在人工智能飞速发展的今天,大型语言模型(LLMs)已经渗透到我们工作和生活的方方面面。然而,当我们惊叹于其强大的语言能力时,一个严峻的挑战也浮出水面:对齐(Alignment)。如何确保这些强大的模型其行为符合人类的意图和价值观,避免产生有害、有偏见或不可预测的输出,是整个AI安全领域的核心议题。
尽管研究人员投入了大量精力,发展出监督微调(SFT)、人类反馈强化学习(RLHF)等一系列对齐技术,但一个令人不安的现象反复出现:对齐似乎异常脆弱。一个经过精心“校准”的模型,可能在经历少量微调后就故态复萌,再次变得“不安全”。这不禁让我们追问:对齐微调究竟是在深层次上改变了模型,还是仅仅进行了“表面功夫”?
来自北京大学人工智能研究院的 Jiaming Ji、Kaile Wang、Yaodong Yang 等学者,在即将于2025年ACL(计算语言学协会年会)上发表的论文 《Language Models Resist Alignment: Evidence From Data Compression》(语言模型抵抗对齐:来自数据压缩的证据) 中,为我们揭示了这一现象背后的深刻机制。

-
论文标题:Language Models Resist Alignment: Evidence From Data Compression -
论文链接:https://aclanthology.org/2025.acl-long.1141.pdf
这篇论文开创性地从理论和实证两个角度,提出了一个全新的概念——模型的“弹性”(Elasticity)。作者们认为,正是这种“弹性”使得LLM在经过对齐后,仍然有一种强烈的趋势,想要恢复到其在海量数据预训练阶段所形成的原始行为分布。更重要的是,他们巧妙地借助数据压缩理论,为这一现象提供了坚实的数学解释和量化分析。
本文将带你深入解读这篇论文,一起探索LLM内心深处的“固执”本性,并思考如何才能实现更鲁棒、更深层次的对齐。
一、对齐的脆弱性:一个亟待解释的现象
在深入探讨“弹性”之前,我们先来回顾一下当前LLM对齐所面临的困境。
传统的对齐方法,如SFT和RLHF,本质上是通过在高质量、经过筛选的数据集上对预训练好的LLM进行微调,从而引导模型学习“好的”行为模式,抑制“坏的”行为模式。例如,通过RLHF,模型会学习去生成更符合人类偏好的回答。
然而,一系列研究和实践表明,这种对齐效果并不牢固:
-
“越狱”轻而易举:即便是经过严格安全对齐的模型,也可能被一些精心设计的提示(prompt)所“欺骗”,从而绕过安全机制,生成有害内容。 -
微调导致“遗忘”:有研究发现,使用少量、甚至是无害的数据对一个安全对齐的模型进行微-调,也可能削弱其安全性能。 -
表面对齐:一些学者认为,当前的对齐技术可能只是在模型的“表层”进行修改,并未真正触及模型内部的表征和机制,因此效果脆弱。
这些现象共同指向一个核心问题:为什么对齐如此脆弱? 是我们的方法错了,还是LLM本身就存在某种内在的“抵抗”机制?这篇论文正是要回答这个问题。
二、核心洞见:模型的“弹性”及其物理类比
为了解释对齐的脆弱性,论文的作者们引入了一个核心概念——弹性(Elasticity)。他们认为,对齐后的模型就像一根被拉伸的弹簧,总有一种恢复原状的内在倾向。
为了更好地理解这个概念,我们可以看论文中的一个精彩类比:
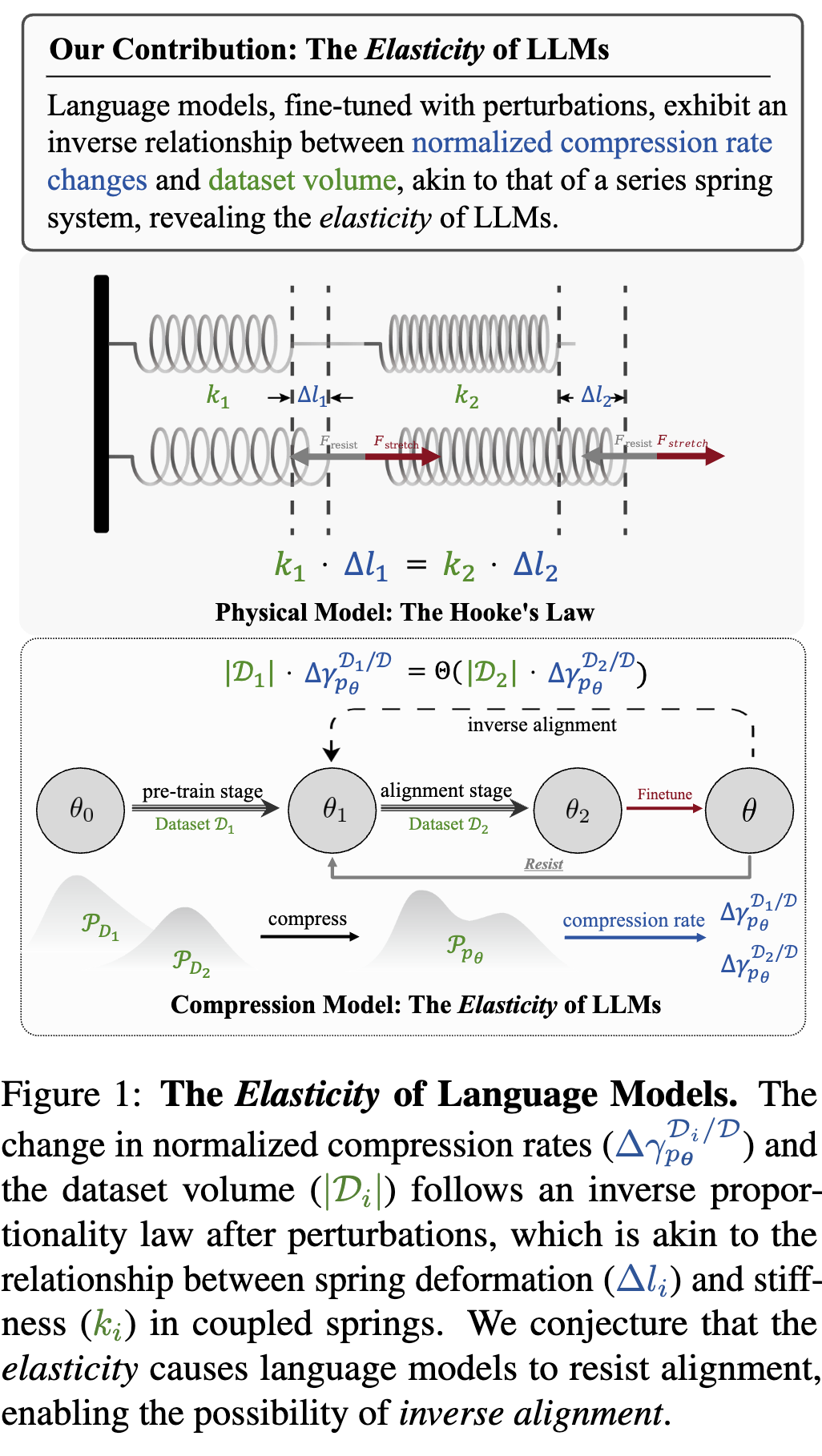
上图将LLM的对齐过程与一个串联弹簧系统进行了类比:
-
两个弹簧:代表模型在两个不同数据集上学习到的行为分布。 -
弹簧的劲度系数 ():代表不同数据集的规模()。预训练数据集规模巨大( 很大),如同一个劲度系数极大的硬弹簧;而对齐数据集规模相对较小( 很小),如同一个劲度系数较小的软弹簧。 -
弹簧的形变():代表模型在相应数据集上的行为变化,论文中用“归一化压缩率的变化”()来衡量。 -
外力():代表后续的微调(或称为“扰动”)对模型产生的影响。
根据物理学中的胡克定律,当一个外力作用于串联弹簧系统时,两个弹簧受到的力是相等的()。这意味着,劲度系数越大的弹簧,其形变量越小;反之,劲度系数越小的弹簧,其形变量越大。
将这个物理模型映射到LLM的对齐过程中,我们可以得到一个惊人的推论:当模型受到新的微调(外力F)时,由于预训练数据集()的规模远大于对齐数据集(),模型在预训练分布上的变化()将远小于在对齐分布上的变化()。
换句话说,微调对对齐阶段学到的知识影响巨大(容易忘记),而对预训练阶段学到的知识影响甚微(难以改变)。模型会“牺牲”在小规模对齐数据上学到的行为,以“保护”在海量预训练数据上形成的根深蒂固的知识和行为模式。
这种为了保持预训练阶段形成的“本性”而抵抗对齐微调的内在倾向,就是作者们所定义的 “弹性”。
三、理论基石:从数据压缩视角看模型训练
将模型训练与弹簧系统类比,是一个非常直观且有启发性的想法。但要使其成为严谨的科学结论,还需要坚实的理论基础。这篇论文的精妙之处,就在于它成功地利用了数据压缩理论,为“弹性”现象提供了数学化的建模和证明。
3.1 语言建模即压缩
首先,我们需要理解一个基本前提:语言建模等价于数据压缩。这个观点源于信息论的创始人香农。简单来说:
-
一个好的语言模型能够准确预测下一个词的概率。 -
一个好的数据压缩算法(如算术编码)需要知道序列中下一个符号的概率,概率预测越准,压缩效率越高。
因此,最小化语言模型的预测损失(负对数似然),就等价于最小化用该模型进行数据压缩后的编码长度。这为我们使用“压缩率”作为衡量模型在特定数据集上性能的代理指标(surrogate metric)提供了理论依据。压缩率越低,说明模型对该数据集的“理解”越好,预测越准。
3.2 弹性理论的数学推导
基于“建模即压缩”的等价性,作者们构建了一套用于分析模型弹性的数学框架。虽然过程非常复杂,涉及大量的数学公式,但我们可以抓住其核心思想。
1. 现象(Phenomenon)的定义
论文首先从现象上定义了弹性,它包含两个方面:
-
抵抗(Resistance):预训练模型倾向于保持其原始分布,抵抗对齐。 -
回弹(Rebound):模型被对齐得越“深”(即在对齐任务上表现越好),在受到反向微调时,其“反弹”回预训练分布的速度就越快。
2. 核心定理:模型弹性定理 (Theorem 4.2)
这是整篇论文的理论核心。作者们证明了,当一个在多个数据集(比如,一个大的预训练数据集 和一个小的对齐数据集 )上训练的模型,受到新的、小规模数据 的微调扰动时,其在 和 上的归一化压缩率的变化率满足以下关系:
其中:
-
是扰动数据集大小与对齐数据集大小的比值。 -
是预训练数据集大小与对齐数据集大小的比值。 -
是模型在数据集 上的归一化压缩率。 -
表示两者存在量级上的正比关系。
这个公式的直观解释是:模型在两个数据集上压缩率变化的速率,与这两个数据集的大小成反比。由于预训练数据集 的规模( 值)通常比对齐数据集 大几个数量级,因此,一个微小的扰动( 的变化)就会导致对齐效果()发生剧烈变化(迅速恶化),而预训练的效果()则相对稳定。
这完美地印证了弹簧类比:对齐是脆弱的,因为它是在一个规模小得多的数据集上进行的“微调”,这种改变很容易被后续的扰动所“抹去”,模型会倾向于回到由海量数据塑造的、更“稳定”的预训练状态。
3. 逆向对齐(Inverse Alignment)的可能性
模型的弹性机制也揭示了“逆向对齐”的可能性。“逆向对齐”指的是,通过一系列技术手段,可以轻易地将一个对齐好的模型“恢复”或“撤销”到其对齐前的状态。由于弹性效应,我们只需要一个规模远小于原始对齐数据集的“反向”数据集,就能高效地破坏对齐效果。这为恶意使用者“越狱”模型提供了理论上的便利,也对AI安全构成了巨大威胁。
四、实证研究:在多种模型和任务上验证“弹性”
理论的优美需要实验的支撑。作者们进行了一系列精心设计的实验,从多个维度验证了模型弹性的存在及其影响因素。
4.1 实验一:验证“抵抗”(Resistance)现象
为了验证模型对预训练分布的“固守”,作者设计了一个巧妙的实验,比较了“前向对齐”和“逆向对齐”的难度。
-
实验设置:
-
在一个预训练模型 的基础上,进行SFT微调,并保存中间的模型检查点,比如 。越往后的检查点,对齐程度越高。 -
从检查点 和 (其中 )在留存的prompt上生成的数据,分别构成数据集 和 。 -
前向对齐(Path A):在对齐程度较低的模型 上,使用对齐程度更高的数据 进行训练。这模拟了常规的对齐过程。 -
逆向对齐(Path B):在对齐程度较高的模型 上,使用对齐程度较低的数据 进行训练。这模拟了“撤销”对齐的过程。
-
-
核心假设:如果模型存在“抵抗”,那么“逆向对齐”(回到更接近预训练的状态)应该比“前向对齐”(进一步远离预训练状态)更容易,即训练损失更低。
-
实验结果:
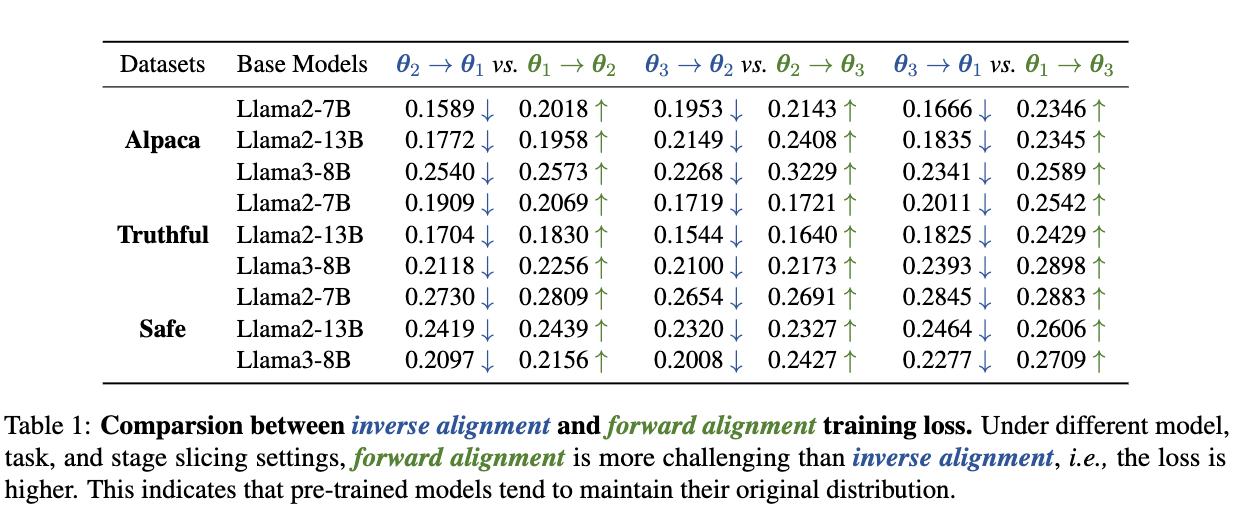
如上表所示,在 Llama2-7B/13B、Llama3-8B 等多种模型上,以及在 Alpaca(指令遵循)、Truthful(真实性)、Safe(安全性)等多种任务上,逆向对齐(如 )的训练损失总是显著低于前向对齐(如 )。
这一结果强有力地证明了,模型倾向于维持其原始的、更接近预训练的分布,对齐的改变是“逆水行舟”,而回到原始状态则是“顺水推舟”。
4.2 实验二:验证“回弹”(Rebound)现象
“回弹”指的是,一个对齐得越好的模型,在受到反向微调时,其性能下降得越快。
-
实验设置:
-
首先使用不同数量的“正面”数据(如安全的、积极的评论)对预训练模型进行SFT,得到一系列对齐程度不同的模型。正面数据越多,模型初始性能越好。 -
然后,使用不同数量的“负面”数据(如不安全的、消极的评论)对这些对齐好的模型进行“逆向微调”。 -
观察模型在相应任务上的性能(如安全评分、正面评论生成比例)如何随着负面数据的增加而变化。
-
-
实验结果:
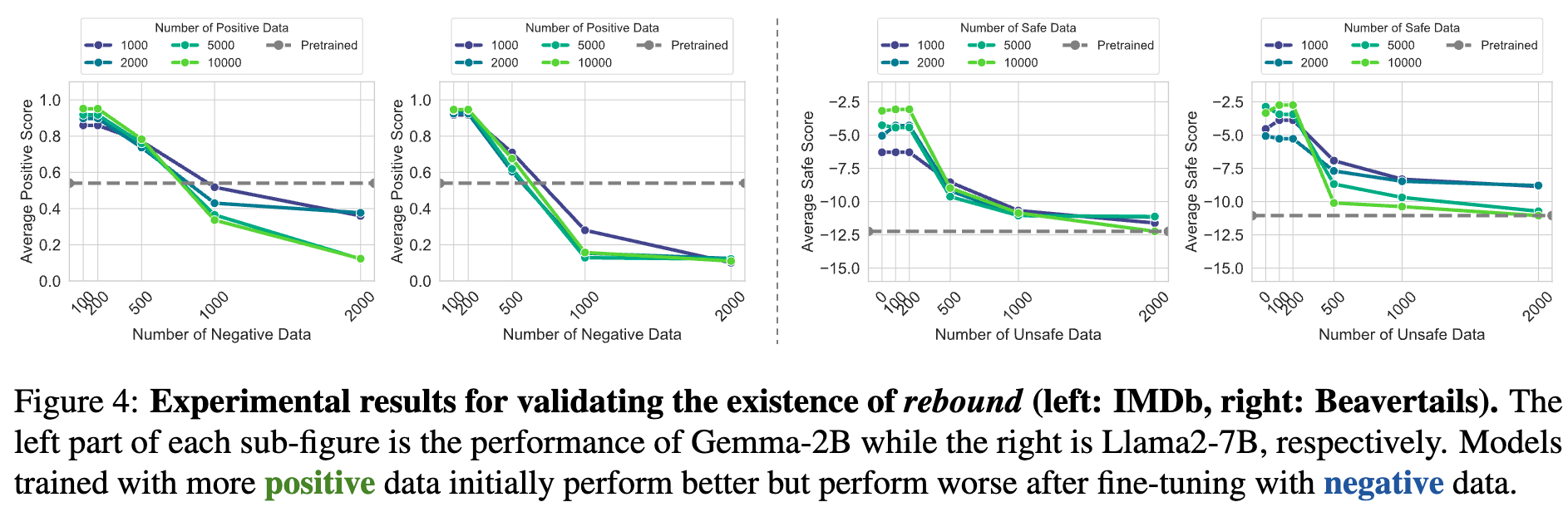
上图展示了在 IMDb(情感分类)和 Beavertails(安全对话)数据集上的结果。可以清晰地看到:
-
初始性能越高的模型(蓝线,用更多正面数据训练),在加入少量负面数据后,性能下降得越剧烈、越迅速。 -
随着负面数据的增加,所有模型的性能都快速下降,之后下降速度减缓,趋于一个稳定的较低水平,这个水平接近于原始的预训练模型状态。
这完美地诠释了“回弹”和“抵抗”:初始的急剧下降是“回弹”,因为模型离预训练状态“太远”;后续的趋于稳定是“抵抗”,因为模型已经回到了它所“偏爱”的预训练分布附近,不愿再做大的改变。
4.3 实验三:弹性与模型规模、预训练数据量的关系
模型的弹性是不是一成不变的?作者们进一步探究了它与两个关键因素的关系:
-
模型规模:
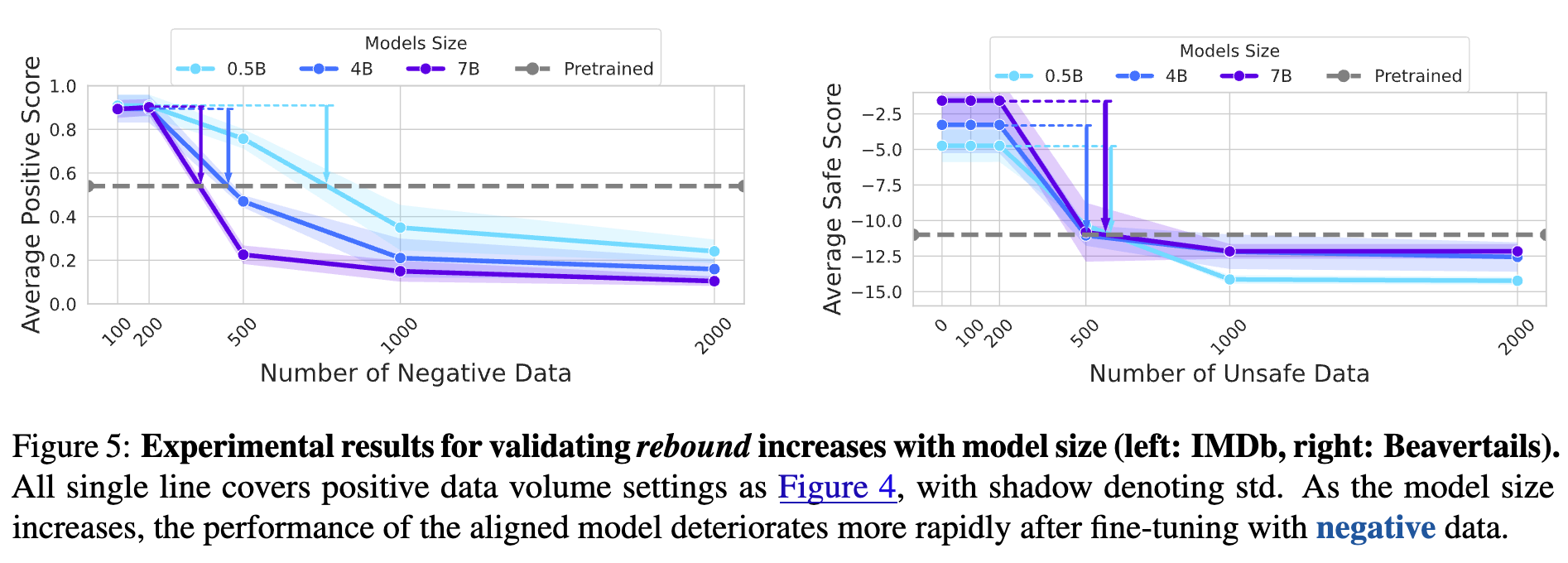
通过在 Qwen 模型系列(0.5B, 4B, 7B)上进行实验,结果显示,模型参数规模越大,弹性越强。具体表现为,在受到相同数量的负面数据微调时,更大模型的性能下降得更快、更剧烈。这表明,更大的模型更“固执”,更倾向于坚守其预训练学到的知识。
-
预训练数据量:
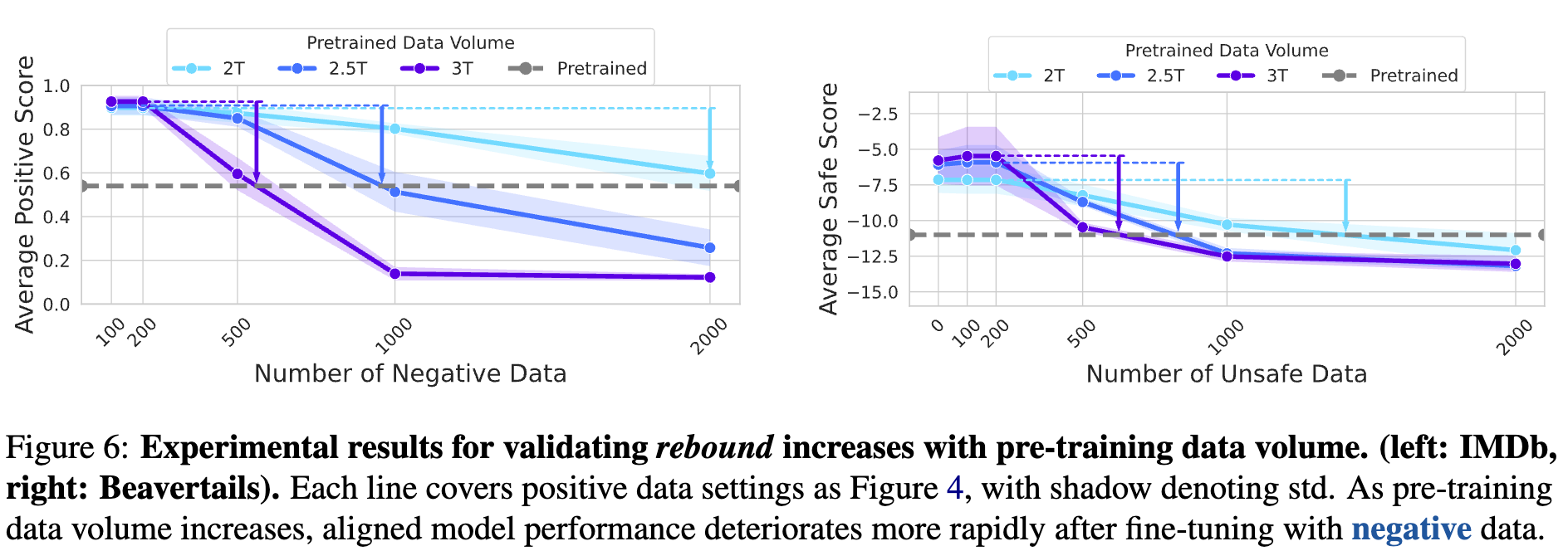
使用 TinyLlama 系列在不同预训练数据量(2.0T, 2.5T, 3.0T tokens)上训练的模型进行实验,结果同样清晰:预训练数据量越大,模型的弹性也越强。这与理论是完全一致的,因为更大的预训练数据量相当于一个劲度系数更大的“弹簧”,其恢复力自然也更强。
这些实验结果不仅验证了理论的正确性,也为我们提供了重要的实践启示:随着LLM的参数和预训练数据规模持续爆炸式增长,对齐将变得越来越困难,模型的“抵抗”和“弹性”问题将愈发突出。
五、影响与启示:重新思考对齐与开源
这项研究的意义不仅在于揭示了一个新的现象,更在于它促使我们从一个更根本的层面上重新审视LLM的对齐问题和开源策略。
5.1 对对齐技术的启示
如果模型天然存在“弹性”,那么我们当前的对齐范式可能需要做出调整:
-
克服数据量级差异:弹性的根源在于预训练和对齐阶段的数据量差异巨大。一个直接的想法是,我们能否在对齐阶段也使用海量数据?但这在成本上是不可行的。因此,一个更实际的方向可能是,如何设计出更高效的对齐算法,能够用少量数据实现更“深入”、更“持久”的改变,而不是停留在表面。 -
超越“表面”对齐:研究表明,我们需要让对齐技术能够真正渗透到模型的内部机制中,而不仅仅是修改输出层的行为。 -
量化对齐难度:弹性理论提供了一个框架,可以用来量化实现某种对齐目标所需的数据量。这有助于我们更科学地设计对齐策略,而不是依赖经验和试错。
5.2 对模型开源的警示
开源LLM极大地促进了AI技术的发展和普及,但弹性和逆向对齐的存在,也为开源模型带来了新的安全风险。
-
“洗白”易,“染黑”更易:一个经过精心安全对齐并开源的模型,可能会被恶意行为者用极小的代价进行“逆向对齐”,恢复其有害能力,甚至进行“欺骗性对齐”(Deceptive Alignment),使其表面安全,实则包藏祸心。 -
平衡开放与安全:这项研究提醒我们,在享受开源带来的好处的同时,必须严肃对待其潜在的滥用风险。仅仅依赖发布前的安全审计可能是不够的,因为模型发布后其安全性可能被轻易颠覆。我们需要发展更具鲁棒性的、难以被逆转的对齐技术,才能在开源生态中维持一个健康的攻防平衡。
5.3 未来研究方向
这篇论文也为未来的研究打开了新的大门:
-
普适性验证:该现象是否在多模态模型中也普遍存在? -
与规模定律(Scaling Laws)的结合:如何将弹性理论与模型性能的规模定律结合,精确预测模型变大后对齐的难度变化? -
设计抗弹性对齐算法:基于弹性理论,开发全新的、能够从根本上克服模型抵抗的对-齐方法。
六、总结
论文通过引入“弹性”这一全新的、直观的概念,并辅以严谨的数据压缩理论和扎实的实验证据,深刻地揭示了当前LLM对齐技术为何如此脆弱的内在原因。
这项工作告诉我们,LLM并非一块可以随意塑造的“橡皮泥”,而是一个拥有自身“惯性”和“记忆”的复杂系统。它在海量数据中形成的“世界观”根深蒂固,会本能地抵抗那些试图用少量数据从根本上改变它的企图。
理解了模型的“弹性”,我们才能更好地应对AI安全的挑战。这不仅仅是技术层面的攻防,更是对我们如何理解、塑造和控制一个日益强大的智能体的根本性思考。未来的道路依然漫长,但像这样深刻的洞察,无疑为我们照亮了前行的方向。
往期文章:


