大型语言模型(LLMs)的出现,让我们看到了AI在处理复杂推理任务(如数学解题和编程)方面的能力。然而,这些模型在面对看似简单的交互式任务时,却常常显得力不从心。
这种现象揭示了两种知识形态的本质区别:陈述性知识(Declarative Knowledge),即“知道某事”,和程序性知识(Procedural Knowledge),即“知道如何做某事”。传统的强化学习(RL)智能体擅长通过与环境互动来获取程序性知识,但它们通常像一个“黑箱”,需要海量的训练数据,并且难以解释其决策背后的原因。相比之下,LLMs拥有丰富的世界知识和推理能力(知其然,并知其所以然),但却无法将这些静态知识有效地转化为动态环境中的决策能力。
为了解决这一难题,来自腾讯的研究团队发表了一篇名为《Think in Games: Learning to Reason in Games via Reinforcement Learning with Large Language Models》的论文,提出了一种名为“Think-In Games”(TiG)的新颖框架。该框架旨在让LLM通过与游戏环境(《王者荣耀》)的直接互动来培养程序性理解能力,同时保留其固有的推理和解释能力。

-
论文标题:Think in Games: Learning to Reason in Games via Reinforcement Learning with Large Language Models -
论文链接:https://arxiv.org/pdf/2508.21365

1. 挑战与机遇
LLMs能够写诗、解题,甚至生成代码,但在需要与环境持续互动的任务中,它们的能力却受到了限制。例如,在简单的游戏环境中进行导航,或者理解基本的空间关系和因果联系,这些对于人类儿童来说轻而易举,但对强大的LLM来说却是一个挑战。
这种“知”与“行”的分离,是当前AI发展面临的一个根本性障碍。要跨越这道鸿沟,AI需要一个可以安全探索、实验并从结果中学习的环境。
数字游戏,尤其是像《王者荣耀》这样的多人在线战术竞技(MOBA)游戏,为此提供了一个近乎完美的试验场。 这类游戏环境具有以下特点:
-
受控且复杂:游戏世界有明确的规则,但其内部状态和可能性组合又极其丰富,要求智能体将理论知识转化为实际操作。 -
多轮互动:游戏本质上是一个持续决策的过程,智能体必须根据环境的实时反馈不断调整策略。 -
高层次战略思维:MOBA游戏不仅仅是操作的比拼,更强调团队协调、长期规划和动态目标管理,这对AI的战略推理能力提出了很高的要求。
传统的游戏AI,无论是基于搜索算法还是强化学习,虽然在特定游戏中取得了成果,但它们往往依赖大量领域相关的工程设计和训练,泛化能力有限,且决策过程不透明。而LLM的出现,为解决这些问题带来了新的可能性。
然而,初步研究表明,直接将LLM应用于复杂动态游戏并不容易。它们从网络文本中学到的知识是静态的。例如,一个LLM可能从游戏攻略中知道“不要推线太深”的策略,但它无法理解“太深”在具体游戏情境下的精确定义,这种理解只能通过实际的游戏经验获得。
这便是TiG框架试图解决的核心悖论:
-
传统RL智能体:知道如何做,但无法解释为什么。 -
大型语言模型:知道为什么,但无法执行如何做。
TiG框架的目标,就是融合二者之长,创造出一个既能有效决策,又能清晰解释其背后逻辑的AI智能体。
2. TiG框架详解:将决策重塑为语言建模任务
TiG的核心思想是将传统的强化学习决策过程,重新定义为一个语言建模任务。在这个框架下,LLM不再是简单地输出一个离散的动作指令,而是生成一段语言引导的策略(Policy),这段策略随后会通过与游戏环境的在线互动和反馈进行迭代式优化。
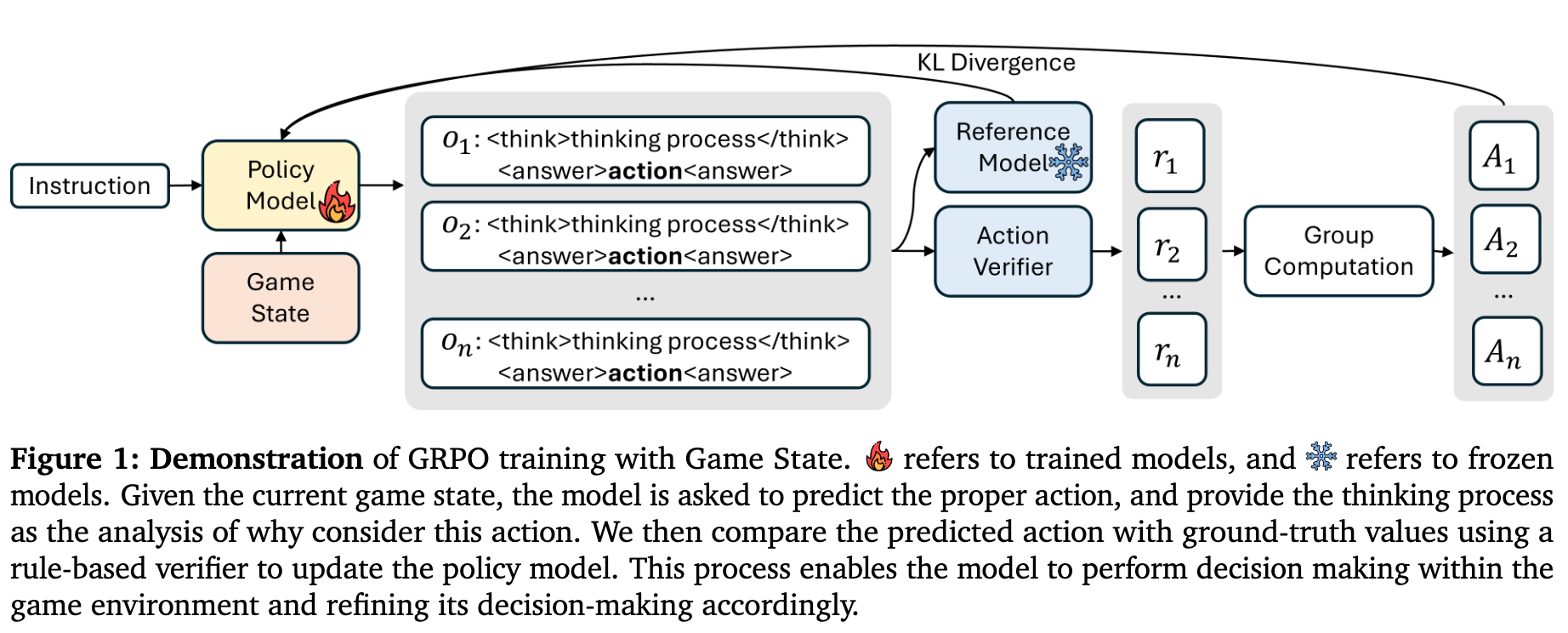
上图展示了TiG框架的训练流程。给定当前的游戏状态,策略模型(LLM)被要求预测合适的动作,并提供其思考过程作为分析。然后,系统会使用一个基于规则的验证器(Action Verifier)将预测的动作与基准值(ground-truth)进行比较,以更新策略模型。这个过程让模型能够在游戏环境中进行决策,并相应地优化其决策能力。
2.1 形式化定义:构建LLM能理解的游戏世界
为了让LLM能够处理游戏信息,TiG框架对游戏环境进行了精心的形式化定义。
游戏状态表示 (Game State Representation)
游戏环境被看作一系列离散的时间步。在每个时间步 ,都有一个对应的综合游戏状态 。这个状态 包含了从主玩家视角看到的所有用于战略决策的可见信息,例如:
-
队友的属性 -
可见的防御塔状态 -
地图视野数据
为了保持真实的游戏体验,像不可见的敌人状态这类隐藏信息被排除在外。为了利用LLM处理结构化数据的能力,每个游戏状态 都被表示为一个JSON对象。这种格式有助于模型更好地理解和解析复杂的游戏信息。

宏观动作空间 (Macro-level Action Space)
为了让模型专注于战略层面的推理,而不是底层的微操(如精确的技能释放),TiG定义了一个有限的宏观动作集合 。每一个动作 都对应一个预定义的团队目标,例如:
-
“推进上路兵线”(Push Top Lane) -
“夺取巨龙”(Secure Dragon) -
“防守基地”(Defend Base)
在论文的设定中,这个集合包含了40个宏观动作,全面覆盖了游戏中有意义的战略选择。这种抽象化的动作空间不仅引导模型进行高层次的思考,也为后续基于规则的奖励设计和评估提供了便利。
策略模型 (Policy Model)
TiG框架中的策略模型就是一个经过训练的LLM。它的任务是将输入的游戏状态映射到宏观动作。框架对模型的具体架构没有硬性限制,只要求它具备强大的指令遵循和结构理解能力。
2.2 任务定义:学习“思考”与“行动”的映射
TiG的任务可以被形式化地描述为一个映射学习:
其中:
-
是当前的游戏状态。 -
是提供给LLM的任何额外上下文或指令。 -
是模型预测出的下一个最优宏观动作。 -
是模型为达到该决策所生成的相应推理链(reasoning chains)。
这个任务鼓励LLM分析当前环境,提取关键信息,并用自然语言预测最合适的宏观动作。为了实现这一点,研究者设计了一个特定的提示模板(Prompt Template)。

在这个模板中,<game_state> 占位符会在训练和推理时被真实的游戏状态JSON数据替换,而 <action_candidates> 则会被预定义的宏观动作列表替换。模型需要填充 <think> 和 <answer> 部分,前者是其决策的思考过程,后者是最终的行动建议。
3. 方法论:从数据到模型的强化学习
TiG框架的实现依赖于一套系统化的数据处理和强化学习流程。
3.1 数据集构建
TiG的数据来源于匿名的真实玩家对战记录。为了保证数据的质量和均衡性,数据集的采集遵循以下原则:
-
隐私保护:不收集任何用户标识符或个人身份信息。 -
数据均衡:保持胜负对局的比例均等。 -
玩家水平:只包含高于特定技能门槛的玩家对局。
数据采样与重标注算法
从每场对局中,首先会提取完整的游戏状态序列。然而,原始的玩家动作标签可能是稀疏或不一致的。为了解决这个问题,研究者开发了一套重标注算法(Relabeling Algorithm)来稠密化和顺滑化动作序列。
这个算法的核心是基于优先级的宏观动作层级(Priority-based Hierarchy of Macro-level Action)。在游戏中,不同动作的优先级是不同的。例如,“争夺主宰或暴君”和“进行团战”这类关键目标的优先级通常高于常规的清线或打野。
研究者将动作的优先级形式化为一个函数:
基于专家知识,他们为所有宏观动作定义了一个优先级层级。重标注算法首先会将一个已知的动作标签向前回溯填充一定数量的未标记帧,然后在一个时间窗口内,利用预定义的优先级层级来解决可能出现的动作冲突,确保每个时间帧的标签都反映了当时最关键的宏观动作。
通过这种方式,算法生成了一个稠密且一致的游戏状态序列,为下游的学习任务提供了高质量的训练信号。
3.2 使用GRPO算法优化游戏策略
为了让模型能够有效地学习战略推理,TiG采用了一个强化学习框架,直接利用游戏状态-动作对的反馈来优化策略模型。具体来说,研究者采用了群体相对策略优化(Group Relative Policy Optimization, GRPO)算法。
GRPO是一种在线RL算法,旨在最大化生成完成(completions)的优势,同时限制策略与参考模型的偏离。 相比于传统的RL算法(如PPO),GRPO在处理长而结构化的输出时,能更好地应对奖励方差大和信用分配效率低的问题。 它通过利用组内的相对优势来标准化奖励,从而稳定训练过程。
GRPO 形式化
在TiG的训练过程中,对于一个给定的提示(包含游戏状态 ),当前策略 会生成一组(例如 个)不同的完成(即思考过程和动作)。对于每个完成 ,系统会通过一个基于规则的奖励函数计算出一个奖励 。
然后,计算每个完成的群体相对优势(group-relative advantage):
这里的 和 分别是该组内所有奖励的均值和标准差。这种归一化处理确保了优势值反映的是每个完成在当前群体中的相对质量。
GRPO的总体目标函数旨在最大化期望的群体相对优势,同时通过KL散度来惩罚策略的过度漂移。
奖励建模 (Reward Modeling)
奖励函数是RL中的核心训练信号。TiG采用了一个简单的、基于规则的二元奖励系统。给定模型在时间步 预测的动作 和从回放数据中得到的真实动作 ,奖励 的定义如下:
如果预测动作与真实动作匹配,奖励为1;否则为0。这种二元奖励机制鼓励模型生成与真实玩家行为高度一致的动作预测,同时惩罚冗长或不相关的输出。这种设计避免了训练一个复杂的神经奖励模型的需要,降低了计算成本和复杂性。
4. 实验与结果分析
研究者在一系列实验中对TiG框架进行了验证,实验环境基于MOBA游戏《王者荣耀》。
4.1 实验设置
-
基线模型:实验包含了多种不同规模的开源LLM作为基线,包括Qwen系列的多个模型(Qwen-2.5-7B, Qwen-2.5-14B, Qwen-2.5-32B, Qwen-3-14B)和Deepseek-R1。 -
训练策略:研究者探索了不同的多阶段训练组合: -
仅GRPO:只使用GRPO训练基础模型。 -
仅SFT:只使用监督微调(Supervised Fine-Tuning)训练基础模型。 -
SFT + GRPO:先用SFT进行训练,然后用GRPO算法进一步提升模型的推理能力。
-
4.2 主要发现
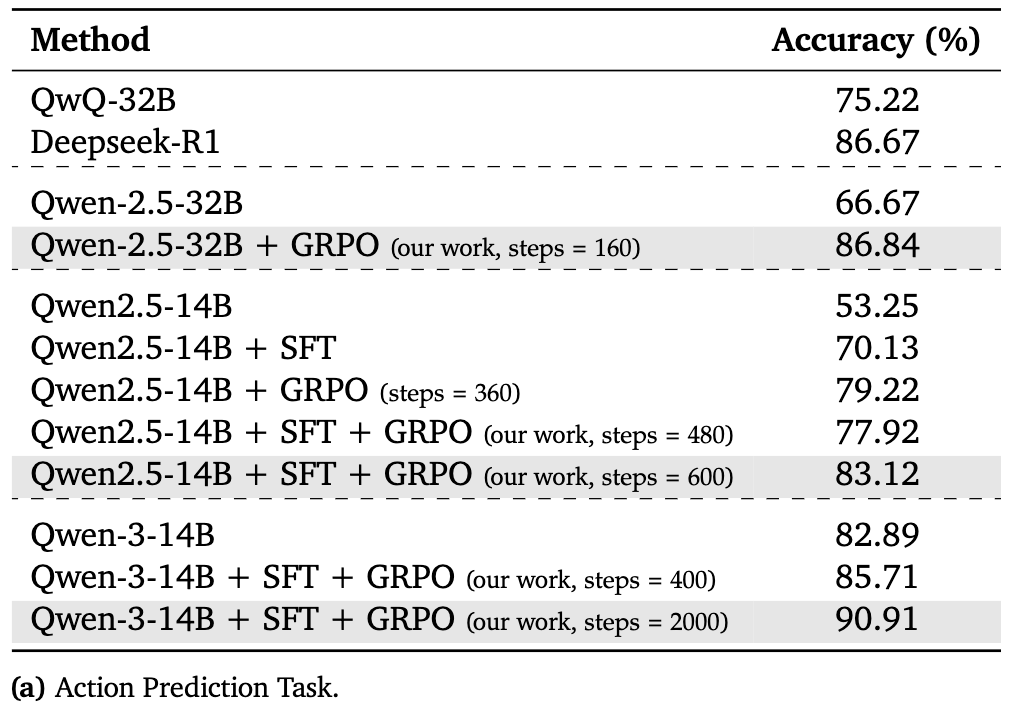
从上表的结果中,可以得出几个关键结论:
-
多阶段训练效果显著:SFT和GRPO的结合,能够大幅提升模型的性能。例如,Qwen-2.5-32B的基础准确率为66.67%,经过GRPO训练后提升至86.84%。而Qwen2.5-14B在结合了SFT和GRPO后,准确率从53.25%提升至83.12%。 -
小模型可媲美甚至超越大模型:通过TiG框架的训练,较小的模型能够达到甚至超过参数量远大于它的模型的性能。经过SFT和2000步GRPO训练的Qwen-3-14B模型,取得了90.91%的准确率,超过了参数规模大一个数量级的Deepseek-R1(86.67%)。这凸显了TiG方法的效率和可扩展性。 -
强化学习是关键驱动力:无论是单独使用还是在SFT之后使用,GRPO都带来了显著的准确率提升。这证实了通过与环境直接互动进行强化学习,是提升LLM在游戏中推理能力的有效途径。
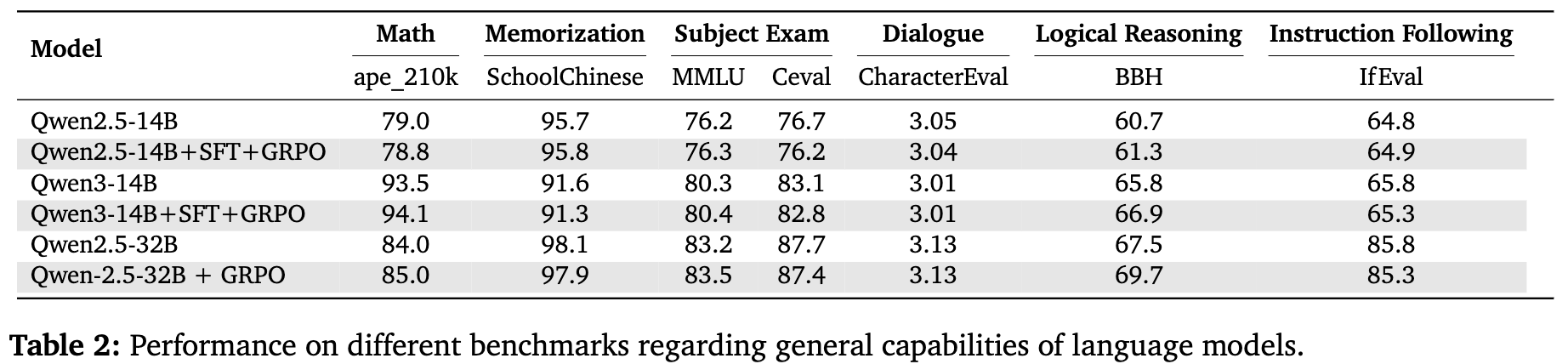
同时,研究者还在一系列标准语言能力 benchmarks 上评估了模型,结果表明,TiG的训练方法在提升模型领域特定能力的同时,并没有牺牲其通用的语言理解和推理能力。
4.3 深入分析
响应长度与奖励的关系
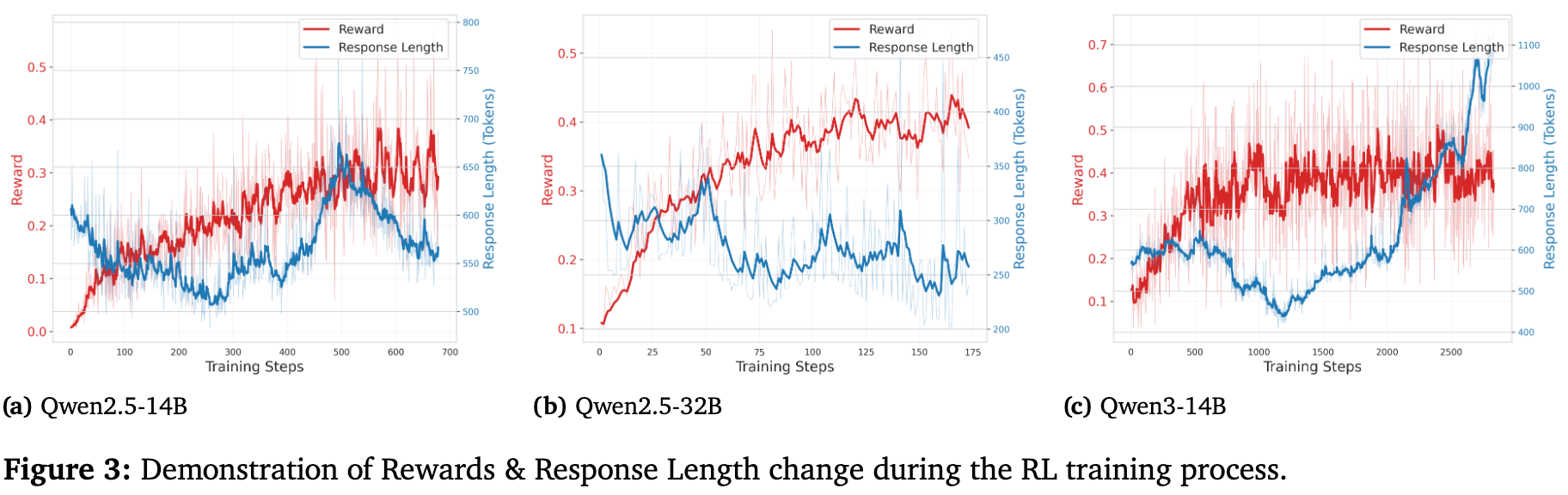
上图展示了不同模型在RL训练过程中,奖励(Reward)和响应长度(Response Length)的变化趋势。对于Qwen2.5-14B和Qwen-2.5-32B,响应长度呈现出先减少、后增加、最终稳定的模式,这与其整体性能趋势相符。而Qwen-3-14B的响应长度则在训练中稳步增长,这可能是因为该模型被设计用于支持更深层次的思考,生成更多的思考内容有助于提升其能力。
错误分析
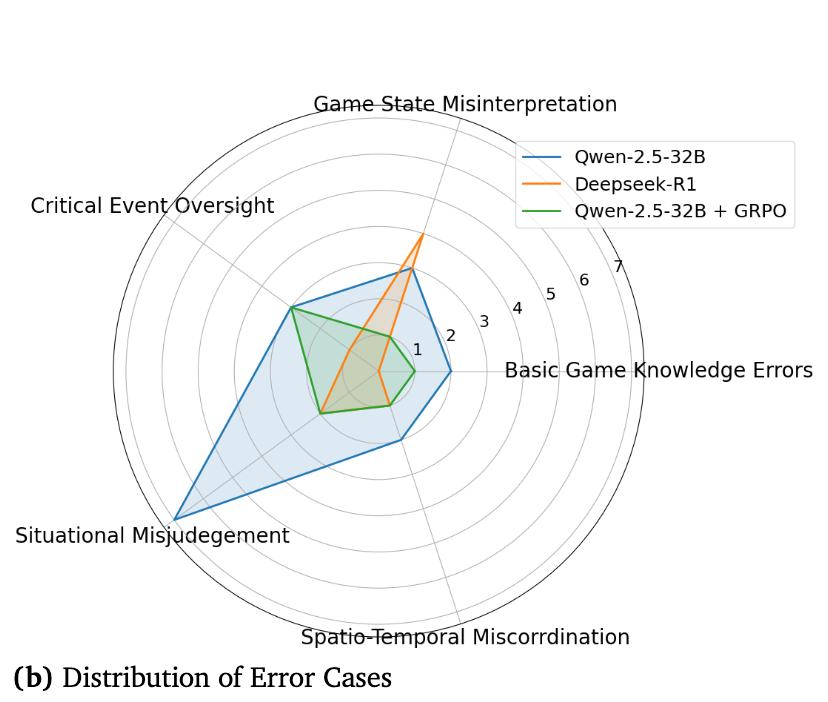
为了更深入地理解模型的行为,研究者对错误案例进行了分类和分析。如上图右侧所示,相比于基础模型,经过GRPO训练后的模型(Qwen-2.5-32B + GRPO)在各个错误类别上都有明显的改进,其错误分布与强大的Deepseek-R1模型相当。考虑到模型参数的巨大差异,这进一步证明了TiG方法的有效性。
4.4 泛化能力测试
为了验证TiG的泛化能力,研究者构建了一个新的问答格式数据集(TiG-QA)。在这个任务中,模型需要根据给定的游戏状态和一个开放式问题,生成一个全面的、基于游戏上下文的回答。
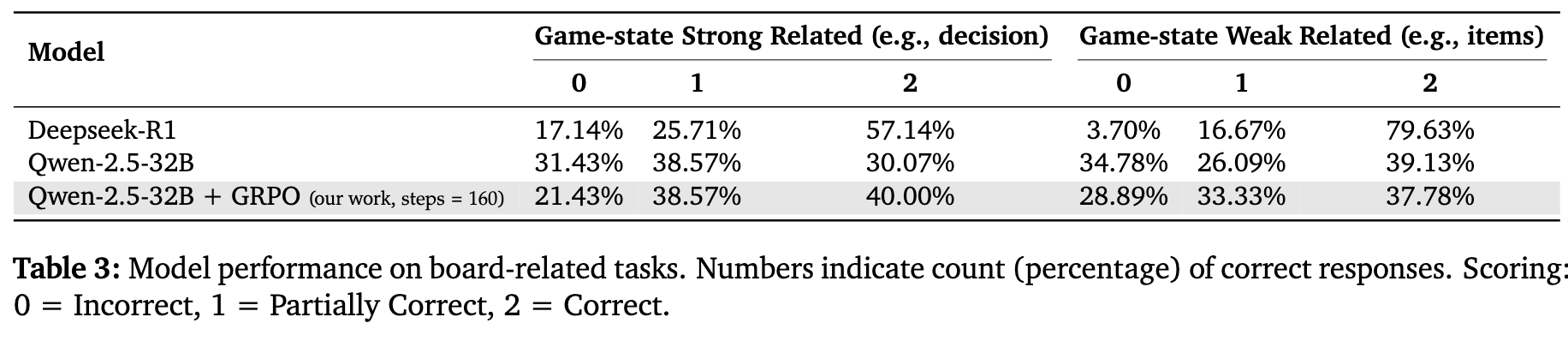
结果显示,在与游戏状态强相关的决策类问题上,经过TiG训练的模型表现优于Deepseek-R1。而在一些依赖先验知识的弱相关问题上,Deepseek-R1仍然有优势,这符合其作为通用大模型的特点。
5. 案例研究:TiG在真实游戏场景中的“思考”过程
论文提供了多个详尽的案例研究,直观地展示了TiG模型在真实游戏场景中的决策和推理过程。下面我们来看几个典型的例子。
案例1:中期顺风推塔决策

-
场景描述:玩家控制的英雄“阿古朵”正和队友“姜子牙”一起在中路推进,攻击敌方一座血量不佳的一塔。 -
模型思考过程 : -
局势分析:模型首先评估了整体游戏状态,正确判断游戏已过前期,防御塔保护机制已失效。它注意到了敌方中路一塔血量很低,这是一个绝佳的推塔机会。同时,模型也识别到了风险:敌方英雄位置不明,且我方英雄“阿古朵”血量不高。 -
目标优先级:基于分析,模型将摧毁中路一塔作为最优先的目标,并强调了与附近队友“姜子牙”协同的重要性。 -
策略制定:模型给出了具体的行动计划:“联合姜子牙前往敌方中路一塔,集中火力推塔。”并附带了风险提示:“注意敌方英雄可能埋伏,保持警惕。” -
英雄特性结合:模型还展示了对英雄角色的理解,建议作为射手的“阿古朵”应“保持安全距离输出”。
-
-
最终指令:“联合姜子牙推掉敌方中路一塔,注意敌方可能埋伏。” -
分析:这个案例展示了TiG不仅仅是做出反应,而是进行了一种主动的、战略性的决策。它在机会与风险之间取得了平衡,结合了英雄特性知识,最终给出了一个战术上合理且可立即执行的指令。
案例2:争夺关键中立生物

-
场景描述:玩家控制的英雄“盘古”位于敌方野区,此时暴君已经刷新并正在被攻击。 -
模型思考过程:模型分析到暴君是当前地图上的优先目标,处理它可以为团队带来优势。它判断出自己的位置可以快速前往暴君处,且敌方人员减少,因此建议优先夺取暴君。 -
最终指令:“优先拿下暴君,提升团队优势,注意观察周围环境。” -
分析:TiG能够准确识别游戏中的关键战略资源,并根据玩家位置和战场局势做出正确的优先级判断。
案例3:支援远端战斗

-
场景描述:玩家控制的英雄“扁鹊”在中路,而暗影主宰正在被队友攻击。 -
模型思考过程:模型观察到暗影主宰对团队增益巨大,是优先目标。同时,它判断出敌方英雄距离较远,而自己前往主宰龙坑的路线更近、更方便。因此,它建议立即前往协助队友。 -
最终指令:“协助铠拿下暗影主宰,获取团队增益。” -
分析:此案例表明,TiG具备了良好的全局观,能够评估不同战场事件的紧急程度和重要性,并做出最优的支援决策。
其他案例
论文还展示了更多场景,包括:


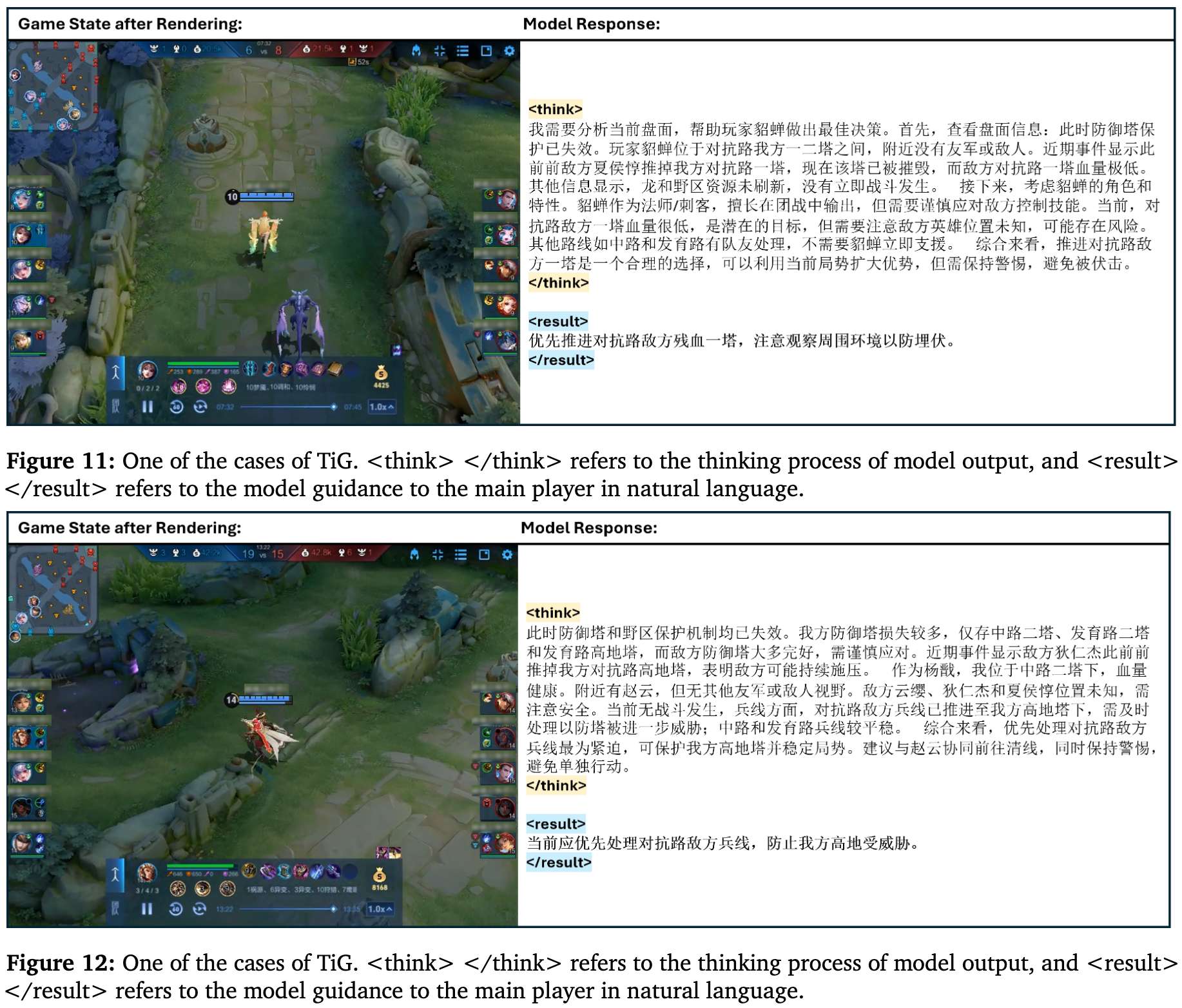

这些案例共同证明了TiG框架赋予了LLM深度、上下文感知的推理能力,并能将复杂的游戏状态转化为对玩家来说清晰、可执行的自然语言指导。


