大型语言模型(LLMs)在处理通用语言任务时展现了强大的能力,但在将它们应用于特定专业领域时,仍然面临挑战。当前主流的领域自适应方法主要有两种:领域自适应预训练(Domain Adaptive Pretraining, DAPT)和检索增强生成(Retrieval-Augmented Generation, RAG)。DAPT 方法通过在领域数据上继续预训练模型,能够将领域知识深度融入模型参数,但在推理时效率较高。然而,这种方法需要进行成本高昂的全参数训练,并且常常伴随着“灾难性遗忘”问题,即模型在适应新领域后,其原有的通用能力会有所下降。另一方面,RAG 方法通过在推理时从外部知识库中检索相关信息来增强模型,它保留了原始模型的参数不变,但检索过程(通常是昂贵的最近邻搜索)和更长的上下文处理为推理带来了显著的延迟。
这两种方法形成了一个困境:DAPT 在推理时高效,但训练成本高昂且不灵活;RAG 具有即插即用的灵活性,但在推理时效率低下。为了解决这一问题,来自上海交通大学、上海人工智能实验室和清华大学的研究人员共同发表了一篇名为《Memory Decoder: A Pretrained, Plug-and-Play Memory for Large Language Models》的论文。该论文提出了一种名为 Memory Decoder (MemDec) 的新方法。

-
论文标题:Memory Decoder: A Pretrained, Plug-and-Play Memory for Large Language Models -
论文链接:https://www.arxiv.org/pdf/2508.09874
Memory Decoder 是一个即插即用的预训练记忆模块,它旨在实现高效的领域自适应,而无需修改原始大语言模型的任何参数。其核心思想是利用一个小型 Transformer 解码器来学习并模仿外部非参数化检索器(如 kNN)的行为。一旦训练完成,这个 Memory Decoder 就可以与任何共享相同分词器(tokenizer)的预训练语言模型无缝集成,无需进行任何针对特定模型的修改。
实验结果表明,Memory Decoder 能够有效地帮助 Qwen 和 Llama 等多种模型适应生物医学、金融和法律这三个不同的专业领域,平均能将困惑度(perplexity)降低 6.17 点。总体而言,Memory Decoder 提出了一种新的领域自适应范式,其核心是一个专门为特定领域设计的、经过特殊预训练的记忆组件。这种记忆架构能够以即插即用的方式集成,持续提升目标领域内多个模型的性能。
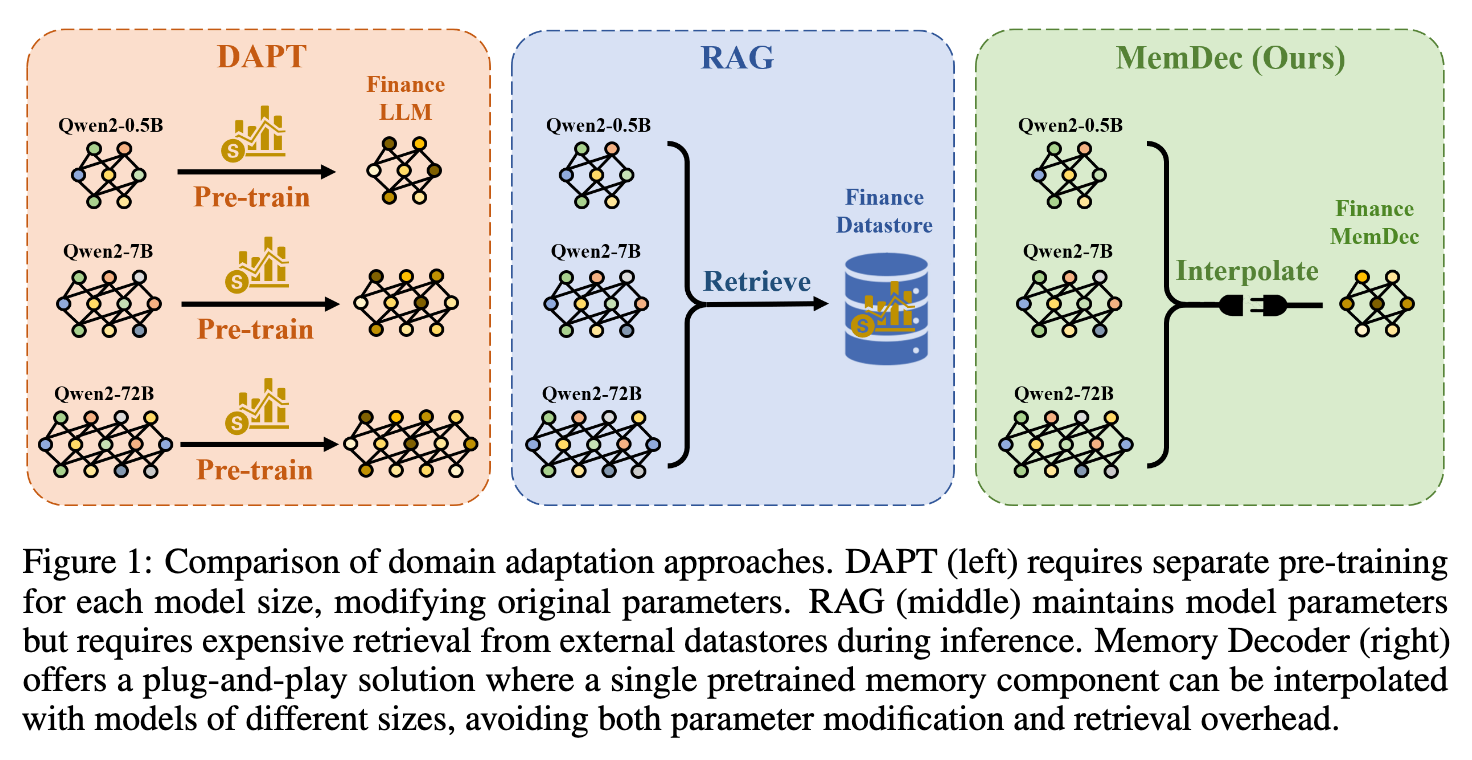
1. 背景:领域自适应的困境
在深入了解 Memory Decoder 的工作原理之前,我们有必要先回顾一下当前大模型领域自适应所面临的核心问题以及现有解决方案的利弊。
1.1 问题定义
领域自适应的目标是提升一个在通用语料上预训练好的语言模型(我们称之为 ,其参数为 )在特定领域文本(领域语料库为 )上的表现。具体来说,就是优化模型在给定上下文序列 后,对下一个词元(token) 的预测概率分布 。
1.2 主流解决方案及其权衡
1. 领域自适应预训练 (DAPT)
DAPT 的做法相对直接:将通用的预训练模型在特定领域的语料上继续进行预训练。
-
优点: DAPT 可以将领域知识深度地编码到模型的权重参数中,使得模型在推理时能够直接利用这些知识,通常能取得不错的性能表现。 -
缺点: -
高计算成本: 对数十亿甚至更大规模的模型进行全参数训练,需要消耗巨大的计算资源和时间。 -
资源效率低下: 如果希望将一个模型家族(例如 Qwen2 的 0.5B、7B、72B 版本)都适配到金融领域,需要对每个模型都独立进行一次完整的 DAPT 流程,造成了资源浪费。 -
灾难性遗忘: 当模型专注于学习特定领域的知识时,它可能会丢失一部分在通用语料上学到的通用语言能力和世界知识。
-
2. 检索增强生成 (RAG)
RAG 提供了一种不同的思路。它不改变模型本身的参数,而是在模型进行推理时,动态地从外部知识库中检索出与当前输入相关的信息,并将这些信息作为额外的上下文(context)一并提供给模型。
-
优点: -
保持模型参数不变: 由于不涉及模型训练,RAG 从根本上避免了灾难性遗忘问题。 -
知识可更新: 领域知识存储在外部数据库中,可以随时更新或扩展,而无需重新训练大模型。 -
即插即用: RAG 作为一个外部模块,可以灵活地与任何模型配合使用。
-
-
缺点: -
高推理延迟: RAG 的核心是“检索”步骤。在庞大的数据库中执行最近邻(k-nearest neighbor, kNN)搜索是一个计算密集型操作,它显著增加了从输入到输出的总时间,成为推理过程中的性能瓶瓶颈。 -
上下文长度增加: 检索到的文本片段会拼接到原始输入中,使得模型的实际输入序列变长,这进一步增加了模型的计算负担。
-
1.3 最近邻语言模型 (kNN-LM)
Memory Decoder 的思想很大程度上受到了 kNN-LM 的启发。kNN-LM 是一种典型的非参数化领域自适应方法,它同样不修改预训练模型的参数。其工作流程如下:
-
构建数据存储 (Datastore): 首先,它会遍历整个领域语料库 。对于语料中的每个位置,它将当前位置的上下文通过预训练模型提取出的隐藏层表示作为“键”(key),将该位置的真实下一个词元作为“值”(value)。这样就构建起了一个大规模的键值对数据存储 :
其中 是从预训练模型中提取隐藏表示的函数。
-
推理与检索: 在推理时,对于给定的上下文 ,首先计算出其隐藏表示 。然后,用这个 作为查询,在数据存储 中找到与之最相似的 个“键”,并获取它们对应的“值”。
-
构建 kNN 分布: 基于检索到的 个邻居,可以构建一个概率分布 。这个分布的计算方式大致如下,与查询 距离越近的邻居,其对应的“值”获得的概率权重就越高:
其中 表示 的 个最近邻居, 是距离函数, 是温度参数。
-
插值: 最后,将 kNN 分布与原始语言模型的分布 进行线性插值,得到最终的预测分布:
其中 是一个超参数,用于平衡两者的影响。
kNN-LM 虽然有效,但它也暴露了非参数化方法的核心问题:需要巨大的存储空间来存放数据存储(例如,Wikitext-103 数据集在 GPT2-small 模型下就需要近 500GB 的存储),并且推理时的 kNN 搜索非常耗时。
这些现有方法的局限性催生了 Memory Decoder 的设计动机:创造一种新方法,它既有 RAG 和 kNN-LM 的“即插即用”特性,又具备 DAPT 的高推理效率。
2. Memory Decoder 核心设计
Memory Decoder 的核心创新在于,它没有在推理时进行显式的、昂贵的检索操作,而是通过预训练一个紧凑的参数化模型(即 Memory Decoder 本身),让这个模型去学习和模拟非参数化检索器的行为。换言之,它将一个巨大的、非参数化的键值数据存储中蕴含的“知识”压缩到了一个小型神经网络的参数之中。
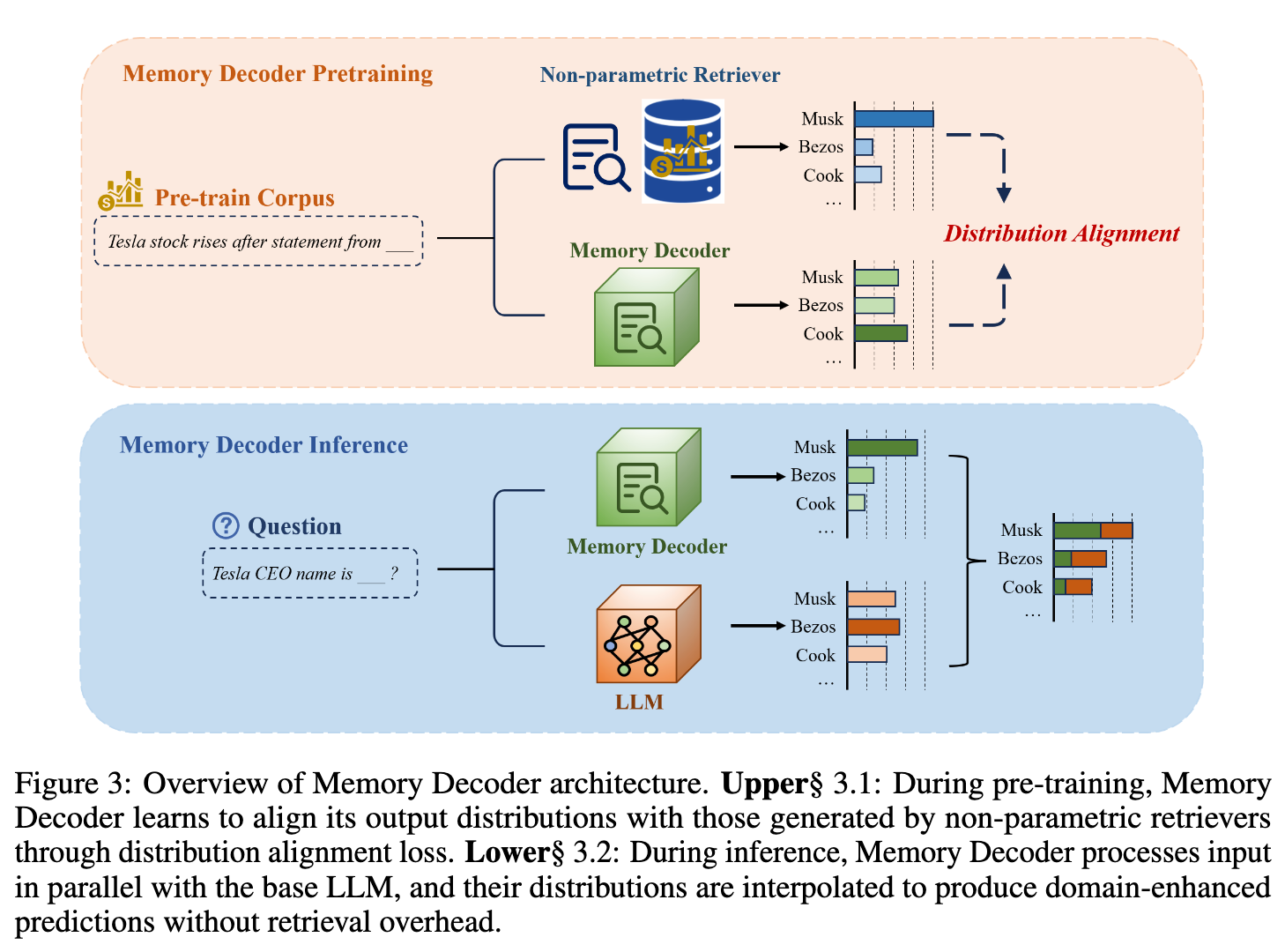
整个方法分为两个阶段:预训练和推理。
2.1 预训练阶段:学习模仿检索器
预训练阶段的目标是训练 Memory Decoder (),使其在接收到任意上下文 时,能够生成一个与 kNN 检索器在该上下文下所生成的概率分布 高度相似的概率分布。
1. 数据构建
这是预训练过程中一个关键且独特的步骤。传统语言模型的训练数据是 (输入上下文, 目标词元) 的形式。而 Memory Decoder 的训练数据则是 (输入上下文, 目标概率分布) 的形式。这个目标概率分布的构建过程如下:
-
构建键值数据存储: 与 kNN-LM 一样,首先利用一个强大的预训练模型(例如 GPT2-xl 或 Qwen2.5-1.5B)和领域语料库 来构建一个键值数据存储 。 -
生成监督信号: 遍历训练语料库 中的每一个上下文 。对于每一个 ,都执行一次 kNN 搜索,找到数据存储中最相似的 个邻居。 -
计算并缓存 kNN 分布: 基于这 个邻居,计算出非参数化的概率分布 。 -
构建训练对: 将上下文 和计算出的分布 作为一对训练数据 缓存起来。
这个过程计算量很大,但它是一次性的预处理工作。一旦为某个领域生成了所有训练对,就可以反复使用它们来训练 Memory Decoder。
2. 预训练目标
kNN 分布与传统的单标签(one-hot)分布相比,是更丰富的监督信号,因为它捕捉了在特定上下文中多种可能的、合理的续写方式。为了让 Memory Decoder 有效地学习这种复杂的分布,论文设计了一个混合的目标函数。
-
分布对齐损失 (Distribution Alignment Loss): 这是核心的损失项。它旨在最小化 Memory Decoder 的输出分布 与我们预先计算好的目标 kNN 分布 之间的差异。论文中使用了 Kullback-Leibler (KL) 散度来度量这种差异:
-
标准语言模型损失 (Standard Language Modeling Loss): 仅有 KL 散度损失可能会使模型学习到一些奇怪的分布,而偏离了语料本身的基本语言结构。为了防止这种情况,论文引入了一个辅助的标准语言模型损失(交叉熵损失),即最大化真实下一个词元 的概率:
-
最终损失函数: 将上述两种损失通过一个超参数 进行加权组合,得到最终的损失函数:
这个混合目标函数使得 Memory Decoder 在学习模仿 kNN 分布的稀疏、尖锐特性的同时,也能保持对领域语料基本语言模式的遵循。
2.2 推理阶段:即插即用的高效增强
一旦 Memory Decoder 预训练完成,它就变成了一个即插即用的领域知识增强模块。在推理时,它的工作流程非常高效:
-
并行处理: 对于一个给定的输入上下文 ,它会被同时送入基础大语言模型 和 Memory Decoder 。这两个模型的计算过程是并行的。 -
生成双重分布: -
基础 LLM 输出其通用的下一词元预测分布 。 -
Memory Decoder 输出其经过领域知识增强的下一词元预测分布 。
-
-
简单插值: 最终的预测分布是通过对这两个分布进行简单的线性插值得到的:
其中, 是一个插值系数,用于控制领域知识(来自 MemDec)的注入强度。
这种设计的优势在于,它将原来 RAG/kNN-LM 中耗时的 kNN 搜索步骤,替换成了一次通过一个小型 Transformer 解码器的前向传播。这个计算开销远小于检索,并且可以与基础 LLM 的计算并行执行,从而实现了低延迟的领域自适应。
3. 实验与结果分析
为了验证 Memory Decoder 的有效性,论文进行了一系列详尽的实验。
实验设置:
-
数据集: -
通用语言建模: Wikitext-103 -
领域自适应语料: 生物医学 (MIMIC-III), 金融 (Financial news from 2024-2025), 法律 (Asylex corpus)
-
-
基础模型: GPT-2 系列, Qwen2 系列, Qwen2.5 系列, Llama3/3.1/3.2 系列 -
对比基线 (Baselines): -
In-Context RAG: 使用 BM25 检索器进行检索。 -
kNN-LM: 经典的非参数化方法。 -
LoRA: 参数高效的微调方法。 -
DAPT: 全参数的领域自适应预训练。
-
3.1 通用语言建模性能 (Wikitext-103)
该实验旨在验证 MemDec 在标准语言建模基准上的基础有效性。
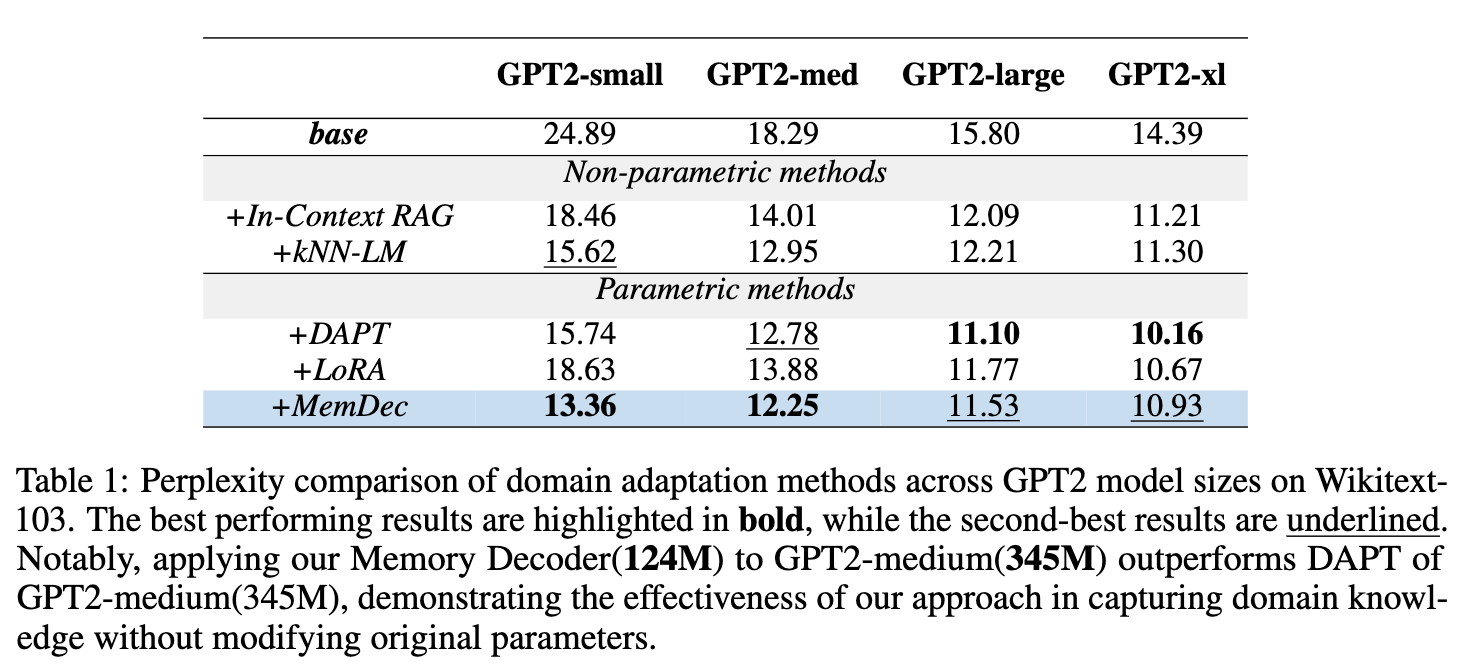
核心发现:
-
一个仅有 124M 参数的 Memory Decoder,在与整个 GPT-2 家族(从 small 到 xl)结合时,都能稳定地降低模型的困惑度(Perplexity, PPL),PPL 越低代表模型性能越好。 -
对于 GPT2-small 和 GPT2-medium 这样的小模型,MemDec 的性能超越了 DAPT。例如, GPT2-medium + MemDec(PPL 12.25) 的表现优于DAPT版本的GPT2-medium(PPL 12.78)。这表明在不修改原始参数的情况下,MemDec 捕捉领域知识的效率很高。 -
对于 GPT2-large 和 GPT2-xl 等大模型,虽然 DAPT 因为全参数更新而具有优势,但 MemDec 依然表现出很强的竞争力,并且优于所有其他参数高效的方法(如 LoRA)。
这个实验证明了,一个小型的参数化解码器确实可以有效地学习并压缩非参数化检索带来的好处。
3.2 下游任务性能与灾难性遗忘
领域自适应的一个重要风险是损害模型原有的通用能力。该实验在 9 个不同的自然语言处理下游任务上,以零样本(zero-shot)的方式评估了各个方法。
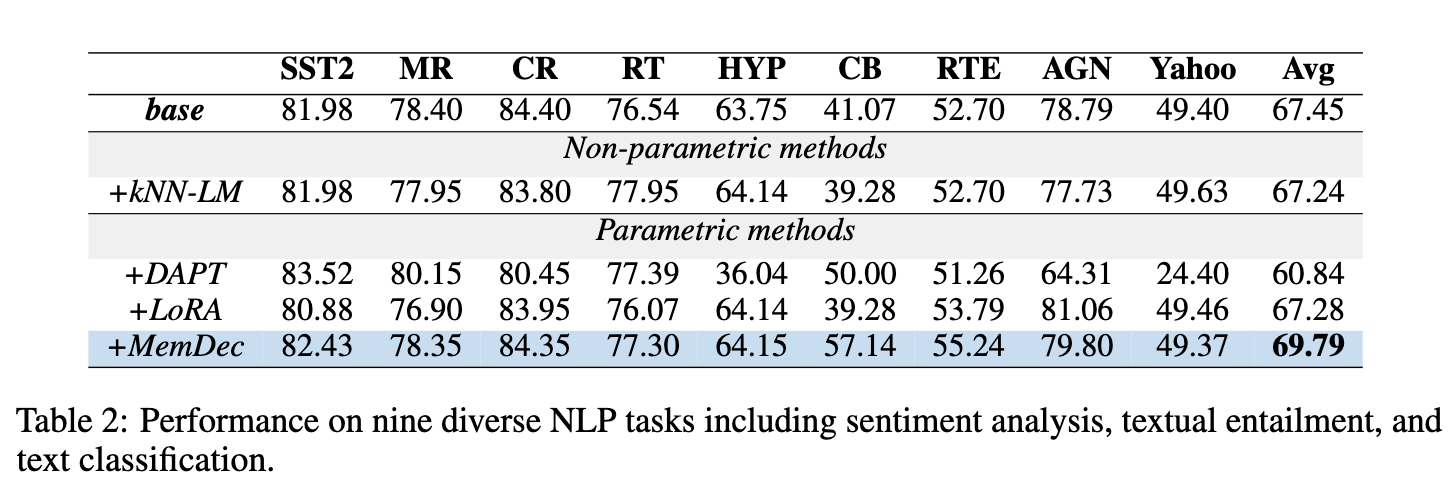
核心发现:
-
DAPT 的灾难性遗忘: DAPT 在多个任务上表现出严重的性能下降,尤其是在 HYP 和 Yahoo 任务上,性能下降了近一半。这证实了全参数微调会损害模型的通用性。 -
MemDec 的能力保持: Memory Decoder 在所有评估任务上都保持或提升了性能,最终取得了最高的平均分 (69.79)。尤其在 CB 和 RTE 等文本蕴含任务上,提升效果显著。 -
原因分析: MemDec 之所以能避免灾难性遗忘,是因为它遵循了“增强而非修改”的原则。基础 LLM 的参数保持不变,其通用能力得以完整保留。MemDec 只是作为一个外部的“专家顾问”提供领域知识,二者结合,相得益彰。
3.3 跨模型自适应能力
这是展示 Memory Decoder “即插即用”特性的核心实验。研究者们只训练了一个 0.5B 参数的 Memory Decoder,然后尝试将其应用到 Qwen2 和 Qwen2.5 家族中从 0.5B 到 72B 的所有模型上。
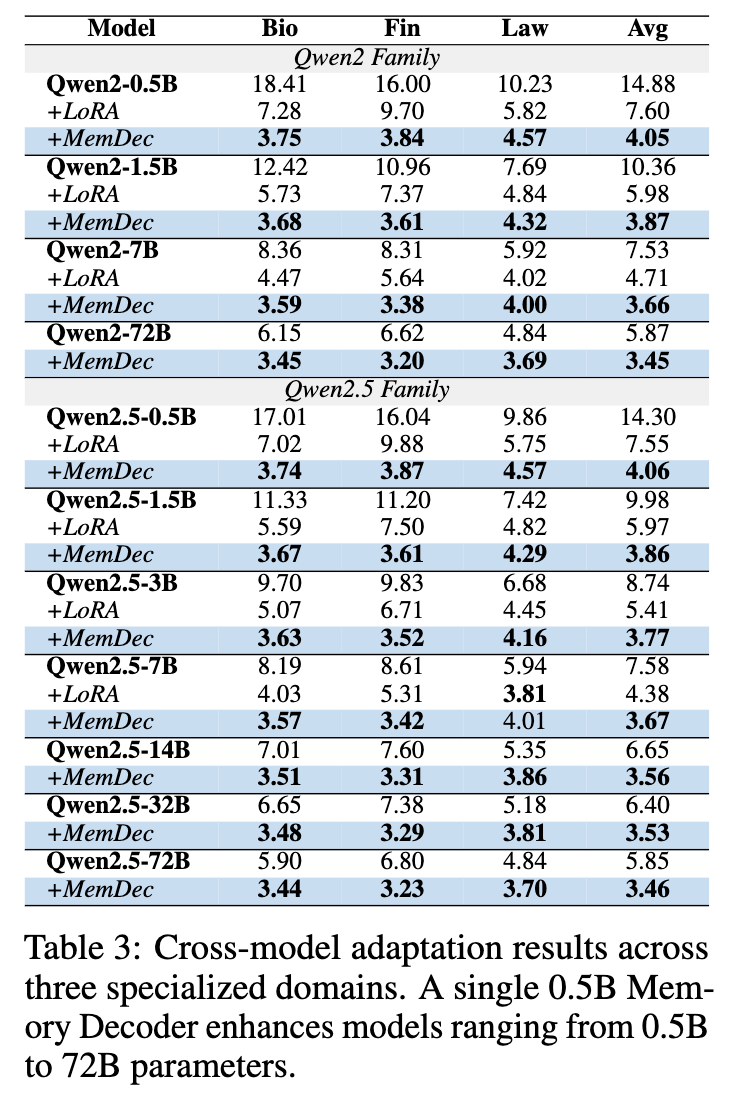
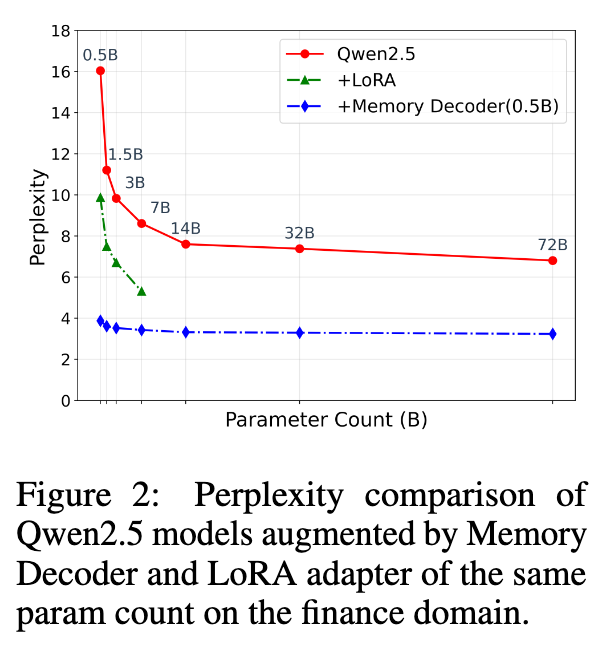
核心发现:
-
出色的通用性: 同一个 Memory Decoder 模块,无需任何修改,直接“插入”到不同大小、不同架构的模型中,都能带来持续且显著的性能提升。困惑度在生物医学、金融、法律三个领域都大幅下降。 -
资源效率: 传统方法需要为每个模型单独进行训练。而使用 MemDec,只需要针对一个领域训练一次,就能赋能整个模型家族。这极大地节省了计算资源。 -
参数效率: 实验显示,一个 0.5B 的基础模型在搭载了 MemDec 之后,其领域性能甚至可以超过一个未经优化的 72B 模型。这体现了超过 140 倍的参数效率。
3.4 跨词表 (Cross-Vocabulary) 自适应能力
这个实验进一步挑战了 MemDec 的通用性:将在 Qwen 词表上训练的 MemDec 迁移到使用不同词表的 Llama 模型家族上是否可行?
迁移方法: 研究者们将 Qwen 训练好的 MemDec 的 Transformer 主体部分参数固定,仅重新初始化其词嵌入层(embedding layer)和语言模型头(LM head),然后用原训练预算的 10% 在 Llama 架构上进行短暂的继续训练。
核心发现:
-
知识可迁移: 这种低成本的迁移是有效的。迁移后的 MemDec 在 Llama 模型上依然带来了巨大的性能提升,在生物医学和金融领域,困惑度降低了约 50%。 -
优于从零训练: 在生物医学和金融领域,迁移后的 MemDec 性能稳定地优于在 Llama 上从零开始训练的 LoRA。 -
结论: 这表明 Memory Decoder 学习到的核心领域知识主要编码在其 Transformer 结构中,而不是与特定词表强绑定的输入/输出层。这种能力极大地扩展了 MemDec 的实用范围,使其可以在不同模型生态系统之间进行知识迁移。
3.5 知识密集型推理任务
传统的检索方法(如 kNN-LM)虽然能提供事实信息,但有时会干扰模型进行复杂推理。本实验在 Natural Questions (NQ) 和 HotpotQA 这两个需要事实检索和多步推理的问答基准上进行了评测。
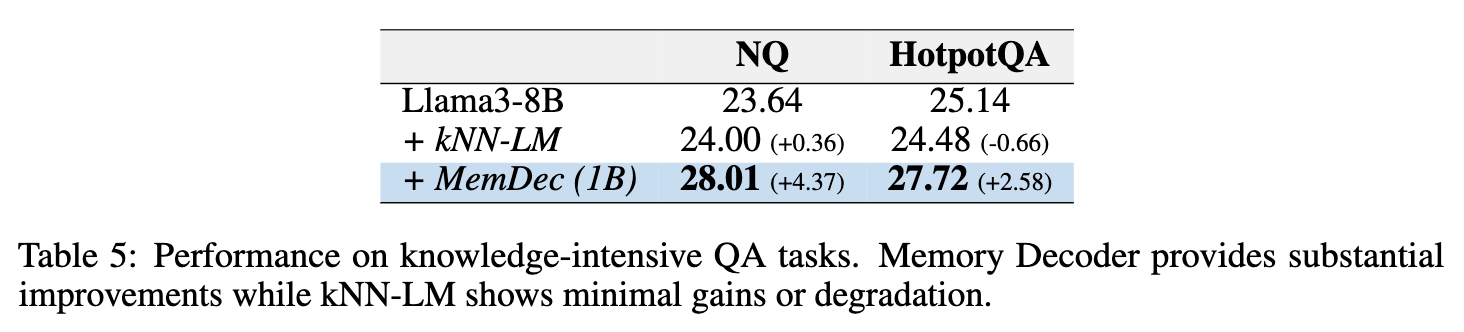
核心发现:
-
kNN-LM 在 NQ 上提升微弱,在 HotpotQA 上甚至导致性能下降。这印证了显式检索可能破坏模型的推理链条。 -
Memory Decoder 在两个基准上都取得了显著的性能提升(NQ: +4.37, HotpotQA: +2.58)。 -
原因推测: MemDec 通过在训练阶段内化检索模式,而不是在推理时生硬地拼接检索结果,学会了如何将事实知识与模型的组合推理能力更平滑地结合起来。它学会的不是“检索这个事实”,而是“在这样的上下文中,倾向于生成与某个事实相关的词元”。
3.6 推理延迟分析
最后,实验直接验证了 MemDec 的效率。
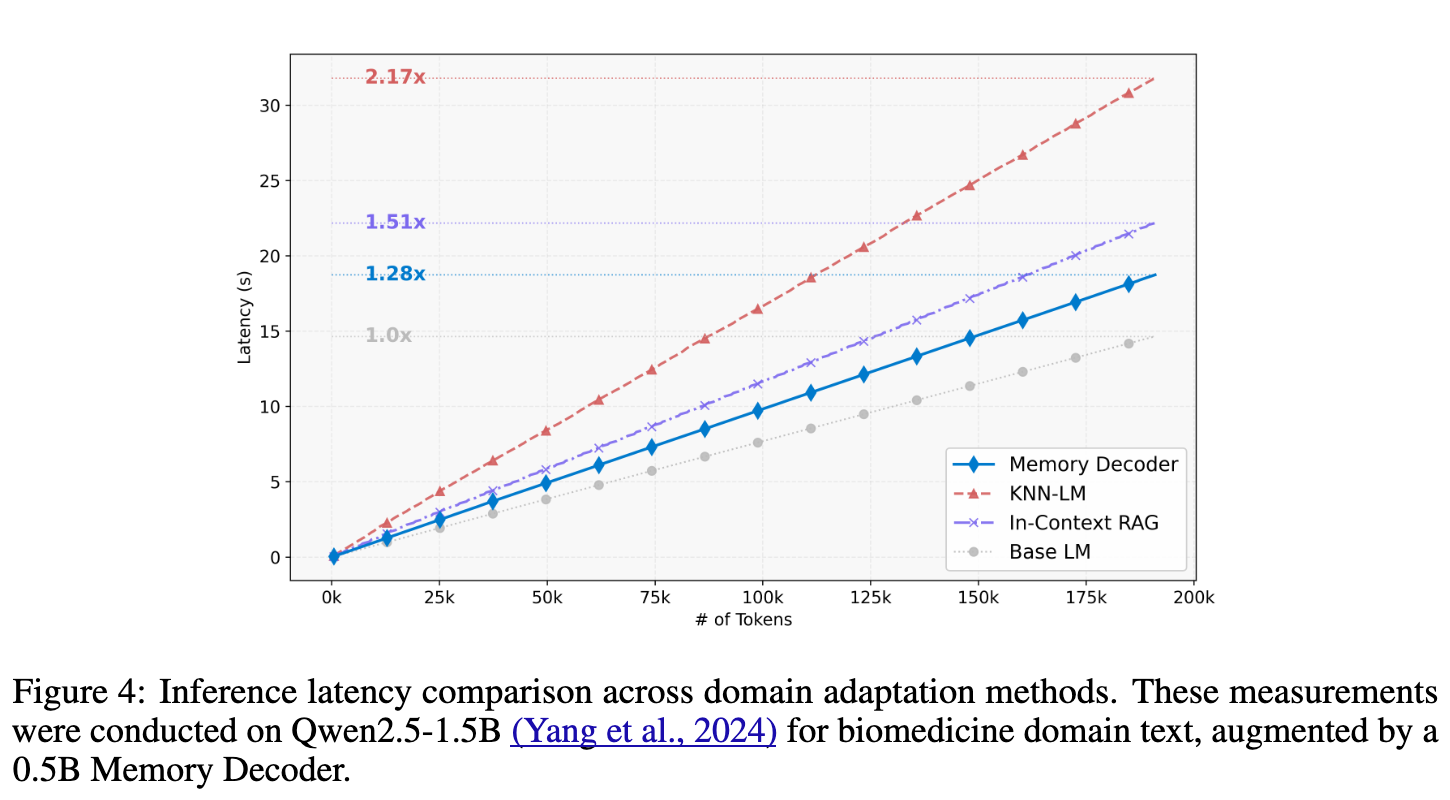
核心发现:
-
与基础 LLM 相比,MemDec 仅带来了约 1.28 倍的延迟开销。 -
这个开销显著低于 In-Context RAG(1.51倍)和 kNN-LM(2.17倍)。 -
随着处理的词元数量增加,MemDec 相对于 kNN-LM 的效率优势会越来越大,因为 kNN 搜索的成本与数据存储大小线性相关,而 MemDec 的前向传播成本是固定的。
4. 深入分析与讨论
4.1 案例研究:连接参数化与非参数化方法
为了更直观地理解 MemDec 学到了什么,研究者们进行了一个案例分析,观察不同方法对特定词元的概率分配。
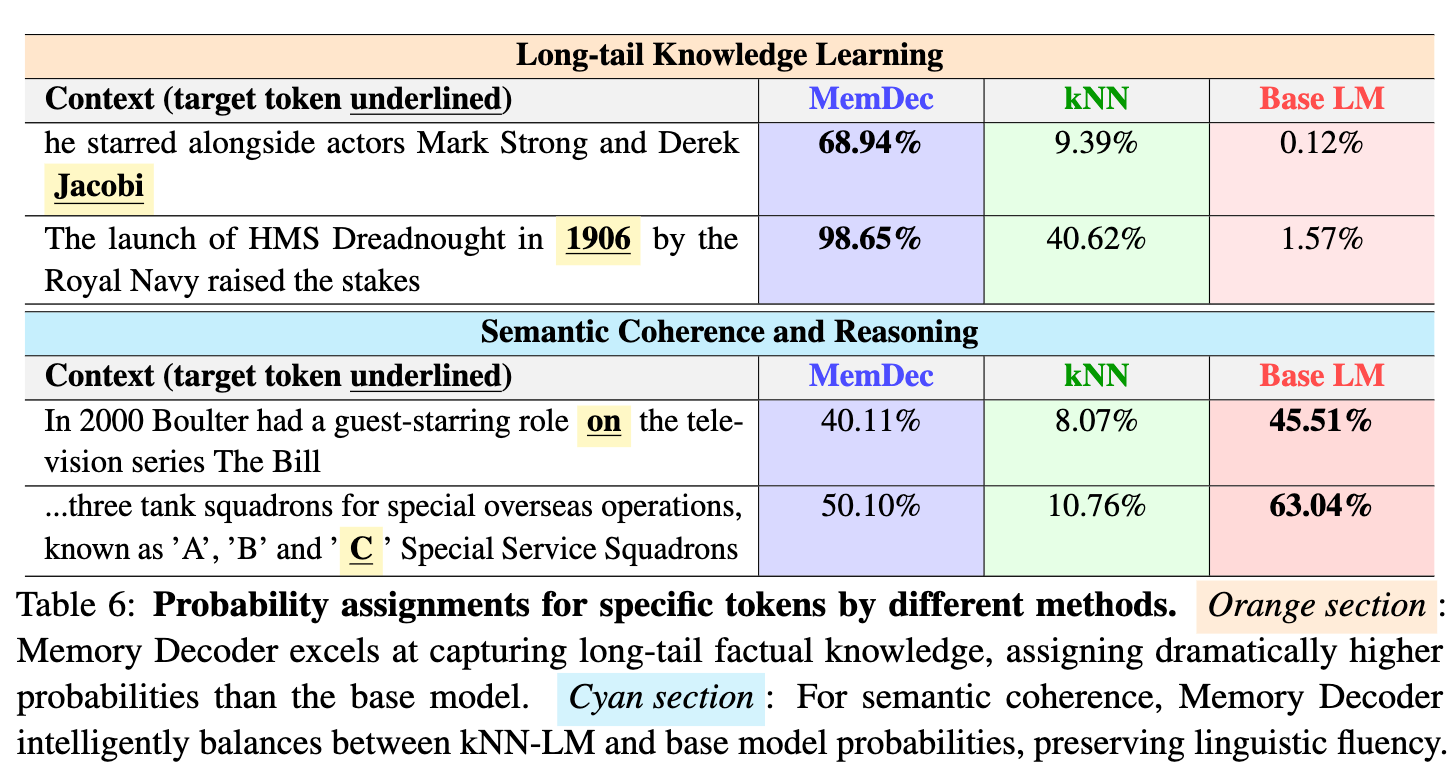
该分析揭示了 MemDec 的两个关键能力:
-
长尾知识记忆: 对于事实性信息,如演员 "Jacobi" 或年份 "1906",这些在通用语料中不那么常见。基础 LLM 分配的概率很低(0.12%, 1.57%)。kNN-LM 通过检索能够提升概率,但 MemDec 分配的概率更高(68.94%, 98.65%)。这表明 MemDec 成功地将数据存储中的长尾事实知识“背”了下来,其记忆能力甚至强于显式检索。 -
语义连贯性保持: 对于常见的、符合语法和逻辑的词,如介词 "on" 和序列 "'C'"。基础 LLM 基于其强大的语言模型能力,给出了很高的概率(45.51%, 63.04%)。而 kNN-LM 的检索结果可能受到噪声干扰,给出了较低的概率。此时,MemDec 的选择是更相信基础 LLM,其给出的概率与基础 LLM 更接近。这说明 MemDec 学会了智能地权衡,在需要事实时依赖“记忆”,在需要语言流畅性时依赖基础模型的“常识”,从而避免了纯检索方法可能带来的语言不连贯问题。
这个案例生动地展示了 MemDec 如何结合参数化方法(泛化能力和流畅性)和非参数化方法(记忆能力)的优点。
4.2 超参数敏感性分析
在推理时,插值系数 的选择是否困难?实验结果表明,MemDec 对此参数不敏感。
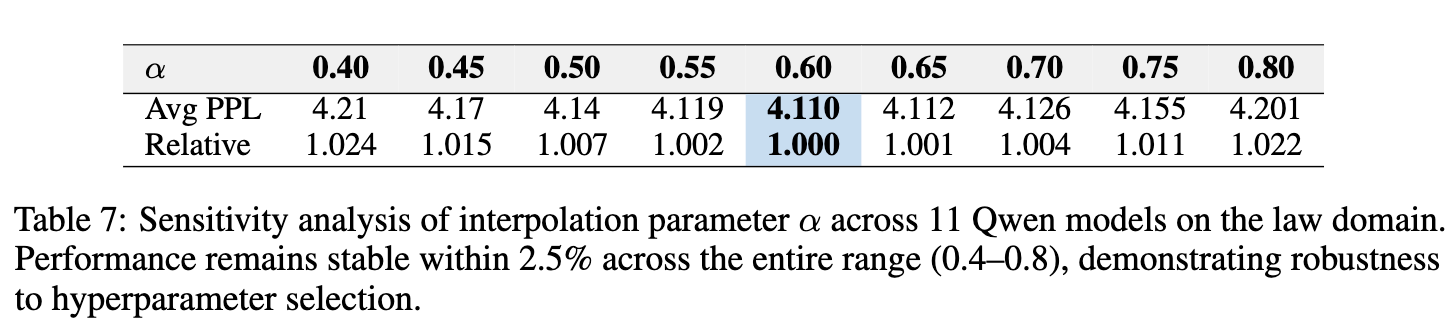
在 从 0.4 变化到 0.8 的大范围内,模型的性能(平均 PPL)变化幅度小于 2.5%。这意味着在实际部署时,用户不需要对 进行精细的调优,使用一个默认值(如 0.6)就能获得接近最优的性能,这降低了其使用门槛。
4.3 Memory Decoder 尺寸的影响
MemDec 本身的大小是否重要?实验结果是肯定的,但即便是小尺寸的 MemDec 也已足够强大。
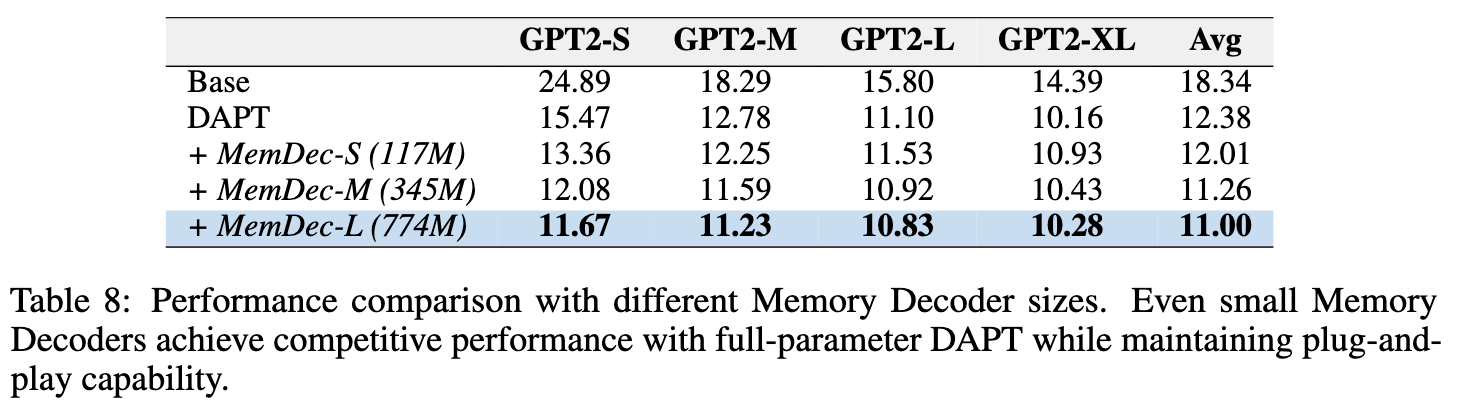
-
即使是最小的 117M 参数的 MemDec ( MemDec-S),其在 GPT2-medium 上的表现也超过了全参数的 DAPT (12.25vs12.78)。 -
随着 MemDec 尺寸的增加,性能稳步提升,大尺寸的 MemDec ( MemDec-L) 取得了最好的平均性能。 -
这为用户提供了灵活性:可以根据自己的计算预算来选择合适大小的 MemDec,在效率和性能之间做出权衡。
4.4 预训练目标消融研究
为了证明混合损失函数的必要性,研究者们进行了消融实验。
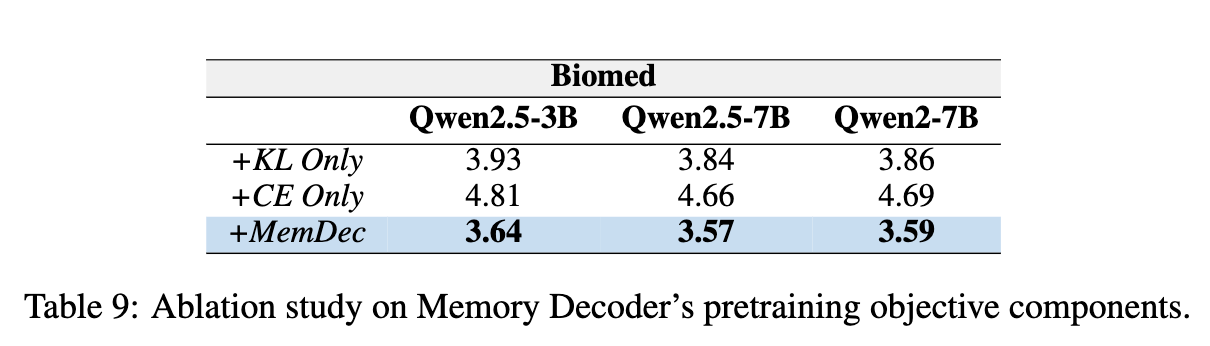
实验对比了三种设置:
-
+KL Only: 只使用 KL 散度损失,即只学习模仿 kNN 分布。 -
+CE Only: 只使用交叉熵损失,这等价于对一个小模型进行 DAPT。 -
+MemDec: 使用完整的混合损失函数。
结果显示,完整的混合损失函数 (+MemDec) 性能显著优于另外两种。这证明了分布对齐(从检索器学习)和标准语言建模(保持语言结构)这两个目标对于 MemDec 的成功缺一不可。
点评
这篇论文介绍了 Memory Decoder,一种用于大型语言模型领域自适应的新颖的即插即用方法。通过预训练一个小型 Transformer 解码器来模拟非参数化检索器的行为,Memory Decoder 成功地将任何兼容的语言模型适配到特定领域,而无需修改其原始参数。
Memory Decoder 的核心优势可以总结为:
-
多功能性 (Versatility): 一个预训练好的 Memory Decoder 可以无缝地增强共享相同分词器的任何模型,并且通过少量额外训练即可迁移到使用不同分词器和架构的模型。 -
高效性 (Efficiency): 与 RAG 和 kNN-LM 相比,它的推理延迟开销低。与 DAPT 相比,它极大地降低了将多个模型适配到同一领域所需的训练资源。 -
高性能 (Performance): 在语言建模、下游任务和知识密集型推理等多个方面,其性能都优于或具有竞争力。 -
能力保持 (Capability Preservation): 通过解耦领域知识和通用能力,它避免了 DAPT 中常见的灾难性遗忘问题。
作者在论文中也坦诚地指出了当前方法的一些局限性:
-
预训练成本: 虽然使用时很高效,但 Memory Decoder 的预训练阶段需要构建 kNN 分布作为训练信号。这个一次性的数据准备过程涉及对整个领域语料进行大量的 kNN 搜索,计算成本较高。 -
跨词表迁移: 尽管可以实现跨词表和架构的知识迁移,但它并非真正的“零样本”迁移。它仍然需要重新初始化并更新部分参数(嵌入层和输出层),并进行少量的继续训练来对齐嵌入空间。
往期文章:


