我们该如何准确、可靠地评估大模型的能力?
如果说模型是“工匠”,那么评估体系就是“度量衡”。一个没有精准度量衡的领域,是无法实现系统性、科学化进步的。目前,对 LLM 的评估,尤其是针对那些有可验证答案的客观问题(如数学计算、知识问答、逻辑推理)的评估,正面临着一场“度量衡”危机。
传统的评估方法主要有两种,但都存在明显的短板:
-
基于规则的字符串匹配:例如,使用正则表达式提取答案中的特定字段进行比对。这种方法虽然简单直接,但极其“脆弱”。只要模型输出的格式稍有变化,或者答案的表达方式不同(例如 sqrt(8)vs2*sqrt(2)),匹配就可能失败。为每个任务定制规则又费时费力,无法规模化。 -
通用大模型即裁判(LLM-as-a-Judge):利用像 GPT-4 这样的顶级模型来判断另一个模型的答案是否正确。这种方法灵活性更高,但引入了新的问题:成本高昂、速度缓慢,且“裁判”本身也可能产生幻觉或带有偏见,导致误判。此外,精巧的提示词工程(Prompt Engineering)也成为了一项繁重的负担。
正是由于这些限制,当前的研究领域迫切需要一个既准确又高效,既能处理复杂情况又能跨领域通用的答案验证器。它不仅是评估模型性能的“精准刻度尺”,更是通过强化学习(Reinforcement Learning, RL)来优化模型、提供奖励信号的“导航灯塔”。
在这样的背景下,来自上海人工智能实验室和澳门大学的研究团队在 2025 年 8 月发表了一篇名为 《CompassVerifier: A Unified and Robust Verifier for LLMs Evaluation and Outcome Reward》 的论文。这项工作直面挑战,提出了一个完整的解决方案,包含两大核心贡献:
-
VerifierBench:一个精心设计、极具挑战性的新型答案验证基准。 -
CompassVerifier:一个准确、鲁棒且轻量级的验证器模型系列。
本文将对这篇论文进行一次全面而深入的“庖丁解牛”,详细剖析其背后的动机、方法论、实验设计和深远意义。我们将一起探索,作者们是如何一步步构建起这个强大的“裁判”与“奖励”系统,从而为大模型的发展提供更坚实的基石。
第一章:为何我们需要更好的验证器?—— 现有方法的困境
在深入了解 CompassVerifier 之前,我们有必要更详细地审视当前答案验证方法所面临的具体困境。这有助于我们理解,为什么这项研究工作是必要的,以及它试图解决的核心痛点是什么。
方法一的窘境:脆弱的“正则表达式”
基于规则的字符串匹配,是最早也是最直观的验证方法。其核心思想是“提取与比对”。
工作原理:
研究人员在设计评测任务时,会要求模型以固定的格式输出最终答案,比如:
“The final answer is: [答案]”
然后,评测脚本会编写一个正则表达式(Regex),从模型的完整输出中精确地抓取 “[答案]” 部分,再与标准答案进行字符串级别的比较。对于数学问题,一些更高级的工具如 math-verify 库被开发出来,它可以处理一些基础的数学表达式等价性问题,例如判断 x/2 和 0.5x 是否相等。
优点:
-
简单快速:一旦规则写好,验证过程计算开销极小,速度飞快。 -
确定性高:只要格式匹配,结果就是确定的,没有随机性。
缺点(致命的):
-
极端脆弱性(Brittleness):这是其最大的问题。LLM 的输出本质上是生成性的,而非结构化的。任何微小的格式偏差,如多一个空格、少一个换行、或者用了不同的引导词,都可能导致正则表达式提取失败,从而将一个正确的答案误判为错误。 -
语义等价性难题:字符串匹配无法理解语义。在数学领域,一个答案可以有无数种等价的表达形式。例如,对于一个要求解 √8的问题,√8、2√2、2.828(在一定精度下)都应被视为正确答案。简单的字符串比对无法处理这种情况,而math-verify这样的工具虽然有所改进,但对于更复杂的公式、不同单位的物理量、或带有文字描述的答案仍然力不从心。 -
高昂的定制成本:每一种新的任务、新的数据集、甚至新的模型输出风格,都可能需要重新编写一套新的匹配规则。这种“打补丁”式的工作流,使得评测框架难以维护和扩展,无法形成统一、通用的标准。 -
无法处理复杂答案类型:对于需要输出一个序列(如按字母排序的单词列表)、多个子问题答案、或布尔值(True/False)的复杂任务,设计一个万无一失的提取规则变得异常困难。
方法二的权衡:昂贵且有偏见的“模型裁判”
为了克服规则方法的脆弱性,研究社区转向了一个更“智能”的方案:让一个强大的 LLM(通常是像 GPT-4 这样的闭源顶级模型)来扮演“裁判”的角色。
工作原理:
评测系统会将“问题”、“标准答案”和“待评测模型的答案”三者一起打包,并通过一个精心设计的提示词(Prompt)发送给“裁判模型”,让它判断待评测模型的答案是否正确,并给出“Correct”、“Incorrect”之类的标签。
优点:
-
灵活性高:模型裁判具备一定的自然语言理解和推理能力,能够更好地处理格式变化和语义等价问题。理论上,它可以理解 2√2和√8是同一个意思。 -
通用性强:同一个裁判模型和提示词模板,可以应用于多种不同类型的任务,减少了为每个任务定制规则的麻烦。
缺点(同样显著):
-
成本与延迟:调用顶级 LLM 的 API 是昂贵的,尤其是在需要评测数万甚至数百万个样本时,成本会急剧上升。同时,API 调用和模型生成需要时间,这大大降低了评测效率,使得快速迭代和大规模实验变得不切实际。 -
裁判自身的不可靠性:这是最核心的风险。“裁判”也是一个 LLM,它同样会犯错。它可能会产生幻觉,错误地理解问题或答案;它可能存在位置偏见(Position Bias),即倾向于认为第一个或第二个答案更好;它也可能过于“严格”或“宽松”,其评判标准可能与人类的直觉不符。这就好比用一把不确定是否精准的尺子去测量另一把尺子。 -
提示词的敏感性(Prompt Sensitivity):裁判模型的表现高度依赖于提示词的设计。一个微小的措辞变化,都可能导致评判结果的巨大差异。设计一个在所有任务和领域都表现稳定的“通用裁判提示词”本身就是一个巨大的挑战,这篇论文的研究也证实了这一点。 -
缺乏可解释性:虽然可以要求裁判模型给出判断理由,但这些理由本身也可能是模型“编造”的,不一定能反映其真实的“思考”过程,使得调试和信任评估结果变得困难。
核心痛点总结
通过上述分析,我们可以清晰地看到当前 LLM 客观能力评估所面临的两大根本性限制,这也正是 CompassVerifier 论文摘要中开宗明义指出的:
-
缺乏全面的基准(Comprehensive Benchmarks):现有基准要么过于简单,无法区分顶尖模型之间的细微差异;要么评测方法本身存在缺陷,导致评估结果不可靠。我们没有一个公认的、能够系统性地、细粒度地衡量“验证能力”本身的试金石。 -
验证器本身发展不成熟(Nascent Stage of Verifier Development):现有的验证器,无论是基于规则还是基于通用 LLM,都缺乏处理复杂边缘情况的鲁棒性(Robustness)和跨不同领域和任务的泛化能力(Generalizability)。
CompassVerifier 的工作,正是为了填补这两大空白,旨在打造一个既能精准度量、又能有效引导 LLM 发展的全新评测与奖励生态。
第二章:奠定基石 —— 挑战性基准 VerifierBench 的构建
在创造一个优秀的验证器(Verifier)之前,必须先有一个优秀的基准(Benchmark)。这个基准就像一把标尺,不仅能量出现有验证器的优劣,还能揭示它们的短板,从而指导未来验证器的发展方向。VerifierBench 正是为此而生。
作者们构建 VerifierBench 的目标是创建一个“照妖镜”,专门收集那些现有方法(无论是规则匹配还是通用 LLM 裁判)容易出错的、模棱两可的、或具有挑战性的样本。
构建流程第一步:大规模、多样化的数据收集
为了确保基准的全面性,作者们利用了 OpenCompass 这一通用评测框架,从一个极其广泛的数据源中收集原始样本。
-
海量数据:收集了超过 132万 个模型响应样本。 -
广泛的模型覆盖:涵盖了 53个 不同的 LLM,包括商业闭源模型(如 GPT 系列、Claude 系列)、强大的开源模型(如 Llama 系列、Qwen 系列)以及新兴的推理模型(LRMs, Large Reasoning Models)。 -
丰富的任务来源:数据来源于 16个 精心挑选的数据集,覆盖四大关键领域:数学、科学、知识和通用推理。具体的数据集如 GSM8K、MMLU-Pro、GPQA等,这些都是业界公认的高质量评测集。
这种大规模的数据收集带来了前所未有的多样性,这也是 VerifierBench 价值的核心所在:
-
答案类型多样性(Answer Type Diversity):覆盖了从简单的单项选择题、数值计算,到复杂的数学公式、多子问题组合、长序列应答等几乎所有客观题的答案形式。 -
提示词多样性(Prompt Variability):输入模型的提示词涵盖了零样本(zero-shot)、少样本(few-shot)以及针对特定数据集的特殊格式要求。 -
响应特征多样性(Response Characteristics):模型的输出形态各异,不仅有直接给答案的,也有包含详细思考过程(Chain-of-Thought, CoT)的,甚至还包括了各种异常输出(如重复、截断、拒绝回答等)。
最终,收集到的原始数据是三元组的形式:D = {(问题, 参考答案, 模型响应)}。VerifierBench 的目标就是为这个三元组打上一个可靠的验证标签 v(Correct, Incorrect, Invalid),形成一个可供训练和测试的四元组 (q, a_ref, r_m, v)。
构建流程第二步:精密的“多阶段验证”流水线
如何为这 130 多万个样本打上准确的标签?如果全部依赖人工,成本将是天文数字。为此,作者们设计了一套高效、精密的“多阶段验证”流水线,像筛金子一样,层层筛选,最终得到高价值的样本。
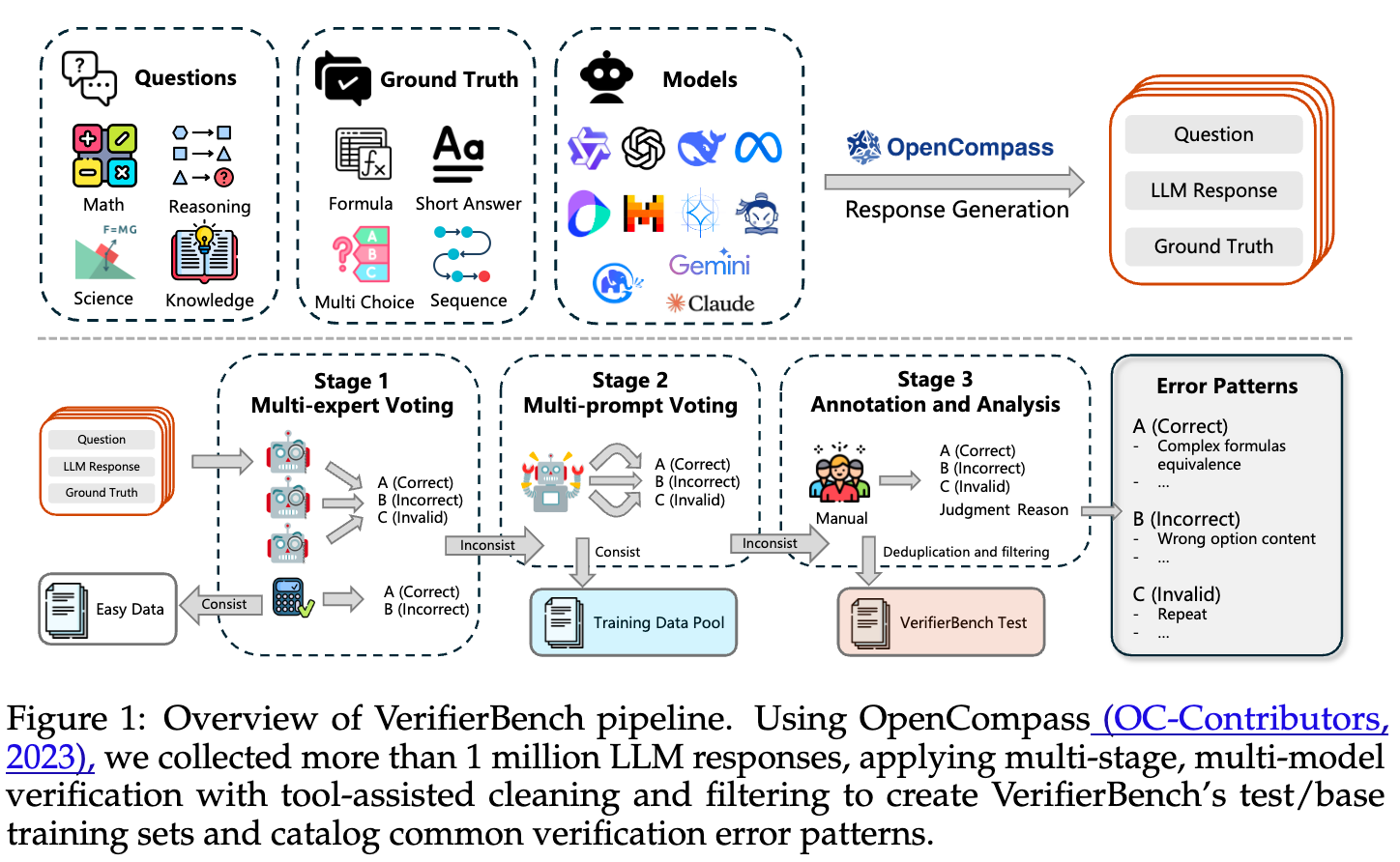
上图展示了整个流水线的核心思想,我们可以将其分解为三个主要阶段:
阶段一:多专家投票 (Multi-Expert Voting)
-
目的:快速、低成本地过滤掉“简单样本”。 -
方法:首先,让一些相对较弱但高效的模型(如 Qwen2.5-Instruct 系列的 7B, 14B, 32B 模型)对样本进行直接判断(不进行 CoT 推理)。对于数学领域的样本,还会额外引入 math-verify工具作为另一个“专家”。 -
筛选逻辑:如果所有这些“专家”对一个样本的判断完全一致(例如,都认为是“正确”的),那么这个样本就被认为是“简单的”、“无争议的”。这样的样本对于训练一个强大的验证器价值不大,因此被直接移除。这个阶段大大减少了后续阶段需要处理的数据量。
阶段二:多提示词投票 (Multi-prompt Voting)
-
目的:处理“中等难度”的样本,并为训练集提供高质量的自动标注数据。 -
方法:第一阶段中“专家们”意见不一的“争议样本”会进入此阶段。此时,一个更强大的模型 DeepSeek-V3会被启用。关键在于,研究者会使用 多个不同风格的提示词 来引导DeepSeek-V3生成带有 CoT 推理过程的判断。 -
筛选逻辑:如果 DeepSeek-V3在多种不同提示词下,对某个样本的判断结果仍然保持一致,那么这个样本就被认为是“中等难度”的,并且其一致的判断结果被采纳为“黄金标签”(golden label)。这些样本构成了CompassVerifier的 基础训练池。 -
重要发现:作者在此处强调,他们发现开发一个适用于所有数据集和任务的“通用验证提示词”是极其困难的。这再次印证了依赖单一提示词的“LLM-as-a-Judge”方法的局限性。
阶段三:人工标注与分析 (Human Annotation and Analysis)
-
目的:处理最困难、最有价值的样本,构建最终的“黄金测试集”。 -
方法:经过前两轮筛选后,仍然存在争议的样本(即便是强大的 DeepSeek-V3在不同提示词下也给出了不一致的判断),会被提交给人类领域专家进行最终裁决。 -
筛选逻辑:人类专家不仅会给出“Correct/Incorrect”的标签,还会对那些有问题的样本(如题目本身有歧义、参考答案错误)进行标记和排除,确保 VerifierBench测试集的纯净和公平。最终,经过严格筛选和平衡,得到了包含 2,817个 样本的高质量测试集。
“无效样本”的创见:重新定义评测的维度
这是 VerifierBench 构建过程中一个非常重要的创新点。在传统评测中,一个模型的输出通常只被分为“正确”或“不正确”。但作者们发现,存在大量的模型输出,它们既不正确,也不“正常”,无法归入这两类。
他们将这类样本定义为 “无效(Invalid)”。典型的“无效”样本包括:
-
输出被截断:回答到一半就戛然而止。 -
无意义的重复:在输出中不断重复某些词语或句子。 -
拒绝回答:模型明确表示因安全限制、信息不足等原因无法回答问题。 -
严重乱码:输出的是无法解析的文本。
将这些“无效”样本单独作为一个类别(Category C)具有深远的意义:
-
更真实的模型能力评估:它使得评估更加多维度和精细化。一个模型可能在正确率上表现不错,但如果它频繁产生“无效”输出,说明其鲁棒性很差。 -
防止强化学习中的“奖励黑客”:在 RL 训练中,如果一个模型因为不知道答案而随便输出一个错误答案,它会得到一个负向的奖励。但如果它学会了通过输出“我无法回答”来规避问题,而系统又没有对这种情况进行惩罚,模型就可能学会这种“投机取巧”的行为(即“奖励黑客”,Reward Hacking)。明确地识别和处理“无效”回答,可以堵上这个漏洞。
通过这套精密的流程,VerifierBench 不再是一个简单的评测集,而是一个经过精心设计的、旨在暴露现有验证方法弱点的“压力测试场”。它的构建为 CompassVerifier 的训练和评估提供了坚实的数据基础。
第三章:核心利器 —— CompassVerifier 模型与三大增强技术
在 VerifierBench 这块坚实的基石之上,作者们开始着手锻造他们的核心利器——CompassVerifier。它的目标是成为一个轻量级、高性能、鲁棒且通用的答案验证模型。
CompassVerifier 的训练监督信号,来源于 VerifierBench 构建流程中产生的带有“黄金标签”的数据。但仅仅使用这些数据进行标准微调是远远不够的。为了让模型真正学会处理复杂和模糊的边缘情况,作者们独创性地提出了三项关键的数据增强技术。
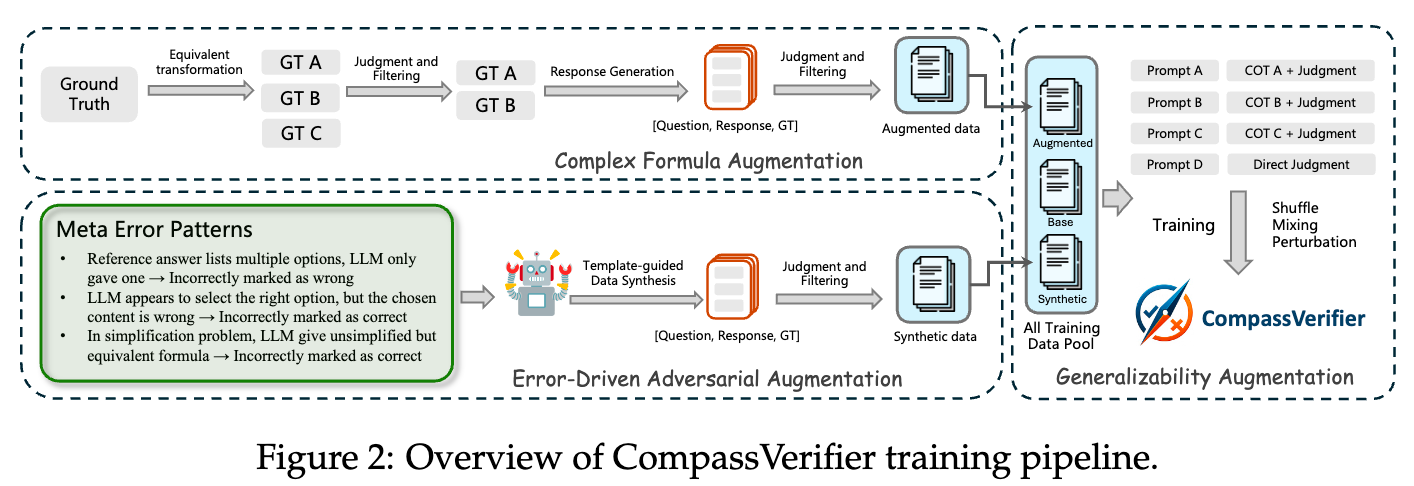
上图展示了 CompassVerifier 的整体训练流程,其中三大增强技术构成了其核心竞争力。
技术一:错误驱动的对抗性增强 (Error-Driven Adversarial Augmentation)
这项技术的核心思想是:从错误中学习,特别是从那些“人类觉得可以容忍,但机器裁判却严厉惩罚”的错误中学习。
传统的自动标注数据,即便是来自强大的 DeepSeek-V3,也可能存在偏差,比如对格式要求过于严格,而对核心概念的错误不够敏感。为了纠正这种偏差,使 CompassVerifier 的判断标准更接近人类专家,作者们设计了一个三步走的对抗性增强策略。
第一步:人机协作分析 (Human-in-the-Loop Analysis)
领域专家对大约 5000 个经过自动标注的样本进行人工复核,并详细记录下他们发现的“误判”案例及其背后的原因。这些原因被归纳为“失败理据(failure rationales)”,例如:
-
“LLM 对任务的限制理解错误。” -
“LLM 误解了问题中的关键信息。” -
“不同的裁判模型对于惩罚的尺度不一致。”
第二步:失败模式聚类 (Pattern Clustering)
收集到大量的“失败理据”后,研究者使用基于密度的聚类算法,将这些理据进行分类。最终,他们识别出了 超过 20 个 高频出现的、影响巨大的错误类别。这些类别揭示了现有验证器在“换位思考”和“格式遵循”等方面的系统性漏洞。
第三步:元裁判模板生成 (Meta-Judge Template Generation)
这是最关键的一步。针对每一个错误类别,研究者们都开发了一套结构化的“元裁判模板(Meta-Judge Template)”。这些模板用于 生成大量的、高质量的合成训练数据。每个模板都编码了两种信息:
-
问题特征(Question Characteristics):例如,某个领域特定的要求、内容或格式上的限制。 -
响应错误模式(Response Error Patterns):具体的失败类型、错误在回答中的位置、错误的严重程度等。
通过这些模板生成的数据,可以有针对性地教会 CompassVerifier 如何像人一样思考。例如,下面是一些从论文附录中提炼出的“元错误模式(Meta Error Patterns)”及其对应的正确判断,这些都通过模板生成了训练数据:
-
案例:一个简化表达式的问题,LLM 给出了一个数学上等价但没有简化到最简形式的答案。 -
传统裁判:可能因为“不够简化”而判为错误。 -
增强后的 CompassVerifier:学会了根据问题是否“明确要求最简形式”来决定是否判错,变得更加灵活。 -
案例:参考答案列出了多个可能的正确选项,而 LLM 只给出了其中一个。 -
传统裁判:可能因为“不完整”而判为错误。 -
增强后的 CompassVerifier:学会了只要回答是正确选项之一,就应该判为正确。
这项技术极大地提升了模型判断的鲁棒性,使其能够有效抵御三种常见的误判:
-
过于严格的格式化拒绝。 -
对流畅回答中概念性错误的惩罚不足。 -
对上下文敏感的评分差异。
技术二:复杂公式增强 (Complex Formula Augmentation)
在自然科学(物理、化学)和数学领域,验证答案的一大挑战是公式和表达式的 多样性。同一个物理定律或数学结果,可以用完全不同的符号和结构来表示。
问题:缺乏强大数学等价性理解能力的验证器,很容易将一个语义上正确但形式上不同的回答误判为错误。这会导致在这些领域的评测中出现大量的“假阴性(False Negatives)”。
解决方案:作者们引入了“复杂公式增强”策略,系统性地为每个问题生成多个表示不同但语义等价的答案。
该过程分为三步:
-
参考答案规范化(Reference Normalization):首先,将原始的参考答案转换成一个“标准范式”,统一数值精度和符号结构。 -
变体生成 (Variant Generation):利用强大的 DeepSeek-v3模型,为每个标准范式答案生成 1 到 3 个不同的等价变体。这些变体包括:-
符号重排:如 a/(b+c)变为(b+c)^-1 * a。 -
精度保持的浮点数扩展:如 0.5变为5e-1。 -
等价的整数或分数表示:如 1/2变为0.5。
在生成过程中,会施加严格的约束以避免精度损失,并确保每个变体在问题上下文中与原始答案数学等价。
-
-
质量控制 (Quality Control):所有生成的变体都会通过一个符号代数引擎(如 SymPy)进行自动化的等价性检查。此外,还会有一部分样本由学科专家进行人工审查,以确保其正确性和表达的自然性。
通过将这些多样化的、等价的公式变体加入训练集,CompassVerifier 被迫学习公式背后的数学本质,而不是仅仅记忆其表面形式。这显著提高了它在处理公式密集型任务时的能力,大大降低了误判率。
技术三:泛化能力增强 (Generalizability Augmentation)
一个好的验证器不应该只在它见过的特定任务或提示词模板上表现良好,它必须具备强大的泛化能力。
问题:现有的验证器模型常常依赖于任务特定的提示词,这限制了它们在不同问题和答案的细微变化下的适用性。例如,在 TheoremQA 数据集中,对数值精度的要求就非常微妙。
解决方案:“泛化能力增强”策略通过系统性地扩展训练数据中提示词和响应的多样性来解决这个问题。
该策略采用了两种关键技术:
-
提示词重写与扰动(Prompt Rewriting and Perturbation): -
方法:利用 LLM(如 DeepSeek-v3)自动生成现有提示词的 释义(paraphrases)、结构修改版和细节丰富的变体。例如,将一个直接的提问方式改为更委婉或更复杂的提问方式。 -
训练机制:在训练过程中,引入 提示词随机采样、动态混合 等机制,并设计了一个“提示词不变性”损失项,来鼓励模型在面对不同形式的提示词时,做出一致的判断,从而防止对特定提示词格式的过拟合。
-
-
长上下文泛化 (Long-context Generalization): -
背景:很多模型会生成非常长的思考过程(CoT),验证器需要能从中准确找到最终答案,而不被中间的推理步骤干扰。 -
方法:作者们对从长推理模型(LRMs)收集到的响应应用了多种扰动,包括: -
截断不同部分:例如,随机截断思考过程的前 20%、40% 或 60%。 -
替换思考标签:将 <think>、</think>这样的标签替换为其他替代标签。 -
完全移除思考标签。
-
-
目标:在进行这些扰动的同时,确保最终的判断标签保持不变。这迫使模型学会忽略推理过程的“装饰”,专注于核心答案的提取与验证。
-
通过这三大技术的“组合拳”,CompassVerifier 被锻造成了一个既能理解人类评判的微妙之处,又能处理复杂公式的多样性,还能适应不同提问和回答风格的“全能裁判”。
第四章:实验与结果分析 —— CompassVerifier 的实力展示
理论和方法论的先进性,最终需要通过严谨的实验来验证。CompassVerifier 在其“主场”——VerifierBench 测试集上,与一系列通用 LLM 和其他专门的验证器模型展开了一场全面的对决。
对手阵容
-
通用 LLMs:包括不同尺寸的 Qwen2.5 和 Qwen3 系列模型,以及两个业界顶级模型 DeepSeek-V3和GPT-4o。 -
专用验证器模型:包括两个近期的相关工作 xVerify和Tencent-Qwen2.5-7B-RLVR。 -
CompassVerifier 自身:作者们训练了 3B、7B 和 32B 三种不同参数规模的版本,以检验其可伸缩性。
主实验结果:全方位的领先
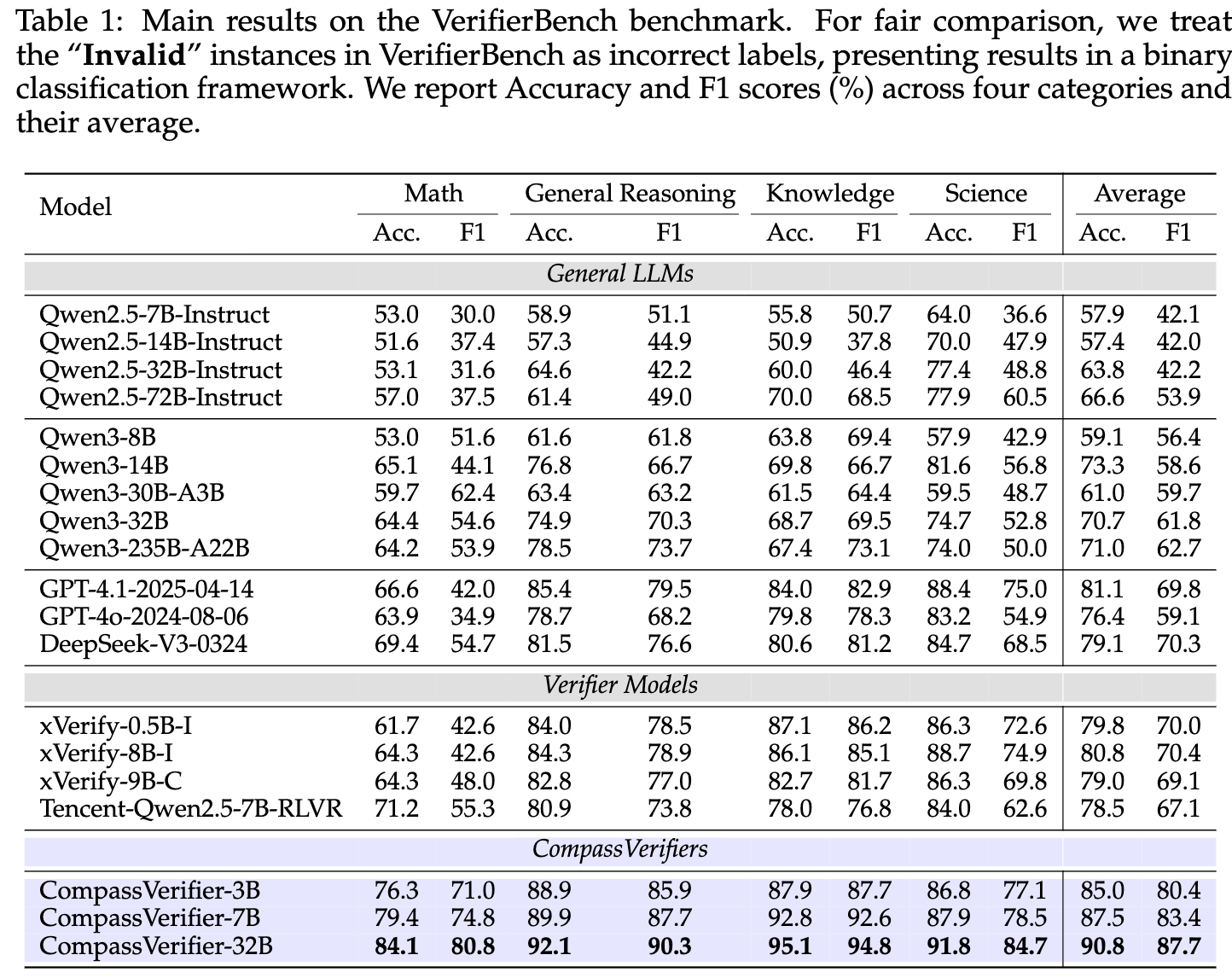
上表展示了在四个主要领域(数学、通用推理、知识、科学)以及平均分上的准确率(Accuracy)和 F1 分数。F1 分数是一个综合考虑了精确率和召回率的指标,更能反映模型的综合性能。从表中可以得出几个惊人的发现:
-
SOTA 性能:
CompassVerifier系列在所有四个领域和平均分上,都取得了当前最佳(State-of-the-Art)的性能。特别是CompassVerifier-32B,其平均准确率达到90.8%,F1 分数达到87.7%,遥遥领先于其他所有模型。 -
验证能力随规模增长:在
CompassVerifier内部,性能与模型规模呈正相关。从 3B 到 32B,F1 分数从 80.4% 提升到 87.7%,这表明其架构具有良好的可扩展性。 -
专有架构的巨大优势:
CompassVerifier-7B的 F1 分数达到了83.4%,而作为其基础模型的Qwen2.5-7B-Instruct的 F1 分数仅为42.1%。这 41.3% 的巨大差距,雄辩地证明了论文中提出的三大数据增强技术和专用训练框架的有效性。 -
轻量级模型的惊人效率:最令人印象深刻的是,
CompassVerifier-3B这个仅有 30 亿参数的小模型,其 F1 分数(80.4%)竟然显著超过了像GPT-4.1(69.8%)和DeepSeek-V3(70.3%)这样的千亿级别巨无霸模型。这展示了其极高的参数效率,意味着可以用更低的成本、更快的速度实现更准确的验证。 -
数学领域仍是挑战:尽管
CompassVerifier取得了巨大进步,但数学领域的 F1 分数(32B 模型为 80.8%)仍然是四个领域中最低的,而知识领域的 F1 分数最高(94.8%)。这表明,需要逐步逻辑验证的数学推理,仍然是验证任务中最困难的一环。
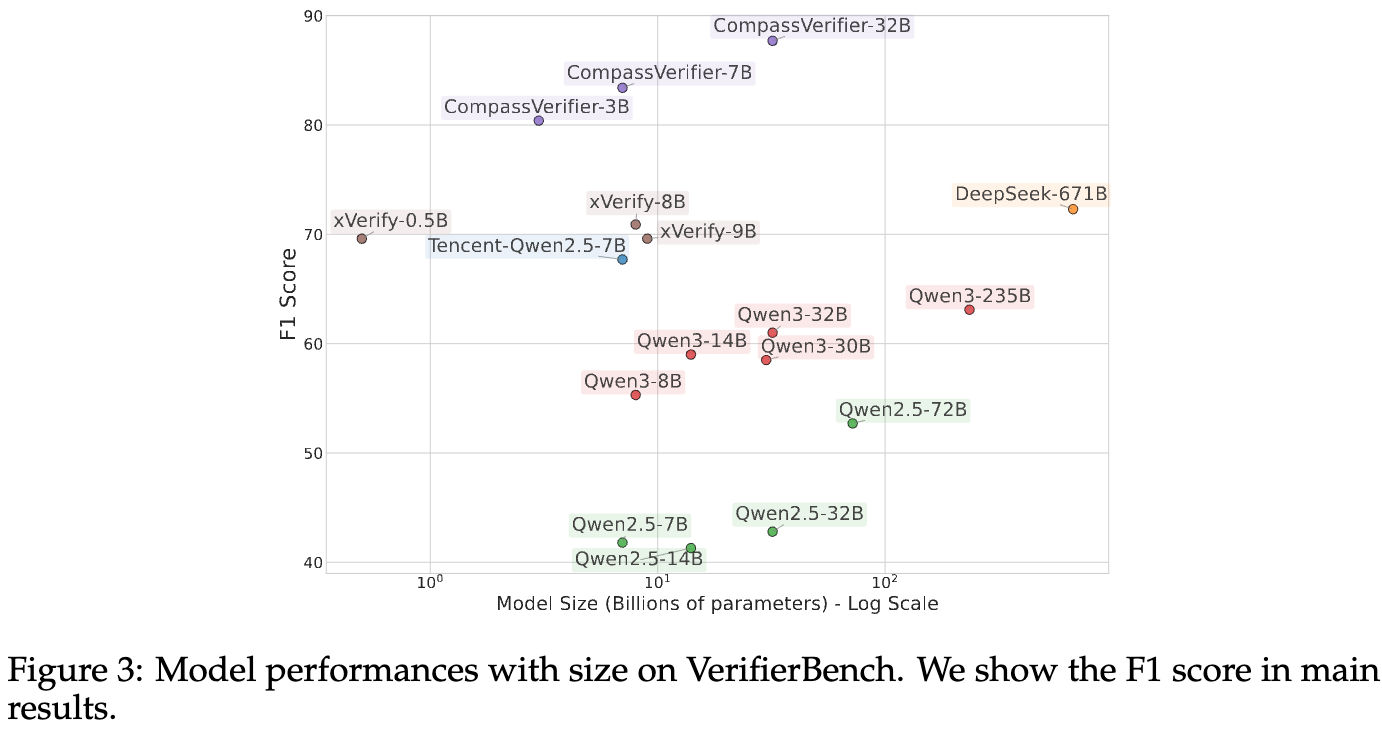
上图更直观地展示了 F1 分数与模型参数规模(对数坐标)的关系。可以清晰地看到 CompassVerifier 系列(图中标注的三个点)远远地脱离了其他模型的性能曲线,形成了一个新的“高效前沿”。
深入分析:CompassVerifier 究竟强在哪里?
为了更深入地理解 CompassVerifier 的优势来源,作者们进行了一系列更细粒度的分析。
1. 按答案类型分析
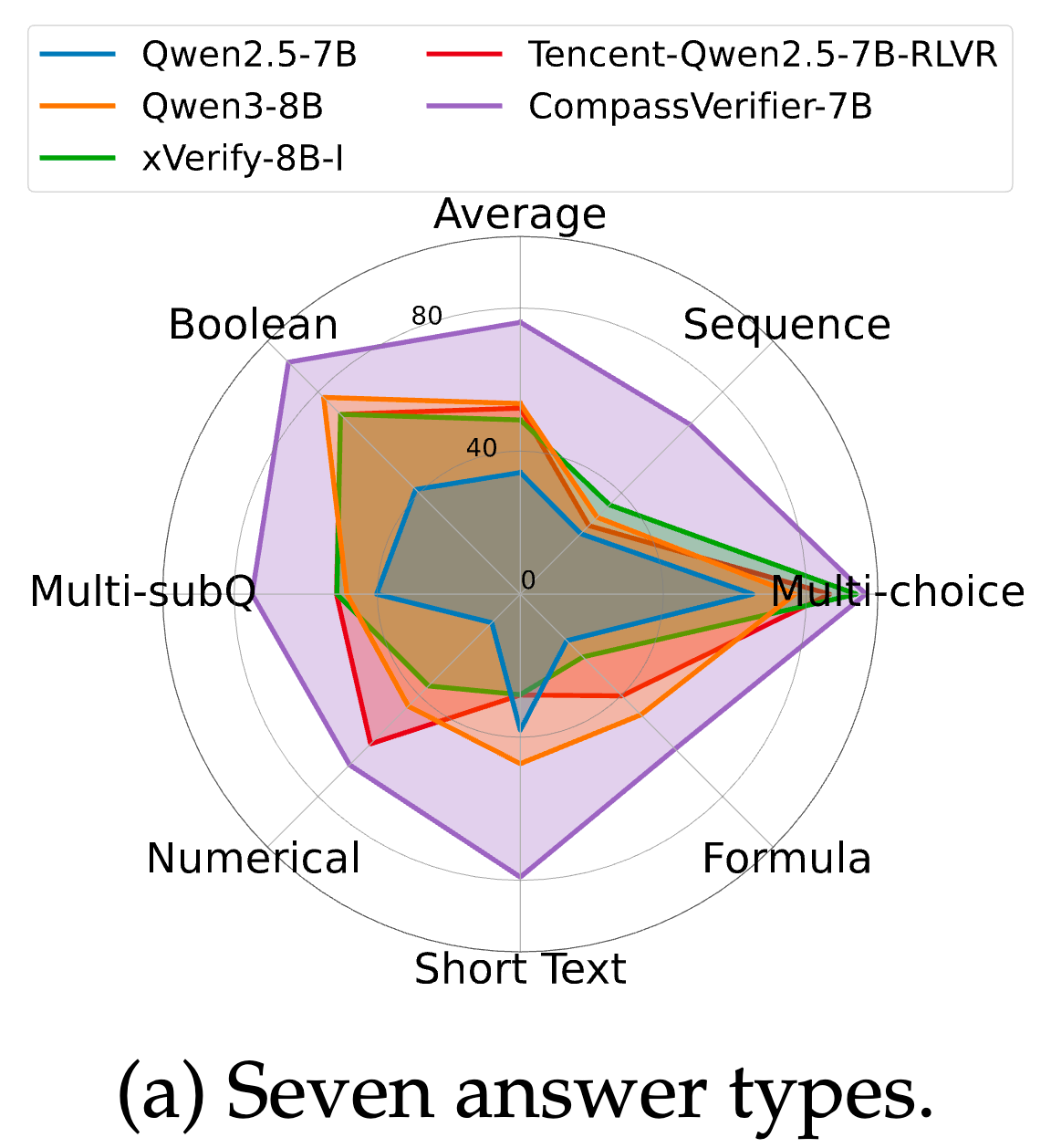
这张雷达图展示了几个代表性模型在 7 种不同答案类型上的表现。
-
简单类型:在“多项选择(multiple-choice)”这类常见类型上,大多数模型表现尚可,因为这是它们在预训练和指令微调中经常见到的任务。 -
复杂类型:差距主要体现在 公式(formula)、多子问题(multi-subproblem)和序列(sequence) 这三种复杂类型上。基线模型在这些任务上表现极差,特别是序列类型,F1 分数几乎都不超过 40%。而 CompassVerifier-7B在所有类别上都实现了一致的提升,证明了其处理复杂结构化答案的强大能力。这正是“复杂公式增强”和“泛化能力增强”等技术发挥作用的地方。
2. 超越二元分类:识别“无效”回答的能力
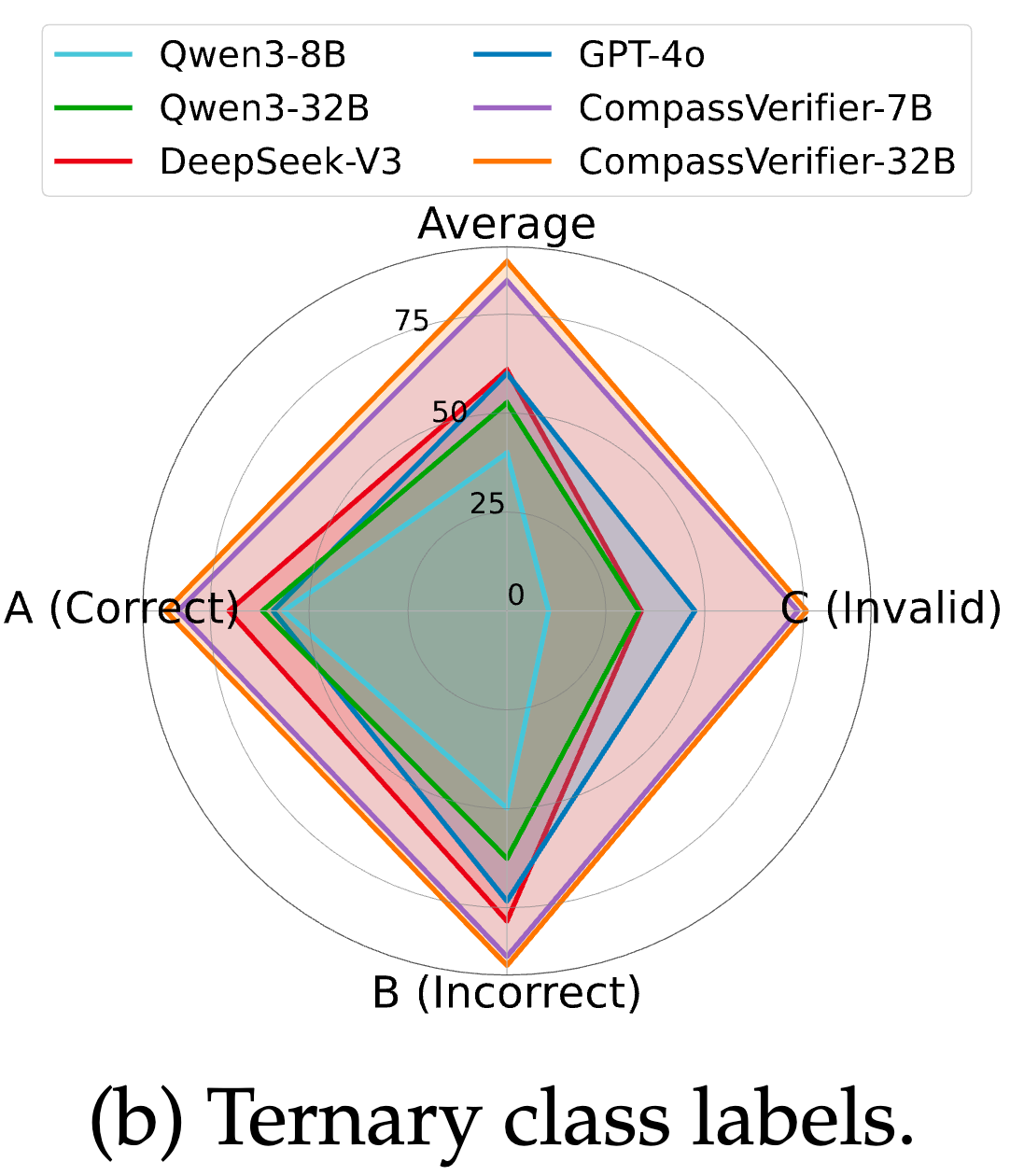
此图分析了模型在区分 A(正确)、B(错误)、C(无效) 三个类别时的性能。
-
通用 LLM 的偏见:结果显示,即便是 GPT-4o和DeepSeek-V3这样强大的通用模型,虽然在区分 A 和 B 上表现不错,但在识别 C 类(无效)样本上存在巨大短板。 -
原因:作者们通过人工分析发现,通用 LLM 对重复模式或截断响应等“无效”特征不敏感。这凸显了在训练数据中明确引入“无效”类别并进行针对性训练的重要性。 CompassVerifier在 C 类的识别上表现明显更优,这要归功于VerifierBench的精心设计以及在数据过滤阶段对重复字符串的检测脚本。
3. 消融研究:三大技术缺一不可
为了证明三项数据增强技术的有效性,作者们对 CompassVerifier-7B 进行了消融实验。
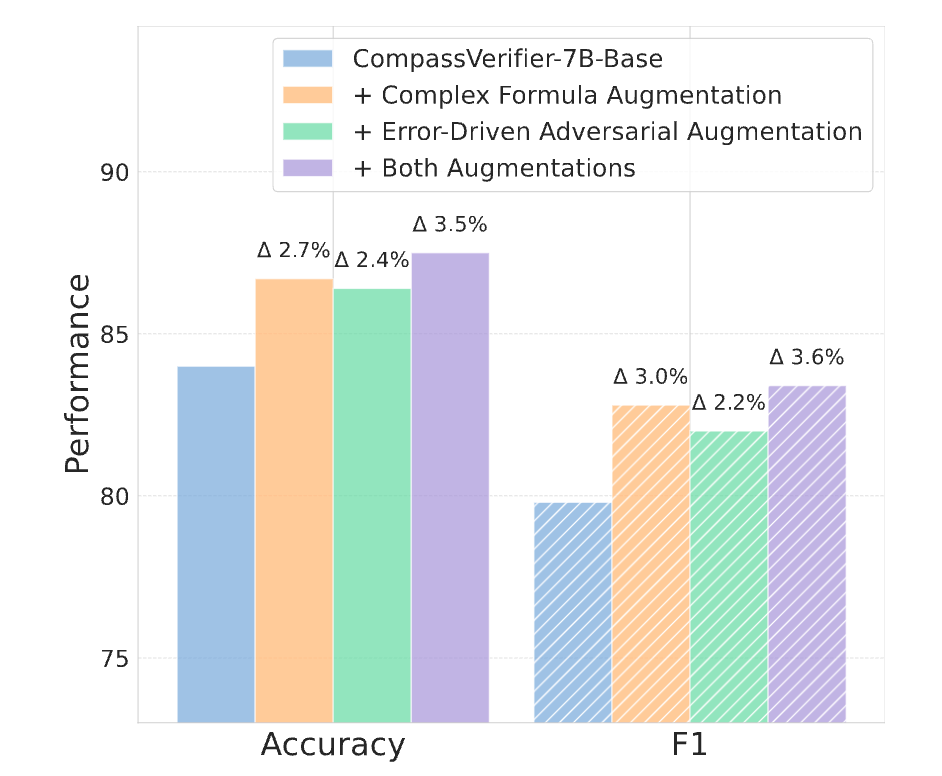
-
基线(Base):只使用 VerifierBench的基础训练集进行训练,F1 分数为 79.8%。 -
+ 复杂公式增强:在基线之上加入公式增强数据,F1 分数提升到 82.8%(+3.0%)。这证明了该技术在处理多样化公式表达上的有效性。 -
+ 错误驱动增强:在基线之上加入错误驱动增强数据,F1 分数提升到 82.0%(+2.2%)。这证明了该技术在让模型学习人类判断的微妙之处、对抗失效模式上的价值。 -
+ 两者皆有:同时使用两种增强技术,F1 分数达到 83.4%(+3.6%),取得了最佳性能。这表明两种技术是互补的,共同提升了模型的整体验证能力。
泛化能力测试:能否应对“题型变化”?
一个好的验证器不应该只在自己的“主场”表现优异。为了测试 CompassVerifier 的泛化能力,作者们将其在一个全新的、它从未见过的测试集——VerifyBench(一个同期的相关工作)的困难子集上进行了测试。
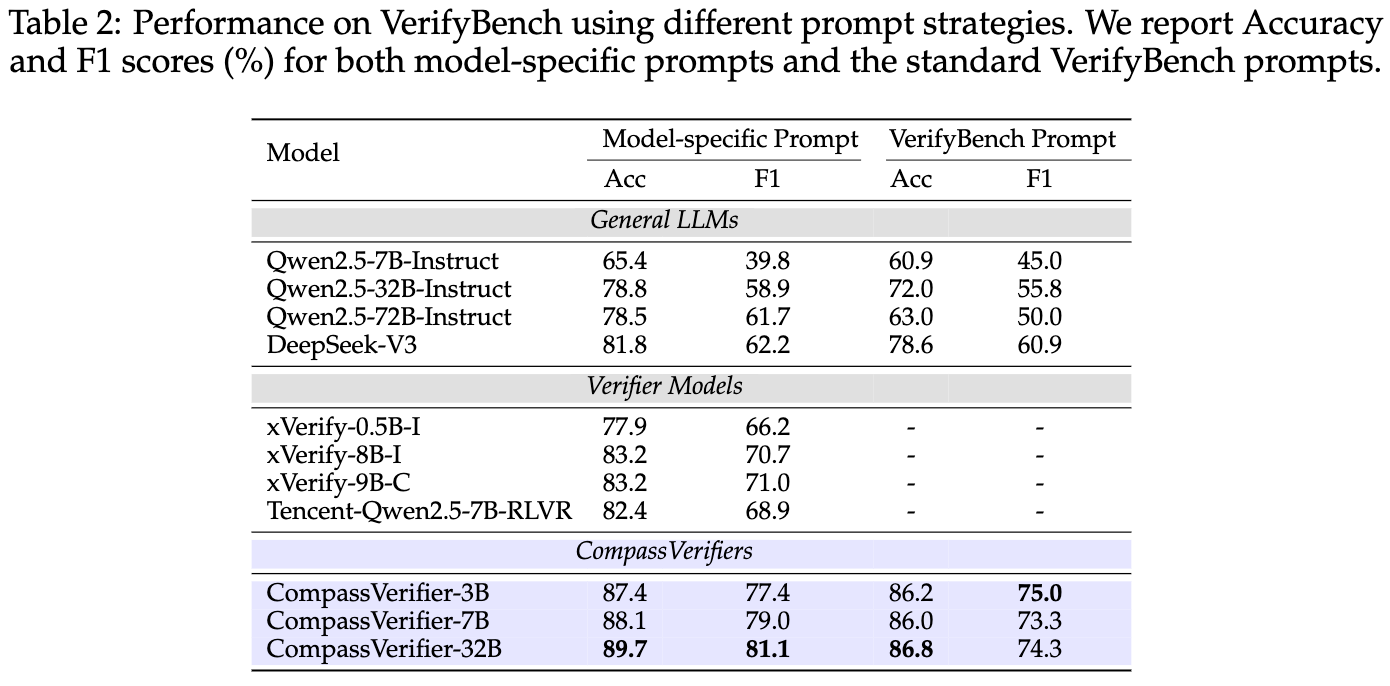
这个实验的设计非常巧妙。它测试了两种情况:
-
模型特定提示词:每个模型都使用自己训练时或官方推荐的提示词。 -
统一的 VerifyBench 提示词:所有模型都使用 VerifyBench数据集提供的统一提示词,这对模型来说是更深层次的“分布外(out-of-distribution)”考验。
实验结果再次证明了 CompassVerifier 的强大:
-
持续领先:无论在哪种提示词设置下, CompassVerifier的表现都优于同等规模的通用 LLM、其他专用验证器,甚至超过了DeepSeek-V3。 -
强大的鲁棒性:在更具挑战的“统一提示词”设置下, CompassVerifier的性能虽然略有下降,但依然保持在 86% 以上的准确率,表现非常稳健。而xVerify和Tencent-RLVR这两个模型则完全无法遵循新的指令,导致测试失败。这充分展示了“泛化能力增强”技术带来的好处。
第五章:超越评估 —— 作为奖励模型的应用
CompassVerifier 的价值远不止于一个被动的“评估工具”。它更重要的角色,是作为一个主动的“奖励模型(Reward Model)”,在强化学习(RL)中引导 LLM 的进化。
在 LLM 的强化学习(如 RLHF 或 RLAIF)流程中,奖励模型是至关重要的一环。它负责评估 LLM 在给定一个提示后生成的多个回答的质量,并给出一个分数值(即“奖励”)。这个奖励信号会指导基础 LLM 的参数更新,使其倾向于生成能获得更高奖励的回答。
一个好的奖励模型,必须能提供 准确、稳定、且与最终任务目标高度一致 的奖励信号。如果奖励信号有偏或不准,那么 RL 训练过程可能会被误导,甚至产生负面效果。
作者们进行了一项实验,来验证 CompassVerifier 作为奖励模型的潜力。
实验设置
-
基础模型:选用 Qwen3-4B-Base作为需要被优化的基础 LLM。 -
RL 算法:采用 GRPO 算法进行训练。 -
训练任务:使用具有挑战性的 Open-S1数学推理数据集作为 RL 的训练语料。 -
对比的奖励模型: -
基线(无 RL):原始的 Qwen3-4B-Base模型性能。 -
规则奖励:使用 Math-Verify工具作为奖励模型。 -
LLM 奖励:使用其他通用 LLM 或专用验证器(如 Tencent-RLVR)作为奖励模型。 -
CompassVerifier 奖励:使用 CompassVerifier-7B和CompassVerifier-32B作为奖励模型。
-
-
评估:在 AIME24、AIME25和MATH500这三个高难度的数学推理基准上,评估经过 RL 训练后的基础模型的性能。
结果与启示:高质量奖励信号的巨大威力
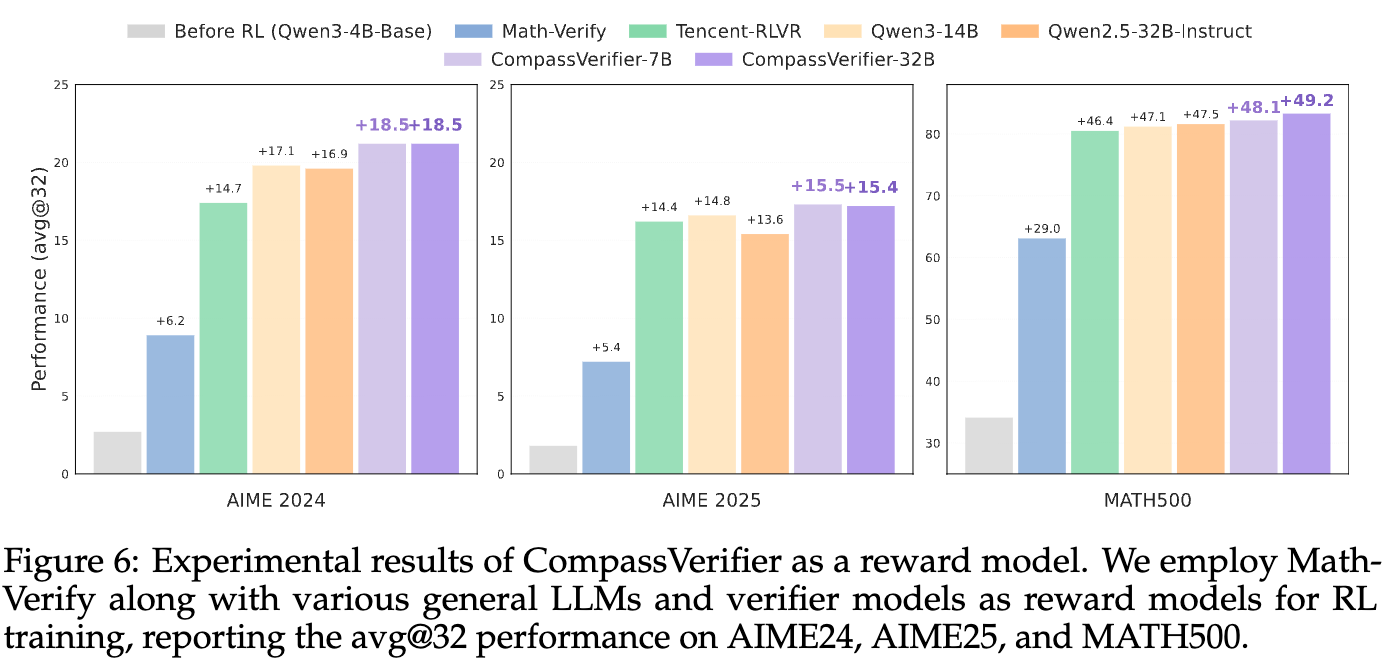

实验结果:
-
性能全面超越:使用 CompassVerifier作为奖励模型训练出的Qwen3-4B-Base,在所有三个数学基准上的性能,都显著优于使用其他任何奖励模型训练出的版本。 -
揭示了规则奖励的局限:与 Math-Verify这种基于规则的奖励相比,基于CompassVerifier的模型奖励展现出巨大的性能优势。这说明随着 RL 训练覆盖的数据类型和学科越来越广泛,简单的规则匹配工具已经变得越来越力不从心。 -
更精确的反馈信号:这一结果凸显了 CompassVerifier作为奖励模型的优越性。它能够为 RL 训练中产生的轨迹(rollout trajectories)提供更精确的评估。当模型生成一个稍微不同但正确的答案时,CompassVerifier能给出正向奖励,而Math-Verify可能会给零分;当模型生成一个看似合理但有细微错误的答案时,CompassVerifier能准确识别并给出负向奖励。 -
提升收敛效率:更有效的奖励信号意味着 RL 训练的收敛效率会大大提高。模型能够更快地学会什么是“好的”回答,从而减少了训练所需的资源和时间。
往期文章:


