对于开放式、创造性生成任务(open-ended, creative generation),例如撰写一篇小说、构思一首诗歌或草拟一份营销文案,并不存在唯一的、客观的“正确答案”。任务的成功与否依赖于原创性、情感共鸣、叙事连贯性等一系列主观和多维度的标准。这种评价标准上的模糊性,使得主流的两种增强模型推理能力的方法——强化学习(Reinforcement Learning, RL)和指令蒸馏(Instruction Distillation)——效果受限。
-
强化学习的困境:RL 依赖于一个明确的奖励模型(Reward Model, RM)。在开放式领域,构建一个能够准确评估生成内容主观质量的 RM 本身就是一个巨大的挑战。即便能够构建,RL 训练过程的样本效率低和计算成本高昂的问题也依然存在。 -
指令蒸馏的瓶颈:指令蒸馏通过让一个强大的“教师模型”(如 GPT-4)生成带有推理过程的范例,来训练一个“学生模型”。这种方法的成本高昂,且学生模型的能力上限被教师模型牢牢锁定,无法超越教师。此外,为复杂的开放式任务获取大量高质量的查询和深度推理轨迹本身就是一大难题。
这两个瓶颈共同构成了一个关键的研究空白:我们如何在缺乏明确任务可验证性的前提下,为开放式生成任务有效地注入深度推理能力?
来自字节跳动和多所高校的研究者在 arXiv 上提交的论文《Reverse-Engineered Reasoning for Open-Ended Generation》提供了一个新的视角。他们提出的逆向工程推理(Reverse-Engineered Reasoning, REER)范式,从根本上改变了教会模型“思考”的方式。它不再尝试通过试错或模仿来“正向”构建一个推理过程,而是反其道而行之:从一个已知的高质量结果出发,“反向”推导出可能产生这个结果的、合乎逻辑的、类似人类的思考过程。

-
论文标题:Reverse-Engineered Reasoning for Open-Ended Generation -
论文链接:https://arxiv.org/pdf/2509.06160
1. REER 核心思想
REER 的核心思想可以概括为一种视角的转换。传统方法问的是:“对于这个问题,如何一步步思考得到答案?”;而 REER 问的是:“对于这个已知的优质答案,一个合理的思考过程是怎样的?” 这种“由果溯因”的思路,巧妙地规避了在开放式领域定义“好”与“坏”的过程的难题,而是直接利用已经存在的“好”的结果。
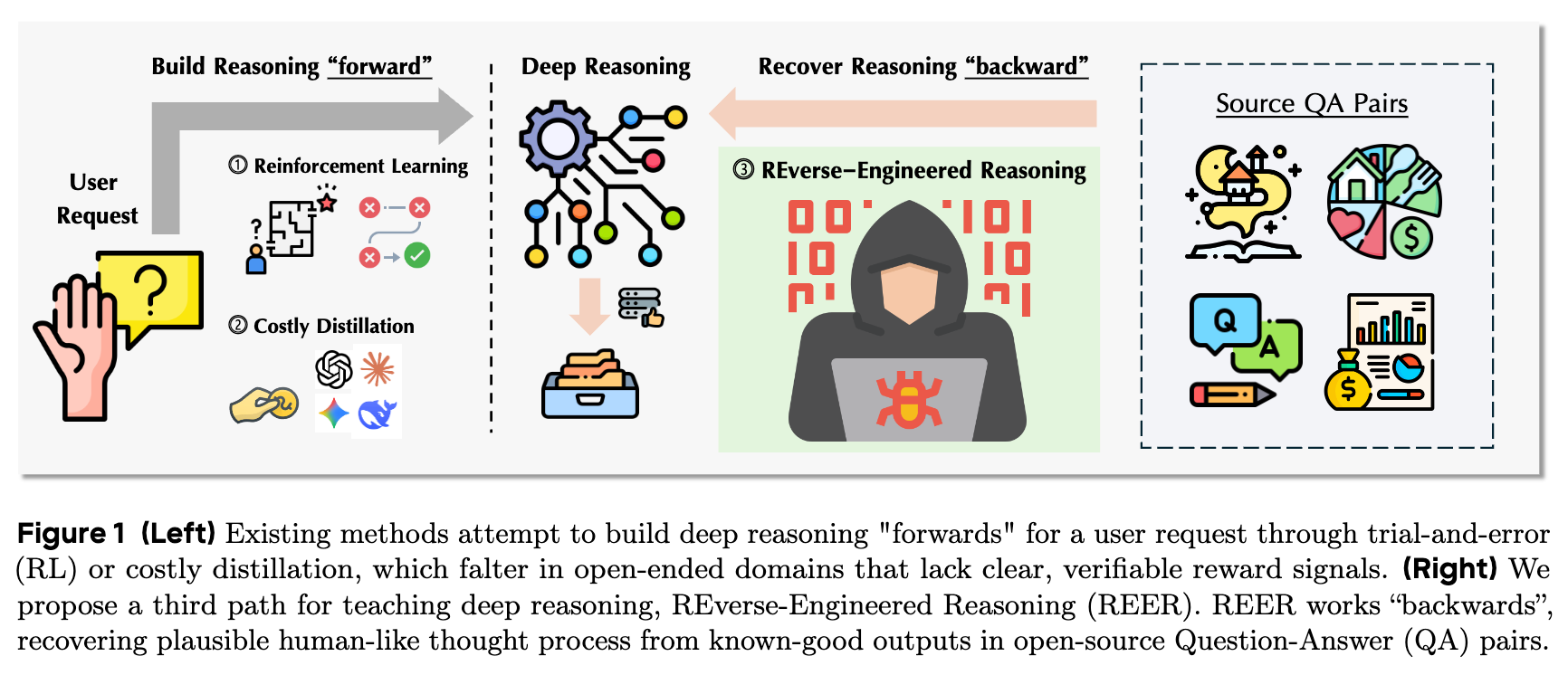
上图直观地展示了 REER 与传统方法的区别。左侧的强化学习和指令蒸馏都是“正向”构建推理过程,前者通过试错探索,后者通过模仿学习。而右侧的 REER 则是从已有的高质量问答(QA)对中,“逆向”恢复出潜在的、合理的思维过程。
1.1 将推理过程的发现形式化为搜索问题
为了将这个思想落地,研究者们将其形式化为一个优化问题。让我们定义几个关键变量:
-
:输入的查询(input query),例如一个写作提示。 -
:一个高质量的参考解决方案(reference solution),例如一篇优秀的范文。 -
:一个深度推理轨迹(deep reasoning trajectory),它代表了一个结构化的、分步的思考过程。这个轨迹 可以被看作是一系列离散的思考步骤组成的序列:。
REER 的目标是找到一个最优的推理轨迹 ,这个 能够最好地“解释”为什么从查询 会生成解决方案 。
那么,如何衡量一个推理轨迹 对 的“解释得有多好”呢?这正是 REER 的巧妙之处。在缺乏外部验证信号的情况下,研究者们引入了一个内部的、可计算的代理指标(proxy):参考解决方案 的困惑度(Perplexity)。
具体来说,他们使用一个生成式 LLM 来计算在给定查询 和推理轨迹 的条件下,生成参考方案 的困惑度,记为 。困惑度是衡量一个语言模型对其预测的样本有多“惊讶”(surprised)的指标。一个较低的困惑度意味着,在模型看来,给定 和 作为前提,生成 是一个非常自然、顺理成章、概率高的事件。
因此,REER 的核心假设是:一个好的思考过程 ,应该能让一个高质量的答案 看起来是意料之中、顺理成章的产物。
基于这个假设,寻找最优推理轨迹 的问题就被形式化为以下搜索问题:
其中 代表所有可能的推理轨迹的巨大空间。这个公式的含义是:在所有可能的思维路径中,找到那条能让参考答案 的困惑度最小化的路径 。
这个形式化定义有几个优点:
-
规避了主观评价:它不需要一个外部的奖励模型来判断 的好坏,而是通过 对 的“解释能力”来间接评估 的质量。 -
目标可计算:困惑度 是一个可以通过 LLM 直接计算的量,这使得优化过程成为可能。 -
梯度无关:整个优化过程是基于离散的文本序列 进行的,因此可以采用梯度无关的搜索算法来求解,这为算法设计提供了灵活性。
2. 通过迭代式局部搜索发现推理轨迹
直接在庞大的轨迹空间 中求解 是一个 intractable 的问题。因此,研究者们设计了一种迭代式优化算法,该算法采用引导式局部搜索(guided local search)的策略来逐步发现高质量的深度推理轨迹。
这个算法从一个初始的、不完美的轨迹开始,然后通过迭代地、逐段地优化这个轨迹来不断提升其质量,直到满足终止条件。整个过程可以分解为四个主要步骤:
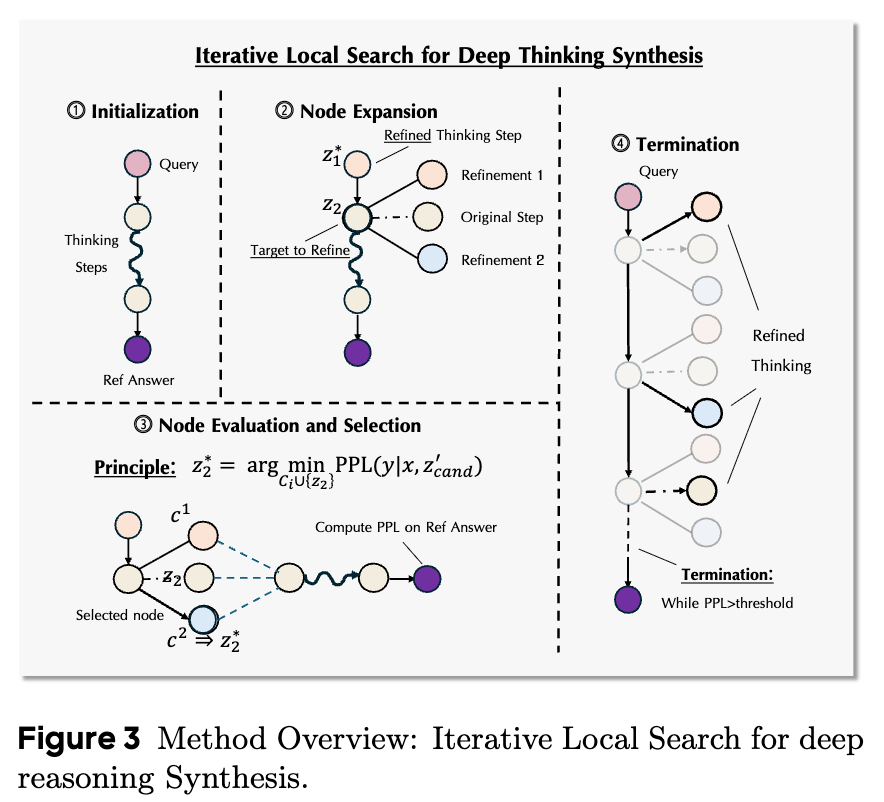
2.1 步骤一:初始化 (Initialization)
对于一个给定的 对,算法首先需要一个初始的推理轨迹 。这个初始轨迹是通过一个精心设计的 thought-provoking 指令(见论文附录 Listing 1)来提示一个 LLM 生成的。这个提示会要求模型为给定的解决方案 生成一个貌似合理的计划。这个初始轨迹 通常是比较粗糙和简单的,可以表示为 。
2.2 步骤二:节点扩展(逐段优化) (Node Expansion / Segment-wise Refinement)
这是算法的核心循环。在每次迭代中,算法会选择轨迹 中的一个片段 进行优化。然后,它会提示 LLM 生成多个候选的优化片段(candidate refinements),这些候选片段应该包含更丰富的思考细节、阐述和反思。
为了生成这些候选片段,提供给 LLM 的上下文(context)是至关重要的。这个上下文包含了:
-
原始查询 。 -
参考解决方案 。 -
围绕目标片段 的上下文轨迹:即在 之前已经优化过的片段和在 之后尚未优化的初始片段。
研究者们特别设计了这一步的提示(见论文附录 Listing 2),以鼓励模型进行详细的推理,同时避免模型仅仅从参考方案 中抄袭内容。
2.3 步骤三:节点评估与选择 (Node Evaluation and Selection)
对于上一步生成的每一个候选优化片段 ,算法会构建一个临时的完整轨迹 ,即用候选片段 替换原始轨迹中的 。
接下来,算法会计算每一个候选轨迹的质量得分 。得分最低(即困惑度最低)的那个候选片段将被选为本次迭代的胜出者,并用它来更新轨迹中的 。
一个关键的细节是,原始的片段 本身也会被包含在候选集 中进行评估。这意味着,如果所有新生成的候选片段都不能让困惑度降低,算法会选择保留原始片段。这保证了在整个迭代过程中,轨迹的质量(以困惑度衡量)是单调不减的(或者说,困惑度是单调不增的)。
更新规则可以表示为:
。
2.4 步骤四:终止 (Termination)
这个逐段优化的迭代过程会一直重复,直到满足以下任一条件:
-
参考解决方案的困惑度 降低到了一个预设的目标阈值。 -
迭代次数达到了一个预设的最大值。
当算法终止时,输出的便是一个经过多轮优化的、高质量的推理轨迹 。
2.5 与 MCTS/Beam Search 的对比
值得注意的是,REER 的这种迭代式局部搜索与蒙特卡洛树搜索(MCTS)或束搜索(Beam Search)等方法有本质区别。
-
避免了昂贵的 Rollouts:MCTS 需要通过大量的随机“rollouts”来评估一个部分状态的价值,这在文本生成领域计算成本极高。REER 通过使用完整参考方案的困惑度作为代理指标,完全避免了这一过程。 -
“从全局到局部”的优化原则:MCTS 和 Beam Search 通常是“从局部到全局”的,它们通过逐步扩展部分解来构建一个完整的解。而 REER 则是先生成一个完整但不完美的全局计划 ,然后通过对局部片段的迭代优化来完善这个全局计划。
这些特点使得 REER 成为一种可扩展且高效的方法,能够为大规模地创建深度推理数据集提供可能。
3. DeepWriting-20K 数据集的构建
拥有了 REER 算法,下一步就是利用它来构建一个大规模、高质量的训练数据集。这个数据集的构建过程同样体现了研究者们严谨的工程实践。数据集被命名为 DeepWriting-20K。
3.1 (Query, Solution) 对的源数据 sourcing
为了保证数据集的多样性,初始的 对来源于三个渠道:
-
公共写作平台:研究者们从 r/WritingPrompts等社区抓取了大量的“写作提示-故事”对。他们利用社区的点赞数作为初始的质量代理指标,筛选出受欢迎的作品。 -
公共领域文学作品:他们使用古腾堡计划(Project Gutenberg)中的经典文学作品作为高质量的解决方案 。然后,利用 GPT-4o 对这些作品的开头段落进行“逆向工程”,生成貌似合理的查询 。 -
公共数据集:他们还从 WildChat和LongWriter6K等指令微调数据集中扩充了数据来源,以增加数据的广度和多样性。
3.2 轨迹合成与过滤
从源数据中,研究者们精心挑选了 20,000 个高质量的 对,这些数据对覆盖了 25 个手动指定的类别,确保了主题的广泛性。对于每一个 对,他们都执行了前文所述的迭代式局部搜索算法,来生成一个最优的深度推理轨迹 。
3.2.1 上下文工程 (Context Engineering)
研究者们发现,搜索算法的有效性不仅取决于搜索过程本身,还高度依赖于用于引导 LLM 的指令的精巧设计。他们提出了几个关键的“上下文工程”技巧,以确保合成的轨迹质量:
-
通过元结构强制进行逐段编辑 (Enforcing Segment-wise Edits via a Meta-Structure) :为了确保 LLM 在优化某个片段 时,不会不受控制地修改轨迹的其他部分,他们在提示中设计了一种元结构。这种结构像一个隐式的正则化器,帮助模型将其注意力“本地化”到当前需要编辑的片段上。 -
注入类人思考模式 (Injecting Human-like Thinking Patterns) :为了避免生成的推理过程过于刻板和公式化,他们在提示中明确鼓励模型使用一些能够体现认知探索和自我反思的短语。例如: -
“嗯... 也许我可以...” (Hmm... maybe I can...) -
“等等,这个思路有点...” (Wait, that's a bit...) -
“让我想想...” (Let me think...)
这些短语能够激发模型产生更自然、更灵活的推理风格,并激励其在训练中进行自我反思。
-
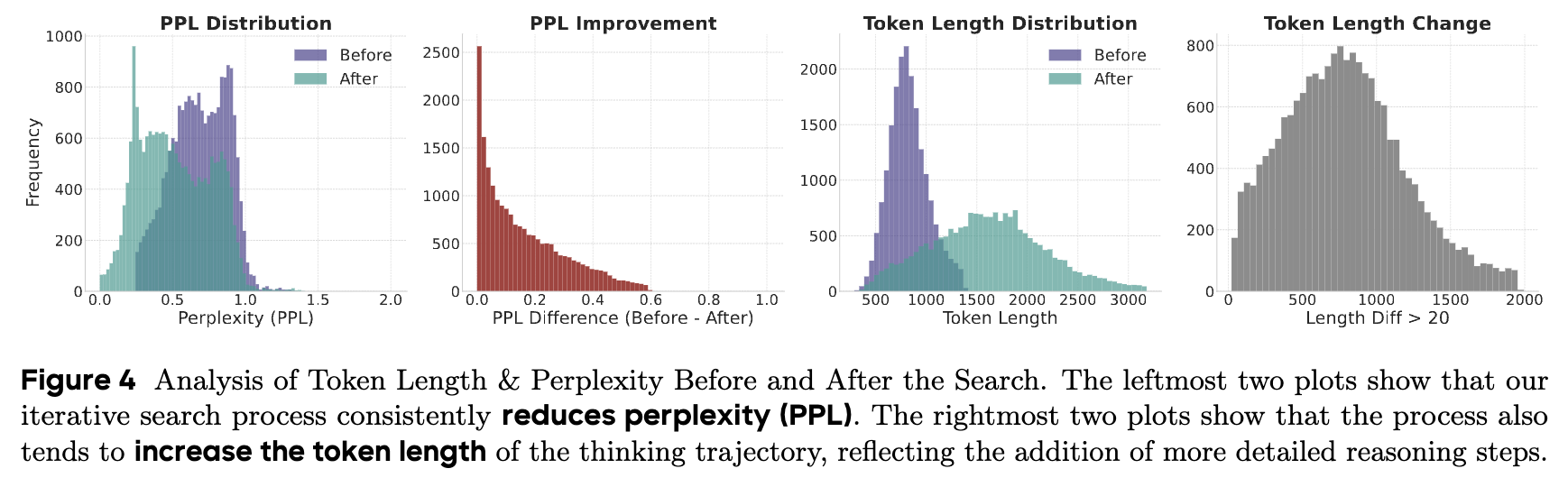
上图展示了合成过程的有效性。左侧两个图表显示,经过迭代优化后,样本的困惑度(PPL)分布显著左移,即 PPL 普遍降低,证明了优化目标的达成。右侧两个图表显示,轨迹的 token 长度在优化后显著增加,这表明搜索过程成功地将简单的初始计划扩展成了更详细、更复杂的推理链。
3.2.2 启发式过滤策略
在指令微调过程中,研究者观察到了重复性和退化思维的挑战。为了提升数据质量,他们采用了两种启发式过滤策略来剔除低质量的轨迹:
-
思维终结过滤 (End-of-Thinking Filtering) :他们丢弃了那些在轨迹的最后 10% 部分仍然出现思考模式(如 "Hmm...")的样本。这些样本可能表明模型陷入了重复循环,未能有效地结束其推理过程。 -
重复性过滤 (Repetition Filtering) :他们使用了一个重复性指标来衡量每个轨迹中 top-3 n-grams 的出现频率。那些表现出高度 n-gram 重复的样本被认为是退化循环的标志,并被过滤掉。
经过这一系列流程,最终产出了一个包含 20,000 个高质量 三元组的数据集。
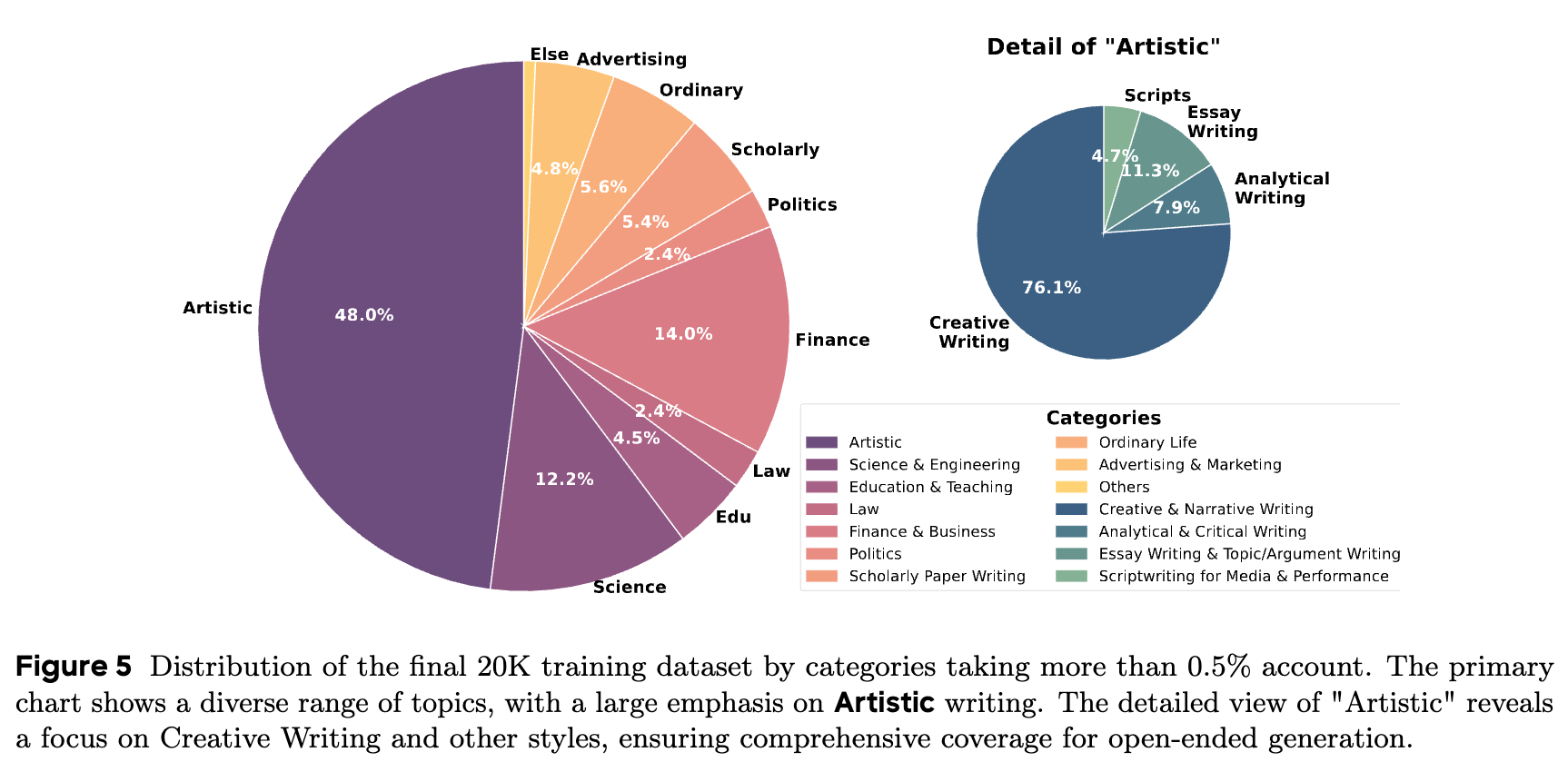
上图展示了数据集的类别分布,可以看出其多样性,并特别侧重于艺术性(Artistic)写作,其下又细分为创意写作、议论文写作等子类,确保了在开放式生成领域有足够的覆盖。
3.3 最终数据集的组装与微调
如果一个模型只在特定领域的数据上进行训练,可能会导致其泛化能力下降,即所谓的“灾难性遗忘”。为了缓解这个问题,研究者们采取了混合数据训练策略 (mixed-data training strategy) 。
他们将自己合成的 20K DeepWriting 数据集与一个公共的、覆盖数学、编程和科学等领域的深度推理数据集 OpenThoughts 进行混合。这种混合策略旨在平衡模型在学习开放式生成深度推理能力的同时,不丢失其在其他领域的通用推理能力。
最终,每个数据三元组 被格式化为一个特定的提示模板,该模板显式地教导模型先进行 <think> 过程,再产出 <answer>。这种结构化的训练方式旨在让模型将这种“先思后行”的推理过程内化(internalize)。
4. 实验
为了严格验证 REER 方法的有效性,研究者们进行了一系列全面的实验。他们旨在回答两个核心问题:
-
DeepWriter-8B(基于 REER 数据集从头微调的 8B 开源模型)与业界领先的专有模型以及其他强大的开源模型相比,表现如何? -
REER 方法中的各个核心组成部分——合成的深度思维轨迹、迭代优化算法、思维轨迹的特性以及数据构成——各自对模型的最终性能有何贡献?
4.1 实验设置
-
训练数据:主训练集是前述的 DeepWriting-20K,与 OpenThoughts数据集混合后,最终形成一个约 37,000 个样本的混合数据集。 -
基础模型:选择了 Qwen1.5-7B-Base 作为微调的基础模型。研究者提到,在初步实验中,其他候选模型(如 Llama-3.1-8B-Base)在内化深度思考过程方面存在困难,而 Qwen-2.5-7B-Base 则有上下文长度的限制。 -
生成模型:在关键的轨迹合成阶段,使用的是 Qwen2.5-32B-Instruct 作为生成器LLM。 -
微调细节:模型训练了 3 个 epoch,使用固定的学习率 ,全局批量大小为 96。
4.2 评测基准 (Evaluation Benchmarks)
为了进行全面和多维度的评估,研究者们使用了三个互补的评测基准:
-
LongBench-Write (LB) :这是一个针对超长文本生成(>10,000 词)的压力测试,旨在衡量模型在维持长程主题一致性方面的基础能力。 -
HelloBench (HB) :这个基准旨在评估模型的实际应用能力,包含了大量来自真实用户查询的“in-the-wild”任务。实验重点关注两个子集:HB-A (开放式问答) 和 HB-B (启发式文本生成,如创意写作和风格模仿)。 -
WritingBench (WB) :这是一个专门为衡量领域专业写作和可控性而设计的基准,覆盖六个专业和创意领域(A:学术与工程, B:金融与商业, C:政治与法律, D:文学与艺术, E:教育, F:广告与营销)。
由于这些任务的主观性,评测采用了强大的 LLM 作为裁判的协议。具体来说,Claude-3.7 被用于 LongBench 和 WritingBench 的打分,而 GPT-4o 被用于 HelloBench 的打分。
4.3 主要结果分析
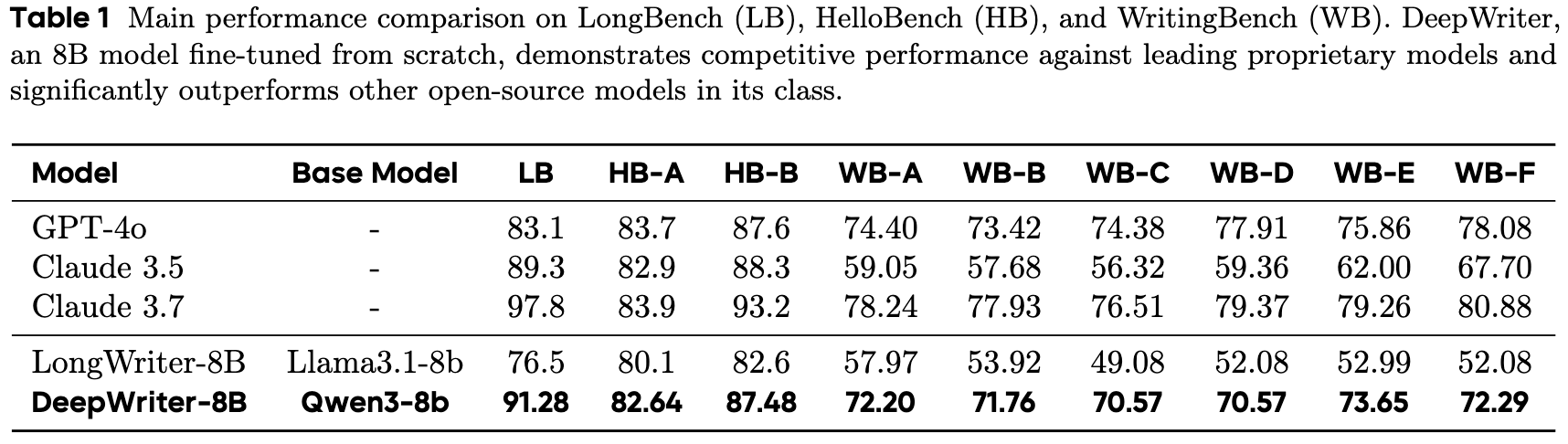
上表中的结果揭示了几个有力的发现:
-
DeepWriter-8B 显著优于强大的开源基线:与同样是 8B 规模的强基线模型 LongWriter-8B 相比,DeepWriter-8B 在所有基准测试中都取得了大幅度的性能提升。尤其是在多样化的 WritingBench 领域,DeepWriter-8B 的平均得分提升超过了 18 分。这凸显了 REER 深度思维合成方法相比于标准指令微调在培养高级生成技能方面的优势。
-
DeepWriter-8B 大幅缩小了与顶尖专有模型的差距:
-
在创意性任务 HelloBench (HB-B) 上,DeepWriter-8B 的得分(87.48)与 GPT-4o(87.6)和 Claude 3.5(88.3)在统计上已处于同一水平。 -
在 WritingBench 的专业写作任务中,DeepWriter-8B 不仅在所有六个类别中都大幅超越了 Claude 3.5,甚至与体量远大于它的 GPT-4o 和 Claude 3.7 模型相比也保持了高度的竞争力。 -
一个值得注意的结果是,在 LongBench-Write 上,DeepWriter-8B 的得分(91.28)超过了 GPT-4o(83.1)和 Claude 3.5(89.3)。这表明,通过显式地训练结构化的思维轨迹,模型获得了强大的归纳偏置(inductive bias),有助于维持超长文本的连贯性。
-
4.4 消融研究 (Ablation Studies)
为了细致地剖析方法中每个组成部分的贡献,研究者们进行了一系列的消融实验。

这些消融实验为 REER 的方法论设计提供了坚实的证据支持:
-
合成数据的重要性 (Importance of Synthesized Data) :当移除 20K 的 REER 合成轨迹,仅在公共思维数据集上训练时(“- Remove Synthesis Data”),模型性能出现了最显著的下降。尤其是在 HelloBench HB-B (87.48 → 73.73) 和 WritingBench (平均下降超过 8 分) 等创意任务上。这证实了一个核心假设:重要的不仅仅是存在“思考”数据,而是这些结构化轨迹的质量以及它们是否为开放式领域量身定制。
-
迭代优化的影响 (Impact of Iterative Refinement) :如果使用初始的、未经优化的思维轨迹 进行训练(“- Remove Iterative Search”),性能同样出现明显下降。虽然下降幅度不及完全移除合成数据,但在精细的 WritingBench 任务上(例如 WB-A: 72.20 → 66.72)仍然是巨大的。这证明了以困惑度为导向的局部搜索是发现高质量推理路径的有效手段,而这些高质量路径能直接转化为更强的生成能力。
-
反思性标记的作用 (Effect of Reflection Tokens) :在合成数据的提示中移除那些类人反思标记(如 'Hmm...', 'Wait, that's...')(“- Remove Reflection Tokens”),对模型性能有细微的影响。整体得分略有下降,但最显著的下降出现在 WritingBench 的 D 领域(文学与艺术),从 70.57 降至 62.04。这表明,这些显式的认知探索、自我纠正和分支思考的标记,对于培养艺术性写作所需的灵活性和创造力尤为重要。
-
轨迹长度的角色 (Role of Trajectory Length) :通过选择性地对长轨迹或短轨迹进行降采样,研究者们探究了轨迹长度的影响。结果显示出任务依赖性:移除更长、更复杂的轨迹(“- Downsample Long Traces”)对复杂的、领域特定的 WritingBench 任务伤害更大;相反,移除更短、更简洁的轨迹(“- Downsample Short Traces”)对像 HB-B 这样的创意任务有略大的负面影响。这或许说明,结构化的专业写作需要详尽的多步规划,而创意构思则可能更受益于敏捷、直接的推理。
-
文学与艺术数据的作用 (Role of Literature & Arts Data) :移除来自“文学与艺术”和“日常生活”领域的数据后,模型在所有基准上的性能都有所下降,而不仅仅是在对应的 WB-D 类别上。这个发现表明,在创意和叙事任务上的训练,能够赋予模型一种更普适的能力来处理细微差别、结构和开放性,这种能力甚至可以迁移并有益于更技术性的领域。
4.5 定性分析
除了定量的分数,研究者们还进行了定性分析,以更深入地理解 DeepWriter-8B 内化深度思维的质量。
4.5.1 深度思维的生成质量
他们从五个与高级推理和规划密切相关的维度对模型的输出进行了评分:
-
问题解构 (Problem Deconstruction) -
逻辑一致性 (Logical Consistency) -
分析深度 (Depth of Analysis) -
表达清晰度 (Presentation Clarity) -
事实 grounding (Factual Grounding)
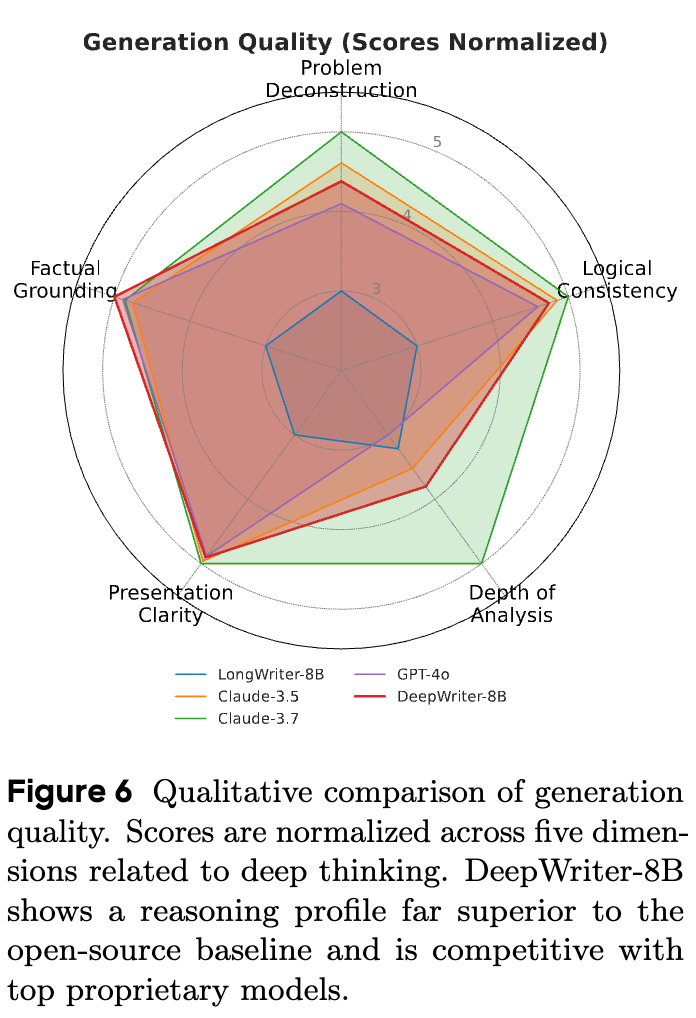
如雷达图所示,DeepWriter-8B 的推理能力画像在所有五个维度上都显著地包围了开源基线 LongWriter-8B,显示了其在底层推理能力上的全面提升。更重要的是,DeepWriter-8B 的画像与 GPT-4o 高度接近,并显著优于 Claude 3.5,尤其是在分析深度和事实 grounding 这两个维度上。这验证了 REER 方法的核心主张:通过梯度无关的合成方法注入深度思维过程,是构建更强大、更可扩展模型的一条有前景的路径。
4.5.2 思维模式的定性比较
为了理解“注入类人思考模式”对模型行为的具体影响,研究者们比较了完整模型和移除了反思性标记的消融模型在生成推理轨迹时所使用的思考短语的频率。
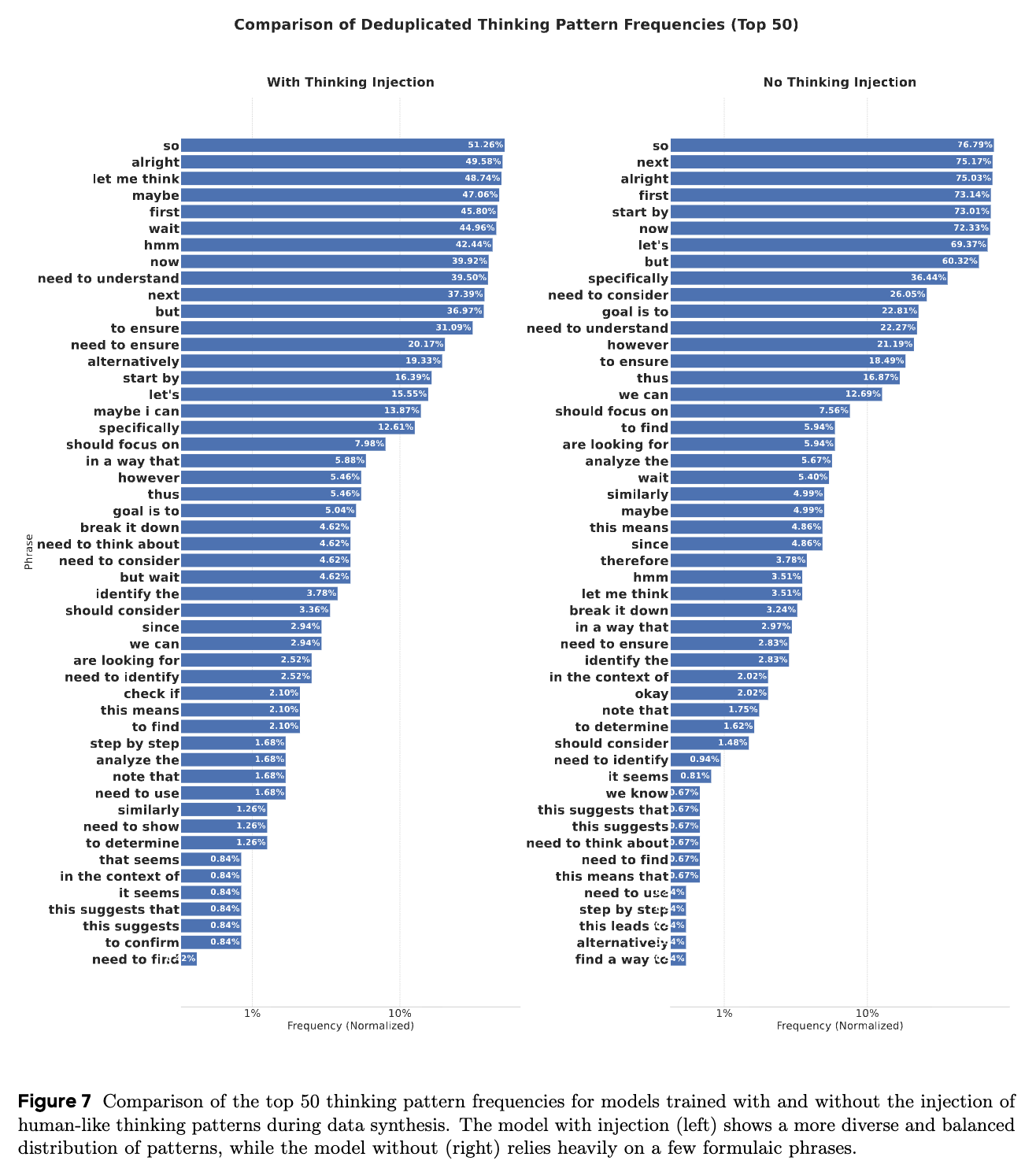
结果差异明显。左图(完整模型)显示了更多样化、更均衡的思考模式分布。像 ‘let me think’, ‘maybe’, ‘hmm’, ‘wait’ 等表示反思和自我纠正的词语非常突出,这表明模型在进行一种更灵活、更富探索性的类人推理。相比之下,右图(消融模型)严重依赖少数几个公式化的短语,如 ‘next’, ‘first’, ‘alright’,其频率分布高度倾斜,显示出一种更刻板、更程序化的推理过程。
这个分析证实了上下文工程技术的有效性,它鼓励模型采纳一种更细致、更具反思性的解决问题的方法,而这种方法在消融研究中被证明对于创造性和复杂任务尤其有益。
点评
这篇论文最大的贡献是提出了 REER 范式,从根本上改变了为开放式任务注入推理能力的思路。传统方法(RL/蒸馏)试图“正向”构建一个从“问题”到“答案”的推理链,但在主观任务上因缺乏明确的奖励/监督信号而受阻。REER “由果溯因”,从一个已知的“好答案”反推其“合理的思考过程”,巧妙地规避了定义“好过程”这一核心难题。这种问题重构的思路本身就极具启发性。
REER 被论文作者称为“第三条道路”,因为它在实践中确实提供了一种兼具可扩展性和成本效益的方案。相比于 RL 训练的巨大算力开销和样本低效,以及指令蒸馏对昂贵闭源 API 的大量调用,REER 的数据合成过程虽然计算密集,但它是一个一次性的、离线的、可自动化的过程。一旦高质量的 (x, y) 对被收集,就可以大规模地并行生成推理数据,这对于想要在特定领域构建深度推理能力的团队来说,具有很高的实用价值。
DeepWriting-20K 数据集: 开源了一个精心构建的、专注于开放式生成的大规模推理数据集,直接解决了该领域数据稀缺的问题。
“最低困惑度”等同于“最佳思考过程”是一个强大但值得深思的假设。对于某些极具创造力、跳跃性的内容(比如一首超现实主义的诗或一个情节反转惊人的短篇故事),其背后的人类思考过程可能恰恰是反直觉、不那么“顺理成章”的。过度优化困惑度可能会倾向于生成那些逻辑上更平铺直叙、更保守、更符合模型“认知”的推理路径,从而可能过滤掉那些更具风险但也更具创造性的“神来之笔”式的思考过程。


