
-
论文标题:RedOne 2.0: Rethinking Domain-specific LLM Post-Training in Social Networking Services -
论文链接:https://arxiv.org/pdf/2511.07070
TL;DR
今天分享一篇来自小红书 NLP 团队的论文《RedOne 2.0: Rethinking Domain-specific LLM Post-Training in Social Networking Services》,该论文聚焦于领域后训练,具有较强的实践性。
论文提出了一种针对社交网络服务(SNS)领域的语言模型后训练(Post-Training)框架。该框架旨在解决通用大模型在应用于SNS时所面临的独特挑战,例如:用户生成内容(UGC)的高度异质性、网络流行语和社区规范的快速演变,以及多语言、多文化的复杂语境所导致的分布偏移(Distribution Shift)问题。
传统的解决方法,如监督微调(Supervised Fine-Tuning, SFT),虽然能在特定任务上提升模型性能,但常常以牺牲模型的通用能力和分布外(Out-of-Distribution, OOD)鲁棒性为代价,产生所谓的“跷跷板效应”,这一现象在小型模型上尤为明显。
为应对这些挑战,RedOne 2.0 提出了一种渐进式的、以强化学习(Reinforcement Learning, RL)为核心的三阶段后训练流程:
-
探索性学习(Exploratory Learning): 利用RL让模型初步接触并对齐SNS领域的语料,同时暴露和诊断模型在特定SNS任务上的能力短板。 -
针对性微调(Targeted Fine-Tuning): 针对上一阶段发现的弱点,选择性地使用SFT进行“靶向修复”,并混入少量通用数据以缓解灾难性遗忘。 -
精炼学习(Refinement Learning): 再次应用RL,对模型进行全局优化,整合前两个阶段的收益,并平衡不同任务间的性能表现。
论文的实验结果表明,该方法在保持模型通用能力的同时,显著提升了在SNS领域的专业能力。一个4B参数的RedOne 2.0模型,在SNS领域的综合表现超过了7B参数的基线模型。此外,相较于SFT为中心的方法,RedOne 2.0在数据效率上表现出优势,用更少的数据达到了更好的性能。
1. 引言
将大型语言模型(LLM)直接应用于社交网络服务(SNS)领域,并非简单的“即插即用”。SNS平台,如小红书、微博、Twitter等,其生态环境与预训练语料库(如通用网页文本、书籍)存在显著的分布差异。这些差异构成了LLM在SNS领域落地时必须克服的障碍。
1.1 异质性
SNS平台上的任务是多样且复杂的。它们包括但不限于:
-
内容审核:实时识别并处理违规、有害或不友好的内容。 -
用户增长:通过生成吸引人的文案、标题或评论来提升用户互动。 -
推荐对话:在推荐场景下与用户进行自然、流畅的对话,理解用户意图。 -
创作者辅助:为内容创作者提供灵感、素材或写作建议。
这些任务对模型的延迟、安全性、语气风格等方面的要求各不相同,需要一个能够处理异构负载的统一模型。
1.2 快速演变的语言环境
网络语言瞬息万变。新的流行语、表情包(meme)和社区内部的“黑话”层出不穷,而旧的词汇可能很快过时。LLM如果不能快速适应这种变化,其生成的内容就会显得“落伍”,甚至会错误地理解用户意
图,影响用户体验。
1.3 多语言与跨文化语料
大型SNS平台通常是全球性的,连接着来自不同文化背景、使用不同语言的用户。模型需要具备强大的多语言处理和跨文化理解能力,才能准确地把握不同社群的表达习惯和文化禁忌。
1.4 SFT 的局限性
监督微调(SFT)是领域自适应的常用方法。通过在特定领域的“指令-回答”数据对上进行训练,SFT可以使模型快速学习到领域的知识和任务范式。然而,SFT也存在固有的缺陷:
-
跷跷板效应 (Seesaw Effect) :过度拟合领域内(In-Distribution, ID)数据,会导致模型在领域外(Out-of-Distribution, OOD)或通用任务上的性能下降。模型似乎在“按下葫芦浮起瓢”,提升了一方面的能力,却损害了另一方面的能力。 -
灾难性遗忘 (Catastrophic Forgetting) :在学习新知识的过程中,模型可能会覆盖或遗忘之前学到的通用知识。这一问题在参数规模较小的模型上更为严重,因为它们的“知识存储容量”相对有限。
为了解决这些问题,学术界和工业界一直在探索新的后训练范式。RedOne 2.0正是在这一背景下,提出了一种新的思路,即从单纯依赖SFT转向一个以RL为主导的、多阶段、渐进式的优化流程。
2. RedOne 2.0
RedOne 2.0 的核心是一个精心设计的三阶段管道,每个阶段都有明确的目标,层层递进,旨在实现领域能力和通用能力的平衡。
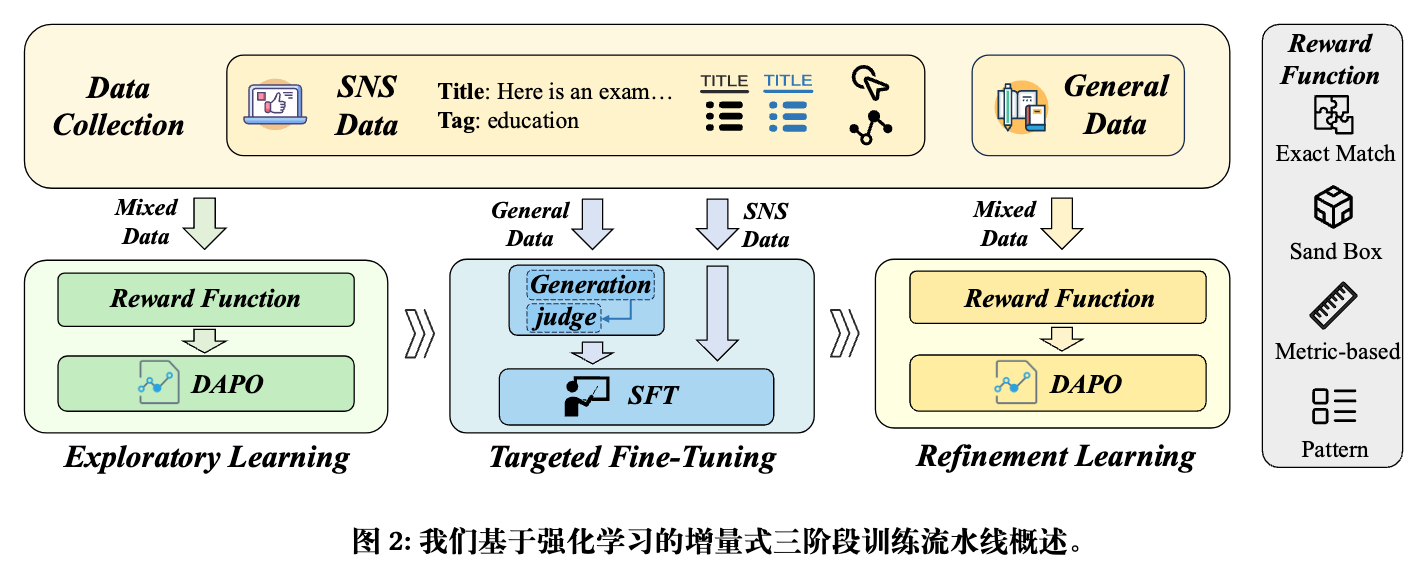
2.1 探索性学习
这一阶段的目标是让基础模型(Base Model)对SNS领域有一个初步的、广泛的认知,并找出其能力上的“短板”。
-
方法:主要采用强化学习(RL),特别是DAPO(Direct Advantage Preference Optimization)算法。DAPO是DPO(Direct Preference Optimization)的一种变体,旨在更有效地利用奖励信号进行策略优化。 -
数据:使用经过筛选的、覆盖约75个不同SNS任务的75万条数据( DSNS),同时混合了5万条包含推理过程的通用领域数据(DGEN)。通用数据的加入,其目的是在模型探索SNS领域的同时,维持其基础的推理和通用知识。 -
奖励函数 :论文设计了四种不同类型的奖励函数,以适应SNS中任务的多样性: -
精确匹配 :适用于分类、多选等具有确定性答案的任务。 -
基于指标 :适用于翻译等开放式任务,使用如BLEU、ROUGE等评价指标作为奖励。 -
沙盒 :适用于代码生成等任务,通过在安全环境中执行代码并验证结果来给予奖励。 -
模式匹配 :关注生成内容的格式是否符合指令要求,而非语义内容本身。
-
-
作用与输出:此阶段结束后,模型在SNS领域的整体性能得到初步提升。更重要的是,通过在各个任务上的评估,可以清晰地识别出模型表现不佳的“弱点任务”。
2.2 针对性微调
这一阶段的核心是利用SFT高效修复在第一阶段诊断出的模型弱点。
-
方法:采用传统的监督微调(SFT)。 -
数据:数据构成是本阶段的关键。 -
SNS数据:170万条来自上一阶段评估出的“失败案例(failure tasks)”的数据。这些数据被进一步按能力进行分层和加权,以优先解决那些罕见但影响重大的问题。 -
通用数据:10万条通用领域数据。值得注意的是,这些通用数据的“答案”并非标准的Ground-truth,而是由第一阶段训练后的模型生成的“软标签(soft labels)”。具体做法是,让模型对一个问题生成多个候选答案,再由一个“裁判模型(judge model)”打分,选出最优的答案作为微调的目标。(简单来说就是拒绝采样。)
-
-
作用: -
修复短板:通过在失败案例上进行SFT,直接、快速地提升模型在弱点任务上的表现。 -
数据层面的正则化:使用模型自己生成的“软标签”作为通用数据的微调目标,而非标准的“硬标签”,可以在一定程度上缓解分布突变带来的学习困难。这种做法减少了“真实答案”与模型当前认知之间的差距,使得学习过程更为平滑,从而在一定程度上防止了灾难性遗忘。这可以被看作是一种隐性的知识蒸馏或正则化手段。
-
2.3. 精炼学习
在SFT“打补丁”之后,模型可能在不同任务上的能力分布不均,需要一个最终的整合与平衡阶段。
-
方法:再次使用基于偏好优化的强化学习(DAPO),与第一阶段类似。 -
数据:使用约40万条来自SNS和通用领域的混合数据,重点依然是那些“困难”的子集。此外,该阶段增加了带有推理过程(rationale)的样本比例至57.18%,旨在进一步强化模型的推理能力。 -
作用: -
巩固收益:将前两个阶段获得的性能提升进行固化。 -
平滑与平衡:RL的探索机制有助于平滑不同任务之间的性能“毛刺”,使模型的能力图谱更加均衡和鲁棒,避免在某些任务上表现突出,而在另一些任务上表现很差。 -
提升推理:通过增加推理样本,使模型不仅知道“是什么”,还在一定程度上知道“为什么”,这对于需要复杂逻辑的下游任务是有益的。
-
3. 实验
论文通过一系列实验来验证RedOne 2.0框架的有效性。评估使用了三个基准测试集:
-
General-Bench:评估模型的通用能力,涵盖知识推理、数学、代码等。 -
SNS-Bench:小红书自建的基准,专门评估在SNS场景下的八项核心能力,如内容分类(Taxon.)、标签推荐(Hash.)、图文相关性(QCorr)等。 -
SNS-TransBench:评估在SNS语境下的中英互译能力。
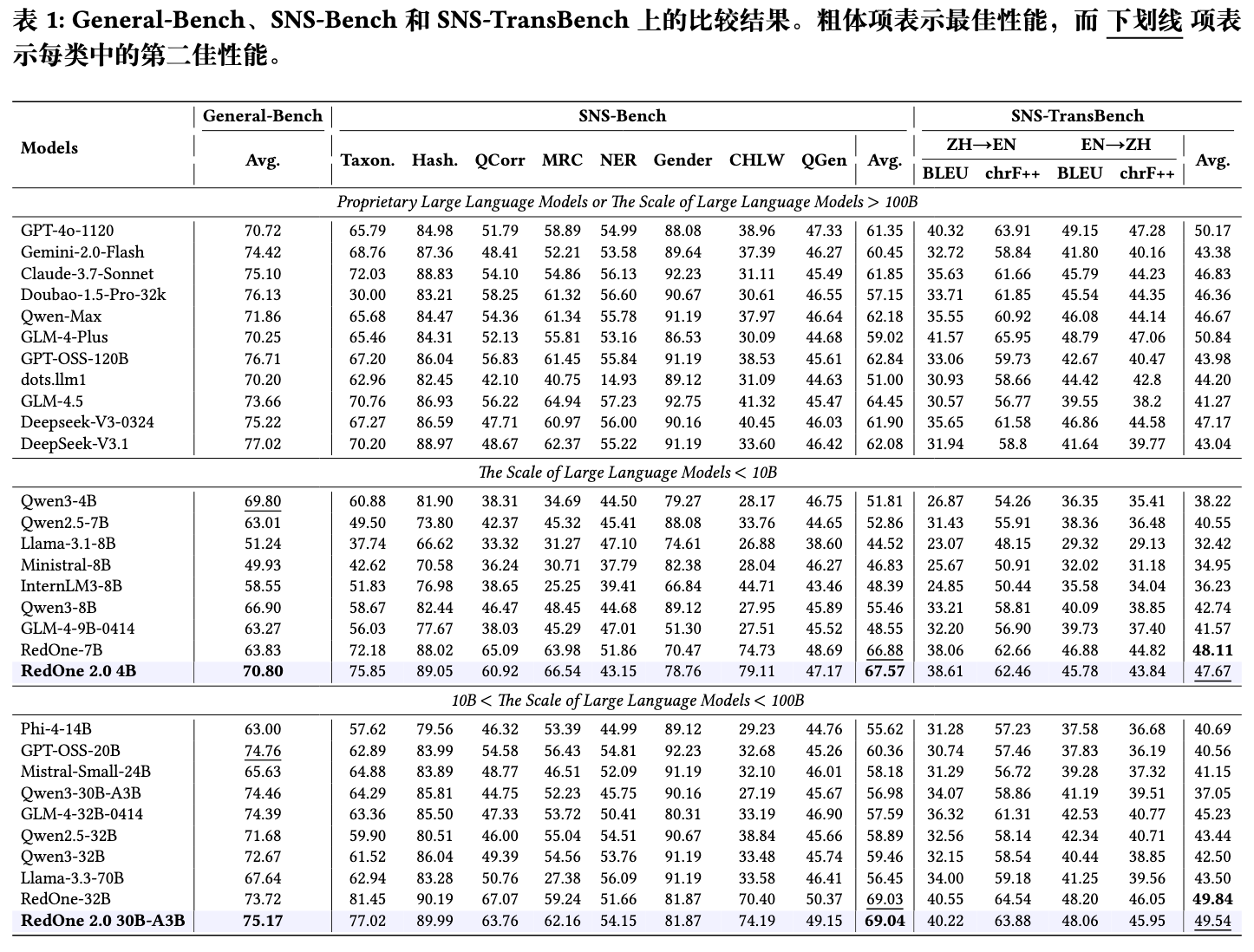
3.1 主要发现
-
小模型超越大模型:RedOne 2.0 4B模型在SNS-Bench上的平均分(67.57)超过了所有10B以下的基线模型,甚至超过了前一代的RedOne-7B模型(66.88)。这表明一个有效的后训练策略可以让小模型在特定领域发挥出超越其参数规模的性能。 -
通用与专业能力的平衡:RedOne 2.0 4B在通用能力基准General-Bench上也取得了70.80的高分,超过了Qwen3-8B等更大的模型。这说明该框架在提升SNS专业能力的同时,没有严重损害其通用能力,成功缓解了“跷跷板效应”。 -
框架的可扩展性:从RedOne 2.0 4B到30B-A3B,模型在三个基准上的性能都呈现稳定提升。这证明了该三阶段框架具有良好的可扩展性,能够适用于不同规模的基础模型。 -
数据效率:论文摘要中提到,RedOne 2.0 相比基础模型实现了约 8.74 的平均性能提升,且所需数据量不足以 SFT 为核心的方法 RedOne 的一半。这说明RL为主导的范式在数据利用效率上可能优于单纯依赖大规模SFT的方法。
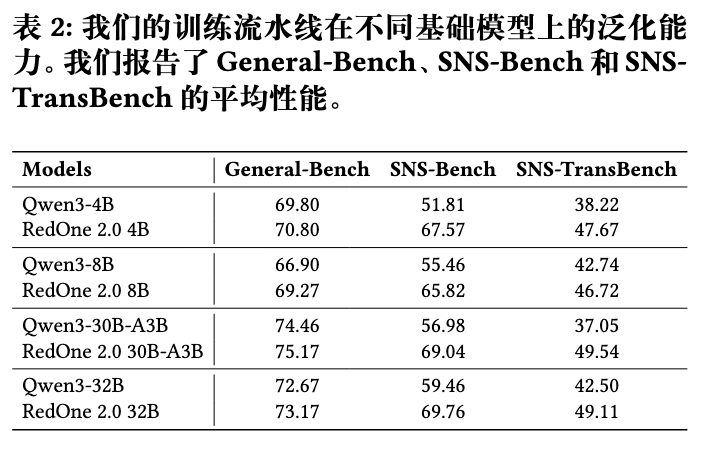
3.2 消融实验分析
论文通过消融实验(Ablation Study)展示了每个阶段的贡献。
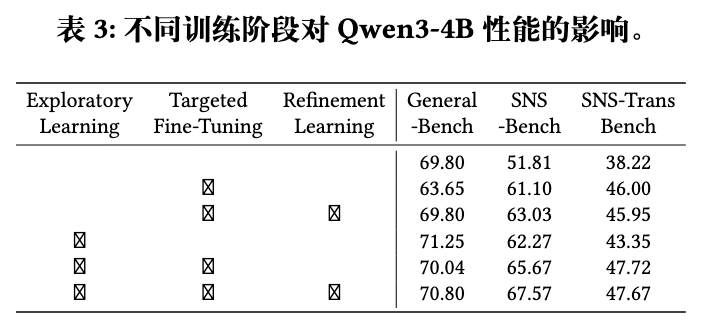
-
阶段一(探索性学习):在基础模型Qwen3-4B上只进行第一阶段的RL训练后,模型在三个基准上都有了显著提升。有趣的是,通用能力(General-Bench)的提升幅度甚至大于SNS专业能力,这可能说明RL的探索过程本身也能激发模型的通用潜力。 -
阶段二(针对性微调):在第一阶段的基础上加入SFT后,SNS-Bench和SNS-TransBench的分数大幅提升,而General-Bench的分数有轻微下降(从71.25降至70.04)。这清晰地展示了SFT的“双刃剑”特性:精准提升领域能力,但伴随着一定的通用能力损失。 -
阶段三(精炼学习):在完成前两阶段后,加入最后的RL精炼,所有三个基准的分数都得到了提升,实现了“全面进步”。这验证了第三阶段在巩固和平衡方面的作用。
3.3 在线应用效果
论文还将RedOne 2.0部署到线上,用于为用户帖子进行标题的二次创作,以提升内容的吸引力。
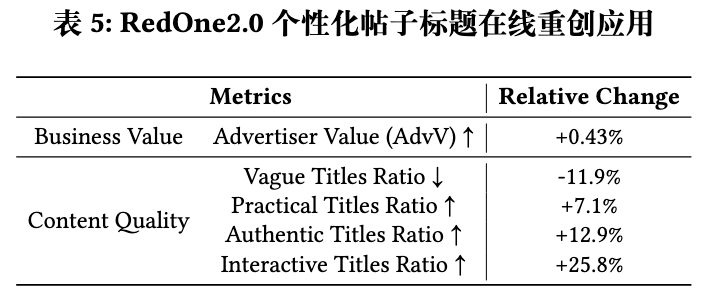
线上A/B测试结果显示,使用RedOne 2.0生成的标题,在商业价值指标(Advertiser Value)上提升了0.43%,内容质量指标(如减少模糊标题、增加互动性标题)也有显著改善。这为该框架的实际应用价值提供了直接证据。
4. 总结
RedOne 2.0 是一次在工业界真实场景下,针对LLM领域自适应问题进行的有价值的探索。它指出了单纯SFT方法的局限性,并提出了一个以RL为核心、结合SFT进行“诊断-修复-巩固”的渐进式后训练框架。该框架在平衡模型领域专业性和通用性、提升数据效率方面,展示了其潜力。
往期文章:


