 的第二个创新是使用稀疏随机投影来对高维梯度进行降维。
随机投影是一种经典的降维技术,其理论基础是 Johnson-Lindenstrauss 引理,该引理保证了在随机投影到一个低维空间后,向量间的距离(或内积)可以在很大概率上被保留。
标准随机投影会使用一个稠密的随机矩阵 (其中 ) 将高维梯度 映射到低维空间 。然而,论文发现了一个反直觉但效果更好的方法:稀疏随机投影。
具体步骤如下:
-
随机选择维度: 首先,从原始的 维梯度中,随机选择一个子集 的维度,选择比例称为稀疏率(sparse ratio)。 -
构建稀疏投影矩阵: 构建一个投影矩阵 ,该矩阵只有对应于子集 中的列是非零的随机向量,其余列全为零。 -
投影: 将梯度投影到低维空间。这个过程等价于先将梯度向量中不在 中的维度置零,然后再进行一次较小规模的随机投影。
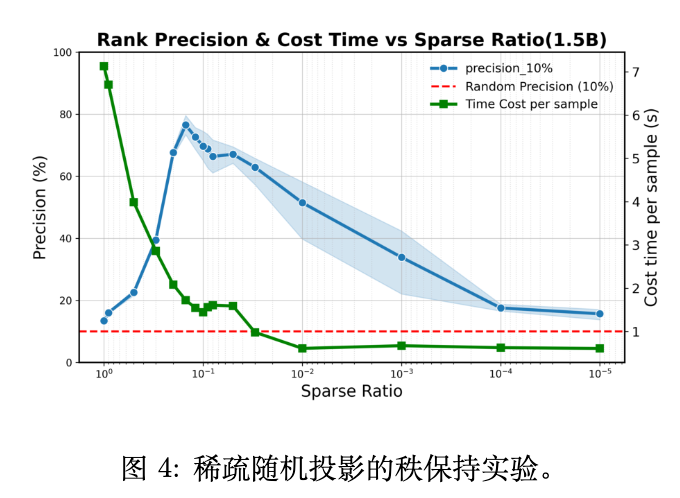
实验结果(如图 4)令人意外:直接对完整梯度进行随机投影时(稀疏率为 1.0),其内积排序的保留能力(precision@10%)仅有 13% 左右,和随机猜测差不多。然而,当稀疏率设置为 0.1 左右时,排序的保留能力飙升至接近 80%。
论文推测,这种现象可能与高维梯度中存在的数值噪声有关。完整的梯度包含了大量对排序无益甚至有害的噪声信息,直接投影会放大这些噪声。而稀疏化处理(即随机丢弃大部分维度)在损失部分信息的同时,也过滤掉了大量的噪声,从而使得投影后的信噪比更高,关键的排序信息反而被更好地保留了下来。
3.3 POPI 与 CROPI 课程学习框架
结合了离策略梯度估算和稀疏随机投影,并引入了梯度归一化(通过计算余弦相似度来消除梯度范数大小带来的偏见)后,论文提出了POPI (Practical Off-Policy Influence) 作为其实际的影响力估算器:
其中 是经过稀疏随机投影后的离策略梯度。
有了 POPI 这个高效的工具,就可以构建CROPI (Curriculum RL with Off-Policy Influence guidance) 课程学习框架。CROPI 是一个多阶段、迭代式的训练流程。
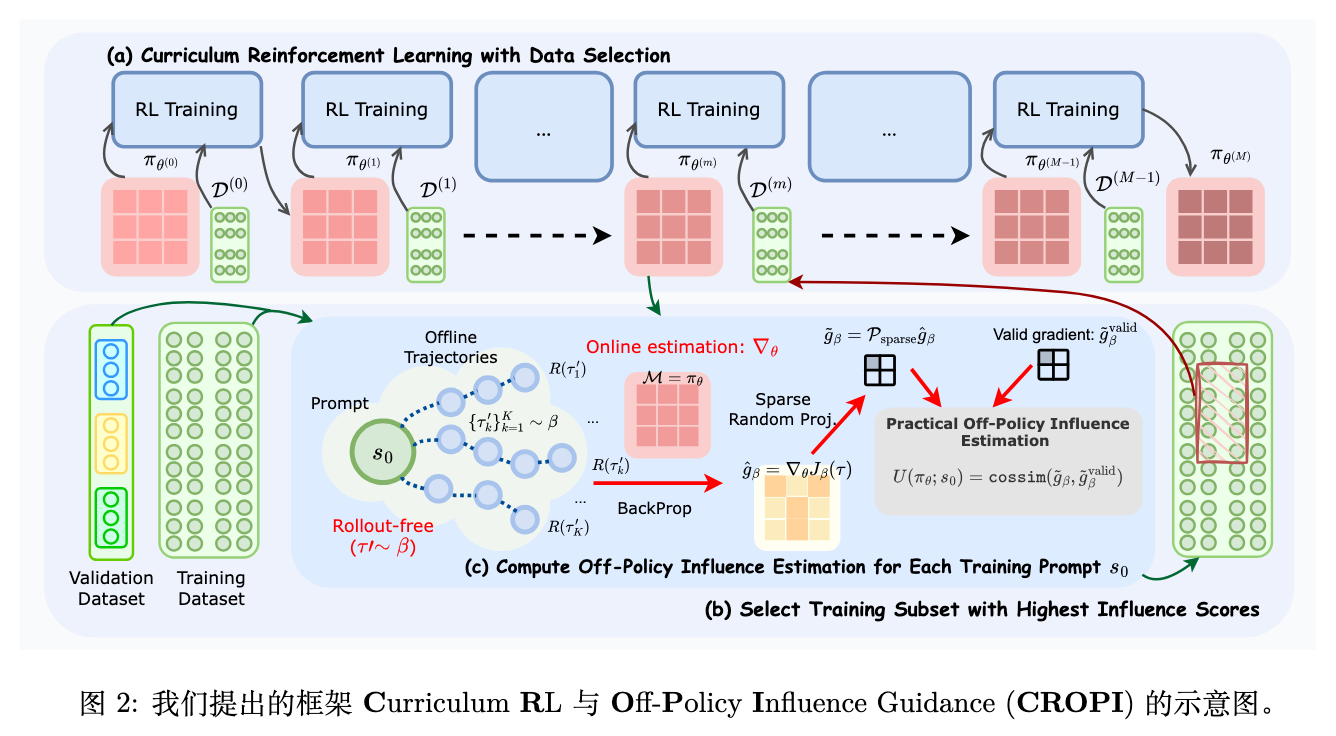
其核心算法流程如下:
-
初始化: 在训练开始前,使用初始模型 为训练集中的每个 prompt 生成并存储一组离线轨迹。 -
进入训练阶段 : -
(a) 影响力计算: 加载当前的模型检查点 。对于训练集中的每一个 prompt ,使用 POPI 计算它相对于一个或多个验证集 的影响力得分。对验证集的影响力通过计算 的梯度与验证集所有样本的平均梯度的余弦相似度得到。如果使用多个验证集,则通过倒数排序融合(Reciprocal Rank Fusion)来合并分数,增强鲁棒性。 -
(b) 数据选择: 根据影响力得分,从整个训练集中选择得分最高的 (例如 10%)的数据,构成当前阶段的训练子集 。 -
(c) 策略优化: 在筛选出的数据子集 上,使用 GRPO 算法对模型进行 E 步的训练,得到新的模型检查点 。
-
-
迭代: 重复步骤 2,直到训练结束。
通过这种迭代的方式,CROPI 实现了一种动态的课程学习。在训练的每个阶段,它都会根据模型当前的能力水平,重新评估所有数据的价值,并选择那些对当前模型最有帮助的数据进行训练。这种“因材施教”的方式,使得学习过程更加高效。
4. 实验
论文通过在多个数学推理任务和不同规模的模型上进行实验,验证了 CROPI 框架的有效性。
4.1 实验设置
-
模型: Qwen2.5-1.5B, Qwen2.5-7B, Deepseek-R1-Distill-Qwen-1.5B。 -
数据集: 训练集由 GSM8K-Train, MATH-Train, DeepScaleR-Preview-Dataset 聚合而成。测试集包括 GSM8K-Test, MATH-Test, Gaokao2023EN 等多个标准 benchmark。 -
评估方式: 为了评估泛化能力,测试任务被分为“目标任务 (Targeted)”(其领域包含在数据选择所用的验证集中)和“非目标任务 (Untargeted)”(领域与验证集无关)。 -
基线方法: 全量数据训练 (Full Dataset)、基于通过率 (Pass Rate)、基于可学习性 (Learnability) 的全局筛选方法,以及批次级别的筛选方法 DAPO。
4.2 主要结果
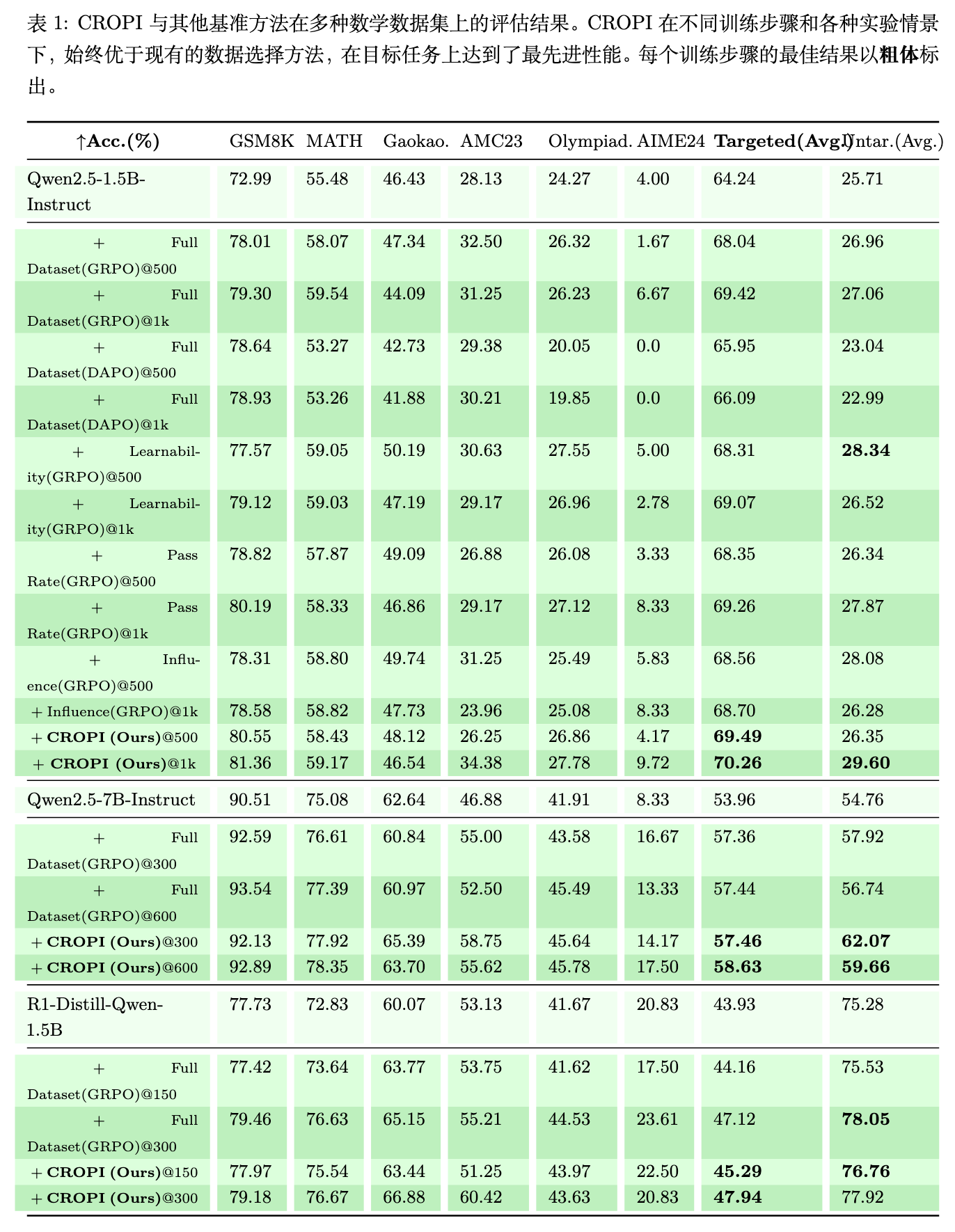
如表 1 所示,实验结果可以看出:
-
效率提升: CROPI 在所有模型规模和目标任务上,都一致地优于全量数据训练和其他基线方法。 -
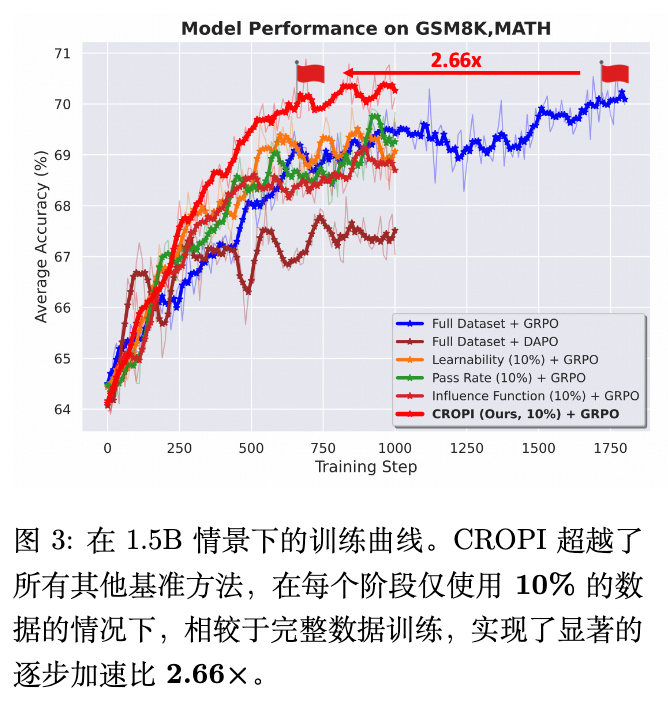
加速效果: 在 1.5B 模型上,CROPI 相比于全量数据训练,在达到相同的性能水平时,实现了 2.66 倍的步数级别加速,而每个阶段仅使用了 10% 的数据。这证明了其在样本效率和计算效率上的巨大优势。
-
泛化能力: CROPI 不仅在目标任务上表现出色,在非目标任务上的性能也有显著提升。这说明 CROPI 筛选出的数据并非仅仅为了“过拟合”验证集,而是真正有助于提升模型的通用推理能力。 -
动态选择的优势: 相比于一次性的全局筛选方法(如 Pass Rate、Learnability),CROPI 的性能能够持续提升,而基线方法很快就进入了平台期。这证明了动态适应模型变化的课程学习策略的优越性。
4.3 分析
论文进一步深入分析了 CROPI 成功的关键原因。
-
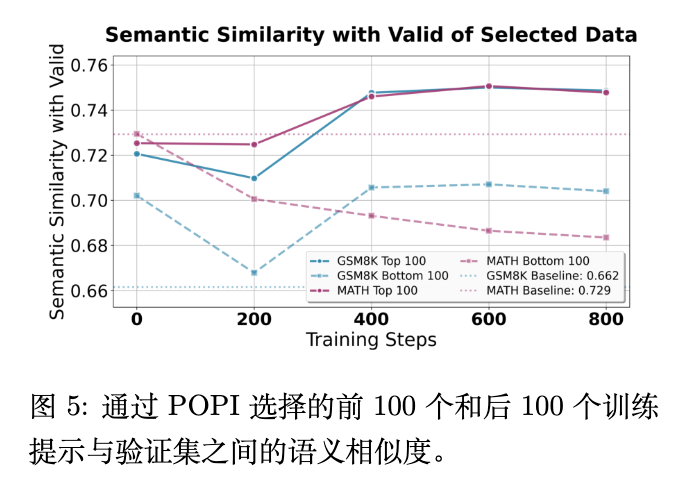
被选数据的语义相关性 (图 5): 分析发现,被 POPI 选中的 top-100 样本,在语义上与验证集的相似度显著高于随机样本和被淘汰的 bottom-100 样本。这说明基于梯度的影响力与语义上的相关性存在内在联系,POPI 能够自动发现与目标任务最相关的训练样本。
-
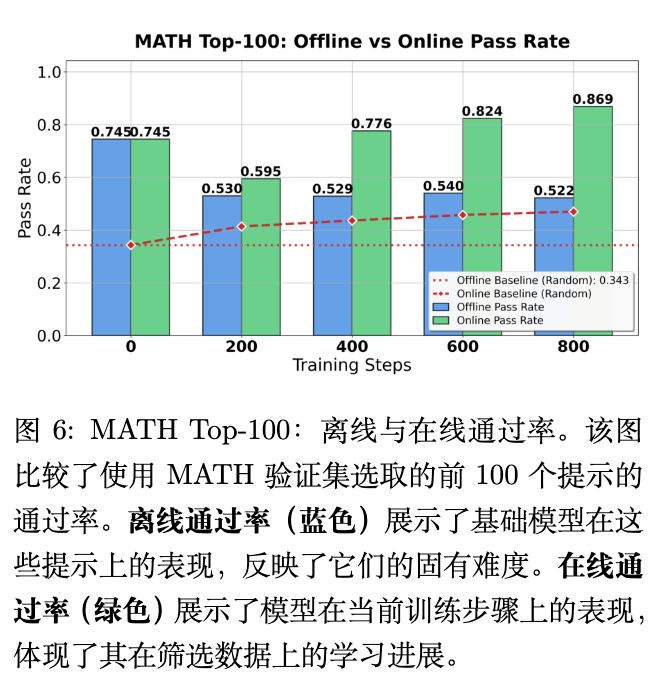
被选数据的难度动态变化 (图 6): 论文对比了被选中的 top-100 样本在初始模型(Offline) 和当前模型(Online) 上的通过率。
-
离线通过率 (Offline Pass Rate):随着训练的进行,被选中问题的离线通过率(即它们对于初始模型的难度)呈现下降趋势。这意味着 CROPI 在不断挑选对初始模型来说更难的问题。 -
在线通过率 (Online Pass Rate):与此形成鲜明对比的是,这些被选问题在当前模型上的通过率却呈现强劲的上升趋势。
-
这两个趋势结合在一起,揭示了 CROPI 工作的核心机制:它总是在动态地为模型选择那些处于其当前“学习前沿” (learning frontier) 的问题。这些问题对于过去的模型来说可能太难,但对于当前的模型来说,恰好是“跳一跳能够得着”的、最具学习价值的挑战。模型通过解决这些问题,能力得到最大化的提升,从而实现了高效的学习。
往期文章:


