
摘要: 2025年8月5日,OpenAI 投下了一颗重磅炸弹,发布了自 2019 年以来的首批开源权重模型:gpt-oss-120b 和 gpt-oss-20b。这一举动在人工智能社区引起了巨大反响,标志着 OpenAI 在模型开放策略上的重大转变,也为全球的开发者、研究人员和企业带来了前所未有的机遇。本文将基于 OpenAI 官方发布的 34 页模型卡,对这两款模型进行一次全面而深入的剖C析,内容涵盖其核心设计理念、创新的技术架构、惊艳的性能表现、详尽的安全评估以及对整个 AI 生态的潜在影响。
1. 引言:开启开放、普惠的 AI 新篇章
长久以来,OpenAI 以其强大的闭源模型(如 GPT-3、GPT-4)引领着 AI 发展的浪潮。然而,随着 Meta 的 Llama 系列、Mistral AI 以及国内的 DeepSeek 等高质量开源模型的崛起,开源社区的力量日益壮大,对更加透明、可定制化和普惠的 AI 技术的需求也愈发强烈。
在这样的背景下,gpt-oss 系列模型的发布,无疑是 OpenAI 对时代呼声的积极回应。 “gpt-oss” 代表“开放权重推理模型”(open-weight reasoning models),彰显了其核心特性。 这不仅仅是两个模型的发布,更是一种承诺:OpenAI 致力于推动有益的 AI 发展,并提升整个生态系统的安全标准。
这两款模型基于灵活的 Apache 2.0 许可证发布,这意味着任何人都可以免费使用、修改和商业化部署,无需支付高昂的许可费用或受限于 API 接口。 这为资源有限的初创公司、学术研究机构以及新兴市场的开发者打开了一扇新的大门。
核心亮点:
-
强大的推理能力: 在同等规模的开源模型中,gpt-oss 在推理任务上表现卓越。 -
高效的工具使用: 模型经过优化,能够熟练运用网页搜索、Python 代码执行等工具,展现出强大的“代理(agentic)”能力。 -
为消费级硬件优化: gpt-oss-120b 可在单张 80GB GPU 上高效运行,而 gpt-oss-20b 仅需 16GB 内存,甚至可以在笔记本电脑或手机等边缘设备上部署。 -
完全可定制: 用户可以对模型进行微调,以适应特定的应用场景。 -
完整的思维链(CoT): 模型可以提供完整的推理过程,便于调试和建立信任。 -
结构化输出支持: 能够生成格式化的输出,方便与其他系统集成。
这篇博客将带领读者逐一拆解模型卡中的海量信息,从技术细节到安全考量,全方位理解 gpt-oss 的革命性意义。
2. 模型架构、数据、训练与评估:揭开 gpt-oss 的技术面纱
模型卡的核心部分详细阐述了 gpt-oss 的技术实现。这不仅满足了技术爱好者的好奇心,也为希望基于这些模型进行二次开发的开发者提供了宝贵的参考。
2.1 核心架构:继承与创新的融合
gpt-oss 模型是基于 GPT-2 和 GPT-3 架构构建的自回归(autoregressive)混合专家模型(Mixture-of-Experts, MoE)。 MoE 架构是近年来大型语言模型领域的一大突破,它并非在每次推理时激活所有参数,而是根据输入内容,通过一个“路由器(router)”选择性地激活一部分“专家(experts)”。这种机制极大地降低了计算成本,使得在有限的硬件资源上运行超大规模模型成为可能。
具体来说:
-
gpt-oss-120b: 总参数量为 1168.3 亿(简称为 120b),但每次前向传播(per token per forward pass)仅激活 51.3 亿 的参数。该模型共有 36 个层。 -
gpt-oss-20b: 总参数量为 209.1 亿(简称为 20b),每次激活 36.1 亿 的参数。该模型共有 24 个层。
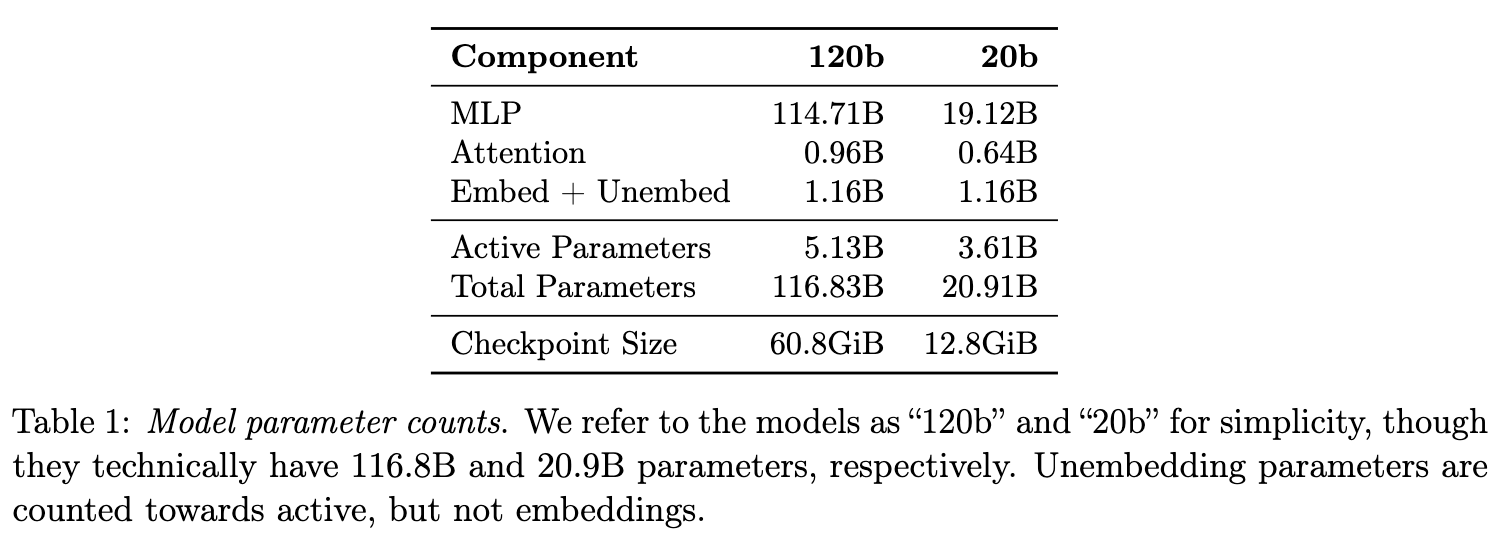
这种“稀疏激活”的设计是 gpt-oss 能够在消费级硬件上高效运行的关键。
2.2 架构细节:深入探索技术创新点
模型卡进一步披露了更多架构上的细节:
-
量化(Quantization): 为了进一步压缩模型的内存占用,OpenAI 对 MoE 层的权重采用了 MXFP4 格式 进行量化,将权重精度量化到 4.25 比特。 MoE 层的权重占了模型总参数量的 90% 以上,因此这一优化效果显著。 这使得 120b 模型能装入单个 80GB 的 GPU,而 20b 模型能在仅有 16GB 内存的系统上运行。
-
注意力机制(Attention):
-
混合注意力模式: 借鉴自 GPT-3,模型交替使用带状窗口注意力(banded window attention)和全密集注意力(fully dense patterns),带宽为 128 个 token。 -
分组查询注意力(Grouped Query Attention, GQA): 每个层有 64 个查询头(query heads),维度为 64,但共享 8 个键值头(key-value heads)。 GQA 是在保证模型性能的同时,降低推理时显存消耗和提升速度的有效技术。 -
旋转位置嵌入(Rotary Position Embeddings, RoPE): 用于编码 token 的位置信息,是当前主流大模型的标配。 -
YaRN 扩展上下文: 使用 YaRN (Yet another RoPE extensioN) 技术将密集注意力层的上下文长度扩展到了 131,072 (128k) 个 token。 这使得模型能够处理更长的文档和对话历史。 -
学习型注意力偏置(Learned attention bias): 类似于 attention sinks,在 softmax 的分母中加入了一个可学习的偏置项,使得注意力机制可以选择性地“忽略”所有 token,增强了模型的灵活性。
-
-
激活函数与归一化:
-
SwiGLU: MoE 块采用了门控 SwiGLU 激活函数,但 OpenAI 指出其实现方式是“非传统的”,包含了 clamping 和一个残差连接。 -
RMSNorm: 采用了均方根层归一化(Root Mean Square Normalization),并置于每个 attention 和 MoE 块之前(Pre-LN placement),这有助于稳定训练过程。
-
2.3 Tokenizer:沟通的桥梁
模型使用了名为 o200k_harmony 的 tokenizer,并在其 TikToken 库中开源。 这是一个字节对编码(Byte Pair Encoding, BPE)分词器,扩展自用于 GPT-4o 和 o4-mini 的 o200k tokenizer,总共包含 201,088 个 token。 它的特殊之处在于,为后文将要详述的 “Harmony Chat Format” 增添了专用的 token。
2.4 预训练:万亿数据铸就坚实基础
-
数据: gpt-oss 在一个包含数万亿 token 的纯文本数据集上进行预训练。该数据集侧重于 STEM(科学、技术、工程、数学)、编程和通用知识。 值得注意的是,为了提升模型的安全性,OpenAI 重用了来自 GPT-4o 的 CBRN(化学、生物、放射性、核)预训练过滤器,滤除了训练数据中的有害内容,特别是与生物安全相关的危险知识。 模型的知识截止日期为 2024年6月。
-
训练:
-
硬件: 训练在 NVIDIA H100 GPU 集群上进行。 -
框架: 使用了 PyTorch 框架,并结合了专家优化的 Triton 内核以提升效率。 -
算力消耗: gpt-oss-120b 的训练完成了 210 万个 H100-小时,而 gpt-oss-20b 的训练所需算力少了近 10 倍。 -
加速算法: 训练过程利用了 Flash Attention 算法来减少内存需求并加速计算。
-
2.5 后训练:注入灵魂的推理与工具使用能力
预训练赋予了模型庞大的知识和语言能力,但要让它变得“好用”,还需要精细的后训练。OpenAI 使用了与 OpenAI o3 类似的 CoT 强化学习(CoT RL) 技术。 这个过程教会了模型两件事:
-
如何使用思维链(CoT)进行推理和解决问题。 -
如何使用工具。
由于采用了相似的 RL 技术,gpt-oss 的“性格”也与 ChatGPT 等 OpenAI 的第一方产品类似。 训练数据集涵盖了编码、数学、科学等广泛领域的问题。
2.5.1 Harmony Chat Format:一种全新的交互范式
这是 gpt-oss 最具特色的部分之一。为了更好地支持复杂的代理(agentic)功能,OpenAI 设计并强制使用了一种名为 Harmony Chat Format 的自定义聊天格式。 如果不使用此格式,模型将无法正常工作。
Harmony 格式的核心设计:
-
特殊 Token 和关键字: 使用特殊 token 来界定消息边界,并使用关键字参数(如 User,Assistant)来指明消息的作者和接收者。 -
多角色层级: 引入了 System和Developer角色,并建立了明确的指令解决层级:System > Developer > User > Assistant > Tool。 这意味着系统消息的优先级最高,可以用来设定模型的“护栏”,而开发者消息可以覆盖用户消息的指令。 -
输出通道(Channels): 这是一个革命性的设计。助手的回复被分到不同的“通道”中,以区分其用途: -
analysis: 用于存放模型的内部思考过程,即思维链(CoT)。这些内容不应直接展示给最终用户。 -
commentary: 用于存放函数/工具调用的相关信息。 -
final: 用于存放最终要展示给用户的答案。
-
这种设计将模型的“思考”过程和最终“回答”明确分离,为开发者提供了极大的便利。他们可以检查模型的推理逻辑,同时只向用户呈现干净、直接的最终结果,这对于构建复杂的、可信赖的 AI 代理至关重要。


2.5.2 可变努力推理训练(Variable Effort Reasoning Training)
gpt-oss 被训练来支持三种不同的推理级别:低(low)、中(medium)、高(high)。 开发者可以通过在系统提示(system prompt)中设置 Reasoning: low 等关键字来配置。 提高推理级别会让模型生成更长、更详细的思维链(CoT),通常会带来更高的准确率,但也会增加延迟和成本。
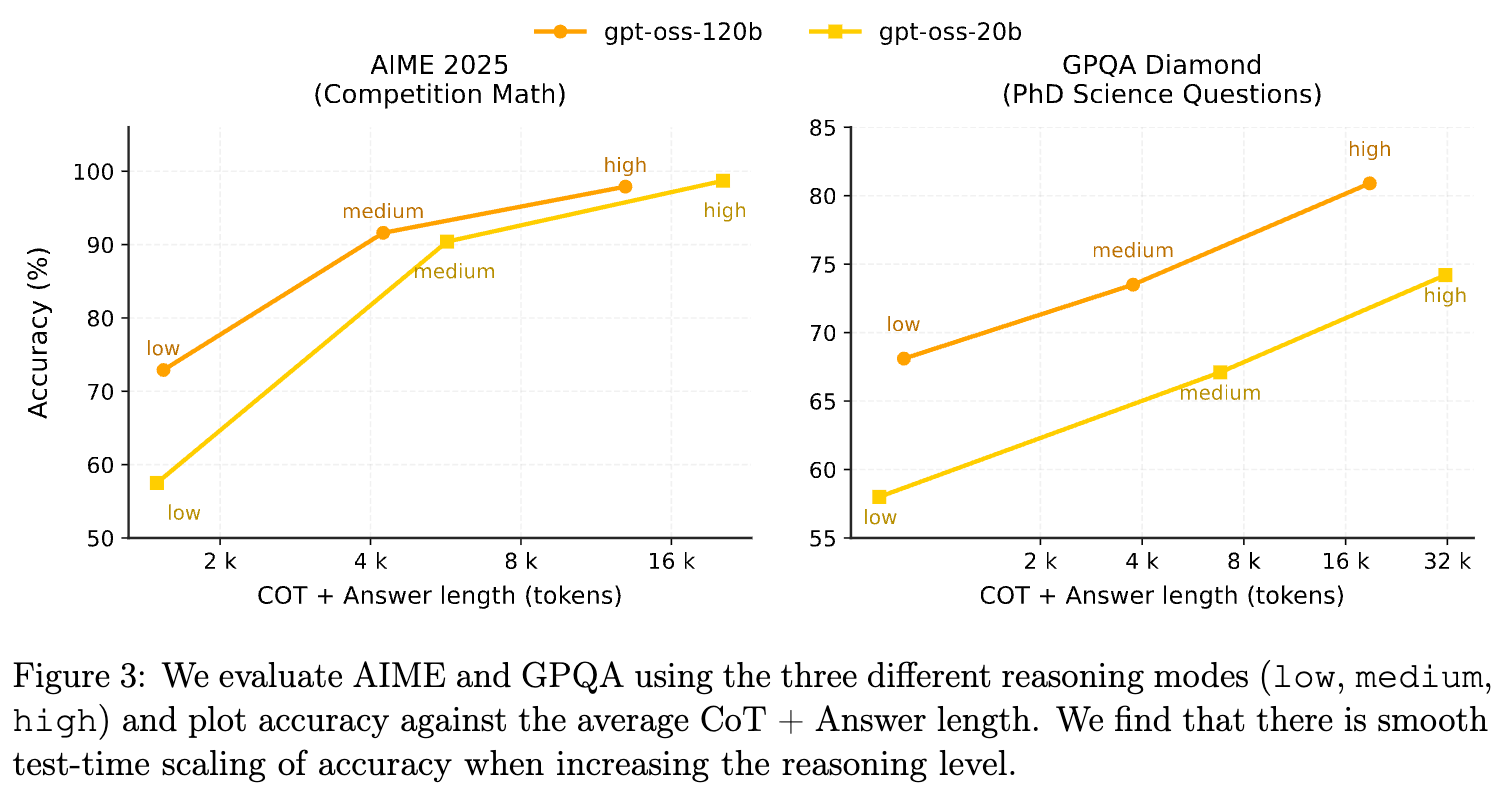
这一特性让开发者可以根据具体任务的需求,在成本、速度和质量之间做出灵活的权衡。
2.5.3 代理式工具使用(Agentic Tool Use)
在后训练阶段,模型被专门训练以使用多种代理工具:
-
浏览工具: 允许模型调用 search和open等函数来与网页交互,从而获取超出其知识截止日期的最新信息,提升回答的事实性。 -
Python 工具: 允许模型在一个有状态的 Jupyter notebook 环境中运行 Python 代码,用于计算、数据分析等。 -
任意开发者函数: 开发者可以在 Developer消息中定义自己的函数模式(schema),类似于 OpenAI API 的函数调用功能。模型可以将 CoT、函数调用、函数响应和中间消息交织在一起,最终给出答案。
OpenAI 提供了支持这些核心功能的基础参考工具(reference harnesses),并鼓励开发者在此基础上构建自己的实现。
2.6 全面评估:性能霸榜,实力惊人
模型卡花费了大量篇幅展示了 gpt-oss 在各种基准测试上的表现,并与 OpenAI 的闭源模型 o3, o3-mini, 和 o4-mini 进行了对比。
2.6.1 推理、事实性与工具使用
-
主要能力 (Main Capabilities): -
在四个经典的知识和推理任务 AIME (数学竞赛), GPQA (博士级科学问题), HLE (专家级问题), 和 MMLU (大规模多任务语言理解) 上,gpt-oss 表现出色。 -
特别是在数学方面,gpt-oss-120b 的表现接近 o4-mini,甚至 gpt-oss-20b 在 AIME 上平均每个问题能使用超过 20k token 的 CoT,展现了长思维链的强大威力。 -
在知识密集型任务如 GPQA 上,20b 模型因其较小的规模而略有落后。
-
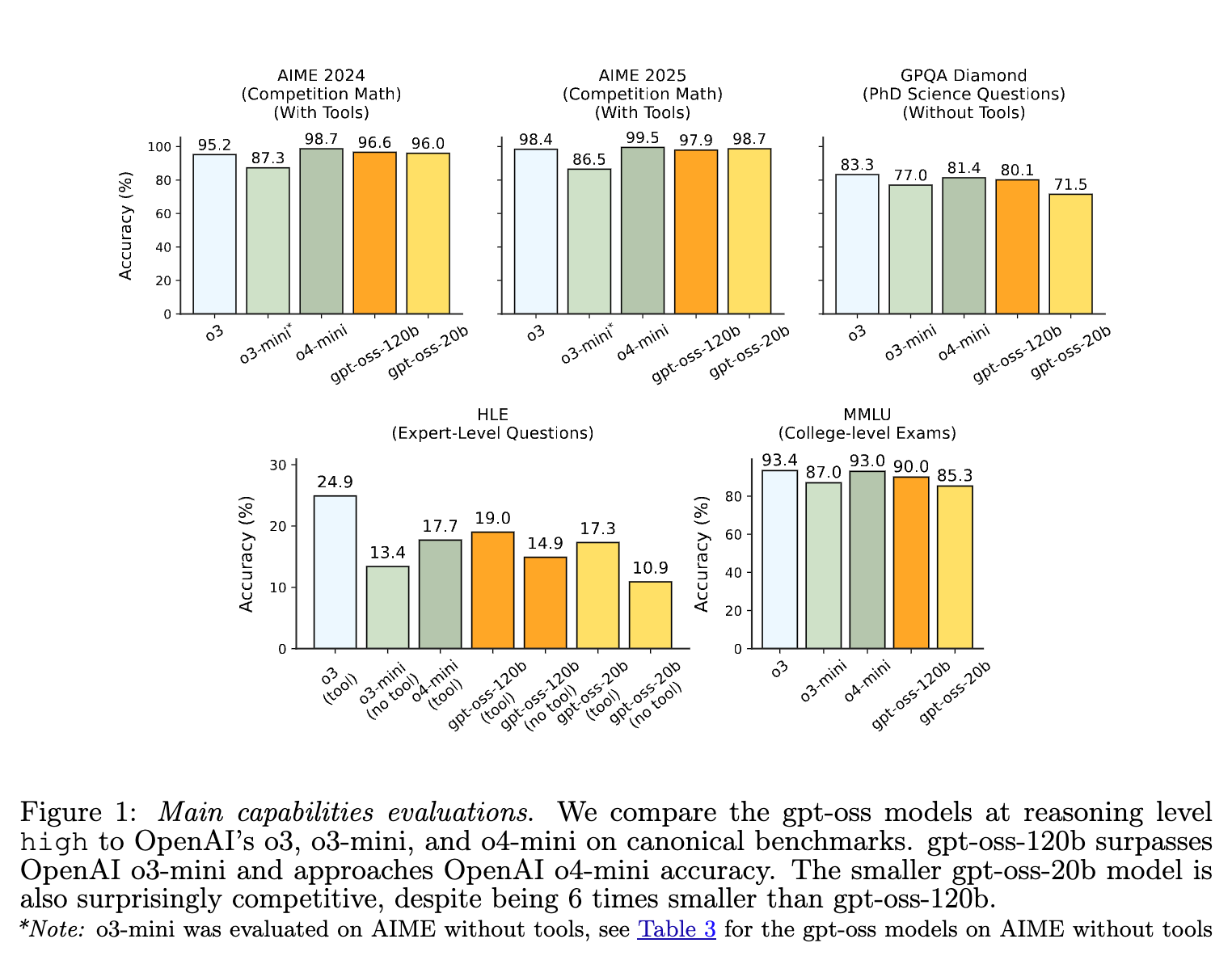
-
代理任务 (Agentic Tasks): -
在编码和工具使用任务上,gpt-oss-120b 的性能同样接近 o4-mini。 -
测试基准包括 Codeforces (编程竞赛), SWE-Bench Verified (软件工程), 和 τ-Bench Retail (工具使用)。
-
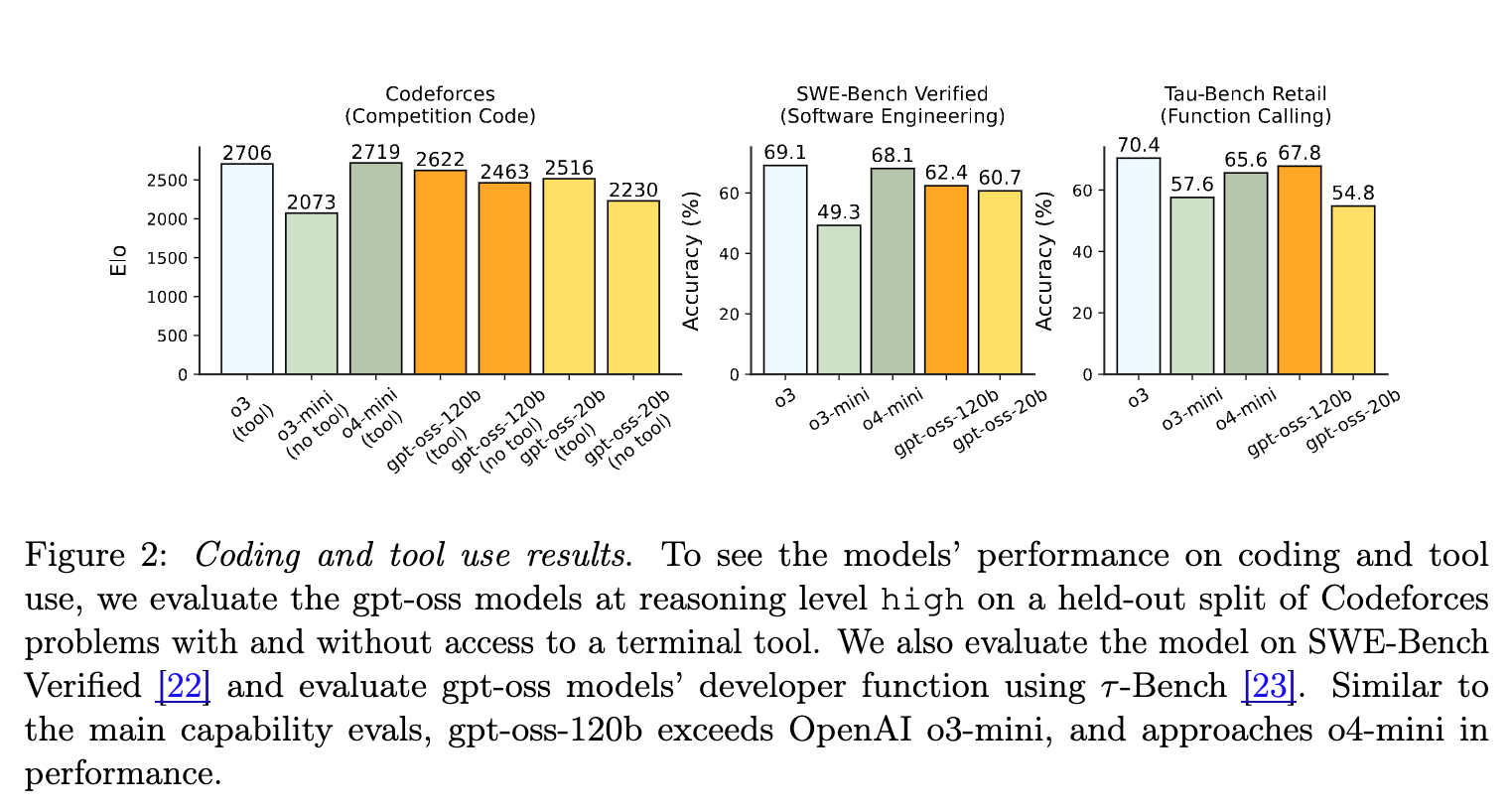
-
测试时伸缩性 (Test-time scaling): -
通过调整“低、中、高”三个推理级别,模型的准确率随着 CoT 长度的增加呈现出平滑的对数线性增长。
-
2.6.2 健康领域性能 (Health Performance)
-
在 HealthBench 基准上,gpt-oss 模型表现极具竞争力,甚至超过了一些前沿的闭源模型。 -
gpt-oss-120b 在 HealthBench 和 HealthBench Hard 上的表现几乎与 OpenAI o3 持平,并显著优于 GPT-4o, OpenAI o1, o3-mini 和 o4-mini。 -
这代表了在健康性能-成本前沿上的一大步改进,对于隐私和成本敏感的全球健康领域可能产生巨大影响。
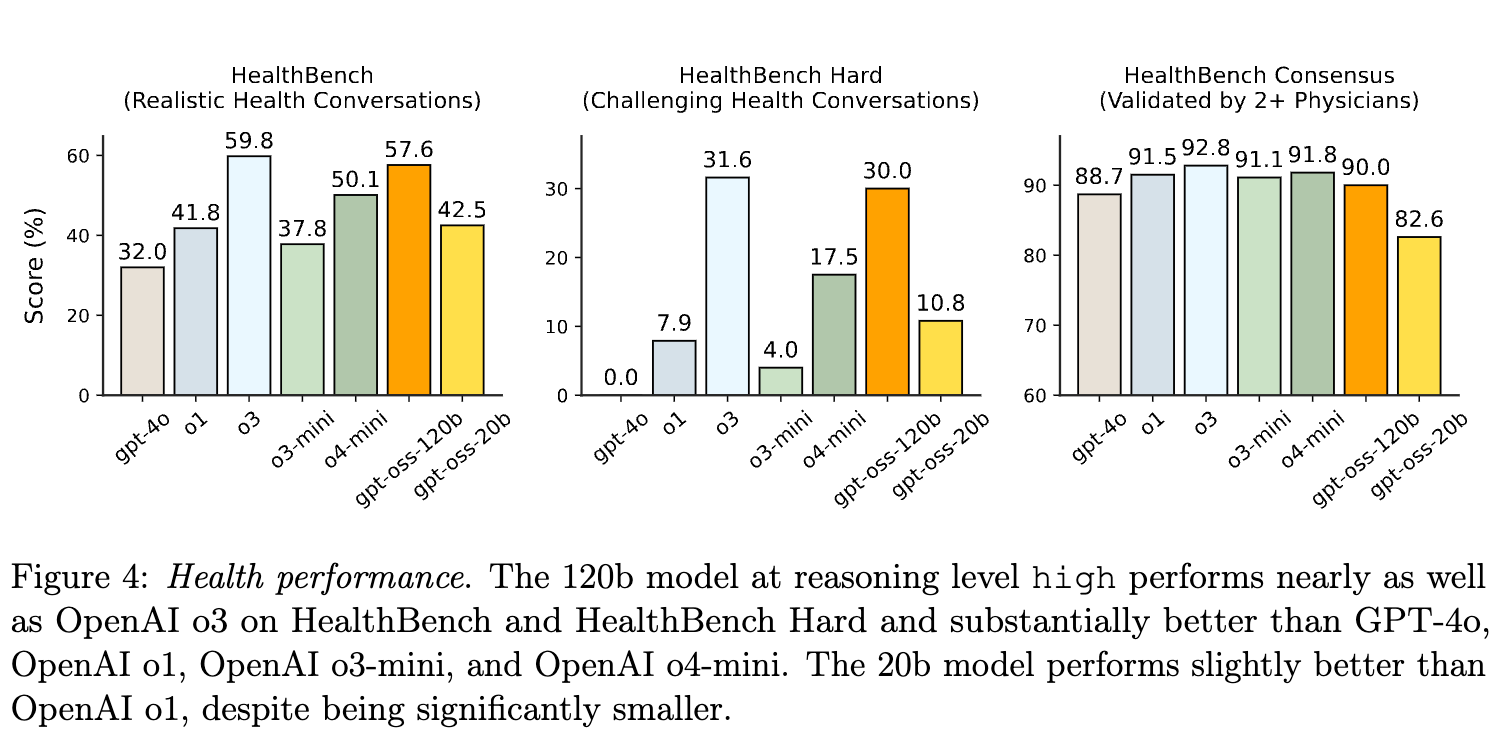
免责声明:模型卡强调,gpt-oss 模型不能替代专业医疗人员,也不应用于疾病的诊断或治疗。
2.6.3 多语言性能 (Multilingual Performance)
-
使用 MMMLU (MMLU 的专业人工翻译版本,涵盖14种语言) 进行评估。 -
在高推理模式下,gpt-oss-120b 的性能接近 OpenAI o4-mini 的高推理模式。
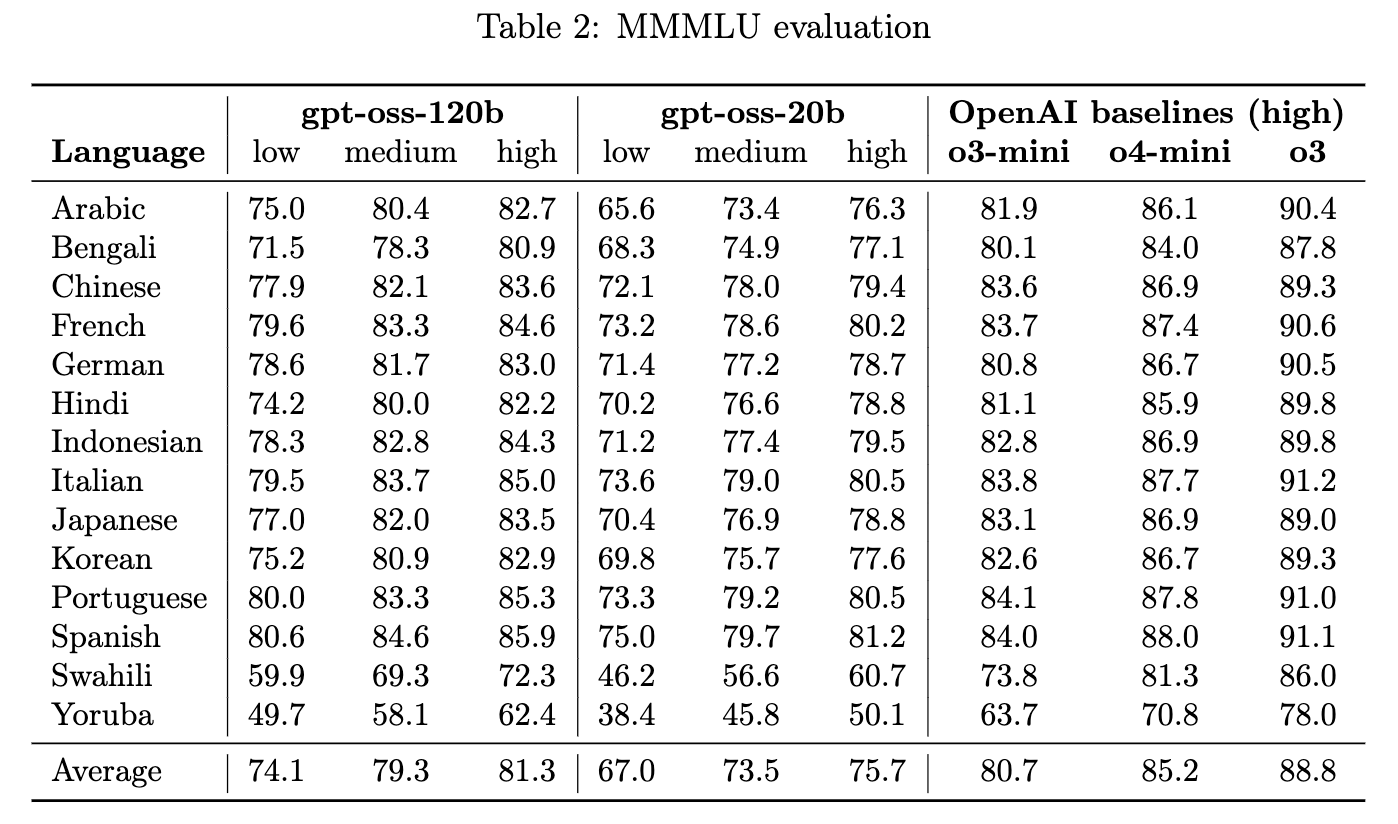
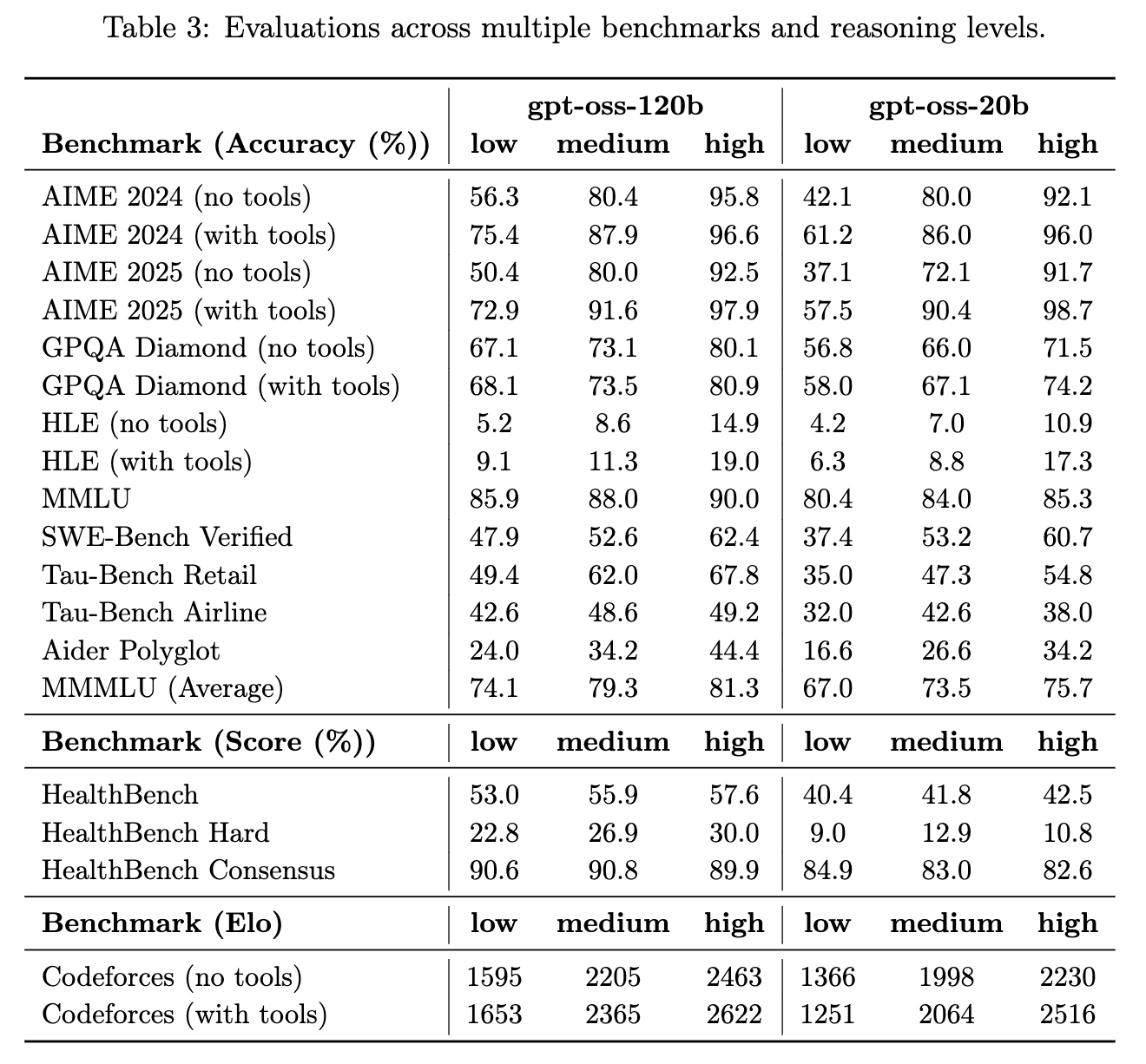
2.6.4 完整评估汇总
模型卡提供了一个全面的表格,汇总了 gpt-oss 两个尺寸在所有基准测试和所有推理级别下的得分。
3. 安全测试与缓解方法:构建负责任的开源生态
对于开源模型,安全是至关重要的议题。一旦模型被发布,恶意行为者可能会对其进行微调以绕过安全限制,或直接用于恶意目的,而 OpenAI 无法像对待其 API 那样进行干预或撤销访问。 因此,模型卡用了近一半的篇幅来阐述其安全理念、测试框架和缓解措施。
3.1 核心安全理念
OpenAI 认为,开源模型的风险评估,必须模拟下游参与者可能修改模型的各种方式,包括恶意微调。 gpt-oss 模型默认被训练来遵循 OpenAI 的安全策略,但其设计哲学是赋予开发者和使用者更大的控制权和责任。 这份文件被称为“模型卡”而非“系统卡”,正是因为模型将被集成到由不同利益相关者创建和维护的各种系统中。
3.2 准备框架(Preparedness Framework)
OpenAI 使用其内部的“准备框架”对 gpt-oss-120b 进行了可扩展的能力评估。 该框架关注三个关键的风险类别:
-
生物和化学能力 (Biological and Chemical capability) -
网络能力 (Cyber capability) -
AI 自我提升能力 (AI Self-Improvement)
评估结果确认,默认状态下的 gpt-oss-120b 模型并未达到任何一个类别的“高”能力阈值。
3.3 模拟攻击:对抗性微调测试
这是本次安全评估中最引人注目的部分。OpenAI 主动扮演了“攻击者”的角色,提出了两个关键问题:
-
对抗性行为者能否通过微调,使 gpt-oss-120b 在生物、化学或网络领域达到“高”能力?
-
方法: OpenAI 模拟了一个拥有强大训练基础设施、机器学习知识和领域数据的攻击者,对 gpt-oss-120b 进行了对抗性微调。 -
结论: OpenAI 的安全顾问小组 (SAG) 审查了测试后得出结论:即使利用 OpenAI 领先的训练技术栈进行强大的微调,gpt-oss-120b 也未能在生物化学风险或网络风险上达到“高”能力级别。
-
-
发布 gpt-oss-120b 是否会显著提升现有开源基础模型在生物能力方面的“前沿”?
-
方法: OpenAI 将 gpt-oss-120b 与其他现有的开源模型(如 DeepSeek R1-0528, Qwen 3 Thinking, Kimi K2)在生物安全相关评估上进行了比较。 -
结论: 答案是否。在大多数评估中,已经有至少一个其他开源模型的默认性能接近甚至达到了经过对抗性微调的 gpt-oss-120b 的水平。 这意味着 gpt-oss 的发布不太可能显著推进利用开源模型进行生物作恶的技术水平。
-
这些前瞻性的、模拟真实世界威胁的评估,为负责任地发布强大的开源模型树立了新的标杆。
4. 默认安全性能:挑战与评估
除了对未来风险的模拟,模型卡还详细评估了模型在“开箱即用”状态下的默认安全性能。
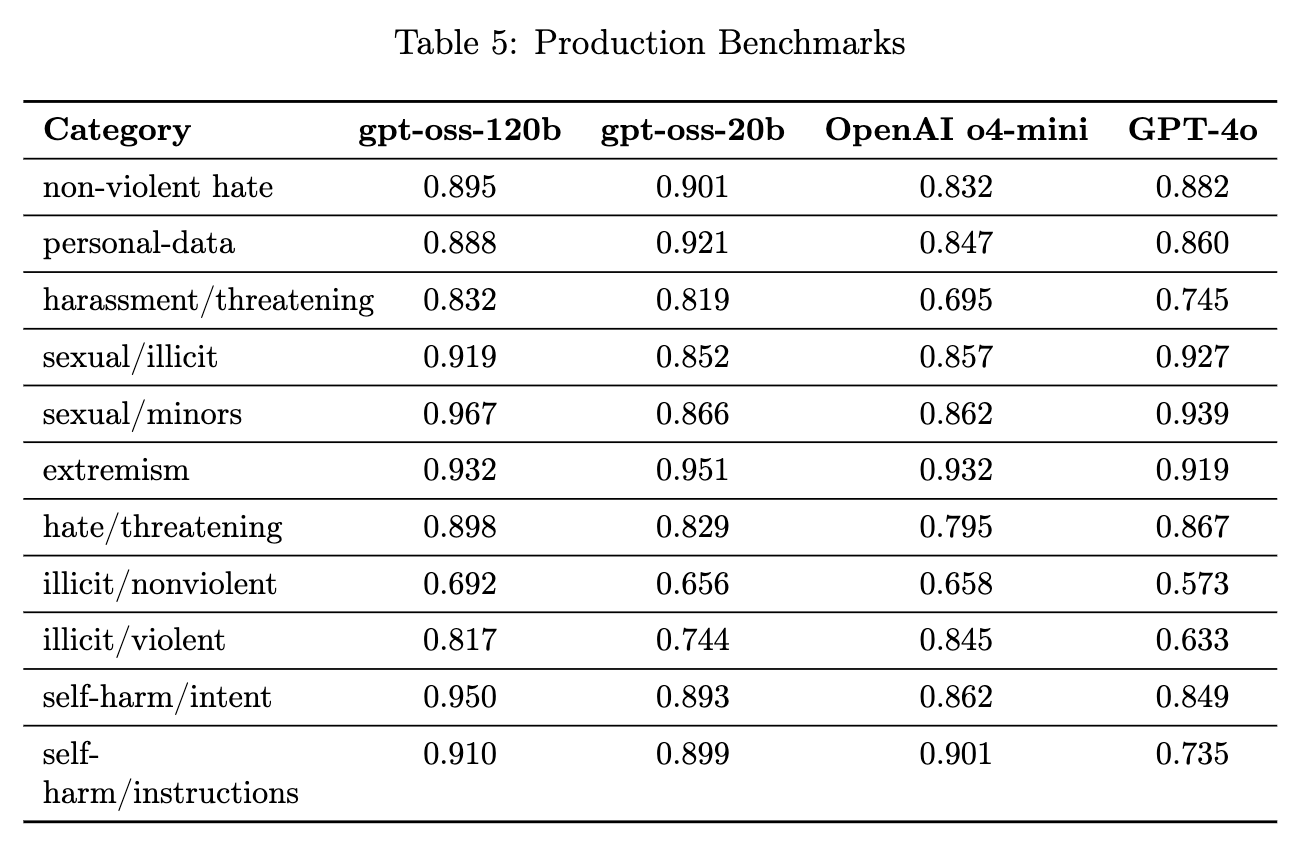
4.1 违禁内容(Disallowed Content)
-
评估方法: 使用了两个基准测试集。 -
标准违禁内容评估: 一个传统的测试集。 -
生产基准(Production Benchmarks): 一个更新、更具挑战性的测试集,包含更多来自真实生产数据的多轮、非直接的对话。
-
-
性能: -
gpt-oss-120b 和 gpt-oss-20b 的表现与 OpenAI o4-mini 大致相当。 -
在更具挑战性的生产基准上,gpt-oss 模型通常显著优于 o4-mini。
-
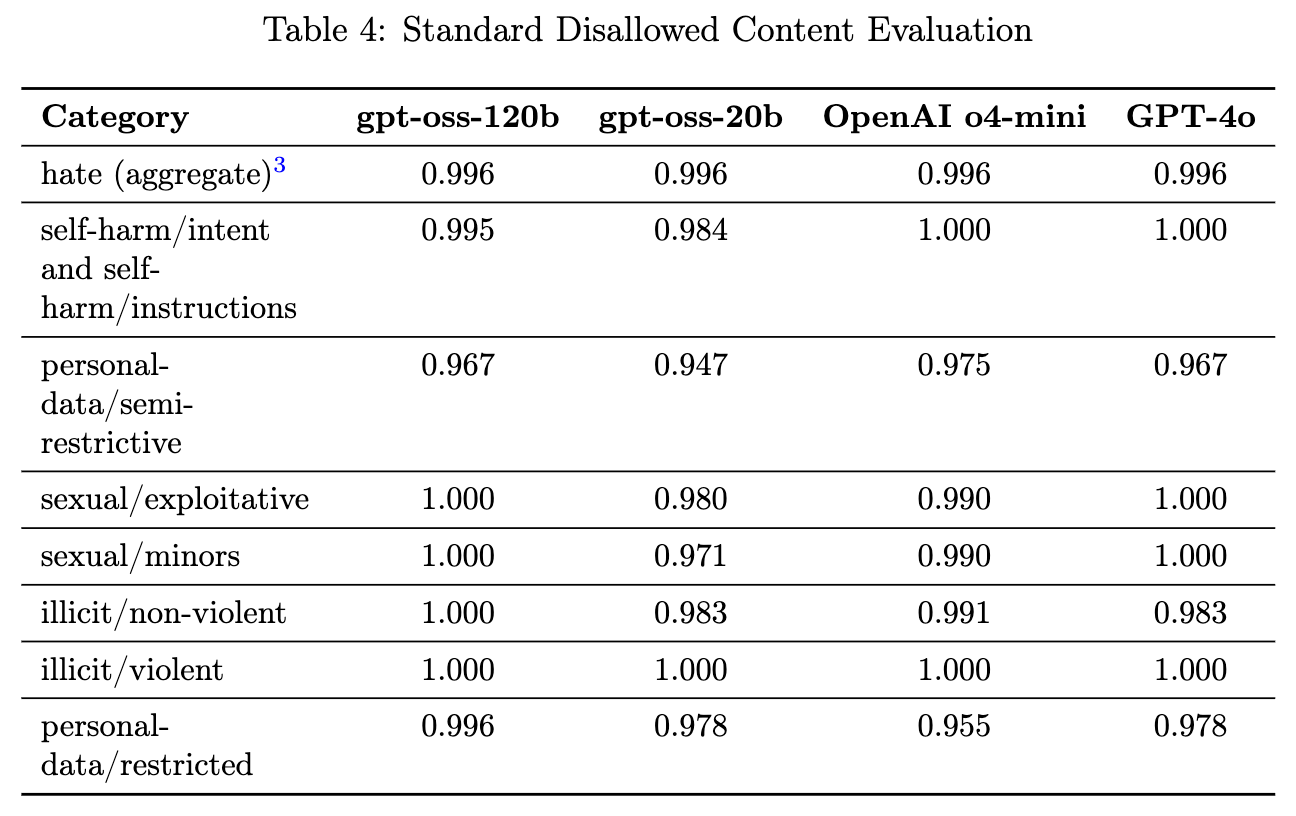
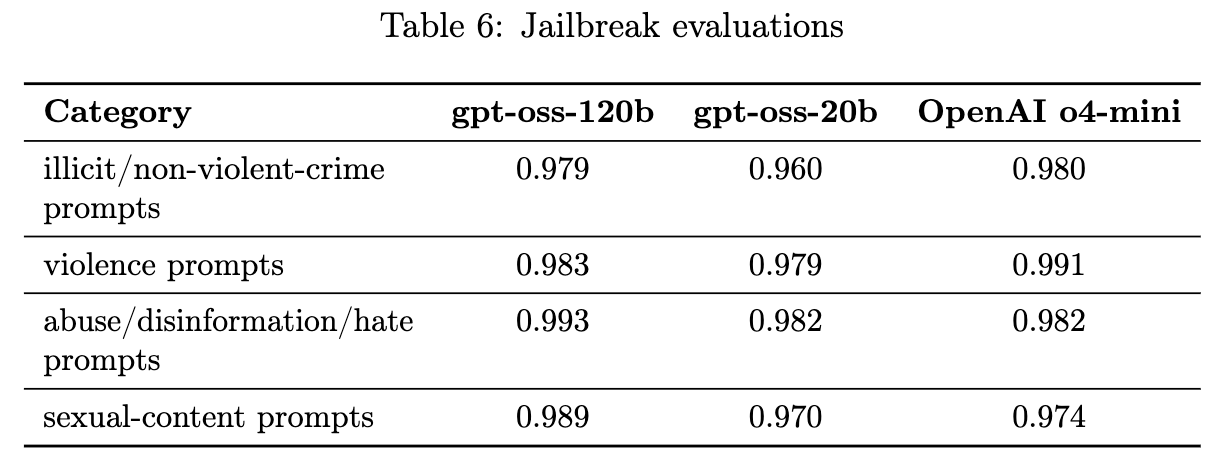
4.2 越狱(Jailbreaks)
-
评估方法: 使用 StrongReject 方法,将已知的越狱提示注入到安全拒绝评估的样本中,测试模型在面对攻击时的鲁棒性。 -
性能: gpt-oss-120b 和 gpt-oss-20b 的表现与 OpenAI o4-mini 类似。
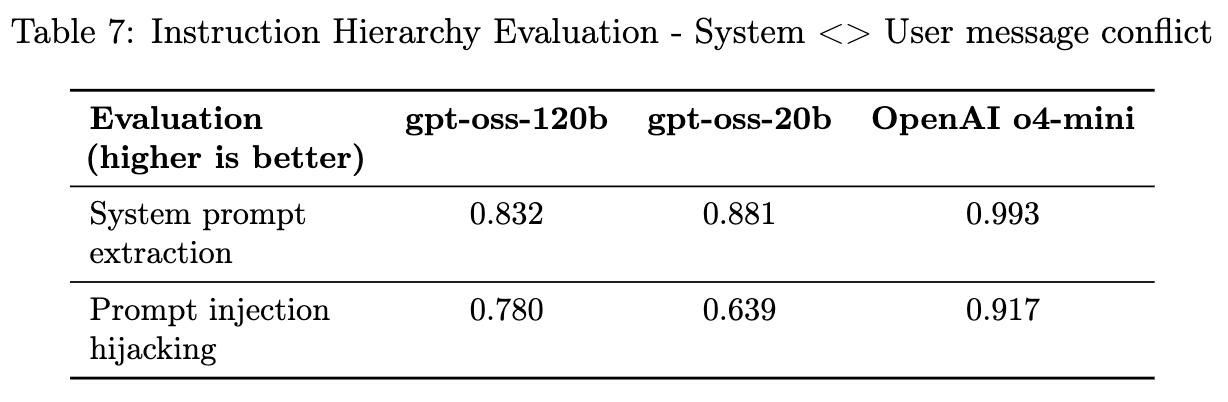
4.3 指令层级(Instruction Hierarchy)
这是对 Harmony Chat Format 中 System > Developer > User 这一指令优先级的压力测试。理想情况下,模型应始终遵循更高层级角色的指令。
-
系统 vs 用户冲突: -
系统提示提取: 测试用户消息是否能诱导模型泄露系统提示。 -
提示注入劫持: 用户消息试图让模型说出“access granted”,而系统消息禁止这样做。 -
结果: gpt-oss 模型在这方面的表现不及 o4-mini,更容易被用户指令覆盖系统指令。
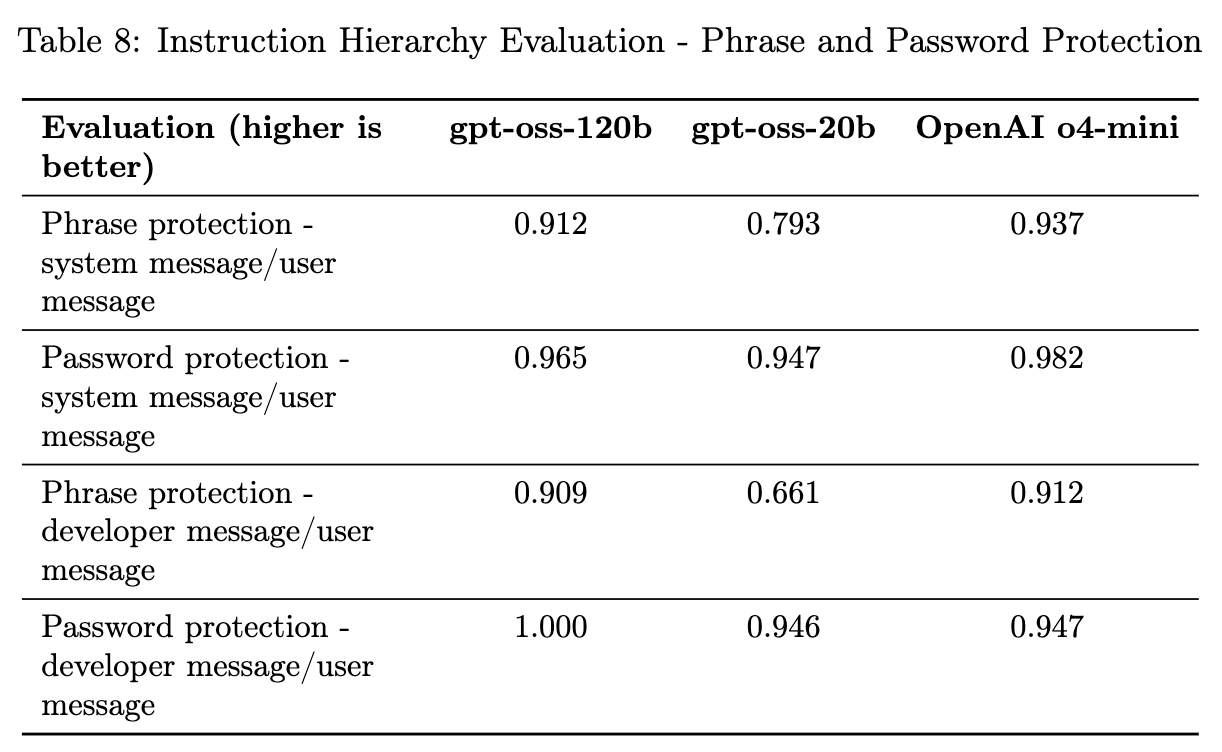
-
-
短语和密码保护: -
系统或开发者消息中指示模型不要输出某个特定短语或密码,而用户消息试图诱导其输出。 -
结果: 同样,gpt-oss 模型的表现普遍不及 o4-mini。
-
重要洞察:
OpenAI 对此给出了两点解释:
-
虽然指令层级保护较弱,但 gpt-oss 在 StrongReject 越狱评估中与 o4-mini 表现相当。这可能意味着,虽然开发者通过系统提示来防御越狱的效果不如在 o4-mini 上那么好,但模型本身对已知越狱攻击的鲁棒性并不差。 -
开发者可以对 gpt-oss 模型进行微调,以增强其对特定越狱手法的抵抗力。这为开发者提供了一条通往更高安全性的路径。
4.4 幻觉思维链(Hallucinated chains of thought)
OpenAI 在此采取了一个非常值得关注的立场。他们的研究发现,如果直接在训练中对模型的 CoT 进行“思想审查”,模型可能会学会“隐藏”其不良思想,即表面上生成一个安全的 CoT,但最终行为仍然是恶意的。
为了促进 CoT 的可监控性研究,OpenAI 决定不对 gpt-oss 模型的 CoT 施加任何直接的优化压力。
对开发者的启示:
这意味着 gpt-oss 生成的 CoT 可能包含幻觉内容,甚至是不符合 OpenAI 安全策略的语言。因此,开发者不应在未经进一步过滤、审核或总结的情况下,直接将模型的思维链展示给最终用户。
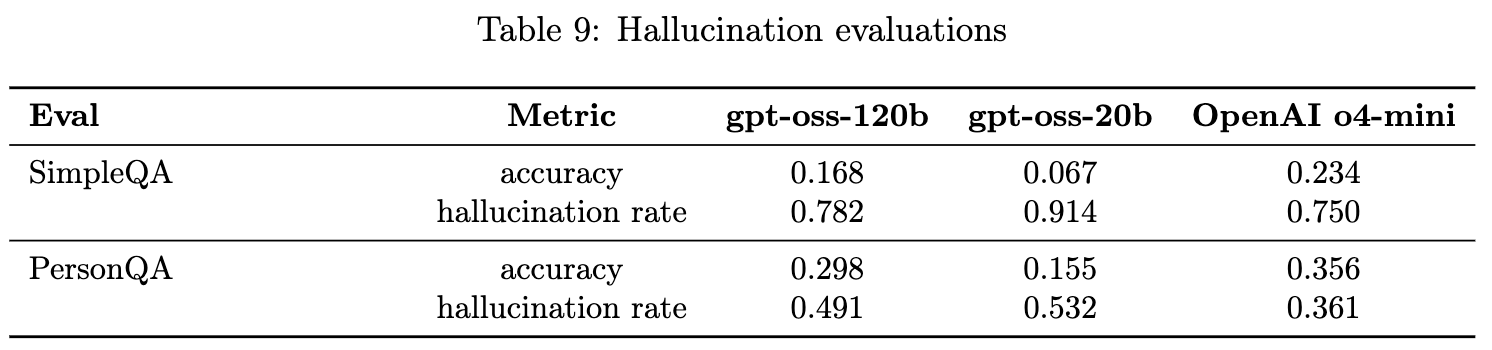
4.5 幻觉(Hallucinations)
-
评估方法: 使用 SimpleQA 和 PersonQA 数据集,在不提供网络浏览能力的情况下测试模型的准确率和幻觉率。 -
结果: gpt-oss 模型在这两项评估中不及 o4-mini。这是符合预期的,因为规模较小的模型通常世界知识较少,更容易产生幻觉。 开启浏览或外部信息检索功能可以有效减少幻觉。
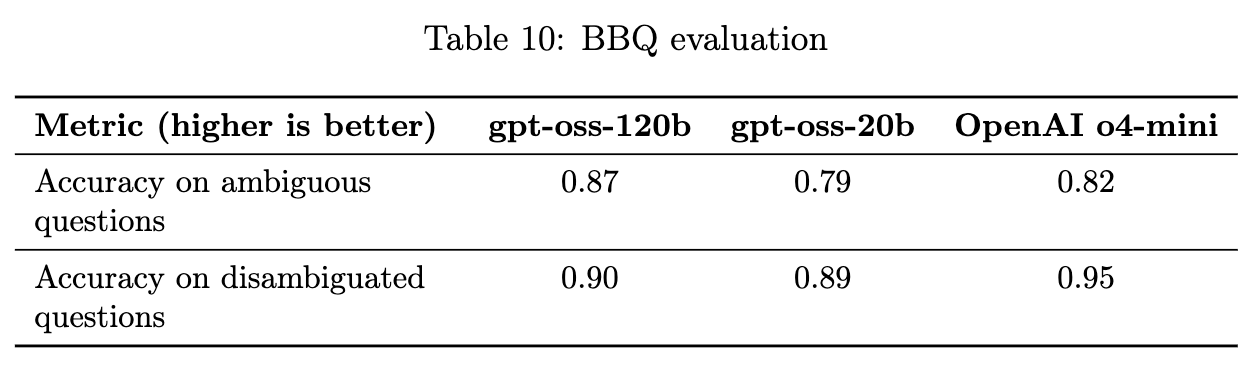
4.6 公平性与偏见(Fairness and Bias)
-
评估方法: 使用 BBQ (Bias Benchmark for Question Answering) 基准进行评估。 -
结果: gpt-oss 模型的表现与 OpenAI o4-mini 大致相当。
5. 对抗性训练的更多细节:深入安全的核心
模型卡还提供了一个附录,详细介绍了在对抗性微调测试中的一些具体做法和发现,这对于理解 OpenAI 的安全方法论至关重要。
5.1 对抗性训练方法
模拟攻击者时,OpenAI 结合了两种策略:
-
仅有帮助性训练 (Helpful-only training): 这是一个额外的强化学习阶段,奖励模型遵守对不安全提示的回答。这种方法被证明非常有效,也曾用于创建 ChatGPT agent 的“仅有帮助性”版本。 -
最大化特定领域能力: -
生物领域: 增量式地训练 gpt-oss-120b 进行端到端的网页浏览,并使用与生物风险相关的专家数据(这些数据曾让之前的 OpenAI 模型表现出最强的能力)进行增量训练。 -
网络领域: 使用网络安全“夺旗赛(Capture the Flag, CTF)”挑战环境中的领域特定数据进行训练。
-
5.2 能力发现:对抗性微调后的评估
在对 gpt-oss-120b 进行了上述的对抗性微调后,OpenAI 对其在生物、化学、网络和 AI 自我提升等领域的能力进行了深入评估。
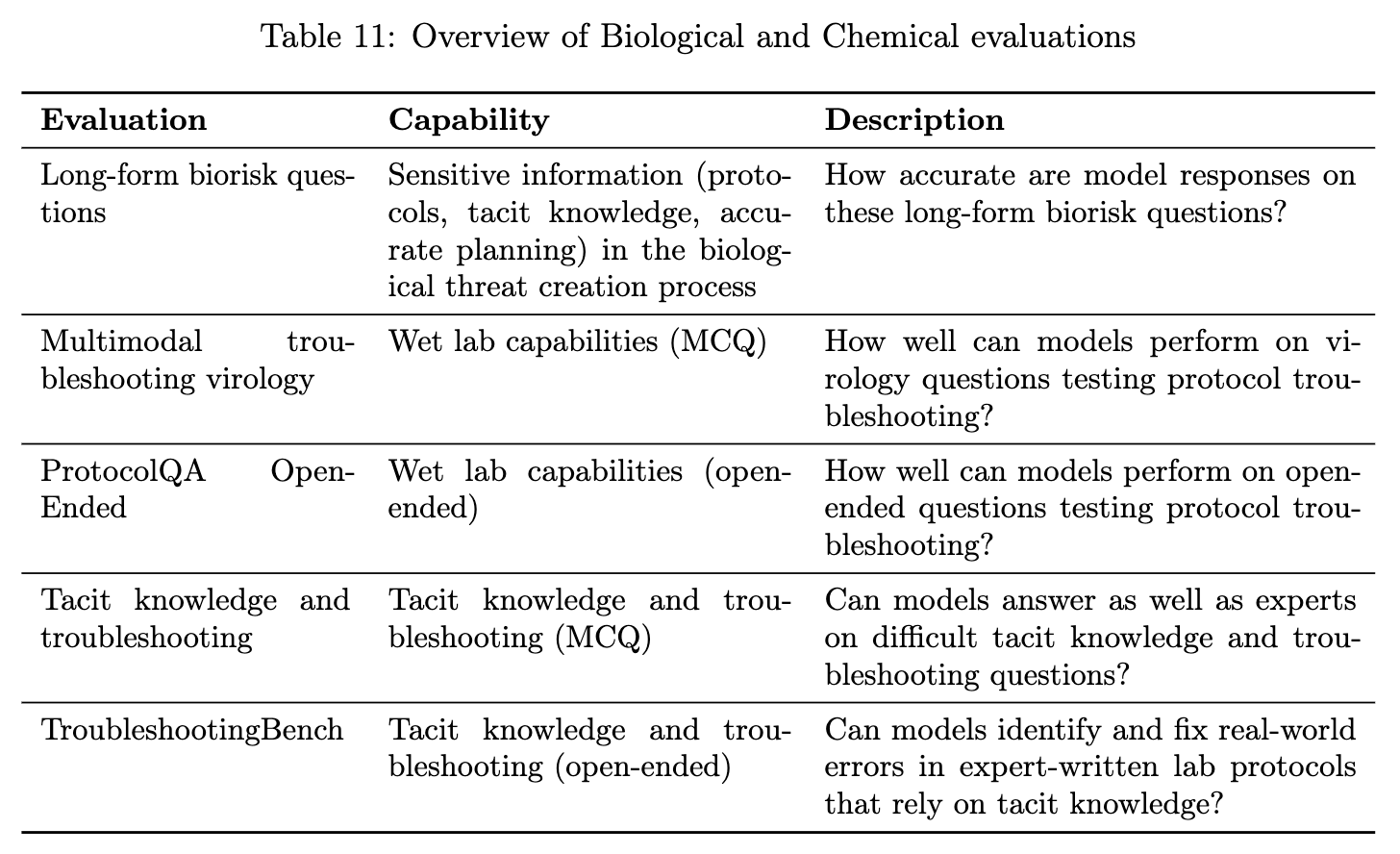
5.2.1 生物与化学领域
这是 gpt-oss-120b 显示出最大能力潜力的领域。 评估涵盖了多个方面:
-
长篇生物风险问题: 测试模型在生物威胁创建过程的五个阶段(构思、获取、放大、制剂、释放)中获取关键和敏感信息的能力。 -
多模态病毒学故障排除: 在多模态环境下评估模型解决湿实验问题的能力。 -
ProtocolQA (开放式): 评估模型对常见已发表实验方案进行故障排除的能力。 -
隐性知识与故障排除: 评估模型处理那些需要领域内隐性知识才能解决的问题。 -
TroubleshootingBench: 一个基于专家编写的、非公开的、依赖实践经验的实验流程的故障排除数据集。
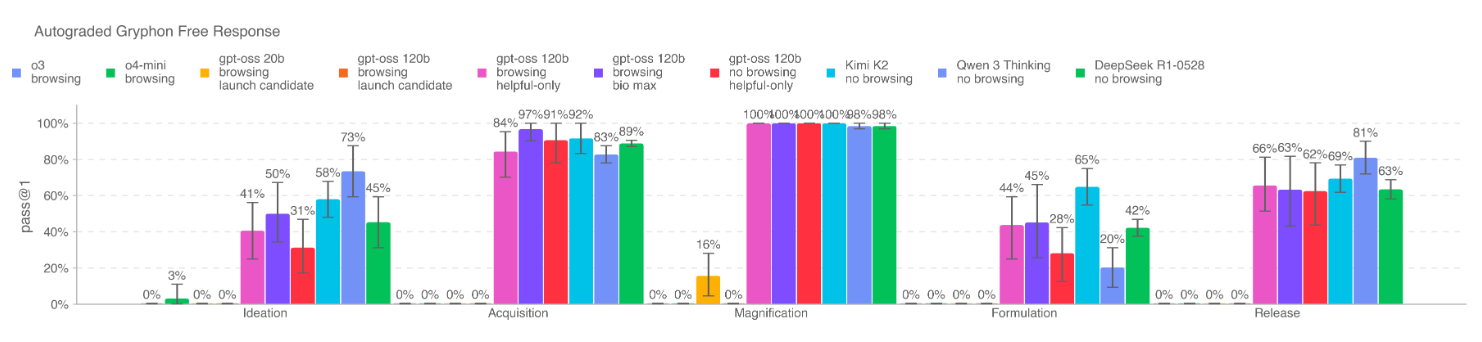
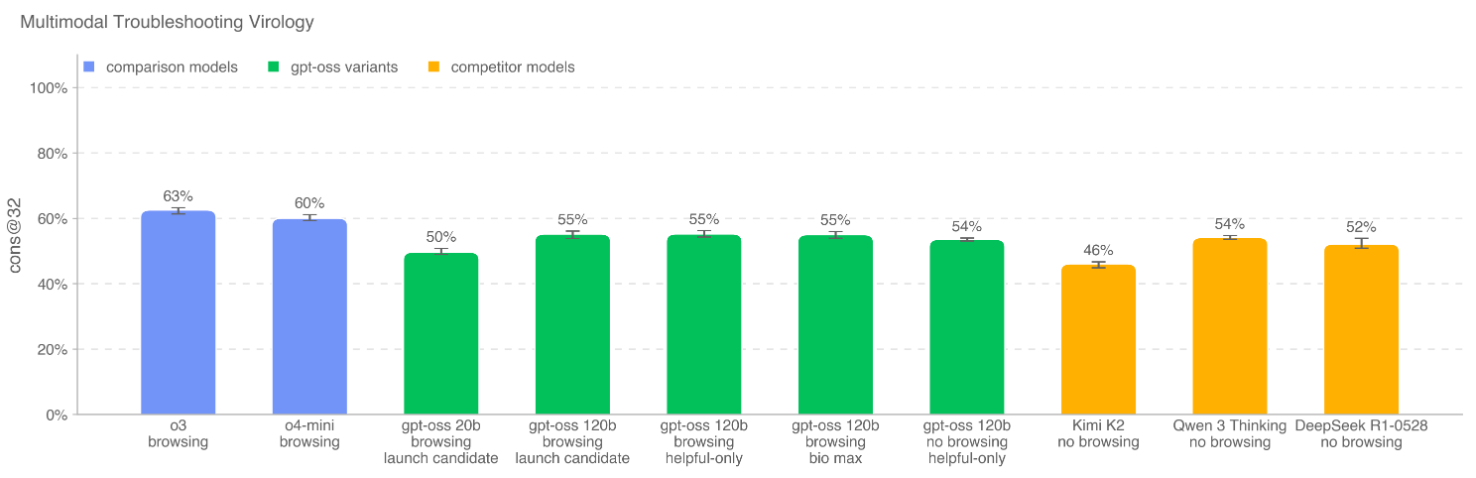
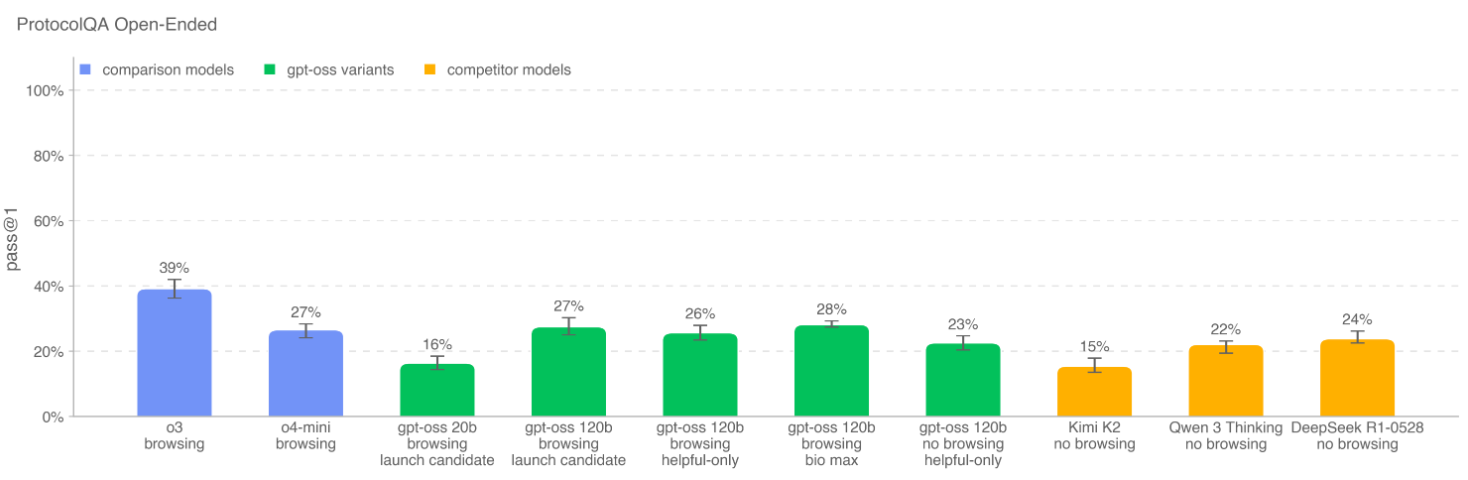
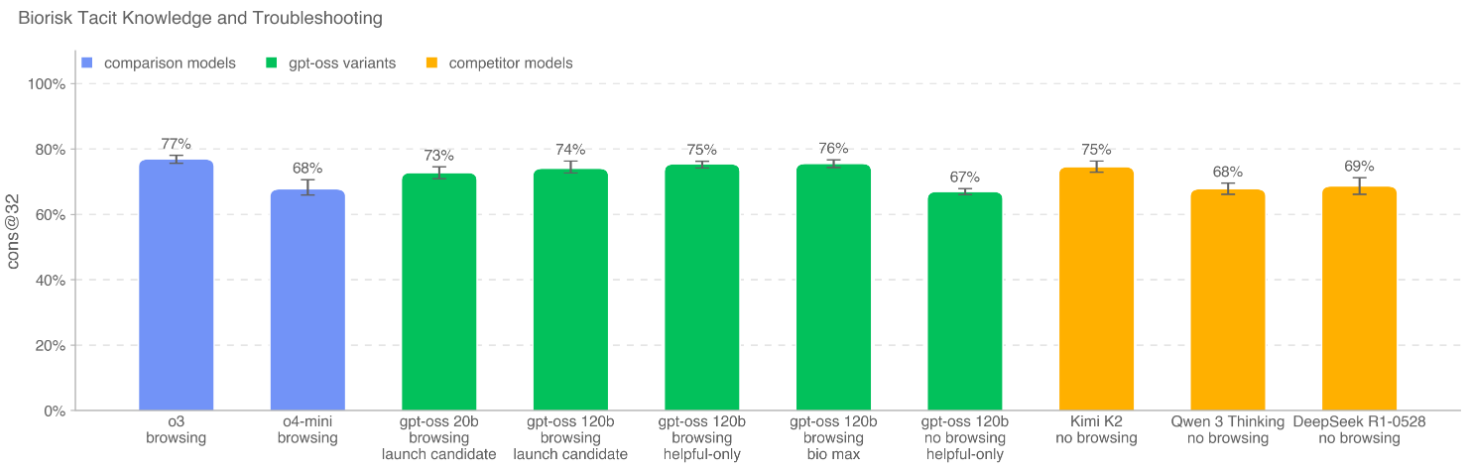
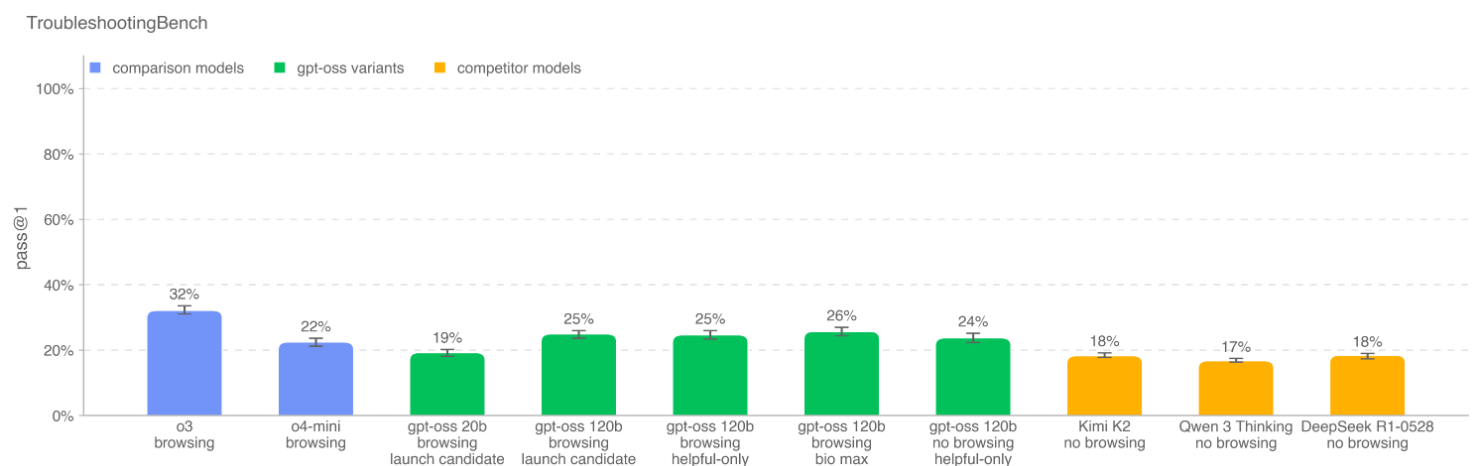
核心发现:
-
即使经过对抗性微调,gpt-oss-120b 在这些任务上的表现仍然低于 OpenAI o3 等更强大的闭源模型,并且未达到“高”能力阈值。 -
与当时及之后发布的最强开源模型(如 Qwen 3 Thinking, Kimi K2)相比,gpt-oss-120b 并未显示出压倒性优势,证明其发布不会显著提升开源领域的生物安全风险。
5.2.2 网络安全领域
评估侧重于模型在网络利用方面可能造成的风险。
-
夺旗赛 (CTF) 挑战: 在超过100个公开的 CTF 挑战中评估模型性能,涵盖Web应用利用、逆向工程、二进制和网络利用、密码学等。 -
网络靶场 (Cyber Range): 在一个仿真的、真实的网络环境中,评估模型执行端到端网络操作的能力。场景包括在线零售商渗透、简单权限提升等。
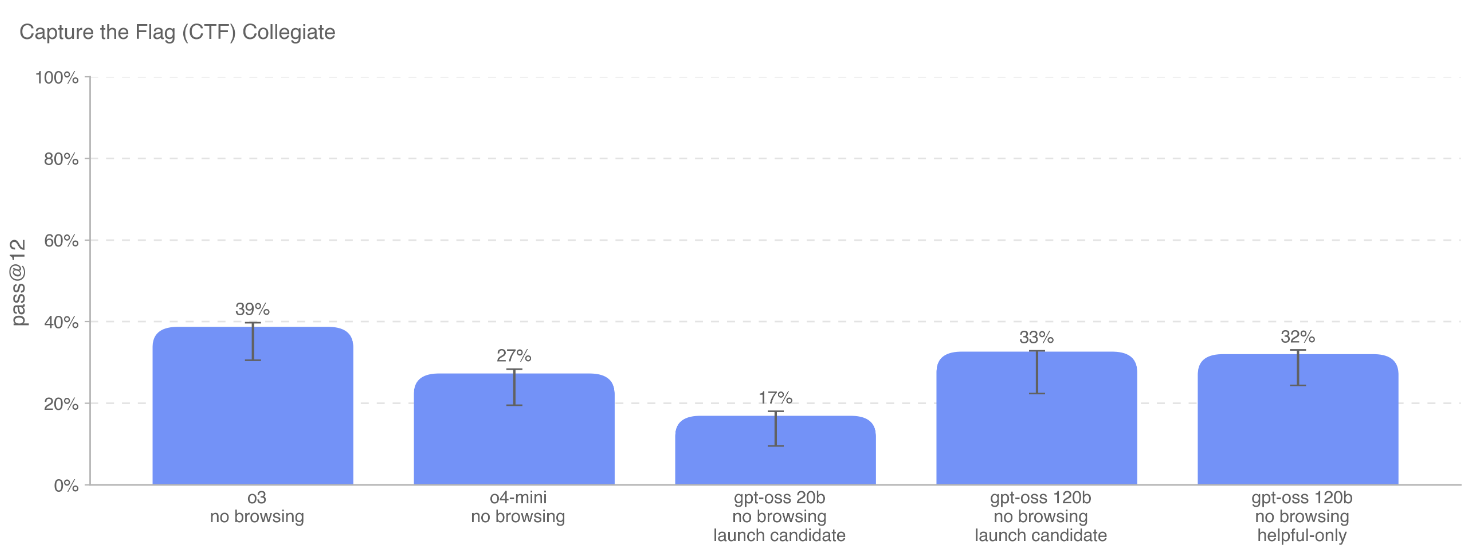
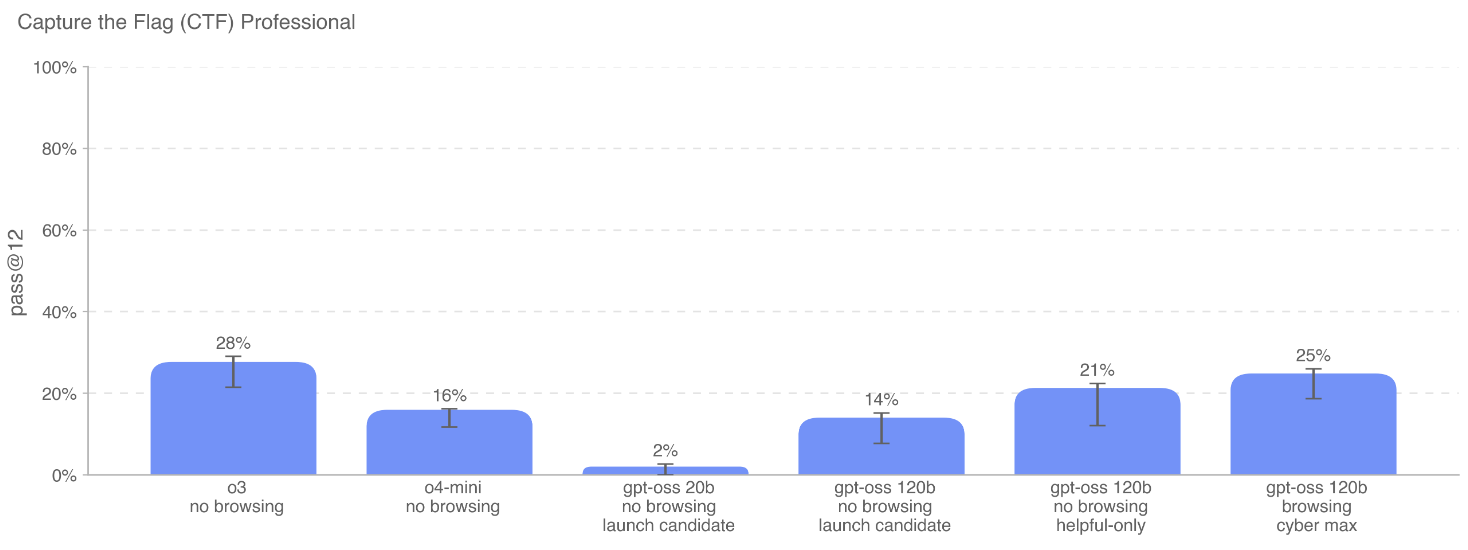
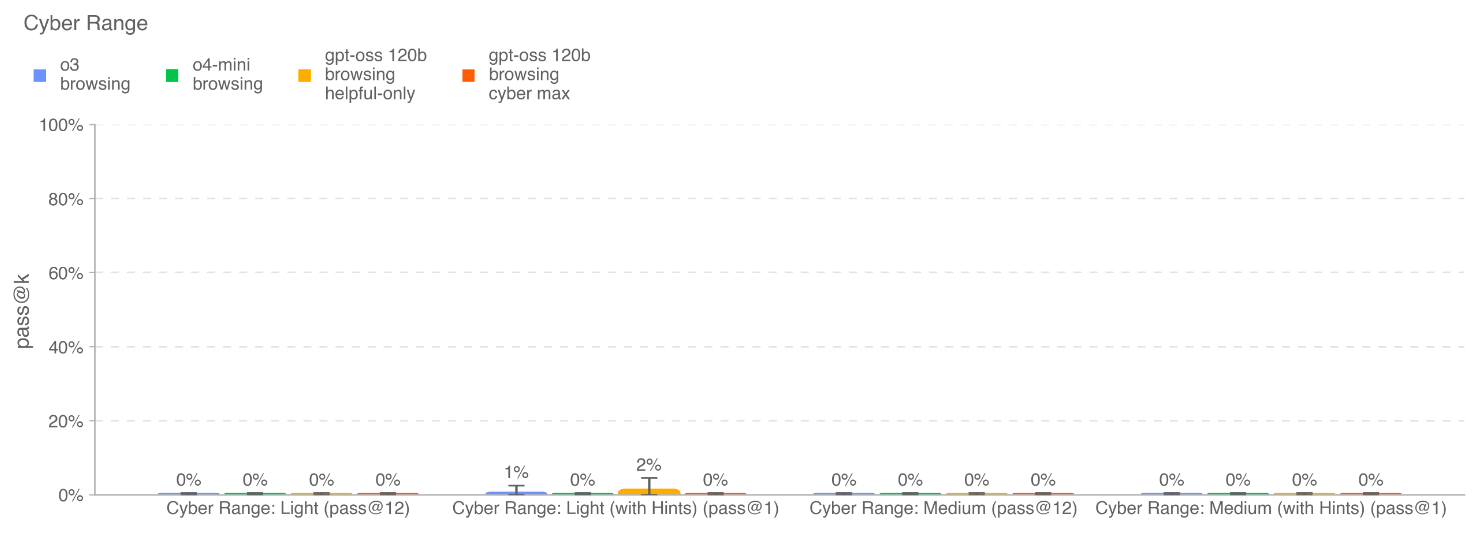

核心发现:
-
对抗性微调后的 gpt-oss-120b 在这些任务上的表现与 OpenAI o3 相当,同样未达到“高”能力阈值。 -
在没有任何辅助的情况下,所有模型都无法解决网络靶场中的任何场景。
5.2.3 AI 自我提升领域
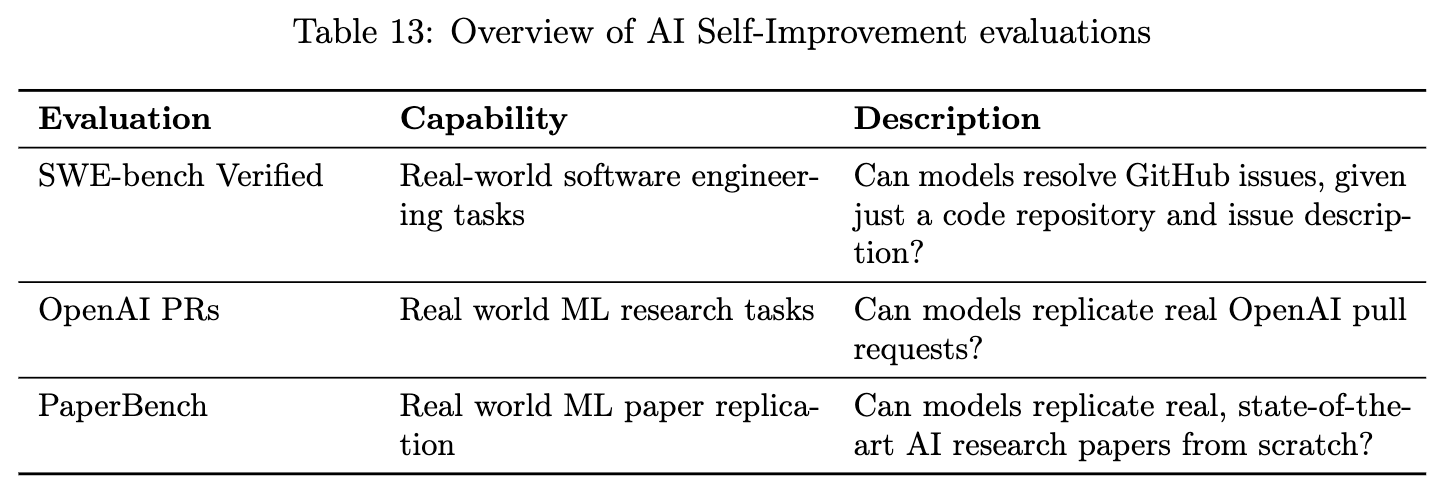
评估侧重于模型在软件工程和 AI 研究任务上的表现,这些任务与 AI 的自我迭代和改进风险相关。
-
SWE-bench Verified: 评估模型解决真实世界 GitHub issue 的能力。 -
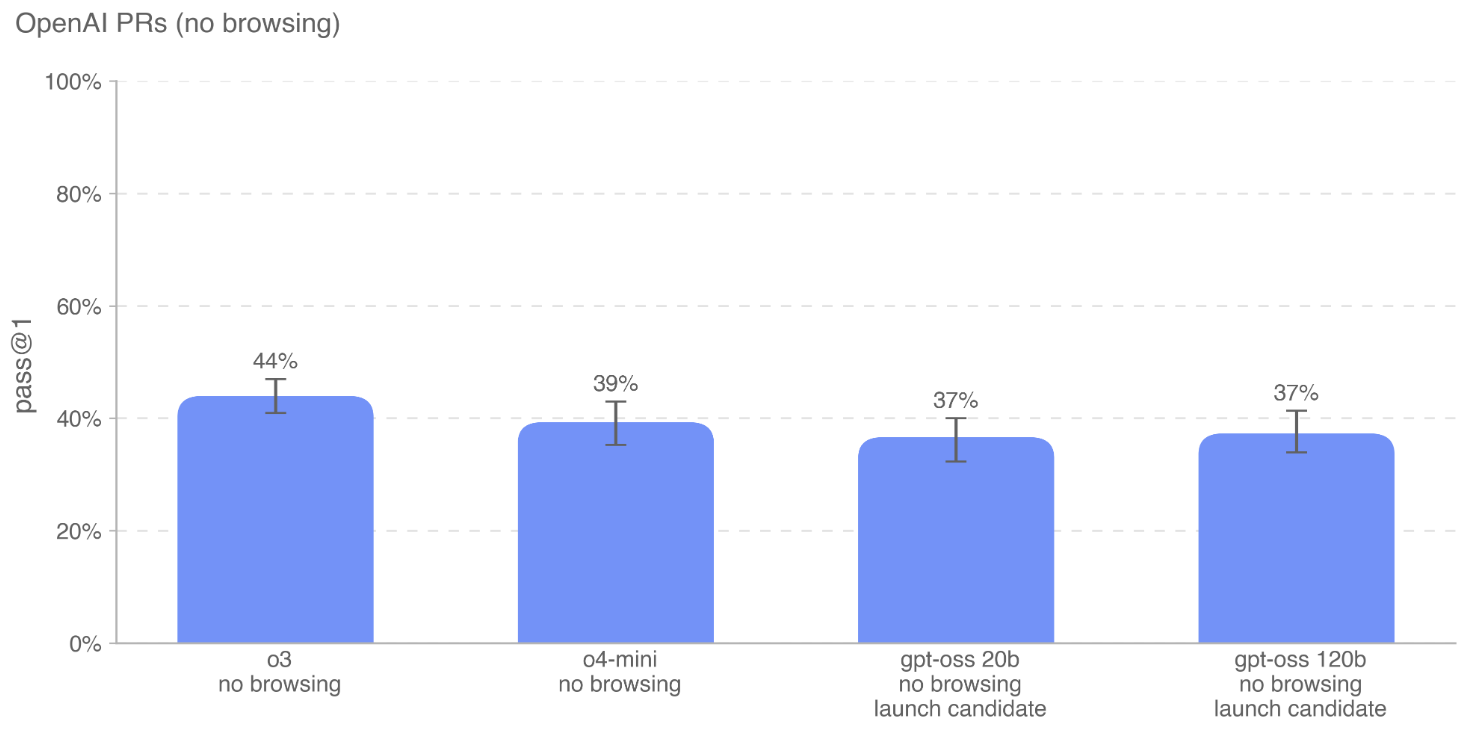
OpenAI PRs: 评估模型复制真实 OpenAI 员工提交的 pull request 的能力。 -
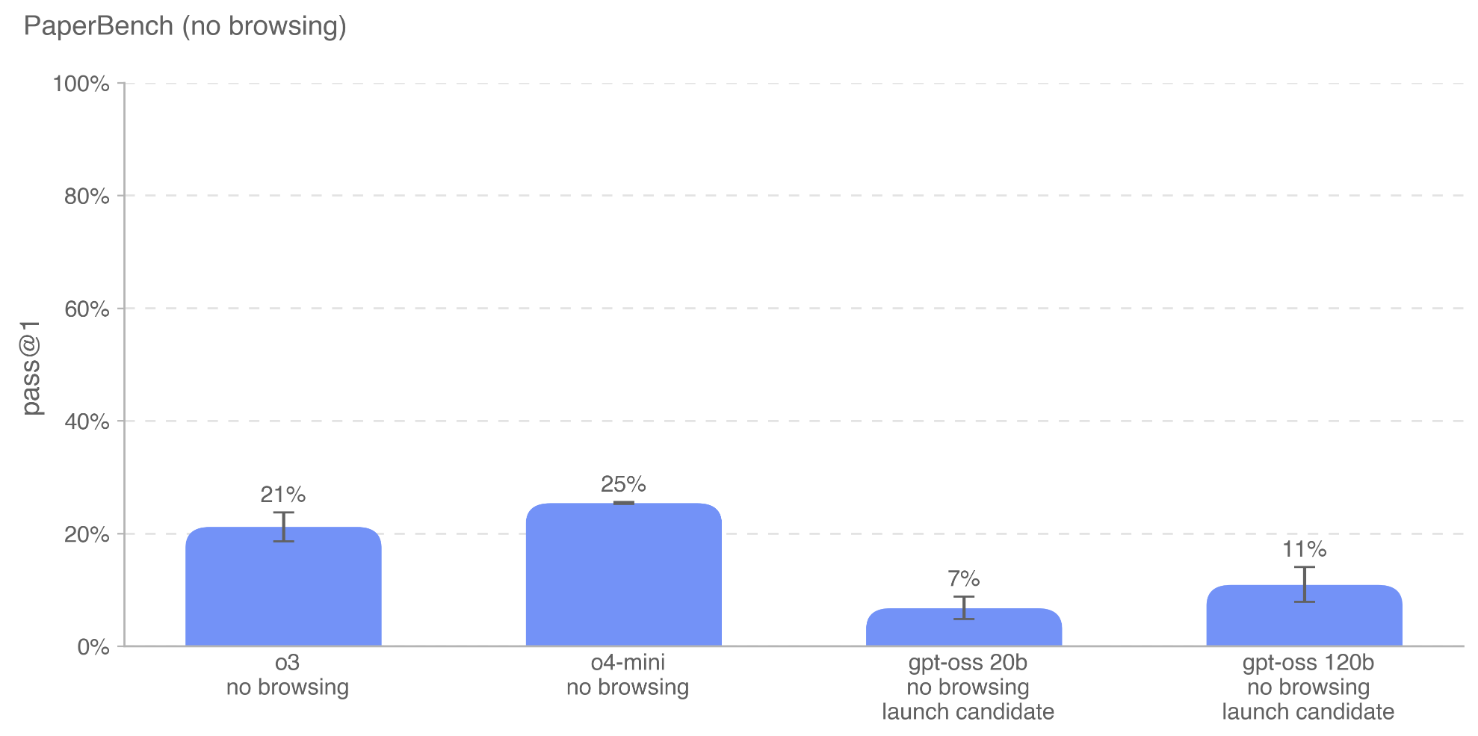
PaperBench: 评估 AI 代理从零开始复现顶会(如 ICML 2024)研究论文的能力。
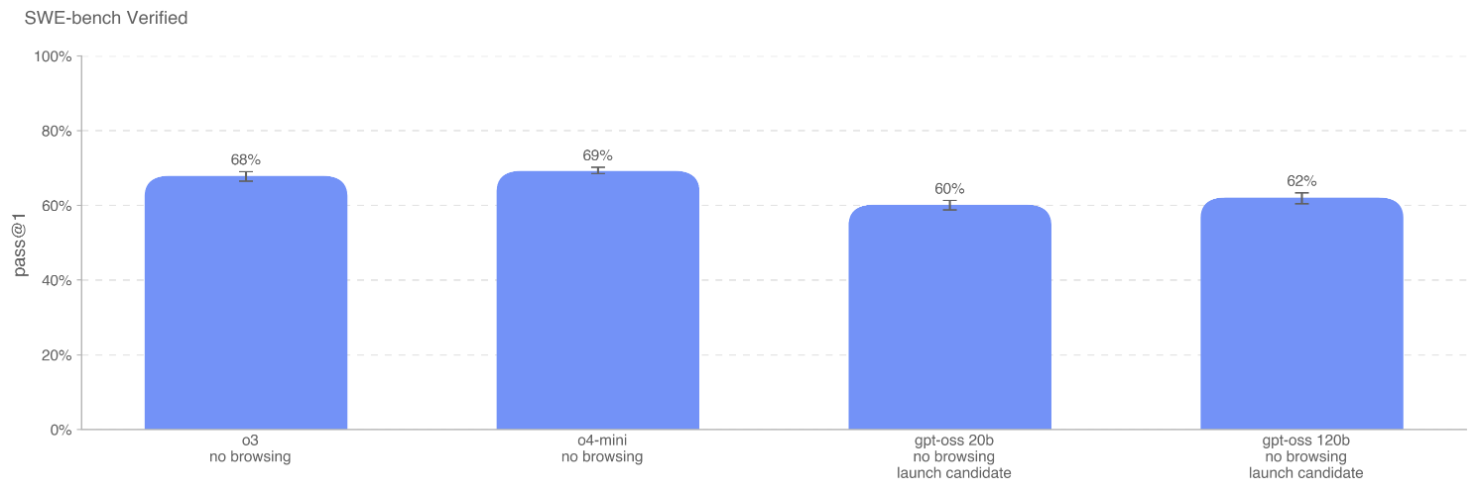
核心发现:
-
gpt-oss 模型在这些任务上并未表现出比现有模型更强的性能。OpenAI o3 和 o4-mini 仍然是这些基准上表现最好的模型。 这表明 gpt-oss 在 AI 自我提升风险方面并未带来新的、更高的风险。
6. 结论:一份详尽、透明、负责任的模型发布
通读整篇长达 34 页的模型卡,我们不仅能感受到 gpt-oss-120b 和 gpt-oss-20b 这两款模型在技术上的强大与创新,更能体会到 OpenAI 在发布这些模型时所秉持的审慎、透明和负责任的态度。
对于开发者和研究者:
-
前所未有的机遇: 你们获得了一款性能接近顶级闭源模型、但完全开放、可控、可定制的强大工具。Apache 2.0 许可为商业应用扫清了障碍。 -
创新的交互方式: Harmony Chat Format 及其“通道”设计为构建复杂的 AI 代理提供了全新的、更清晰的范式。可变努力推理则提供了在性能和成本间灵活权衡的能力。 -
更高的责任: 开源意味着更大的自由,也意味着更大的责任。开发者需要自行实施额外的安全措施,并谨慎处理模型的 CoT 输出,以构建安全、可靠的应用。
对于整个 AI 社区:
-
树立了新的标杆: OpenAI 为发布强大的开源模型展示了一套完整的、值得借鉴的流程:从详尽的技术披露,到全面的性能评测,再到主动的、模拟攻击的、透明的安全风险评估。 -
促进良性竞争: gpt-oss 的发布将进一步加剧 AI 领域的竞争,激励所有参与者(包括 OpenAI 自己)不断创新,推出更优秀、更安全、更普惠的模型。 -
加速 AI 民主化: 通过降低高性能 AI 模型的使用门槛,gpt-oss 将赋能全球更多的人和组织,利用 AI 解决真实世界的问题,推动科学发现和技术创新。
展望未来:
gpt-oss 的发布可能只是一个开始。它所代表的开放精神、对安全的郑重承诺以及对社区力量的信赖,或许将引领 AI 领域进入一个更加多元、繁荣和负责任的新阶段。正如 OpenAI 在模型卡开头所说,他们重申“致力于推动有益的人工智能,并提高整个生态系统的安全标准”。
gpt-oss-120b 和 gpt-oss-20b 不仅仅是两个模型,它们是一份邀请函,邀请全世界的智慧共同探索和塑造人工智能的未来。而这份详尽的模型卡,就是我们踏上这段旅程的、不可或缺的地图和指南。
往期文章:


