现有的强化学习微调方法(如ReFT)在实践中面临两大挑战:一是它们通常忽略了高质量的、由人类专家标注的思维链(Chain-of-Thought, CoT)数据中所蕴含的丰富过程信息;二是强化学习训练过程本身存在不稳定性,容易出现“模型崩溃(model collapse)”现象,导致性能下降。针对这些问题,论文《CARFT: Boosting LLM Reasoning via Contrastive Learning with Annotated Chain-of-Thought-based Reinforced Fine-Tuning》提出了一种名为CARFT的新型微调框架。CARFT的核心思想是利用对比学习,将标注CoT的监督信号与强化学习的探索优势相结合,旨在增强模型推理性能的同时,也提升微调过程的稳定性。

-
论文标题:CARFT: Boosting LLM Reasoning via Contrastive Learning with Annotated Chain-of-Thought-based Reinforced Fine-Tuning -
论文链接:https://www.arxiv.org/pdf/2508.15868
CARFT详解
CARFT (Contrastive learning-based Reinforced Fine-Tuning) 框架的核心在于其创新的对比反馈机制。它巧妙地将标注CoT的信息价值重新引入到强化学习的循环中,作为一种“软”指导,既利用了标注CoT的正确性,又保留了RL的探索能力。
CARFT 整体框架
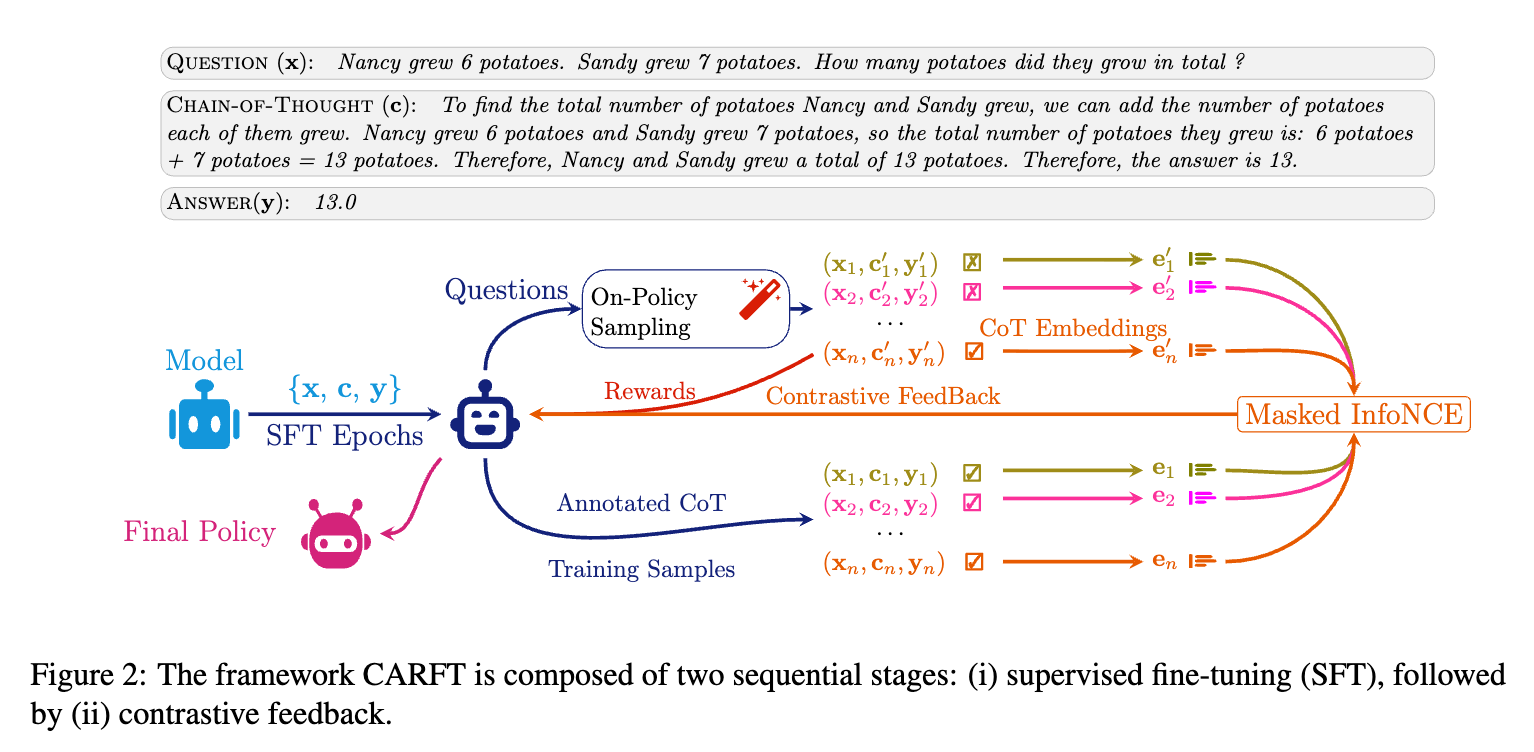
CARFT的整个流程包含两个主要阶段:
第一阶段:标准的监督微调 (SFT)
与常规做法一样,首先在一个包含 (问题 x, 标注CoT c, 答案 y) 的数据集上对基础LLM进行SFT。这一步的目的是为模型提供一个良好的初始化,使其具备生成基本连贯的CoT的能力。完成SFT后,我们得到一个初始策略模型 。
第二阶段:基于对比反馈的强化微调
这是CARFT的核心。在这个阶段,模型将在强化学习的框架内进行进一步的优化。对于训练集中的每一个问题 x,流程如下:
-
On-Policy 采样:使用当前的模型策略 为问题 x生成一个推理路径,我们称之为 on-policy CoT,记作 。 -
对比反馈构建:将模型生成的 与数据集中对应的、高质量的标注CoT 进行对比。这个对比过程会产生一个对比信号(contrastive signal),用于指导模型的学习。 -
参数优化:结合传统的RL奖励(基于最终答案的正确性)和新引入的对比信号,共同计算一个总的损失函数,并用它来更新模型参数 。
下面,我们将深入探讨对比反馈机制的两个关键组成部分:CoT嵌入表示和对比信号的构建。
CoT 嵌入表示 (Chain-of-Thought Embeddings)
为了对两个CoT( 和 )进行语义层面的比较,首先需要将它们转化成定长的向量表示,即CoT嵌入。一个CoT是由一系列token组成的序列 。CARFT通过以下方式计算其嵌入 :
首先,通过模型得到每个token 对应的隐藏状态(token embedding) 和一个标量状态值 (由价值网络输出,表示当前状态的优劣)。然后,将所有的状态值 进行softmax归一化,得到每个token的权重。最后,将这些权重应用于对应的token嵌入 进行加权求和。
其数学表达式为:
其中 表示逐元素相乘。这种加权方式使得对推理过程更重要的token(通常具有更高的状态值)在最终的CoT嵌入中占有更大的比重,从而得到一个能够有效概括整个推理链核心语义的向量表示。
掩码对比信号构建 (Masked Contrastive Signal Construction)
获得了CoT的嵌入表示后,CARFT通过对比学习来构建正向和负向两种信号,以更精细地指导模型优化。
1. 正向信号 (Positive Signal)
正向信号的目标是“拉近”模型生成的CoT与高质量的标注CoT。直观上,我们希望模型生成的推理路径在语义上与专家给出的范例尽可能相似。CARFT利用InfoNCE损失函数来实现这一点。在一个训练批次(batch)中,对于每一个样本,其 和 构成一个正样本对。该样本的 与批次内其他所有样本的 则构成负样本对。
正向对比损失 的定义如下:
其中, 表示余弦相似度, 是温度超参数,用于调节相似度分布的锐利程度。通过最小化这个损失函数,可以促使模型生成的CoT嵌入 与其对应的标注CoT嵌入 的相似度远高于与其他不相关标注CoT嵌入的相似度。这为模型的探索提供了一个明确的优化方向。
2. 负向信号 (Negative Signal)
仅仅有正向信号是不够的。有时模型生成的路径可能与标注路径大体相似,但在关键步骤上出现了错误。为了处理这种情况,CARFT设计了负向信号,其目标是“推开”模型生成的CoT中与标注CoT不一致的、可能导致错误的部分。
负向信号的构建方式如下:
-
首先,计算 和 之间的最长公共子序列 (Longest Common Subsequence, LCS) 。LCS代表了两个推理路径中共同的、一致的部分。 -
然后,从 中剔除LCS部分,剩下的token序列 代表了“标注中有,但生成中没有”的关键步骤。同理,从 中剔除LCS部分,得到 ,代表了“生成中有,但标注中没有”的多余或错误步骤。 -
利用 和 分别计算嵌入 和 。 -
负向对比损失 的目标是最小化这两个“差异”嵌入之间的相似度,即把它们推开。
其公式与 类似,但优化的目标是降低正样本对(即来自同一原始问题的 和 )的相似度。
3. 总体损失函数
最终,模型的策略网络通过一个组合损失函数进行更新。该损失函数结合了标准的PPO策略损失 、价值损失 以及新引入的对比损失( 或 )。
其中 和 是用于平衡不同损失项的超参数。这个总体损失函数使得模型在优化时,既要考虑最终答案的正确性(来自PPO),也要参考与标注CoT的语义相似性(来自对比损失)。
嵌入增强的部分奖励 (Embedding-enhanced Partial Reward)
传统ReFT的另一个问题是奖励稀疏。只有当整个CoT生成完毕并且答案正确时,模型才能获得正奖励,这使得学习效率低下。为了提供更密集的引导信号,CARFT设计了一种嵌入增强的部分奖励(embedding-enhanced partial reward)。
这个奖励是在每一步生成的token上计算的,其大小正比于当前生成的CoT片段与完整标注CoT之间的嵌入相似度。具体来说,奖励函数 被设计为:
这个奖励函数的值域在 之间。当模型生成的CoT与标注CoT在语义上越相似,它在每一步获得的奖励就越高。这种密集的奖励信号能够更有效地引导模型朝着生成高质量CoT的方向探索,进一步提高了训练的稳定性和效率。
实验与结果分析
为了验证CARFT的有效性,论文进行了一系列详尽的实验。
实验设置
-
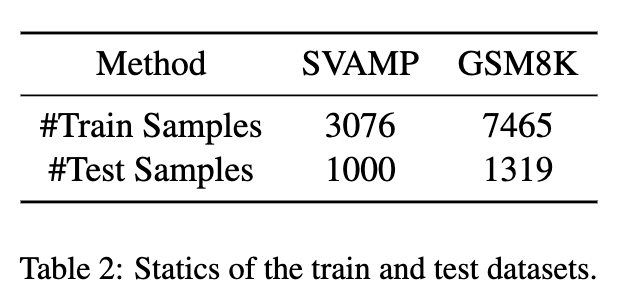
数据集:实验在两个广泛使用的数学推理基准数据集上进行:SVAMP(简单算术问题)和GSM8K(小学数学问题)。
-
基础模型:选用了两个具有代表性的开源模型:CodeLlama-7B 和 Qwen2.5-7B-Instruct,它们的参数规模均为70亿。
-
对比方法:CARFT与以下几个主流或相关的基线方法进行了比较:
-
SFT:标准的监督微调。 -
ReFT:一种先进的、基于PPO的强化学习微调方法。 -
Dr.GRPO:另一种增强的、利用多轮采样(rollouts)的RL微调方法。
-
主要实验结果
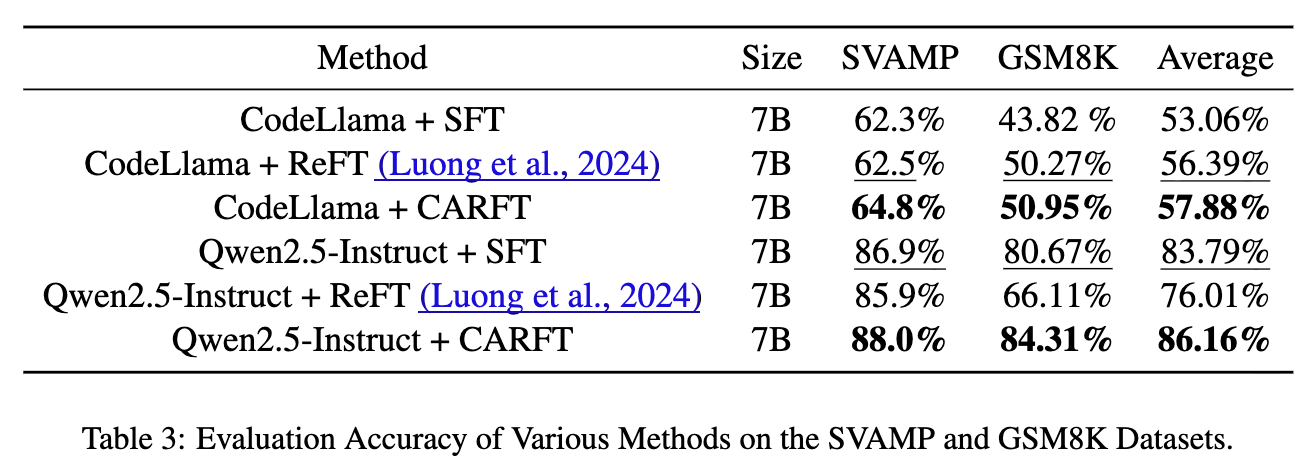
从上表可以看出,CARFT在所有实验设置中均取得了优于其他所有基线方法的性能。
-
在CodeLlama-7B模型上,CARFT在SVAMP和GSM8K上的准确率分别达到了64.8%和50.95%,显著超过了SFT和ReFT。 -
在更强大的Qwen2.5-7B-Instruct模型上,CARFT的性能优势进一步扩大,准确率达到了88.0%和84.31%。与ReFT相比,平均准确率提升了约2.18%。与SFT相比,平均提升了约4.15%。 -
值得注意的是,CARFT不仅在性能上超越了ReFT,在训练效率上也优于需要多次采样的Dr.GRPO。如表4所示,CARFT的训练时间(16.99小时)远少于Dr.GRPO(24.49小时)。
这些结果有力地证明了CARFT框架的有效性。通过结合对比学习和强化学习,CARFT能够更充分地利用数据,从而达到更高的推理准确率。
训练过程稳定性分析
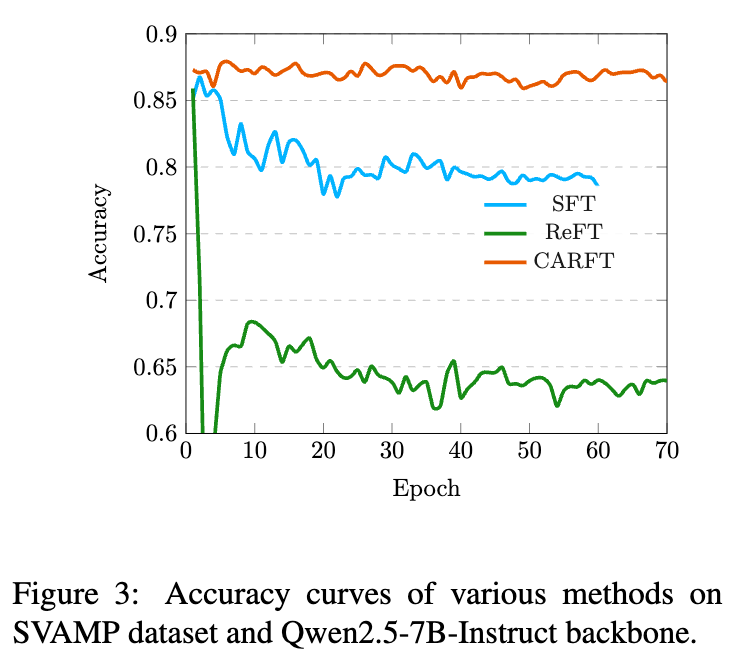
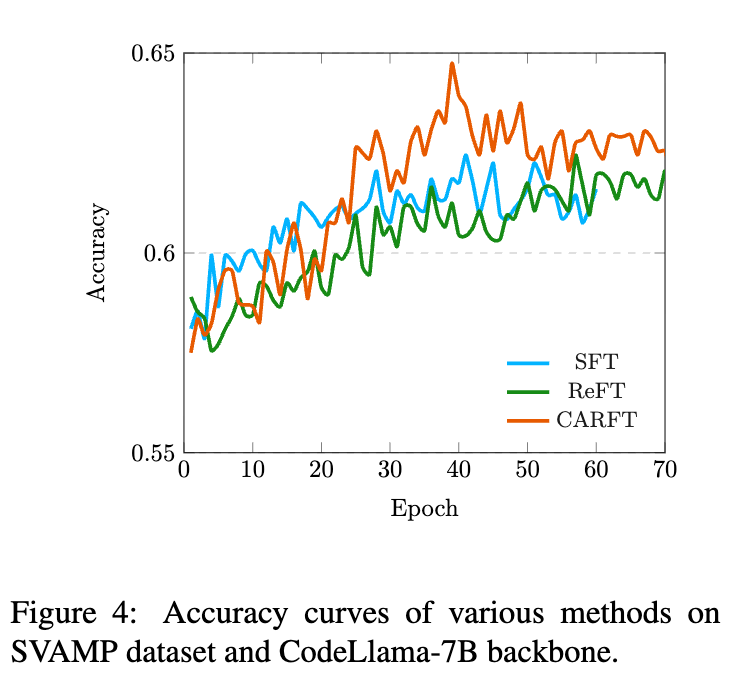
除了最终性能,训练过程的稳定性是衡量一个RL方法好坏的另一个重要指标。上方的学习曲线图清晰地展示了不同方法在训练过程中的准确率变化。
-
ReFT的不稳定性:从图中可以看到,ReFT的训练曲线波动较大。特别是在CodeLlama-7B模型上,ReFT在训练后期出现了明显的性能衰退,这就是典型的“模型崩溃”现象。这表明,在没有有效指导的情况下,RL的探索很容易导致不稳定的结果。 -
CARFT的稳定性:相比之下,CARFT的学习曲线表现出稳定上升的趋势,并且收敛到了比SFT和ReFT更高的性能水平。这表明CARFT中的对比信号起到了关键的正则化和引导作用,有效抑制了PPO策略更新的“跑偏”倾向,从而稳定了整个微调过程。
消融研究
为了探究CARFT框架中不同组件的贡献,论文还进行了一系列消融实验。
-
正向信号 vs. 负向信号
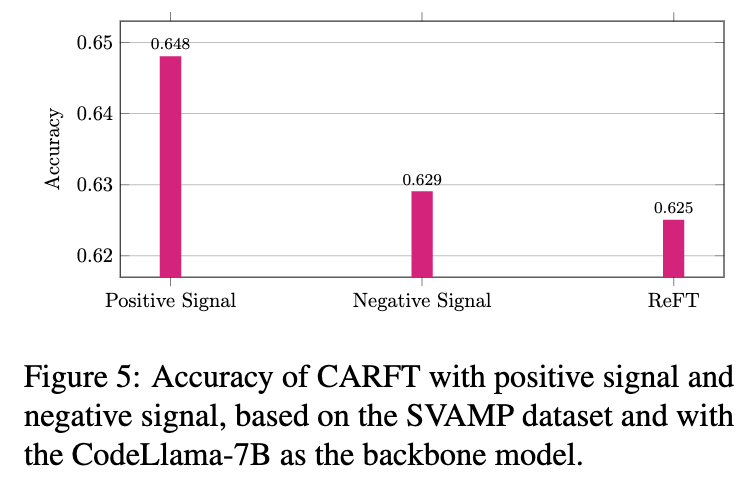
实验发现,单独使用正向信号(拉近与标注CoT的距离)带来的性能提升最为显著(准确率达到64.48%)。单独使用负向信号(推开与标注CoT的差异)也能带来一定的提升,但效果不如正向信号。这表明,在当前的任务设置下,直接引导模型学习“好的范例”是提升性能最有效的方式。
-
嵌入增强的部分奖励的作用
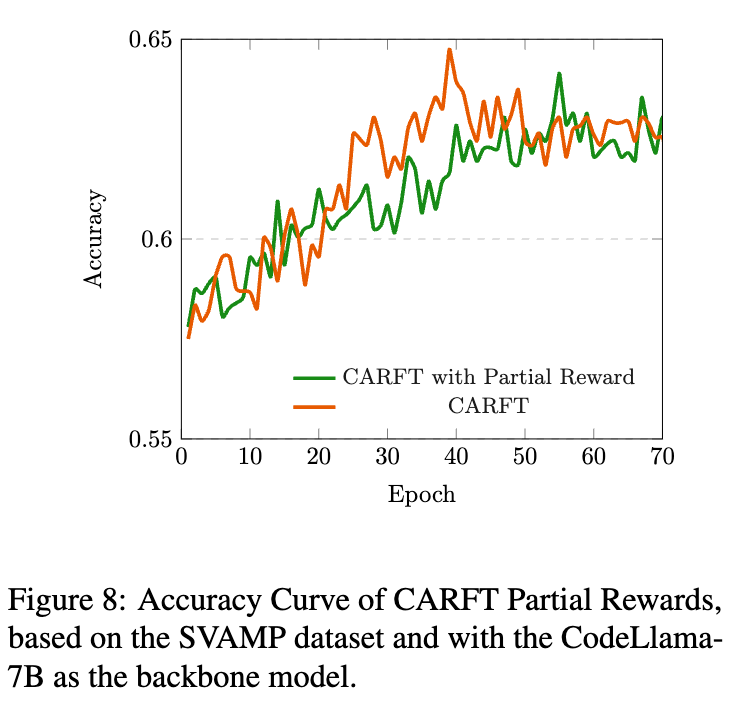
实验结果显示,在CARFT框架中加入嵌入增强的部分奖励后,模型的最终准确率和学习曲线的稳定性都得到了进一步的提升。这验证了提供密集奖励信号对于引导RL探索和加速收敛的积极作用。
往期文章:


