
-
论文标题:LongCat-Flash-Thinking-2601 Technical Report -
论文链接:https://arxiv.org/pdf/2601.16725
TL;DR
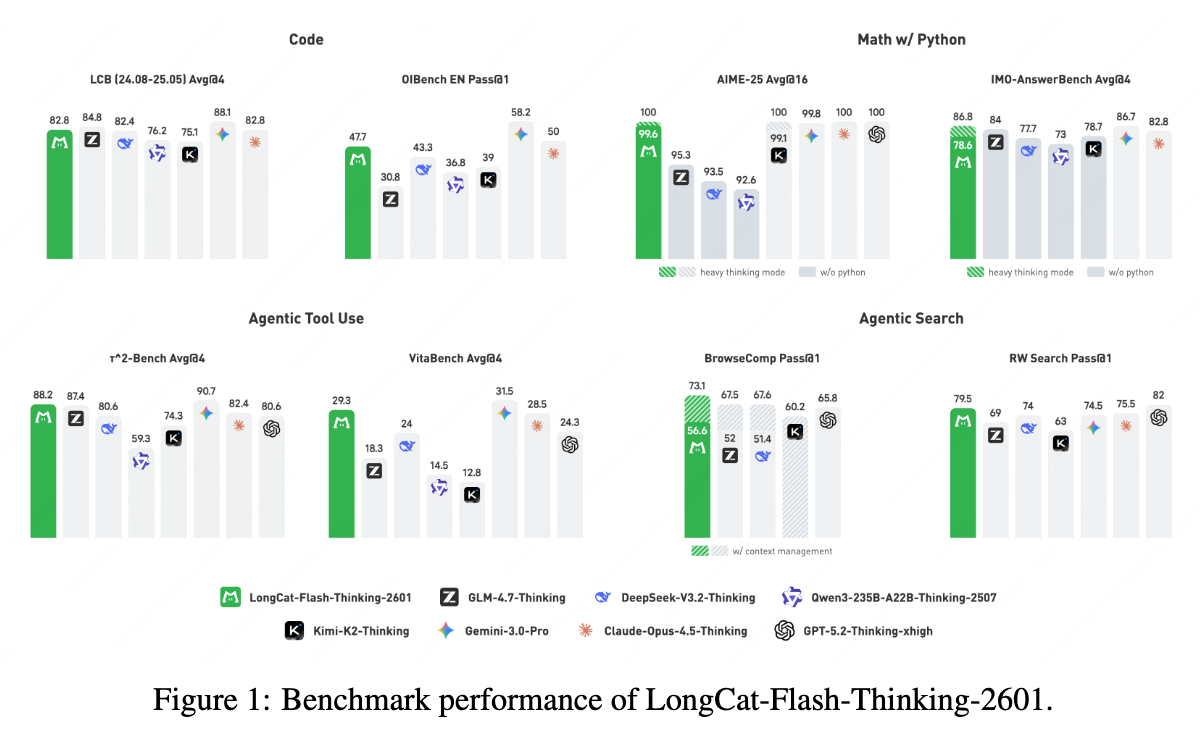
LongCat-Flash-Thinking-2601 是美团 LongCat 团队发布的一款拥有 5600 亿参数(激活 270 亿)的开源混合专家(MoE)推理模型。该模型在 Agentic Reasoning(代理推理)能力上表现突出,特别是在 Agentic Search(代理搜索)、Agentic Tool Use(代理工具使用)以及与工具集成的推理任务中,取得了优于现有开源模型的效果,并在部分指标上接近闭源模型。
核心技术要点:
-
环境扩展(Environment Scaling): 开发了一套自动化流水线,构建了覆盖 20 多个领域、超过 10,000 个可执行且可验证的仿真环境,解决了 Agentic 任务中高质量环境稀缺的问题。 -
鲁棒性 RL 训练: 针对真实世界环境的不确定性,设计了噪声注入机制和多领域混合训练策略,显著提升了模型在非理想环境下的泛化能力。 -
Heavy Thinking 模式: 提出了一种测试时计算(Test-Time Scaling)的新范式,通过并行推理(扩展宽度)和迭代反思(扩展深度)的结合,进一步挖掘模型的推理潜力。 -
DORA 训练框架扩展: 针对长链路、多轮交互的 Agentic 任务,升级了异步强化学习框架,支持高达 32,000 个并发环境的高效训练。 -
Zig-Zag Attention: 作为“One More Thing”,探索了一种可从全注意力平滑过渡的稀疏注意力机制,支持百万级上下文长度。
1. 引言
近年来,推理模型在数学和代码任务上取得了显著进展。然而,如何将这种内在的求解能力(Intrinsic Reasoning)转化为解决复杂现实任务的能力,是当前研究的重点。美团团队认为,与外部环境的交互是突破现有瓶颈的关键。
Agentic Reasoning(代理推理)本质上是通过与外部环境的自适应交互来解决复杂问题。这要求模型不仅具备通过思维链(CoT)进行内部审视的能力,还需要判断何时调用工具、如何处理环境反馈,并从长周期的交互中修正错误。
相比于传统的数学推理,Agentic 任务面临三大挑战:
-
长视界(Long-horizon): 涉及多轮交互,上下文窗口压力大。 -
异构环境: 不同领域的 API、数据库结构差异巨大。 -
长尾动态: 真实环境的反馈具有高度不确定性。
LongCat-Flash-Thinking-2601 的设计初衷即是为了解决上述挑战,通过构建大规模合成环境和鲁棒的 RL 训练流程,填补了由于现实世界中高质量 Agentic 轨迹数据稀缺带来的空白。
2. 预训练与中期训练
模型的基座沿用了 LongCat-Flash-Chat 的配方,保留了通用语言能力。针对 Agentic 能力的提升,主要集中在中期训练(Mid-training)阶段。
2.1 针对长上下文的分阶段训练
Agentic 任务通常伴随着极长的上下文(工具文档、历史交互、搜索结果)。模型采用了分阶段上下文扩展策略:
-
32K/128K 阶段: 消耗 500B tokens。 -
256K 阶段: 额外消耗 40B tokens。
为了降低在超参数搜索上的计算成本,团队提出了一种基于验证集损失和 FLOPS 映射的最优超参数预测方法,从而避免了大规模的网格搜索。
2.2 数据合成策略
由于真实世界中涉及复杂推理、规划和交互的高质量数据极其稀缺,报告提出了一种混合数据合成框架,包含文本驱动(Text-driven)和环境驱动(Environment-grounded)两个互补方向。
2.2.1 文本驱动合成
利用大规模文本语料中隐含的过程性知识(如教程、说明书),将其重构为显式的交互轨迹。
-
工具提取: 识别具有多步工作流的文本段落,定义潜在函数并提取调用列表。 -
合成与细化: 将抽象工作流转化为具体的用户-代理多轮对话。 -
增强策略: -
工具分解(Tool Decomposition): 将部分工具参数“隐藏”到环境中,迫使模型通过交互去获取这些参数,而不是一次性生成。 -
推理分解(Reasoning Decomposition): 为每一步行动生成多个候选,并让模型生成选择理由,从而将轨迹转化为决策过程。
-
2.2.2 环境驱动合成
为了保证逻辑正确性和执行一致性,团队构建了轻量级 Python 环境。
-
依赖建模: 构建工具间的参数依赖图(Directed Graph)。 -
逆向合成(Reverse-Synthesis): 从依赖图中采样有效的工具执行路径,利用逆向工程合成对应的用户 Prompt,并执行代码验证最终状态,确保数据基于真实的执行逻辑。
2.2.3 面向规划的数据增强
Agentic Reasoning 的核心在于规划。为了显式增强这一能力,团队构建了两类特定数据:
-
问题分解: 合成“问题分解+初始动作选择”的配对数据,提供从粗粒度规划到早期决策的监督。 -
多候选决策: 从完整轨迹出发,在每个决策点生成多个候选方案,训练模型进行推理和选择。
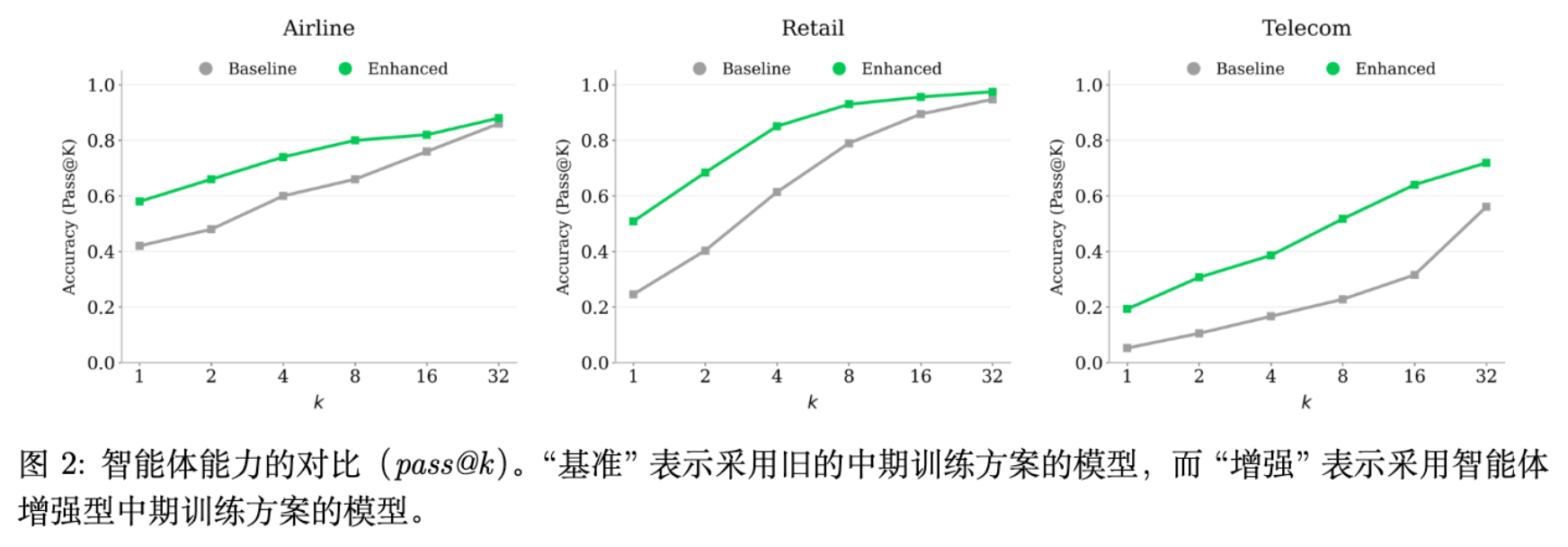
3. 环境扩展与自动化构建
这是该报告最核心的技术亮点之一。为了训练通用的 Agent,必须让模型暴露在足够多样化的环境中。人工设计环境不可扩展,因此团队设计了一套自动化流水线,能够从高层定义生成可执行的领域环境。
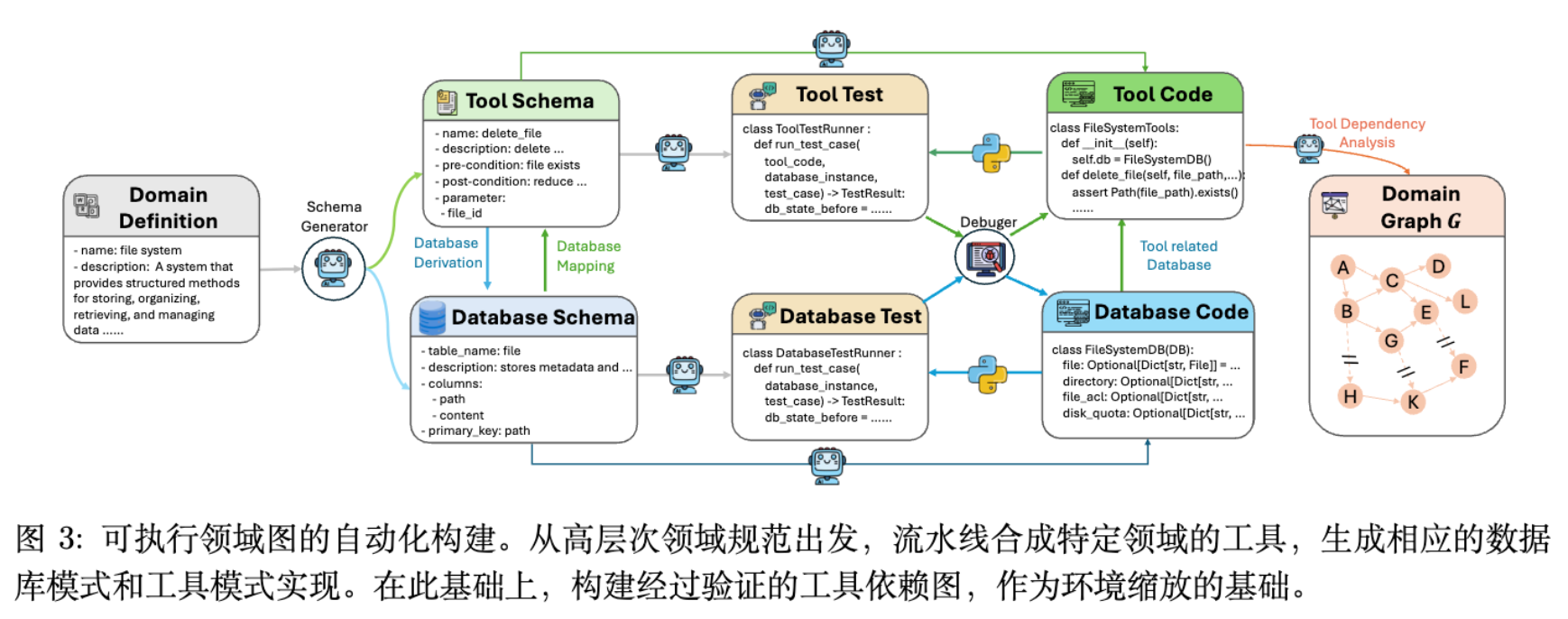
3.1 领域图 (Domain Graph) 构建
构建过程分为以下步骤:
-
Schema 生成: 从领域描述生成工具 Schema(函数名、参数、前后置条件)和数据库 Schema。 -
代码实现: 自动生成数据库实现代码和工具逻辑代码。 -
单元测试与调试: 通过辅助 Agent 生成单元测试,确保代码转换成功率超过 95%。 -
依赖图构建: 基于验证后的工具集,构建工具依赖图 。节点为工具,边表示参数依赖关系。
目前该系统已覆盖 20 多个领域,每个领域的工具图 包含超过 60 个工具,形成了密集的依赖网络。
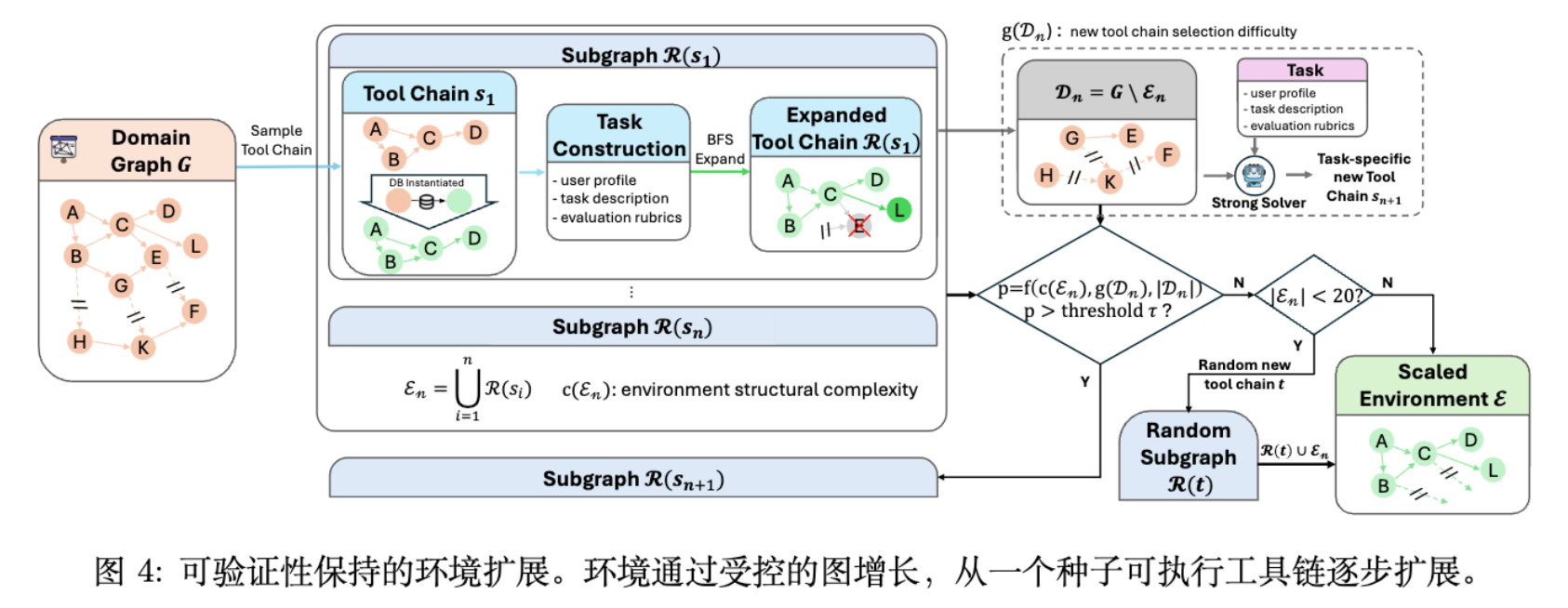
3.2 保持可验证性的环境扩展
给定一个工具图 ,如何生成不同难度的环境?团队采用了一种受控的图生长算法。
-
种子采样: 随机采样一个中等规模的工具链 ,实例化对应的数据库状态,确保依赖满足。
-
受控扩展: 为了增加环境复杂度,需要将 扩展为更大的子图 。
-
这里存在一个关键挑战:如果盲目引入新工具,可能会破坏数据库的一致性,导致有效轨迹执行失败,从而在 RL 中引入错误的负反馈。 -
解决方案: 采用 BFS 风格的扩展,仅添加那些依赖已被当前已实例化工具满足的节点。
-
-
多链融合: 决定是否引入新的独立工具链 。决策基于概率 :
其中 是当前环境结构复杂度, 是从剩余节点中发现新有效工具链的难度。如果 高于阈值,则引入新链 并进行融合。
这种机制保证了生成的环境既具有足够的复杂度(每个环境至少 20 个工具),又保持了严格的可执行性和可验证性。
4. 大规模异步强化学习
在 Post-training 阶段,目标是通过 RL 激发模型的 Agentic 能力。这不仅需要算法创新,更需要强大的基础设施支持。
4.1 任务集准备
RL 的效果取决于 Task Set 的质量。
-
Agentic Coding: 从软件开发平台收集轨迹,通过严格的执行验证和动作级过滤,保留涉及长程调试的轨迹。 -
Agentic Search: 合成优先考虑完整性和抗“走捷径”能力的推理轨迹。 -
基于图形的 QA 合成: 基于 Wikipedia 实体构建关系图,通过采样生成多跳推理问题,并利用 LLM 模糊化具体细节以增加难度。 -
基于 Agent 的合成: 使用多 Agent 协作(出题、验证、回答、裁判)生成具有歧义约束的问题。
-
-
Agentic Tool-Use: 直接基于上述环境扩展流水线生成任务。
4.2 基础设施:扩展 DORA
针对 Agentic 任务的多轮次、长延迟特点,团队对 DORA(Dynamic ORchestration for Asynchronous rollout)系统进行了扩展。
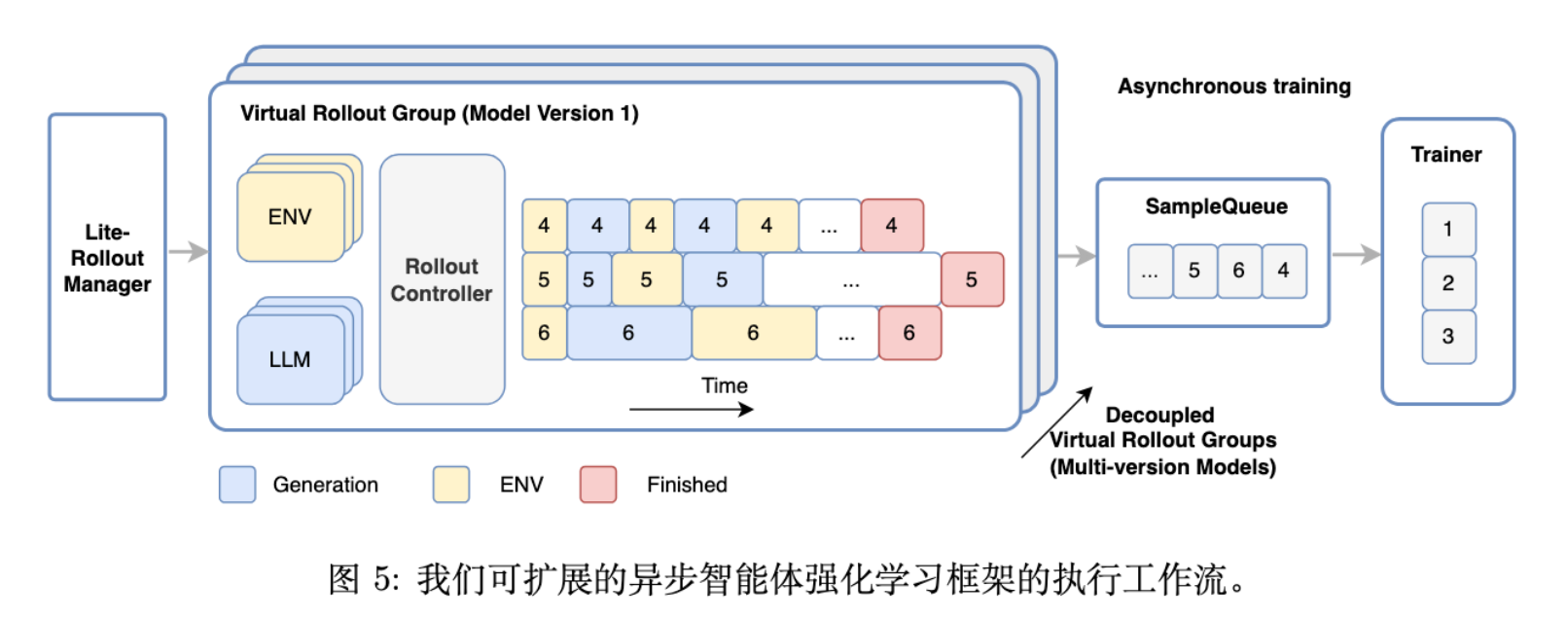
4.2.1 全流式异步管道
-
消除批处理同步: 在 Rollout 阶段,取消了 Batch Barrier。LLM 生成、环境执行、奖励计算均在样本粒度上异步进行。 -
多版本共存: 允许不同模型版本的轨迹同时存在,Trainer 只要满足条件即可更新,或利用空闲算力开启更多生成实例。
4.2.2 生产环境中的资源调度
-
沙箱调度: 实现了高并发沙箱调度器,支持 32,000 个环境并发运行。 -
轻量级 Rollout 管理: 将原有的 RolloutManager 拆分为轻量级的元数据管理器和多个数据并行的 RolloutController,解决单机 CPU 瓶颈。
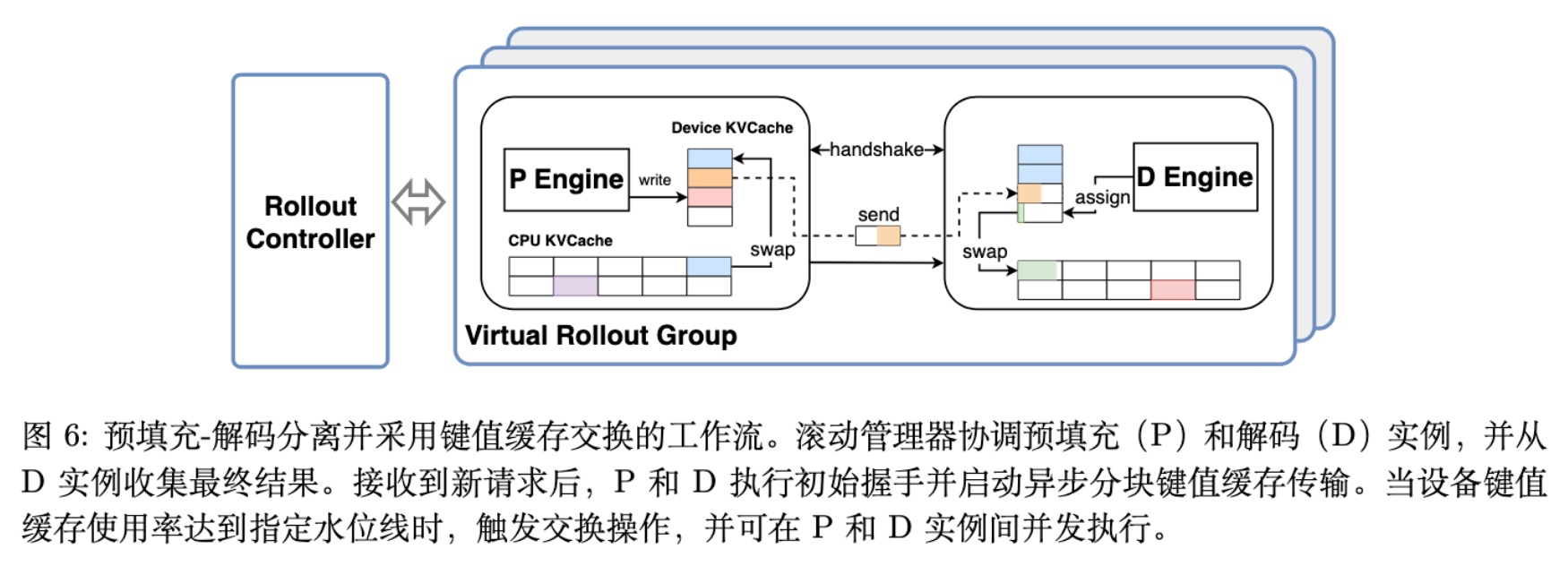
4.2.3 PD 分离与 KV-Cache Swapping
针对 560B MoE 模型的显存限制(60GB 卡),采用了 Prefill-Decode (PD) 分离架构。
-
负载不均衡问题: 长上下文任务会导致专家并行组内的负载不均衡。 -
解决方案: 将 Prefill 和 Decode 节点物理分离。 -
KV-Cache Swapping: 引入 CPU 驻留的 KV-Cache。当设备显存不足时,将 KV Block 换出到 CPU,需要时再预取。这支持了 chunk 级别的异步传输,实现了计算与传输的重叠。
4.3 训练策略
4.3.1 动态预算分配
不同难度的任务对模型当前的训练价值不同。传统的均匀采样效率低下。团队提出基于实时指标 (如通过率)的动态价值函数:
利用贪心算法最大化当前 Batch 的总学习价值,动态调整各任务的 Rollout 预算。
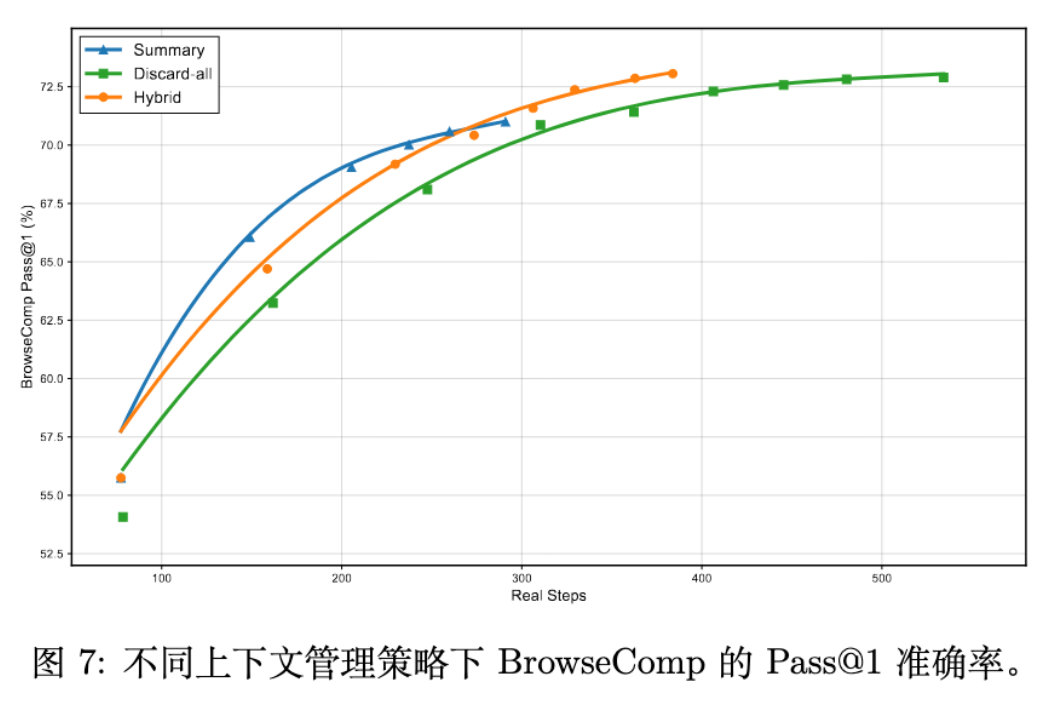
4.3.2 混合上下文管理
Agentic 任务容易导致上下文溢出。团队对比了 Summarization 和 Discard 策略,提出了混合方案:
-
Summary-based: 当上下文超过 80K tokens 时,使用模型自身对历史工具调用进行摘要。 -
Discard-based: 当交互轮数超限时,触发 Discard-all 重置,仅保留系统提示和原始问题。
实验表明,混合策略在 BrowseComp 任务上实现了最高的效率和准确率。
4.3.3 鲁棒性 RL:引入环境噪声
这是提升 Real-world 表现的关键。真实环境充满了噪声(指令模糊、工具报错、网络超时)。如果仅在完美合成环境中训练,模型会极其脆弱。
-
噪声注入: 在训练中显式注入指令噪声(用户表述的多样性、歧义)和工具噪声(执行失败、格式错误、部分结果)。 -
课程学习: 噪声强度随训练进程逐步增加。
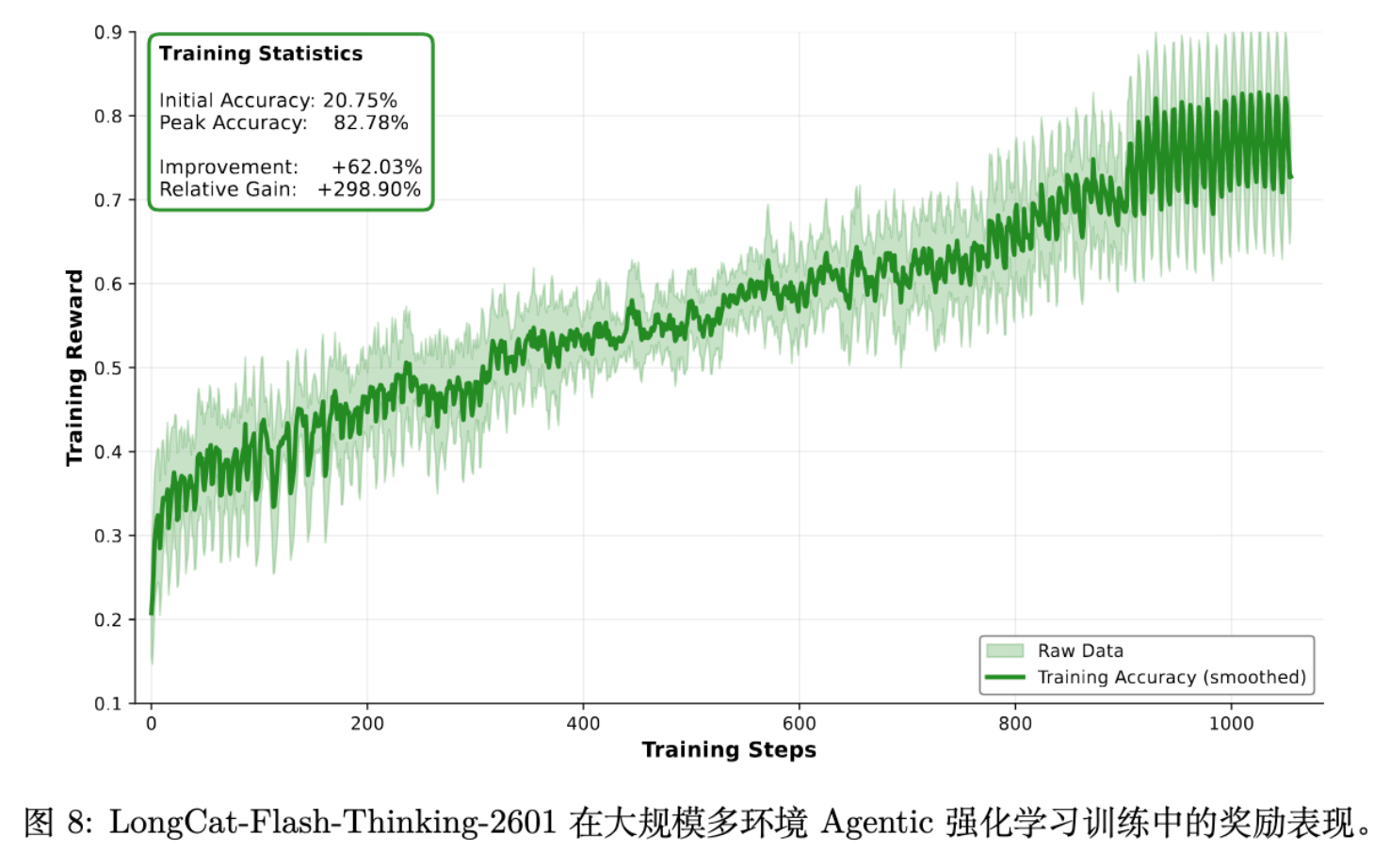
实验数据显示,在引入噪声训练后,模型在 -Bench Noise 和 VitaBench Noise 等噪声测试集上的表现有显著提升(例如 VitaBench-Noise 从 13.3% 提升至 20.5%),且未损害在标准环境下的性能。
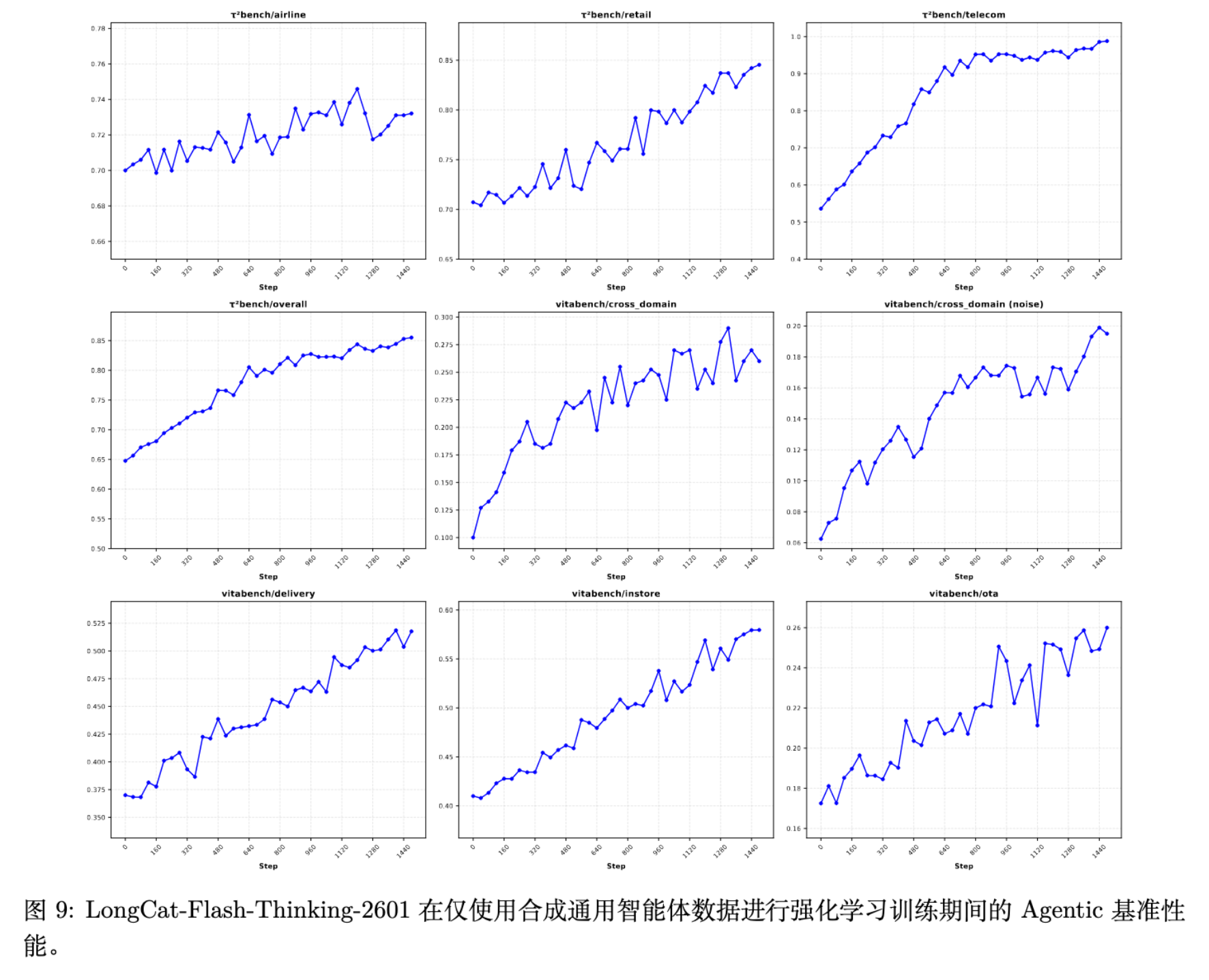
5. Test-Time Scaling
为了进一步挖掘模型潜力,报告提出了一种名为 Heavy Thinking 的推理模式。这不仅仅是简单的 Self-Consistency,而是一个结构化的“并行推理 + 深度反思”框架。
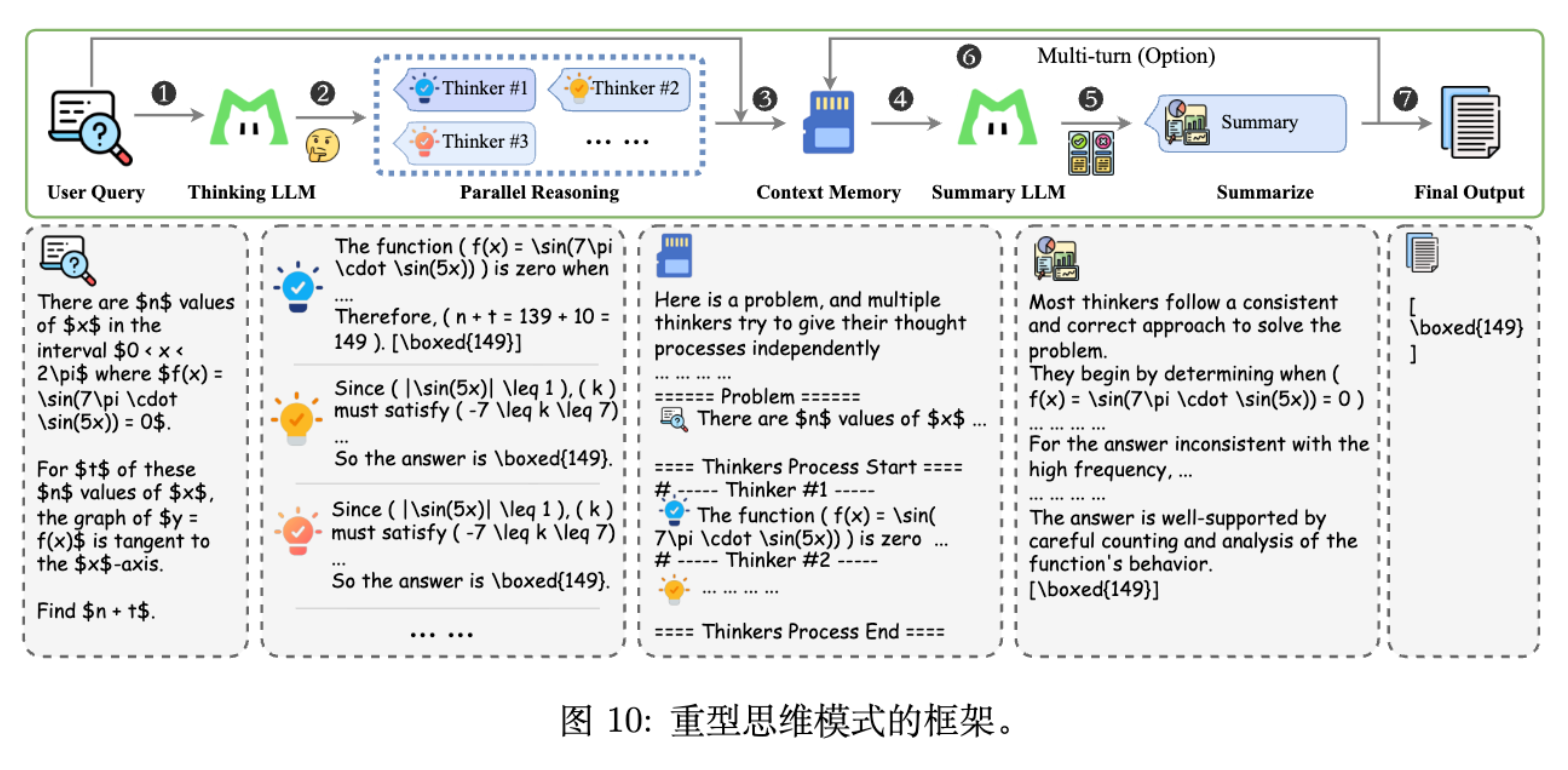
5.1 框架设计
Heavy Thinking 将推理分解为两个阶段:
-
并行推理 (Parallel Reasoning) - 扩展宽度:
-
模型并行生成 条候选推理轨迹。 -
这些轨迹独立探索不同的解题路径。
-
-
重度思考 (Heavy Thinking) - 扩展深度:
-
引入一个 Summary Model(可以是同一模型)。 -
该模型接收并行阶段的所有历史消息和候选答案。 -
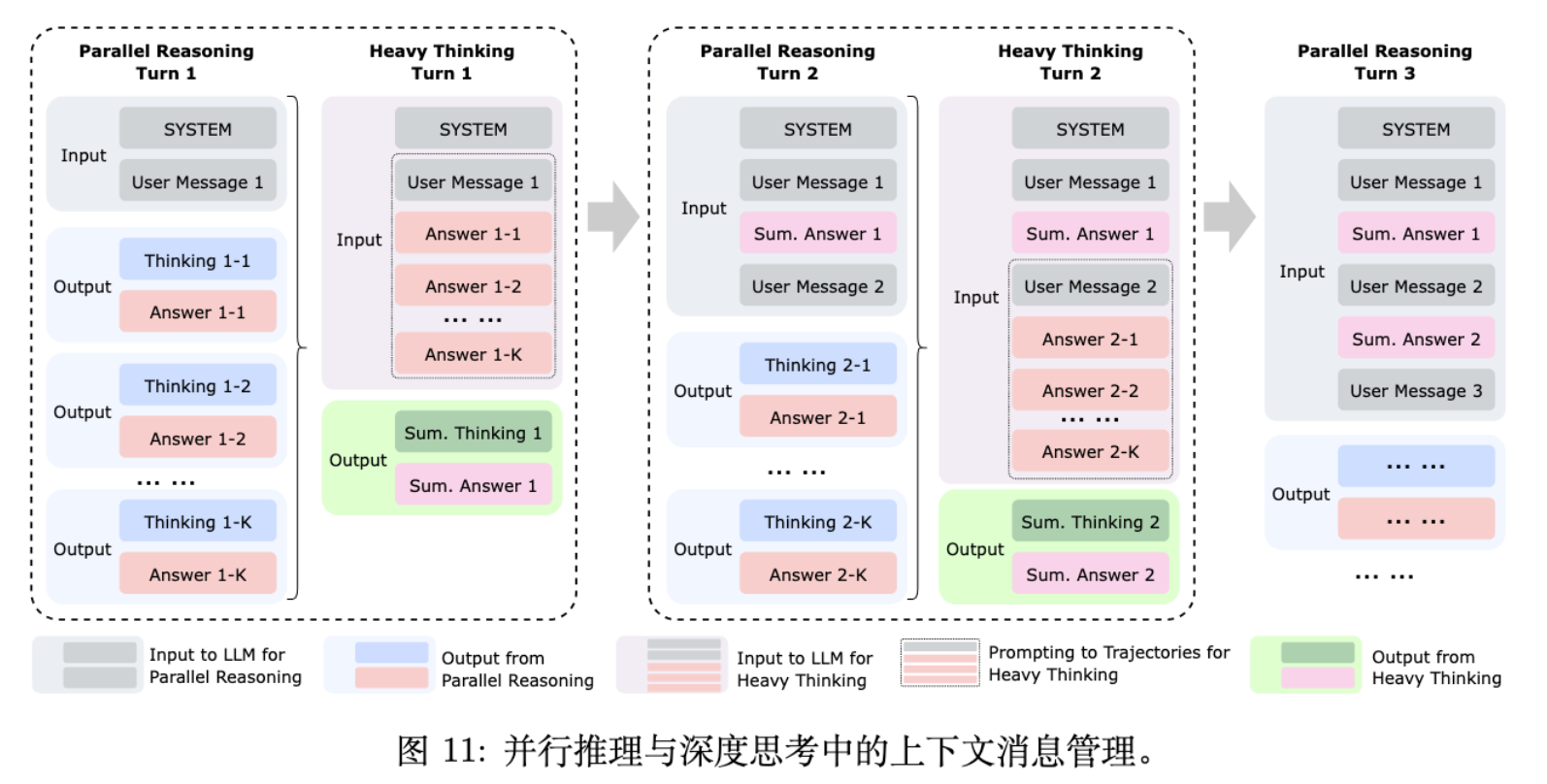
上下文记忆模块: 为了支持多轮对话和工具使用,设计了特定的 Prompt 模板,将并行轨迹的排列(仅保留答案内容)组织起来。 -
Summary Model 进行反思性推理,综合各路径的优劣,聚合或修正中间结果,生成最终决策。
-
5.2 针对 Summary 阶段的 RL
为了让 Summary Model 更好地通过并行轨迹进行去伪存真,团队引入了专门针对 Summary 阶段的强化学习。实验表明,这种 Test-Time Scaling 策略在长思维链、工具集成推理等场景下,效果始终优于单纯的 Self-Consistency,且计算预算越大,优势越明显。
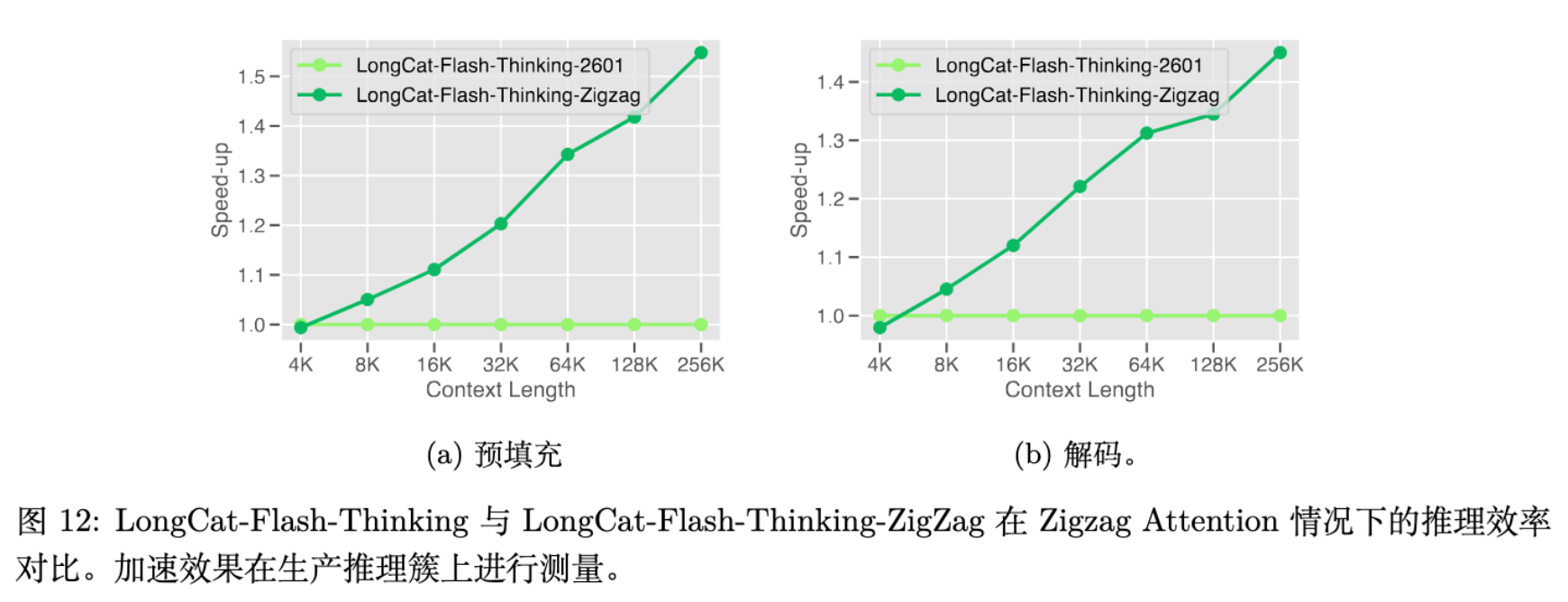
6. One More Thing: Zig-Zag Attention
针对长上下文推理的效率问题,尤其是 Heavy Thinking 模式下推理延迟放大的问题,团队探索并发布了 LongCat-Flash-Thinking-ZigZag 模型。
6.1 核心理念
全注意力机制(Full Attention)的 复杂度限制了其在超长上下文(1M+)下的应用。现有的稀疏注意力方法通常需要大量重新训练。Zig-Zag Attention 旨在实现从预训练全注意力模型到稀疏模型的平滑过渡。
6.2 架构实现
Zig-Zag Attention 结合了 MLA(Multi-head Latent Attention)和 SSA(Streaming Sparse Attention)。
其中保留了局部窗口 和初始锚点 。
Zig-Zag 连接性:
采用层级交错稀疏化(Layer-wise interleaved sparsification)。
-
约 50% 的层替换为 SSA 层。 -
剩余层保留 MLA 全注意力。 -
信息传播: 虽然单层是稀疏的,但信息可以通过层间组合在多个层级上传播,形成“之”字形(Zig-Zag)路径,从而在大幅降低计算量的同时保留全局依赖能力。
6.3 性能与效率
通过将约一半的层替换为 Zig-Zag Attention,模型在 1M 上下文下的端到端推理速度提升了约 1.5倍,且在各项基准测试中保持了与全注意力模型相当的性能。
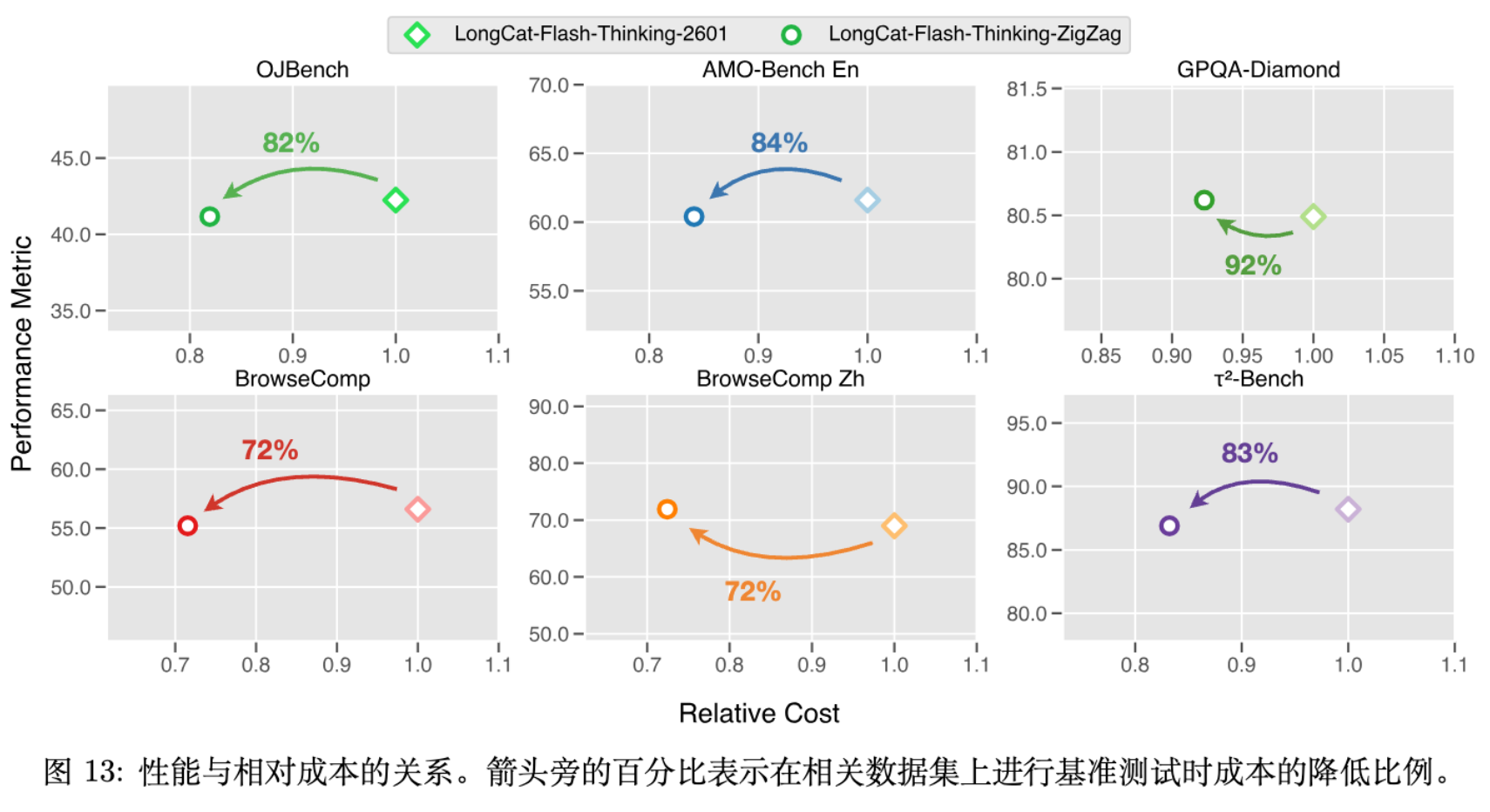
7. 实验评估
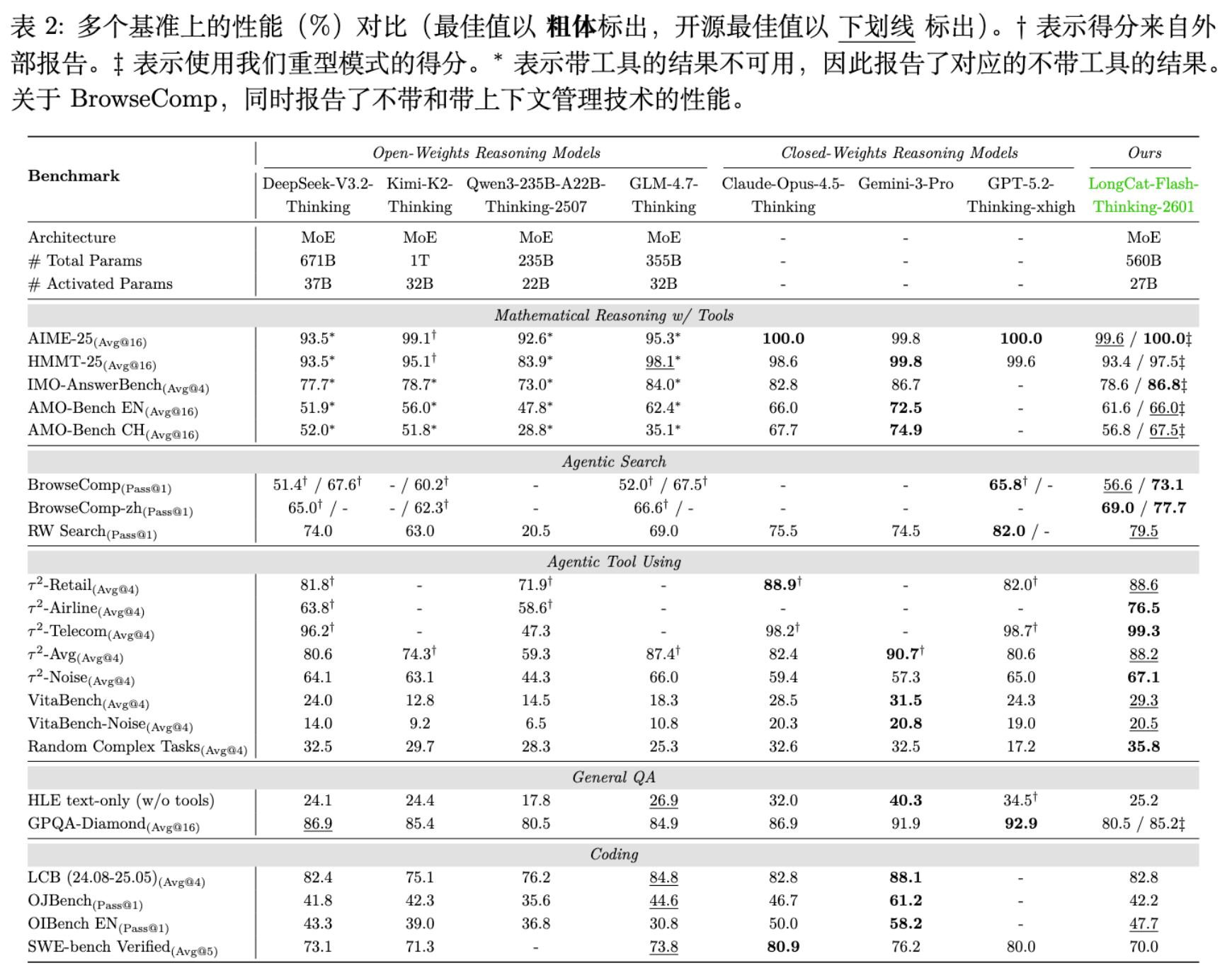
LongCat-Flash-Thinking-2601 在五个维度进行了评估:数学推理、Agentic Search、Agentic Tool Use、通用推理和代码。
7.1 主要结果
在与 DeepSeek-V3.2、Claude-Opus-4.5、Gemini-3-Pro 等模型的对比中:
-
Agentic Search: 在 BrowseComp 和 BrowseComp-ZH 上,配合上下文管理,模型分别达到了 73.1% 和 77.7% 的 Pass@1,超越了所有开源模型,并在 RWSearch 上取得了 79.5% 的高分,仅次于 GPT-5.2-Thinking。 -
Agentic Tool Use: 在 -Bench 和 VitaBench 上表现优异。特别是在引入噪声的测试集(-Noise, VitaBench-Noise)上,得益于鲁棒性训练,展现了极强的抗干扰能力。 -
数学推理: 搭载 Heavy Mode 后,在 AIME-2025 上实现了 100% 的准确率(参考外部报告分值),在 IMO-AnswerBench 上达到 86.8%,具有与闭源模型一战的实力。 -
代码: 在 LiveCodeBench 和 SWE-bench Verified 上均位列开源模型第一梯队。
7.2 随机复杂任务
为了验证泛化性,团队引入了一个新的评估协议。基于环境扩展流水线随机生成复杂的 Agentic 任务。结果显示,模型在未见过的任务分布上依然保持了高水平的完成率,证明了 Multi-domain Environment Training 的有效性。
更多细节请阅读原文。
往期文章:


