研究界的主流范式是将模型的训练过程清晰地划分为两个阶段:首先是通过在海量通用文本上进行自监督学习的预训练(Pretraining)阶段,旨在构建一个通识性的、知识广博的基础模型;随后是通过在高质量、特定任务的数据集上进行监督微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL)的后训练(Post-Training)阶段,旨在向模型注入特定的技能,尤其是复杂的推理能力。
这种两阶段的划分虽然在实践中取得了显著成功,但也形成了一种思维定式:推理能力是一种可以“附加”在通用语言基础之上的高级技能。因此,大量的研究工作和算力资源被投入到后训练阶段,探索如何通过更优质的数据、更精巧的算法来提升模型的推理表现。然而,一个根本性的问题在很大程度上被忽视了:推理能力的基础,是否必须、以及应该在多大程度上,在预训练阶段就进行基础铺垫?
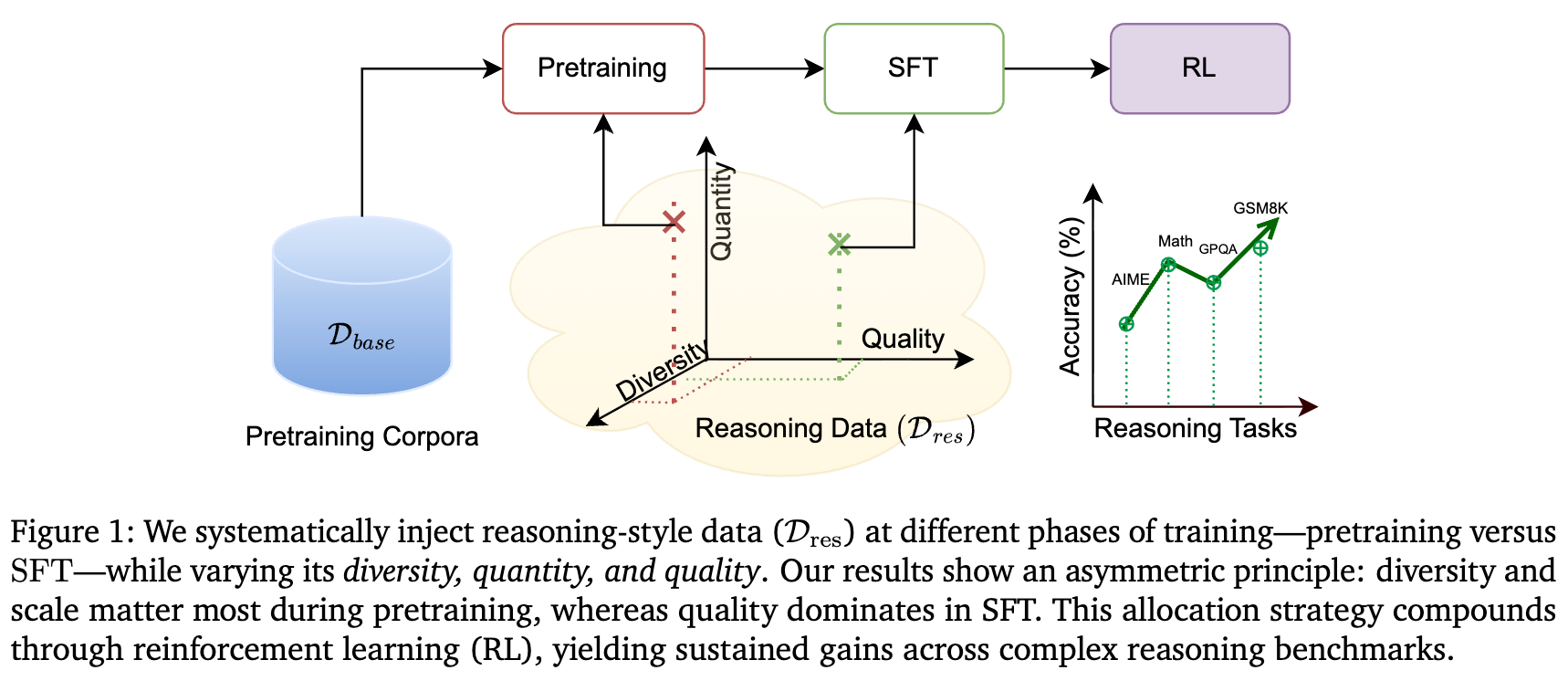
来自 NVIDIA 的论文《Front-Loading Reasoning: The Synergy between Pretraining and Post-Training Data》,对这些问题进行了首次系统性的、大规模的实证研究。他们的工作挑战了传统上将语言建模和推理能力培养相分离的观念,通过一系列精心设计的控制实验,揭示了在整个训练流程中策略性地分配推理数据的深刻影响。这项研究的核心结论是:将推理数据“前置”(Front-Loading)到预训练阶段是至关重要的,它能够为模型建立一个持久的、可复利的基础优势,而这种优势是后期任何强度的SFT都无法完全复制的。

-
论文标题:Front-Loading Reasoning: The Synergy between Pretraining and Post-Training Data -
论文链接:https://www.arxiv.org/pdf/2510.03264
1. 关于数据分配的优化问题
为了系统性地研究推理数据在不同训练阶段的作用,作者首先将这个问题形式化为一个优化问题。其核心目标是,在给定的推理数据总量预算下,如何将其在预训练(Pretraining, PT)和监督微调(Supervised Fine-Tuning, SFT)两个阶段之间进行分配,从而最大化最终模型在下游推理任务上的性能。
我们用 表示可用的推理数据集的总和。这个数据集可以被划分为两个部分:
-
:用于预训练阶段的推理数据。 -
:用于SFT阶段的推理数据。
这两部分数据共同构成了总预算 ,即 。
模型的训练过程包含两个阶段。我们设模型为 ,其参数为 。
第一阶段:预训练
在预训练阶段,模型的目标是最小化标准的语言模型损失函数 。训练数据由两部分构成:一个大规模的通用预训练语料库 ,以及分配给此阶段的推理数据 。该阶段结束后,我们得到的模型参数为 :
其中, 是模型对输入 的预测, 是真实的目标。
第二阶段:监督微调
在SFT阶段,模型以 为起点,使用分配给此阶段的推理数据 进行微调。其目标是最小化SFT损失函数 (通常也是交叉熵损失),得到最终的模型参数 :
评估目标
研究的最终目标是评估最终模型 (在论文后续也称为 )在下游一系列推理任务 上的性能。我们将这个性能函数定义为 ,它是模型在任务集 上的平均准确率(Accuracy):
因此,整个研究的核心可以概括为求解以下优化问题:
这个框架清晰地定义了研究的核心权衡(trade-off):是在早期(预训练)投入更多推理数据以构建更强的基础,还是在后期(SFT)投入更多数据以进行针对性的强化?数据的规模(scale)、多样性(diversity)和质量(quality)在这一权衡中又各自扮演什么角色?这正是论文后续实验所要解答的问题。
2. 实验
为了有效地回答上述问题,作者设计了一套严谨且全面的实验流程。这套流程的核心在于对数据变量的精细控制和对训练阶段的系统性组合。
2.1. 模型架构与基线
研究选用了一个拥有80亿(8B)参数的混合架构模型作为基础模型 。该模型结合了 Mamba 2、自注意力(self-attention)和前馈网络(FFN)层。选择8B这个参数规模,是在计算可行性与模型学习复杂推理模式的能力之间取得的一个平衡点。所有模型都从零开始进行1万亿(1T)token的预训练,确保了实验的公平性和可比性。
2.2. 数据
实验设计的基石是对数据的精确划分。作者将数据分为两大类:
-
通用预训练语料库 ()
这是所有预训练实验的“背景板”。作者采用了NVIDIA在另一项工作中引入的数据集,其中包含6.2万亿(6.2T)token,来源包括高质量的Common Crawl、数学和代码数据。这个语料库覆盖了广泛的语言和技术领域,为模型提供了通用的语言知识基础。
-
推理导向的数据集 ()
这是实验中的核心自变量。为了研究数据质量(quality)、多样性(diversity)和规模(scale)的影响,作者精心策划并使用了四种不同的推理数据集,它们均采用问答(question-answer)格式:
-
(Large-Scale, Diverse Data / 大规模、多样性数据)
-
来源: Nemotron-Pretraining-SFT-v1 数据集。 -
特点: 这是一个规模巨大的数据集,包含3360亿(336B)token。其领域覆盖广泛,大致构成为56%数学,17%代码,27%科学和通用推理。数据质量参差不齐,推理深度各异,模拟了现实世界中大规模数据“量大但质杂”的特点。它代表了一种“数量优于质量”(quantity-over-quality)的策略。
-
-
(Small-Scale, High-Quality Data / 小规模、高质量数据)
-
来源: Guha et al. (2025) 的数据集。 -
特点: 该数据集规模小得多,包含约120万个精心策划的样本。其特点是包含了由强大教师模型生成的、详细的、长链思维(long chain-of-thought, CoT)轨迹。其领域分布相对集中(71%数学,21%代码,8%科学)。它代表了一种“质量优于数量”的策略,强调推理路径的深度和准确性。
-
-
(Large-Scale, Mixed-Quality Data / 大规模、混合质量数据)
-
构建方式: 直接将 和 进行并集操作,。 -
特点: 这个数据集既保持了大规模和广泛的领域覆盖,又注入了一部分高质量的推理样本。其目的是为了探究多样性和质量之间的平衡。
-
-
(Answer-Length Filtered Data / 答案长度过滤数据)
-
构建方式: 从 中筛选出答案长度超过4096个token的子集。 -
特点: 该数据集基于一个假设:更长的回答通常对应着更复杂的CoT推理。通过这种方式,作者试图从一个质量混杂的数据集中,以一种启发式的方式分离出复杂度更高的样本,用于专门研究推理深度在训练中的作用。
-
2.3. 三阶段训练与评估流程
整个研究流程被划分为三个阶段:
阶段一:预训练 (Pretraining)
此阶段的目标是探究在预训练中注入不同推理数据所带来的直接影响。作者基于引入的 类型的不同,训练了四个不同的基础模型。在所有情况下,预训练语料都由80%的 和20%的 组成,总计训练1T token。
-
: 基线模型。仅使用 进行预训练,不包含任何额外的推理数据。这是实验的控制组。 -
: 使用 进行预训练,检验大规模、多样性数据的效果。 -
: 使用 进行预训练,检验小规模、高质量数据的效果。 -
: 使用 进行预训练,检验混合质量数据的效果。
在后续分析中,作者使用 来指代三个注入了推理数据的模型()的平均性能。
阶段二:监督微调 (Supervised Finetuning)
此阶段是研究协同效应的关键。四个预训练好的模型()中的每一个,都会在不同的SFT推理数据集(如 等)上进行微调。这种“全交叉”(fully crossed)的实验设计,使得作者能够系统性地回答前文提出的核心问题:
-
检验“追赶假说”: 将 在高质量的 数据上进行SFT,观察其能否追上那些“赢在起跑线上”的 模型。 -
评估预训练数据的影响: 将 和 在相同的高质量SFT数据集()上进行微调,比较它们的最终表现,从而判断哪种预训练基础(广度优先 vs. 深度优先)更有利于吸收SFT阶段的知识。 -
评估SFT数据的影响: 将所有四种基础模型分别在不同质量和规模的SFT数据集( vs. )上微调,衡量SFT阶段数据质量的边际效用。
阶段三:强化学习 (Reinforcement Learning)
为了观察在预训练和SFT阶段形成的优势或劣势是否能够持续到模型对齐的最终阶段,并可能被进一步放大,作者对部分SFT后的模型部署了强化学习。他们使用了GRPO(Group Relative Policy Optimization)算法,在 nemotron-crossthink 数据集上进行训练,这个数据集已被证明能有效提升模型在多个领域的推理能力。这一阶段主要用于验证前两个阶段发现的规律的持久性和放大效应。
2.4. 评估指标
为了全面评估模型在不同阶段的能力,作者采用了分阶段、多维度的评估体系:
-
基础模型评估 (PT后): 关注模型的通用推理能力。使用了包括GPRPT AVG(通用推理)、MATHPT AVG(数学)、SCIENCEPT AVG(科学)和CODEPT AVG(代码)在内的多个基准测试集,如ARC, HellaSwag, GSM8K, MMLU, HumanEval等。 -
SFT模型评估: 关注模型在经过专门指令调优后的专业推理能力。评估标准更加严苛,引入了更复杂的基准,如AIME(美国数学邀请赛)、GPQA-Diamond(研究生水平的科学问答)、LiveCodeBench(复杂代码生成)和IFEval(指令遵循能力)。 -
RL模型评估: 采用与SFT阶段相同的复杂推理基准,以进行直接的性能对比。
3. 核心发现与结果分析
通过上述严谨的实验设计,作者获得了一系列具有深刻洞见的结果。这些结果不仅回答了引言中提出的问题,还揭示了一些关于数据分配的非对称原则。
3.1. 发现一:在预训练中“前置”推理数据可建立显著的即时优势
实验的第一组结果直接评估了四种基础模型在完成1T token预训练后的性能。
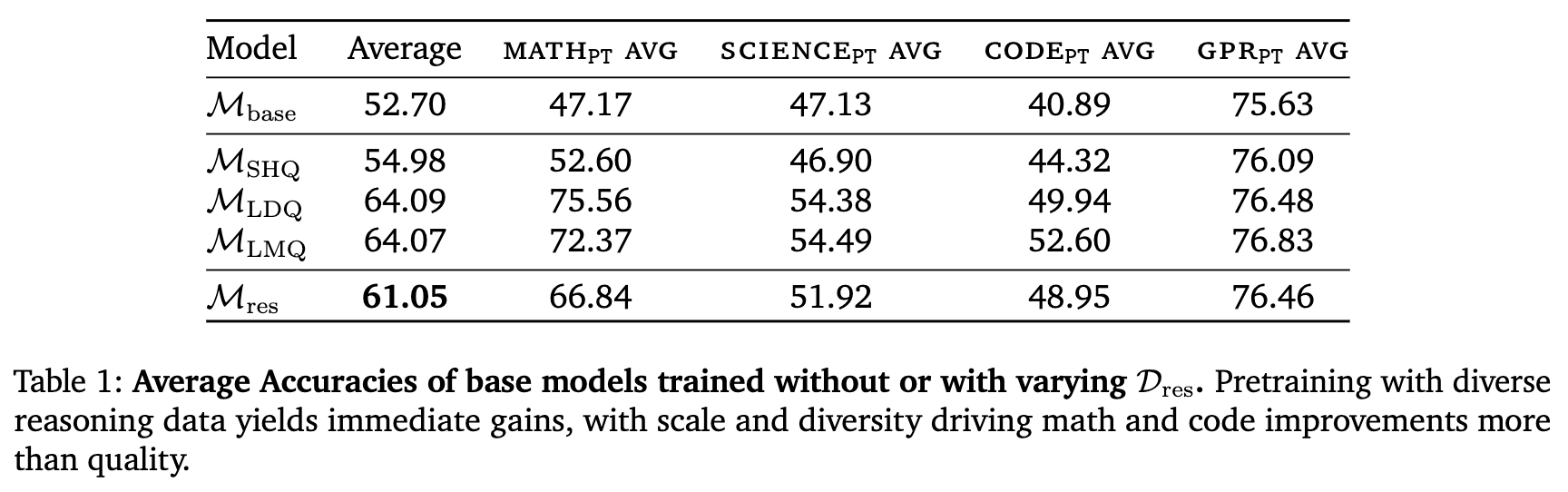
如表 1 所示,结果清晰地表明,任何在预训练阶段接触过推理数据()的模型,其性能都显著超过了基线模型 。
-
整体提升: 的平均分(61.05)比 (52.70)高出8.35个百分点,这是一个巨大的基础性提升。 -
规模与多样性的力量: 在预训练阶段,(大规模、多样性数据)取得了最高的平均分(64.09)。尤其是在数学(MATHPT AVG)和代码(CODEPT AVG)这两个高度依赖结构化推理的领域,其相对于 的提升分别达到了惊人的28.4%和9.05%。 -
质量的初步作用: 与之相比,(小规模、高质量数据)虽然也超越了基线,但其提升幅度(54.98)相对温和。
表 7 提供了更详细的基准测试分解,让我们能看清这些提升具体来源于何处。例如,在数学基准GSM8K上,(82.71)和(85.14)的表现远超(59.74)。在更难的MATH-500上,差距同样巨大。这表明大规模多样性数据能显著构建模型解决定量推理问题的基础。
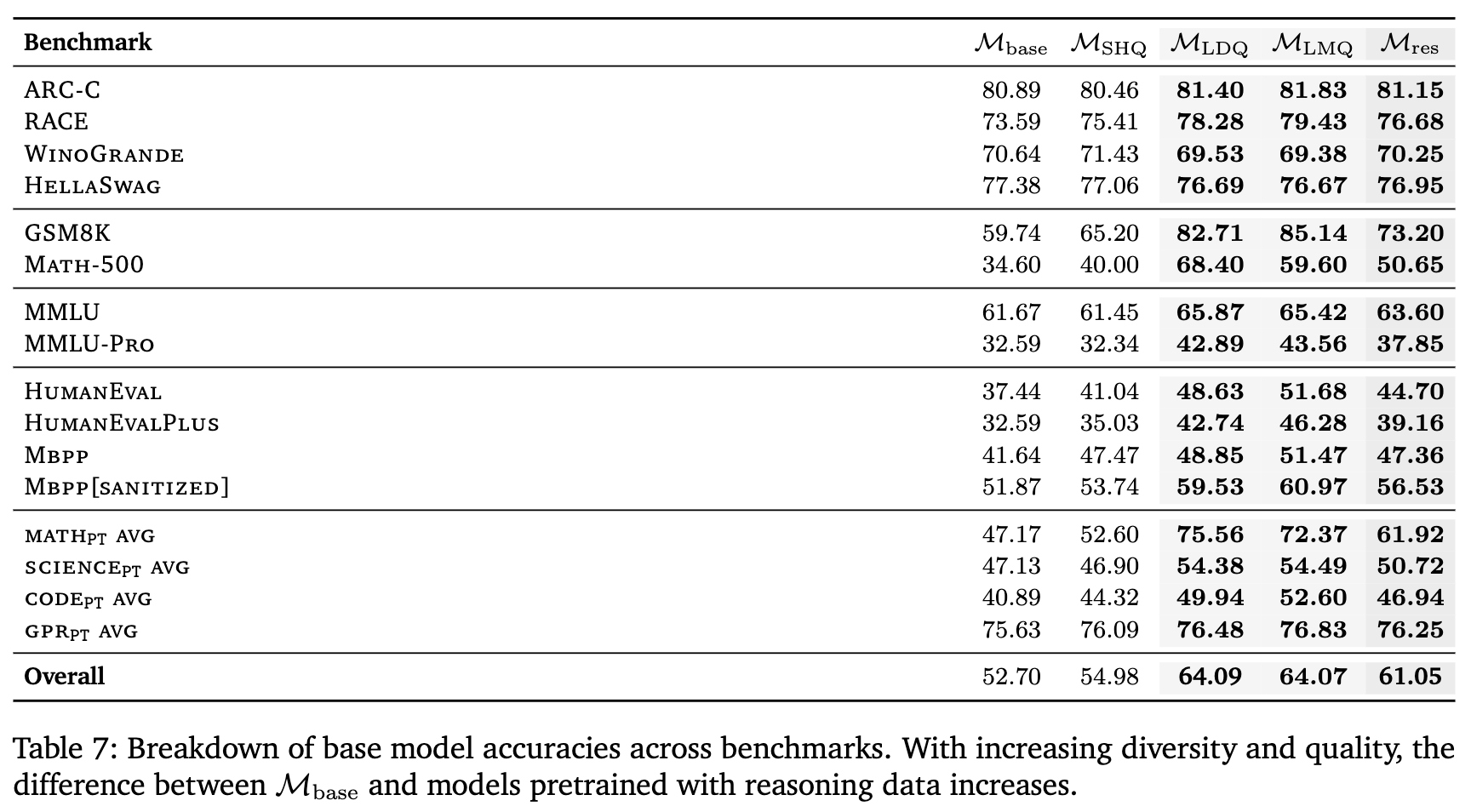
这一发现得出了第一个重要结论:在预训练的早期阶段,让模型广泛地接触不同类型、不同领域的推理模式(即数据的规模和多样性),比仅仅让它学习少量高质量的范例更为关键。
3.2. 发现二:“追赶假说”不成立,预训练优势在SFT后被保持并放大
接下来,作者检验了SFT能否抹平预训练阶段建立的差距。他们将所有基础模型都在高质量的推理数据()上进行了微调。
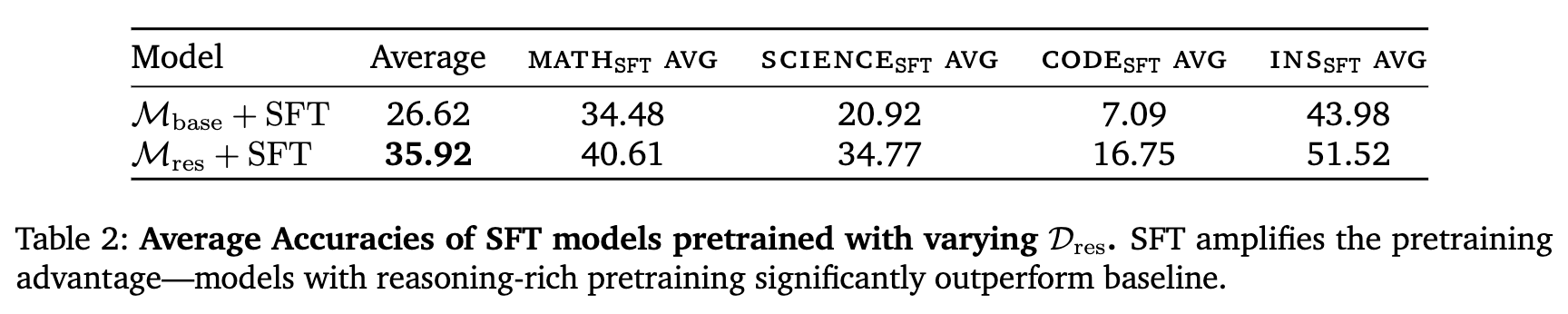
表 2 的结果有力地驳斥了“追赶假说”。
-
差距持续扩大: 经过SFT后,预训练时包含推理数据的模型组( + SFT)的平均性能(35.92)与基线模型组( + SFT)的平均性能(26.62)之间的差距被进一步拉大到了9.3%。这表明,SFT并不是一个可以弥补基础短板的“万能药”,而是一个放大器。一个更强的预训练基础能够让模型在SFT阶段更有效地学习,从而达到更高的性能天花板。 -
SFT并非替代品: 即使经过了与 同样强度的SFT,其表现仍然远远落后。这证明,在预训练阶段建立的推理基础是后期专业化训练所无法替代的。
表 8 提供了在SFT后各项基准测试上的详细得分。我们可以看到,在像AIME-24这样的高难度数学竞赛上,+SFT 的得分(41.88)是 +SFT(8.12)的五倍以上。这直观地展示了预训练优势是如何在SFT后被急剧放大的。
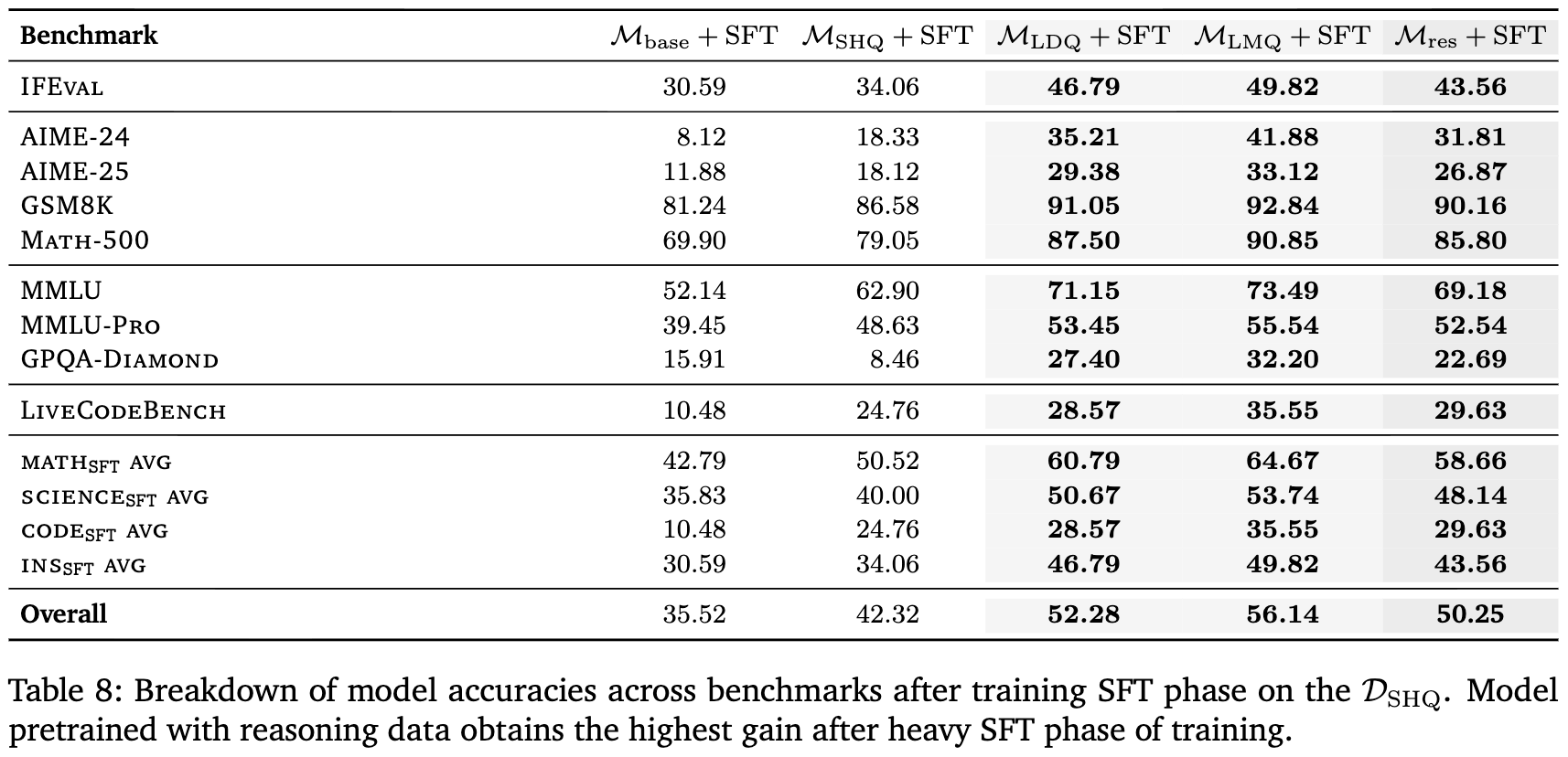
这一发现证实了“前置”推理的必要性:一个强大的推理基础必须在预训练阶段就开始构建。
3.3. 发现三:预训练策略决定了模型在专家级任务上的最终高度
为了验证这一优势的持久性,作者将模型推进到RL阶段,并在最具挑战性的专家级基准上进行评估。

如表 3 所示,在经过完整的“预训练 -> SFT -> RL”流程后,模型之间的性能差距达到了顶峰。
-
完全对齐后的 模型(预训练于混合数据)与 模型相比,在所有任务上的平均准确率领先了18.57%。这是一个决定性的差距。 -
在极具挑战性的AIME数学竞赛问题上,推理预训练模型相比基线模型实现了39.32%的性能提升。
综合以上三个核心发现,论文清晰地勾勒出一条因果链:在预训练阶段的投入,会转化为SFT阶段的学习效率,并最终决定模型在RL对齐后所能达到的性能上限。
4. 消融实验与分析
为了更深入地理解数据在不同阶段作用的机制,作者进行了一系列精巧的消融实验,从而揭示了关于数据分配的“非对称原则”以及数据质量的“潜在价值”。
4.1. 预训练阶段:规模与多样性压倒质量
如3.1节所述, 在预训练后的表现优于 。这强调了在构建基础模型时,广泛的视野(接触多样化的推理模式)比狭窄但深刻的钻研(学习少量高质量范例)更重要。一个在早期见识过各种“解题思路”的模型,其底层表征更具泛化性。
4.2. “追赶假说”的再次证伪:加倍SFT数据也无济于事
作者进行了一个更为苛刻的实验,他们将用于 的SFT数据量加倍( + SFT(2x)),试图通过“蛮力”来弥补其预训练的不足。
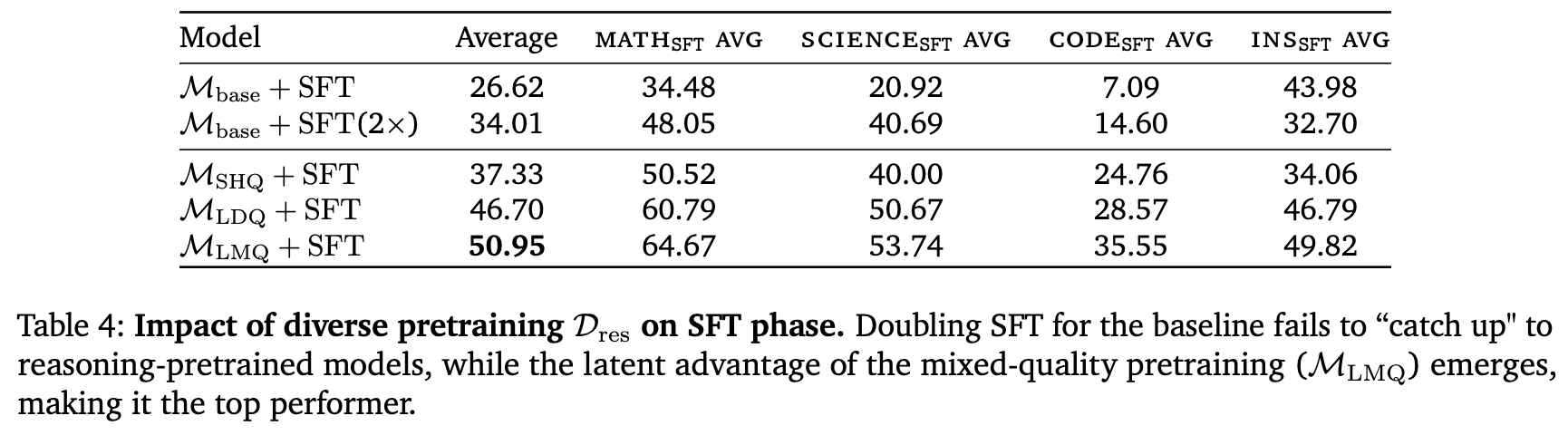
结果如表 4 所示,即便SFT数据翻倍, + SFT(2x) 的平均分(34.01)虽然有所提升,但仍然低于性能最弱的推理预训练模型 + SFT(37.33)。这提供了强有力的证据:预训练阶段所灌输的基础推理能力,具有某种“质”的特殊性,是无法简单地通过后期增加“量”来完全复制的。
4.3. 高质量预训练数据的“潜在价值”:SFT是解锁钥匙
表 4 还揭示了一个有趣的现象。在预训练后, (混合质量)和 (仅多样性)的性能非常接近。然而,在经过同样的高质量SFT之后, 的性能(50.95)明显超过了 (46.70),实现了额外的4.25%的性能提升。(更详细的分解见表8)
这揭示了一个关键的协同效应:在预训练阶段添加的高质量数据(),其价值在预训练结束时并未完全显现,是一种“潜在价值”(latent value)。SFT阶段就像一把钥匙,解锁了这些高质量数据在模型内部埋下的潜力。这表明,高质量数据在预训练中可能扮演着一个“补充放大器”(complementary amplifier)的角色,其效果需要在后续的对齐阶段才能被激活和放大。
4.4. 核心洞察:数据分配的非对称原则
前面的发现暗示了不同阶段对数据的“偏好”不同。为了验证这一点,作者将所有推理预训练模型()分别在不同的SFT数据集上进行微调。
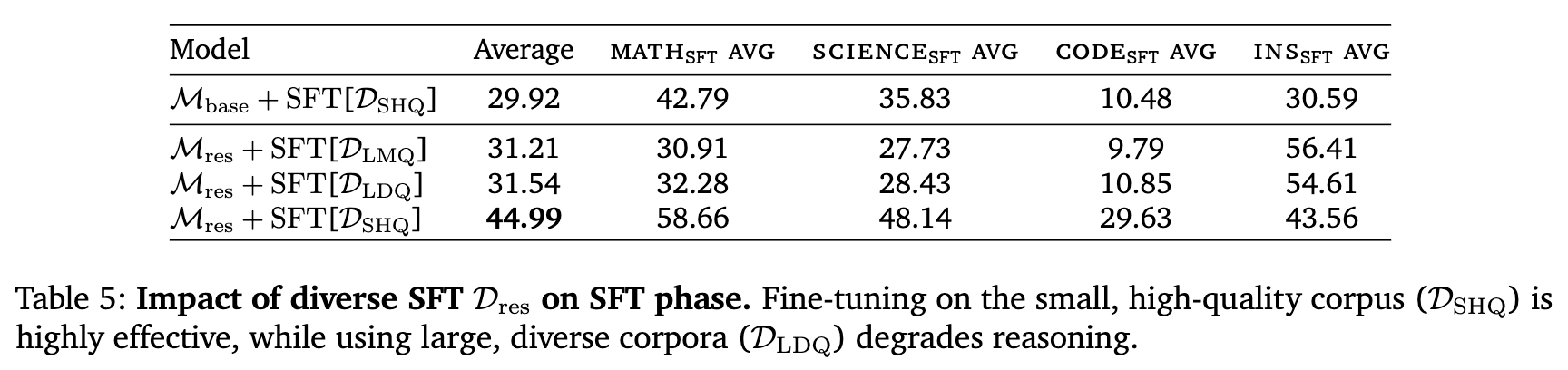
表 5 的结果揭示了一个鲜明的对比,也是本文最重要的洞察之一:
-
SFT阶段由质量主导: 当使用小规模、高质量的 进行SFT时,模型性能得到了巨大提升(平均44.99)。 -
多样性在SFT阶段可能有害: 当使用大规模、多样性(但质量混杂)的 或 进行SFT时,模型性能反而大幅下降(平均31.54和31.21)。其在数学、代码和科学等核心推理任务上的表现,甚至不如经过 微调的 基线模型。
这一结果导出了一个清晰、可操作的非对称数据分配原则:
-
预训练阶段,应优先考虑数据的多样性和规模,以建立一个泛化能力强的推理基础。 -
SFT阶段,应优先考虑数据的质量和推理深度,以进行有针对性的、高效的能力强化。
4.5. SFT阶段数据质量的解剖:推理深度是关键
那么,“质量”具体指什么?作者通过一个精巧的实验来探究高质量数据的核心特征。他们从大规模、混合质量的数据集 中,仅筛选出答案长度最长(>4096 tokens)的样本,构成了一个规模小得多但推理链条可能更复杂的数据集 。然后,他们用 对 模型进行SFT,并与使用完整 进行SFT的结果进行对比。

如表 9 所示,结果是惊人的。切换到规模小50倍、但按答案长度过滤的 数据集,模型的整体性能提升了近10个点。尤其是在数学(提升超过32点)、科学和代码等领域,性能实现了飞跃。这有力地证明了,在SFT阶段,更长的思维链(CoT)作为一种更丰富的监督信号,是数据质量的一个关键指标。 即使这些长推理链来源于一个原本噪声较大的数据集,只要通过简单的启发式规则(如长度过滤)筛选出来,就能产生巨大的效益。这也为构建高效SFT数据集提供了一个成本效益极高的方法。
4.6. 数据重复训练的再思考:是巩固基础,而非灾难性遗忘
一个在序列化微调中常见的担忧是,在预训练和SFT阶段使用相同的数据会导致“灾难性遗忘”或过拟合。作者通过图2直接回应了这个问题。
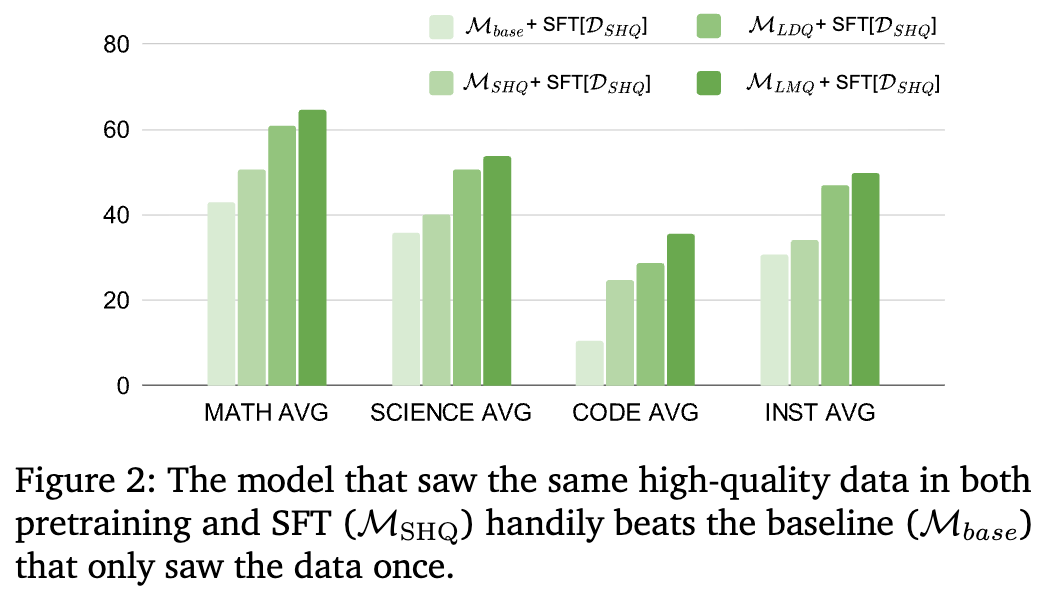
图 2 比较了几个关键模型在SFT后的表现:
-
:只在SFT阶段见过一次高质量数据 ,表现最差。 -
:在预训练和SFT阶段见过两次相同的高质量数据 。其性能远超 。
这表明,第二次接触相同的高质量数据,起到了强化和巩固核心技能的作用,而不是覆盖或遗忘。 -
:预训练接触了多样化+高质量数据,SFT再次接触高质量数据。其表现最好。
这个结果表明,对于推理能力而言,高质量数据重复训练是有益的。
5. 总结
这篇论文的核心贡献可以总结为以下几点:
-
“前置推理”至关重要:将推理数据在预训练阶段早期引入,可以为模型建立一个持久且可复利的优势基础。 -
“追赶假说”被证伪:后期的监督微调(SFT)无法完全弥补在预训练阶段缺失的推理基础。SFT是放大器,而非替代品。 -
数据分配的非对称原则:最优的数据分配策略是阶段依赖的。预训练受益于数据的多样性与规模,而SFT则由数据的质量与推理深度主导。 -
高质量数据的潜在价值:在预训练中加入的高质量数据可能具有潜在效应,其全部价值需要在SFT对齐阶段才能被“解锁”。 -
SFT数据质量的关键指标与扩展方式:长思维链是SFT数据质量的关键。有效的扩展策略是精准地增加高质量、推理密集的样本,而非盲目扩大规模。 -
高质量数据重复训练有益:在预训练和SFT中重复使用高质量推理数据可以有效巩固技能,而非导致过拟合。
这些发现共同挑战了将预训练(语言建模)与后训练(推理能力培养)严格分离的传统观念。它表明,一个真正强大的推理模型,其能力的培养必须贯穿于整个训练流程的始终,从第一个 Token 的预训练开始。这要求我们以一种更整体、更具规划性的“数据流程思维”来指导模型的开发,而不仅仅是孤立地优化某个特定阶段。
往期文章:


