
-
论文标题:Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning -
论文链接:https://arxiv.org/pdf/2601.09088v1
TL;DR
今天解读一篇阿里云团队近期发布的论文《Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning》。该工作针对当前大语言模型(LLM)推理能力蒸馏中普遍采用的“基于教师生成数据的监督微调(SFT)”范式进行了理论反思与方法改进。作者指出,现有的SFT蒸馏方法往往仅被视为一种数据过滤过程,而忽略了蒸馏的核心目标——序列级分布匹配(Sequence-Level Distribution Matching)。
基于此,论文提出了DASD(Distribution-Aligned Sequence Distillation)框架,包含三个核心改进:
-
温度调度学习(Temperature-scheduled Learning):通过从低温到高温的渐进式采样,平衡模式覆盖率与学习难度。 -
差异感知采样(Divergence-aware Sampling, DAS):通过比较教师与学生的概率分布,优先筛选教师置信度高但学生置信度低的样本(即“教师主导的句子”),以最大化信息增益。 -
混合策略蒸馏(Mixed-policy Distillation):结合学生生成的前缀与教师的续写,缓解教师强制(Teacher Forcing)训练与自回归推理之间的暴露偏差(Exposure Bias)。
实验结果显示,基于Qwen3-4B的DASD模型(DASD-4B-Thinking)在AIME24、GPQA-Diamond和LiveCodeBench等基准测试中,以仅448K的训练数据量,达到了同等规模模型的SOTA水平,并在部分指标上超过了32B规模的模型。
1. 背景
1.1 现有范式的局限性
随着DeepSeek-R1等工作的发布,通过蒸馏(Distillation)将强大教师模型(Teacher Model)的推理能力迁移至小规模学生模型(Student Model)已成为社区的研究热点。目前主流的做法是序列级蒸馏(Sequence-Level Distillation),具体表现为:收集教师模型针对复杂问题生成的长思维链(Long-CoT)响应,经过正确性验证或启发式过滤后,对学生模型进行监督微调(SFT)。
这种方法虽然简单有效,但论文作者认为,当前的研究大多局限于“SFT视角”,即过度关注如何设计启发式规则来过滤高质量数据,而忽略了“蒸馏视角”的核心原则。经典的知识蒸馏(Hinton et al., 2015)旨在让学生模型学习教师的输出分布。然而,直接对教师生成的样本进行SFT,存在三个主要问题:
-
教师分布的代表性不足(Inadequate representation):通常使用的随机采样策略往往只能覆盖教师分布的一小部分模式,无法充分利用教师模型中蕴含的潜在知识。 -
分布与能力的错配(Misalignment):教师生成的某些高难度或噪声样本可能超出了学生模型当前的学习能力,或者学生模型在某些样本上已经具备了足够的能力,继续训练带来的边际收益递减。 -
暴露偏差(Exposure Bias):SFT训练时使用Teacher Forcing(即输入为教师生成的Ground Truth前缀),而推理时学生模型需自回归生成。这种训练与推理的不一致导致学生模型在脱离教师引导后容易产生误差累积。
1.2 理论框架
为了厘清SFT与蒸馏的关系,论文首先回顾了序列级蒸馏的数学本质。给定输入 ,序列级蒸馏的目标是最小化教师模型分布 与学生模型分布 之间的KL散度:
其中 是所有可能响应的集合。展开KL散度公式:
由于 仅与教师相关,不影响梯度,目标简化为:
由于输出空间 的指数级大小,直接计算该期望是不可行的。通常采用蒙特卡洛近似,即使用采样得到的样本 来代替整个分布,此时 被近似为一个点质量分布(Point Mass):
这导出了我们熟悉的SFT损失函数:
这个推导表明,SFT本质上是序列级蒸馏的一种近似形式。因此,SFT的效果取决于采样样本 能否有效代表教师的分布 ,以及这个分布是否适合学生模型 学习。论文的核心论点即在于:我们需要更好的采样策略来提升这种近似的质量,而不仅仅是过滤“正确”的答案。
2. DASD
为了解决上述问题,论文提出了DASD框架,包含三个递进的模块。
2.1 温度调度学习
问题分析:
如何选择采样温度是一个权衡。
-
低温采样(如 T=0.6):教师分布尖锐,样本集中在高概率区域,质量一致性高,易于学生学习。但模式单一,信息量有限。 -
高温采样(如 T=1.0):教师分布平坦,覆盖更多长尾模式(Modes),多样性强。但包含更多噪声,且对于能力较弱的学生模型而言,学习难度大,收敛慢。
论文图3展示了实验观察:在高温数据上训练虽然收敛慢、Loss高,但最终在AIME25等复杂基准上的性能明显优于低温数据训练(+4.2分)。这表明覆盖更广的教师模式对提升推理泛化能力至关重要。
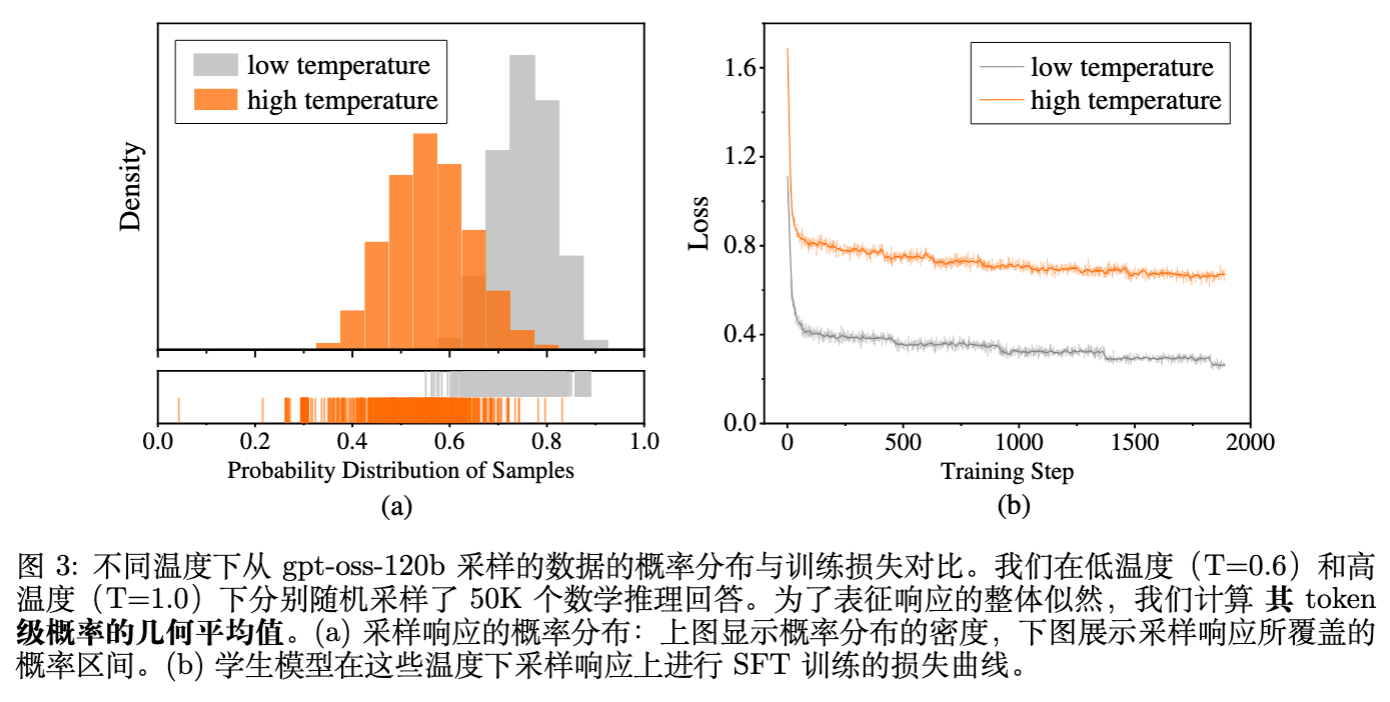
解决方案:
受课程学习(Curriculum Learning)和模拟退火(Simulated Annealing)的启发,作者提出了一种“反向退火”的策略:
-
阶段一(Cold Start):使用低温采样数据(T=0.6)进行SFT。目的是让学生模型快速掌握基本的推理模式和格式,建立稳定的梯度信号。 -
阶段二(Scale Up):基于阶段一的检查点,混合高温采样数据(T=1.0)继续训练。目的是在已有基础上扩展模型的分布覆盖范围,学习更复杂的推理路径。
这种策略有效地结合了低温数据的易学性和高温数据的丰富性。
2.2 差异感知采样
这是论文最核心的贡献。在传统的Logit蒸馏中,教师会针对每一个Token提供完整的概率分布,告诉学生“应该提高哪个Token的概率,降低哪个Token的概率”。但在SFT蒸馏中,学生只看到一个硬标签(Hard Label),SFT损失函数会无条件地推高样本中所有Token的概率。
核心矛盾:
如果教师生成的某个Token本身在教师分布中概率并不高(例如在高温采样下产生的低概率词),或者该Token对学生来说已经是高概率词,那么盲目地通过SFT推高其概率可能会导致梯度误导(Misleading Gradients)或无效学习。
分布分解框架:
为了找到对学生学习最有价值的样本,作者提出了一个基于句子级概率差异的分析框架。对于教师生成的响应中的每一个句子,分别计算其在教师模型 、学生模型 (蒸馏前)和蒸馏后学生模型 下的生成概率。
根据 和 的相对大小,可以将句子分为四类(见图5):
-
教师主导的句子:。教师置信度高,但学生置信度低。这意味着该句子包含了学生尚未掌握的教师知识。 -
学生主导的句子:。学生置信度高,但教师置信度低。这通常意味着学生过拟合了某种偏差,或者是教师认为不太好的路径。 -
共享句子:。两者置信度都差不多(通常较高)。这部分知识学生已经掌握,继续学习收益较小。 -
增强句子:蒸馏后 显著升高,但初始 和 都不高。这通常是训练过程产生的副产品。
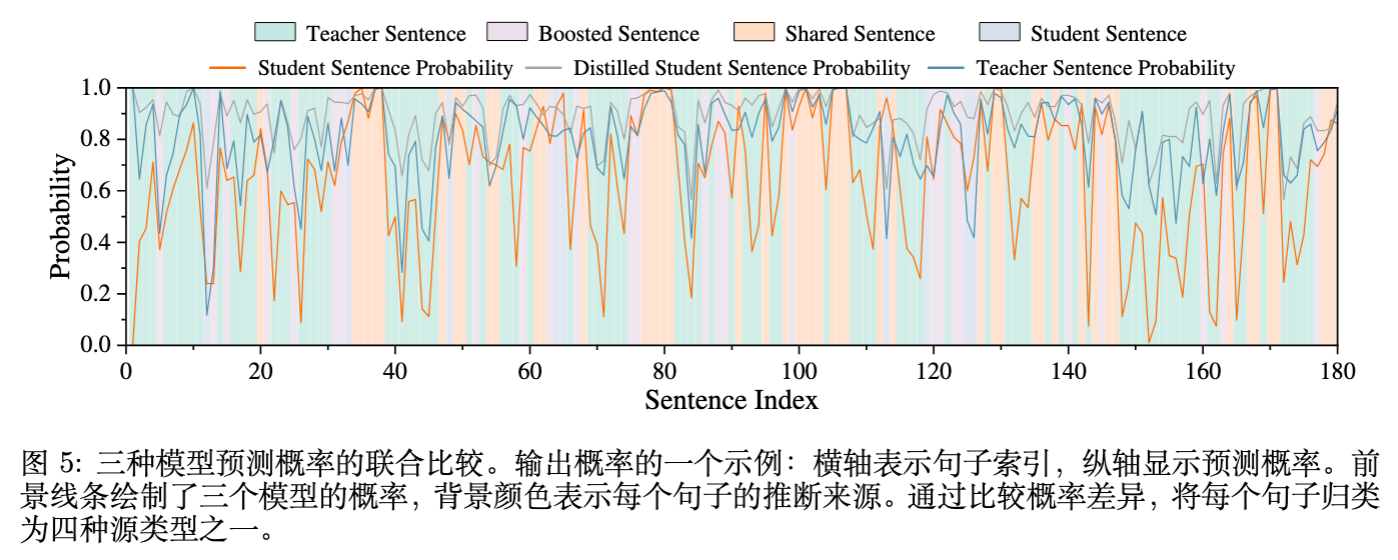
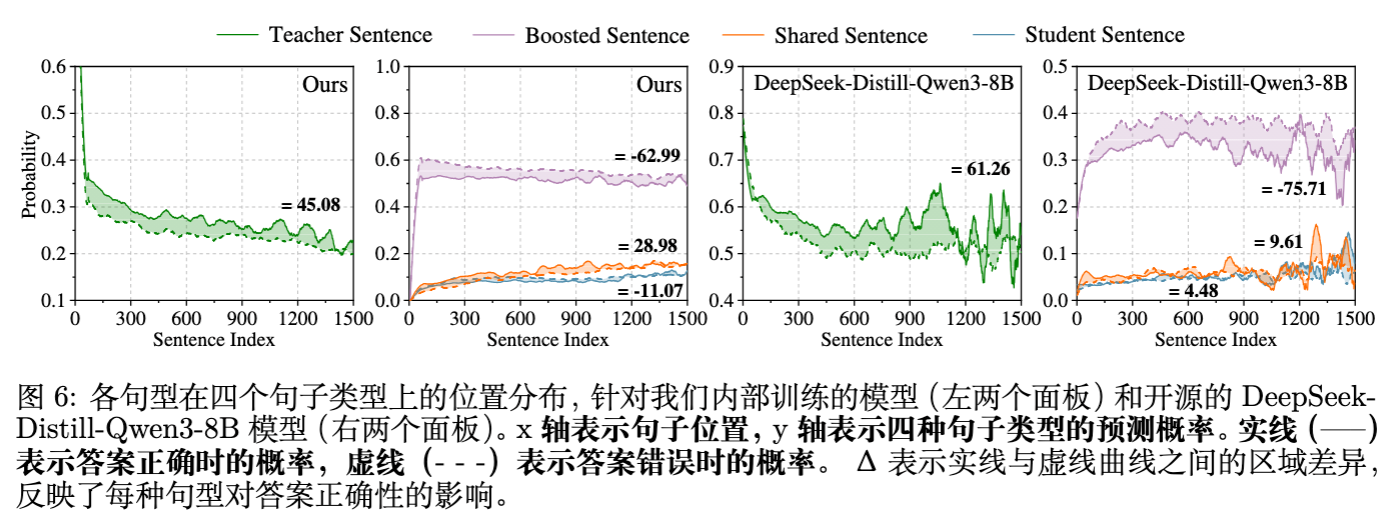
实证发现:
作者分析了句子类型与最终答案正确性的相关性(图6)。结果发现:“教师主导的句子”(Teacher Sentences)在正确答案中的出现频率显著高于错误答案,且其概率提升与模型性能提升呈现最强的正相关。
换句话说,蒸馏最有效的部分在于让学生学会那些“教师认为很大概率、但学生认为很小概率”的推理步骤。这符合信息论中信息增益的直觉。
DAS算法实现:
基于上述发现,DAS策略的具体做法是:
在从教师模型采样生成多个候选响应(Candidate Responses)后,不使用随机采样或仅基于答案正确性的过滤,而是计算每个响应中所有Token的 和 。优先选择包含更多“教师主导句子”的响应进行训练。
具体指标可以是整个序列中 的累积或平均值。这种方法不需要训练额外的奖励模型,也不需要Ground Truth标签(虽然通常会结合正确性过滤),仅利用了生成时的概率信息。
优势:
-
梯度安全性:优先学习 的样本,避免了对低 样本进行SFT可能带来的分布偏离。 -
数据效率:通过筛选高信息量样本,可以在更少的数据量下达到更好的效果。 -
通用性:不需要Logit对齐,即使Tokenizer不同也可以通过计算对应文本段的概率来实现(尽管论文实验中是Token级别的对比,但原理可扩展)。
2.3 混合策略蒸馏
前两步主要关注如何更好地从教师处获取知识(Off-Policy),但学生模型最终需要独立进行自回归生成。仅依靠SFT,学生模型在推理阶段产生的微小误差会随着序列增长而累积,导致状态分布偏离训练数据的分布(即暴露偏差)。
现象观测:
论文图7显示,随着生成长度的增加,学生模型生成的内容被教师模型截断(Cut-off,即认为偏离合理路径)的比例显著增加。这证实了长思维链推理中暴露偏差的严重性。
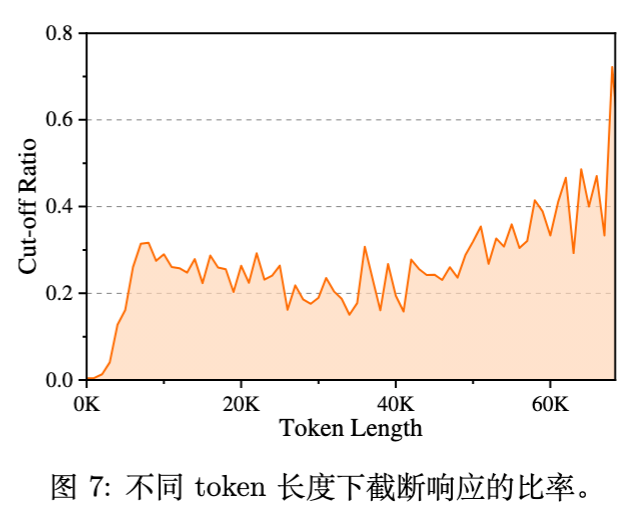
解决方案:
为了缓解这一问题,作者引入了一个轻量级的混合策略微调阶段:
-
学生生成:让经过前两阶段训练的学生模型针对训练集问题生成响应。 -
随机截断与续写:根据教师生成的参考长度,将学生生成的响应在中间随机截断。 -
教师修正:将截断后的前缀(Prefix)输入教师模型,让教师完成后续的推理步骤。 -
过滤与训练:保留教师成功修正并得出正确答案的样本,将其加入训练集进行微调。
这种方法的精髓在于构建了“学生犯错前兆 + 教师正确修正”的数据对。它让学生模型见识到了由自身策略产生的部分轨迹(On-Policy分布),并学习如何从这些中间状态回归到正确的推理路径上。这是一种构造性的(Constructive)混合策略,比纯粹的On-Policy拒绝采样(Rejection Sampling)更具指导意义。
3. 实验
3.1 数据集构建
-
数据来源: -
数学:AIME, AMC, NuminaMath, AoPS论坛等。 -
代码:CodeContests, APPs, Codeforces, TACO等。 -
科学推理:OpenScienceReasoning。 -
指令遵循:由教师模型生成的复杂指令。
-
-
规模:总共收集了约448K条经过DAS筛选的高质量训练样本。相比OpenThoughts(1.2M)、OpenReasoning-Nemotron(30M)等工作,该数据量级非常小,体现了方法的效率。
3.2 教师与学生模型
-
学生模型:Qwen3-4B-Instruct-2507(及后续验证的Qwen3-30B MoE版本)。选择4B模型是因为它在轻量级部署上的潜力,且具有一定的基础能力。 -
教师模型:gpt-oss-120b。这是一个强大的闭源模型,代表了当前的强推理能力。
3.3 训练流程
-
数据采样: -
低温(T=0.6):105K样本。 -
高温(T=1.0):330K样本。 -
均采用DAS策略筛选。
-
-
阶段一训练:使用低温数据微调学生模型。 -
阶段二训练:加载阶段一权重,混合高温数据继续微调。学习率从 5e-5 衰减至 1e-5。 -
阶段三(混合策略):使用约12.7K条混合策略数据进行少量步骤的微调。
3.4 过滤规则
除了DAS,常规的工程化过滤也是必不可少的:
-
长度过滤:移除超过上下文窗口的样本。 -
结构过滤:移除包含函数调用(Function Call)的样本(专注于纯CoT),确保包含 <think>标签。 -
重复内容过滤:通过N-gram和正则匹配移除陷入循环生成的样本(长CoT常见问题)。
4. 实验结果分析
论文在五个主要基准上进行了评估:AIME24/25(高难度数学)、GPQA-Diamond(研究生级科学问答)、LiveCodeBench (LCB) v5/v6(代码生成)。
4.1 核心性能对比
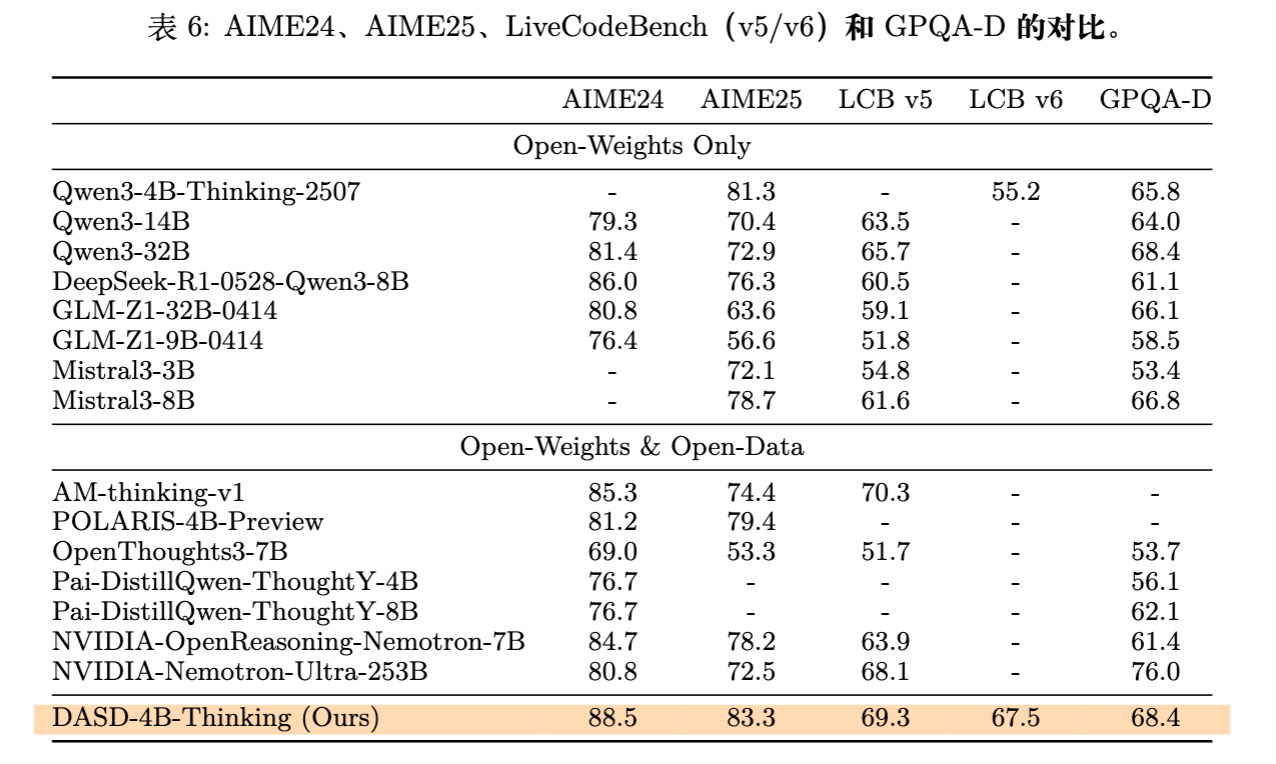
主要结论:
-
超越同级模型:DASD-4B-Thinking在所有测试基准上均显著优于同参数量级的开源模型,如Qwen3-4B-Instruct、Mistral-3B等。 -
AIME25: 83.3% (vs Qwen3-4B 81.3%) -
GPQA-Diamond: 68.4% (vs Qwen3-4B 65.8%)
-
-
越级挑战:该模型甚至击败了许多32B规模的模型。 -
在AIME25上,DASD-4B (83.3%) 优于 Qwen3-32B (72.9%) 和 GLM-Z1-32B (63.6%)。 -
在Code (LCB v5) 上,DASD-4B (69.3%) 优于 Qwen3-32B (65.7%)。
-
-
数据效率:相比于使用30M数据的Nemotron-7B或2.9M数据的AM-Thinking,DASD仅使用448K数据就达到了甚至更高的分数。这强有力地证明了“数据质量 > 数据数量”,以及DAS采样策略的有效性。
4.2 消融实验
为了验证每个组件的贡献,作者进行了详细的消融研究(表7)。
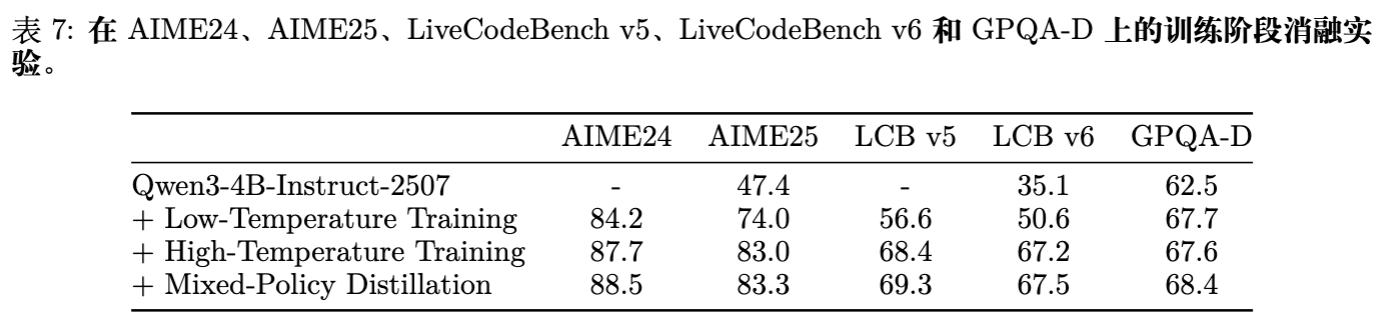
-
Baseline (Qwen3-4B): AIME25 为 47.4%。 -
+ 低温训练 (w/ DAS): 提升至 74.0%。基础能力的建立至关重要。 -
+ 高温训练 (w/ DAS): 提升至 83.0%。证明了扩展模式覆盖率对解决难题的贡献。 -
+ 混合策略蒸馏: 提升至 83.3%,并在LCB上提升约1%。虽然幅度看似不大,但在高分段的提升往往是最困难的,且该阶段主要用于提升鲁棒性。
4.3 DAS vs. 随机采样 (RS)
论文专门对比了DAS与随机采样在相同数据预算下的表现(表3)。
-
在T=0.6时,DAS比RS在AIME25上高出2.3分。 -
在T=1.0时,DAS比RS高出3.1分。 -
即便将RS的数据量翻倍(100K),其效果(78.9%)依然不如50K数据的DAS(79.2%)。
这一结果直接验证了DAS能够筛选出更利于学生学习的分布。
4.4 扩展到MoE模型
为了验证方法的通用性,作者将DASD流程应用于Qwen3-30B-MoE架构。结果显示,DASD-30B-MoE在未进行全量数据训练(仅使用了阶段一数据)的情况下,就在AIME25上达到了86.7%,LCB v6上达到72.8%,证明了该蒸馏框架可以扩展到更大参数量和不同架构的模型上。
5. 深度讨论与启示
5.1 从“模仿数据”到“模仿分布”
这篇论文最大的启示在于将视点拉回了蒸馏的本源。在LLM时代,由于获取Logit的成本高昂(尤其是对于API模型),社区习惯于将蒸馏简化为“生成-过滤-微调”的流水线。这种简化虽然工程上可行,但丢失了概率分布中的丰富信息。
DASD通过采样时的概率对比,巧妙地在没有完整Logit对齐的情况下,近似实现了分布匹配。它告诉我们:不是所有正确答案都等价。对于学生模型而言,那些“我知道是对的”样本(Shared Sentences)带来的梯度信号很弱,而“老师觉得是对的,但我不敢确定”的样本(Teacher Sentences)才是知识传递的关键载体。
5.2 温度调度的辩证关系
关于采样温度的讨论为数据工程提供了指导。一味追求多样性(高温)会导致模型学不会,一味追求高质量(低温)会导致模型泛化差。先易后难、循序渐进的课程学习策略在长CoT推理训练中依然适用。这与人类学习过程(先掌握基本题型,再挑战变式)是不谋而合的。
5.3 混合策略与System 2思维
混合策略蒸馏部分触及了System 2思维(慢思考)的核心难点:纠错与回溯。单纯的Teacher Forcing训练让模型成为了温室里的花朵,一旦推理偏离轨道就无所适从。通过让教师在学生偏离的路径上进行修补,实际上是在教学生“如果在这一步想错了,该如何通过后续步骤修正回来”或者至少“在这个前缀下,最优的后续路径是什么”。这增强了模型在长序列生成中的鲁棒性。
5.4 局限性与未来方向
尽管结果优异,该工作仍有改进空间:
-
概率获取:DAS依赖于教师模型提供Token级的概率。对于仅提供文本输出的黑盒API教师,该方法无法直接应用。 -
计算开销:计算 需要对教师生成的每一个样本进行一次前向传播,这增加了数据筛选阶段的算力成本。 -
领域适应:目前的实验主要集中在理科(Math/Code/Science),对于文科或开放域创作任务,其有效性有待验证。
更多细节请阅读原文。
往期文章:


