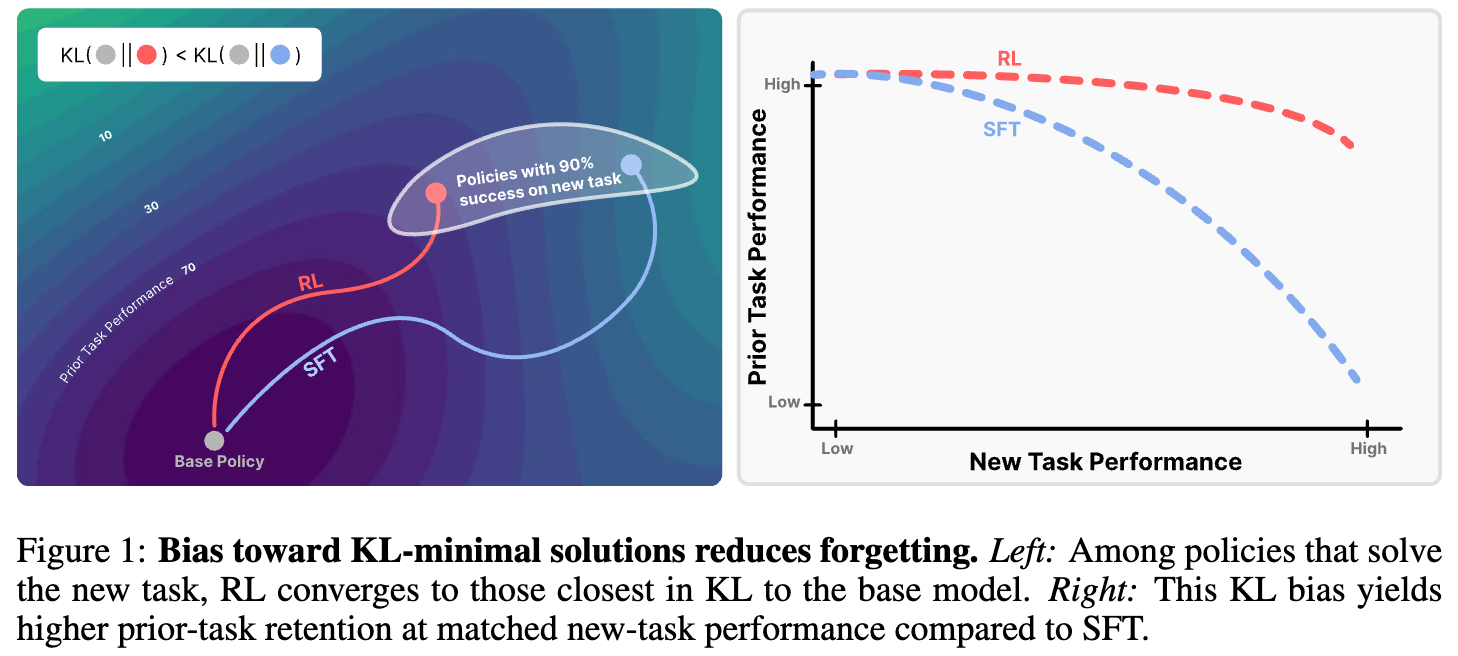
我们知道知识蒸馏(Knowledge Distillation)主要被视为一种模型压缩或在有监督微调阶段提升性能的手段。然而在过去的一年中,知识蒸馏在大模型预训练阶段取得了显著地位。
来自 Meta AI 和卡内基梅隆大学的研究者们发表的论文《Distilled Pretraining: A modern lens of Data, In-Context Learning and Test-Time Scaling》,重新审视了蒸馏预训练这个手段,揭示了对上下文学习(In-Context Learning, ICL)和测试时扩展(Test-Time Scaling)的影响。

-
论文标题:Distilled Pretraining: A modern lens of Data, In-Context Learning and Test-Time Scaling -
论文链接:https://arxiv.org/pdf/2509.01649
这篇论文的重要性在于它回答了几个根本性问题:
-
蒸馏预训练所带来的收益,仅仅是因为“教师模型”见过了更多的数据吗?还是蒸馏过程本身存在独特的优势? -
在现代 LLM 所依赖的新范式(如 ICL)上,蒸馏预训练是放大还是减弱了这一能力? -
蒸馏预训练如何影响模型的生成多样性,进而影响其在需要多轮尝试的复杂推理任务上的表现?
1. IsoData 实验
在探讨蒸馏预训练的复杂效应之前,我们必须首先回答一个基础性问题:蒸馏的收益究竟源自何处?
传统的认知是,教师模型通常比学生模型更大、能力更强,并且在更多的数据上训练过。因此,学生模型通过蒸馏从教师那里学到的“知识”,很可能大部分是其未曾见过的“额外数据”的体现。如果这个假设成立,那么随着我们逼近“数据墙”(Data Wall)的极限,蒸馏的价值将会大打折扣。
为了剥离“额外数据”这一混淆变量,论文设计了一组名为 “IsoData Distillation”(等数据量蒸馏) 的核心对照实验。
1.1 IsoData 实验设计
实验设置如下:
-
教师模型 (Teacher Model) :一个 8B 参数的模型,在 1T (万亿) tokens 的数据上进行训练。 -
学生模型 (Student Model) :一个 1B 参数的模型。 -
对照组 (Standard Pretraining, SPT) :学生模型在与教师模型完全相同的 1T tokens 数据上进行标准(从零开始)的预训练。 -
实验组 (Distilled Pretraining, DPT) :学生模型同样在 1T tokens 数据上进行预训练,但其损失函数结合了来自教师模型的“软标签”(soft labels)。
这里的关键在于,学生模型和教师模型看到了完全相同的数据集。在这种“IsoData”设定下,如果蒸馏模型(DPT)依然优于标准模型(SPT),那么这种优势就不能归因于教师带来的额外数据,而必须源于蒸馏过程本身所蕴含的某种独特机制。
1.2 IsoData 实验结果与解读
论文在多种标准的语言建模任务上比较了 DPT 和 SPT 的性能,涵盖了常识推理 (Hellaswag)、问答 (Natural Questions)、代码生成 (MBPP) 等。
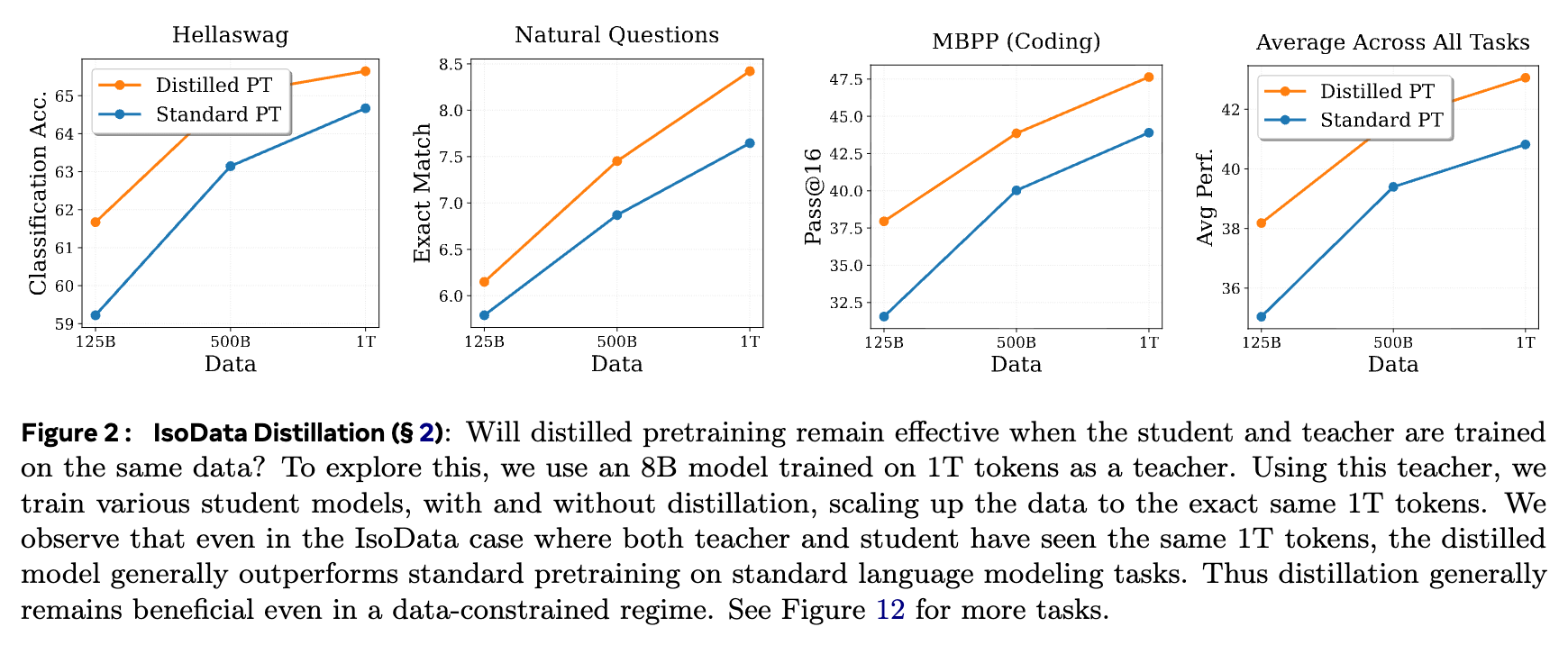
上图展示了 IsoData 设定下的实验结果。横轴代表学生模型训练所用的数据量,从 125B 扩展到 1T。纵轴是各项任务的评估指标。我们可以清晰地观察到:
-
一致的性能优势:在 Hellaswag、Natural Questions、MBPP 以及所有任务的平均表现上,橙线(Distilled PT)几乎在所有数据点上都位于蓝线(Standard PT)之上。 -
数据约束下的有效性:即使在学生和教师看到完全相同的 1T tokens 数据时(图中最右侧的数据点),蒸馏预训练的模型依然在绝大多数任务上表现更优。
这一结果有力地证明了:蒸馏预训练的价值超越了单纯的数据增强。即使在数据受限的场景下,它依然是一种有效的训练策略。
1.3 优势来源
那么,这种不依赖于额外数据的优势从何而来?论文引用并讨论了近期的理论工作,将其归因于隐式正则化 (implicit regularization) 。
-
优化视角:蒸馏过程可以引导学生模型在参数空间中走向一个泛化能力更好的区域。教师的软标签可以看作是一种对损失曲面的平滑,帮助学生模型避免陷入过拟合的尖锐局部最小值。 -
表征视角:Nagarajan 等人的研究表明,蒸馏会放大梯度下降的隐式偏置,促使学生模型更快地学习到数据表征的主要特征方向(top eigendirections)。
总而言之,第一部分的 IsoData 实验为整篇论文奠定了坚实的基础。它清晰地表明,我们需要更深入地探索蒸馏过程本身,理解它如何塑造模型的内在能力,而不是简单地将其视为一种传递更多数据的管道。这为后续探讨蒸馏对 ICL 和测试时扩展的影响铺平了道路。
2. 蒸馏预训练的得与失
在证实了蒸馏的内在价值后,论文进入了核心论述部分:通过现代 LLM 的棱镜,即上下文学习(ICL)和测试时扩展(Test-Time Scaling),来审视蒸馏预训练带来的影响。研究发现,蒸馏预训练是一把双刃剑,它在增强一项能力的同时,可能会损害另一项能力。
2.1 “失”——对上下文学习 (ICL) 的损害
上下文学习(ICL)是现代 LLM 的一项标志性能力,它使得模型能够在不更新权重的情况下,仅通过推理时提供的几个示例(in-context examples)来完成新任务。
2.1.1 归纳头 (Induction Heads) 与 ICL 的内在机制
Olsson 等人的开创性工作揭示了 ICL 的一个关键微观机制:归纳头(Induction Heads)。归纳头是 Transformer 中的一种特殊注意力模式,它使模型能够执行“搜索并复制”的操作。例如,当模型看到 ... "apple" means "red" ... what does "apple" mean? 这样的序列时,归纳头可以定位到前一个 "apple" 出现的位置,并复制其后跟随的 "red"。
这种复制能力对于许多 ICL 任务至关重要,因为它要求模型精确地、确定性地(deterministically)再现上下文中的信息。这是一种低熵(low-entropy)的任务:对于一个给定的输入,正确的下一个 token 是唯一或极少数的。
2.1.2 蒸馏如何损害 ICL
论文通过一系列 ICL 相关的任务来评估蒸馏的影响,包括:
-
基于上下文的问答 (Context-based QA) :答案必须来自所提供的上下文。 -
大海捞针 (Needle in Haystack) :在长文本中定位并复述一个特定的信息。 -
反事实上下文问答 (Counterfactual Context QA) :上下文中的信息与模型的内在知识相矛盾,强制模型依赖上下文。

上图展示了蒸馏对 ICL 任务性能的影响,同样是在 IsoData 设定下。
-
优势随数据量增加而减弱:在训练数据较少时(如 125B),蒸馏模型(橙线)优于标准模型(蓝线)。这可能是因为教师(已在 1T 数据上训练)见过了更多样的复制任务,提供了更好的监督信号。 -
IsoData 设定下的性能反转:当学生模型的数据量增加到与教师相同的 1T 时(最右侧的数据点),情况发生了反转。在“大海捞针”和“反事实问答”这类强依赖精确复制的任务上,蒸馏模型的性能反而低于标准预训练模型。
为什么会这样? 论文给出了深刻的解释:
-
完美教师的无效性:对于归纳头这样的低熵任务(例如,复制 token A),理想的监督信号是一个 one-hot 向量,在A的位置为 1,其余为 0。一个完美的教师模型,其输出也会是这样一个 one-hot 分布。在这种情况下,蒸馏的软标签与原始的硬标签(ground truth)完全相同,没有提供任何额外信息。 -
不完美教师的噪声注入:在现实中,教师模型并非完美。它的输出分布即使在 A上有最高的概率,也可能为其他 token 分配一些非零的微小概率。这种“软化”的监督信号,实际上是向一个本应是确定性的任务中注入了噪声。它告诉学生模型:“下一个 token 主要是A,但也可能是B或C”。这种模糊的信号会阻碍学生模型学习到精确、无歧义的复制能力,从而损害了归纳头的形成。
因此,蒸馏预训练的本质——使用软标签进行监督——与 ICL 核心机制(归纳头)所依赖的确定性、低熵的特性产生了冲突。
2.2 “得”——测试时扩展 (Test-Time Scaling) 能力的增强
虽然蒸馏损害了 ICL,但它在另一方面带来了显著的收益:增强了模型的测试时扩展能力。
2.2.1 pass@k 与生成多样性
测试时扩展通常通过 pass@k 指标来衡量,常见于代码生成和数学推理等任务。pass@k 的含义是:模型生成 k 个不同的答案,只要其中至少有一个是正确的,就算通过。
-
pass@1衡量的是模型的准确性(precision):模型最自信的那个答案是否正确。 -
pass@k(当k > 1) 衡量的是模型的广度或生成多样性(breadth/diversity):模型能否生成一个包含正确答案的候选集合。
对于许多可以通过验证器(verifier)检查答案是否正确的任务(如代码是否通过单元测试,数学题答案是否正确),高 pass@k 表现至关重要。这意味着即使模型的首选答案是错的,我们也可以通过多次采样来找到正确答案。
2.2.2 蒸馏如何增强测试时扩展
论文在 GSM8k(数学应用题)、MATH(高级数学)和 MBPP(基础 Python 编程)等任务上对比了不同模型的 pass@k 表现。
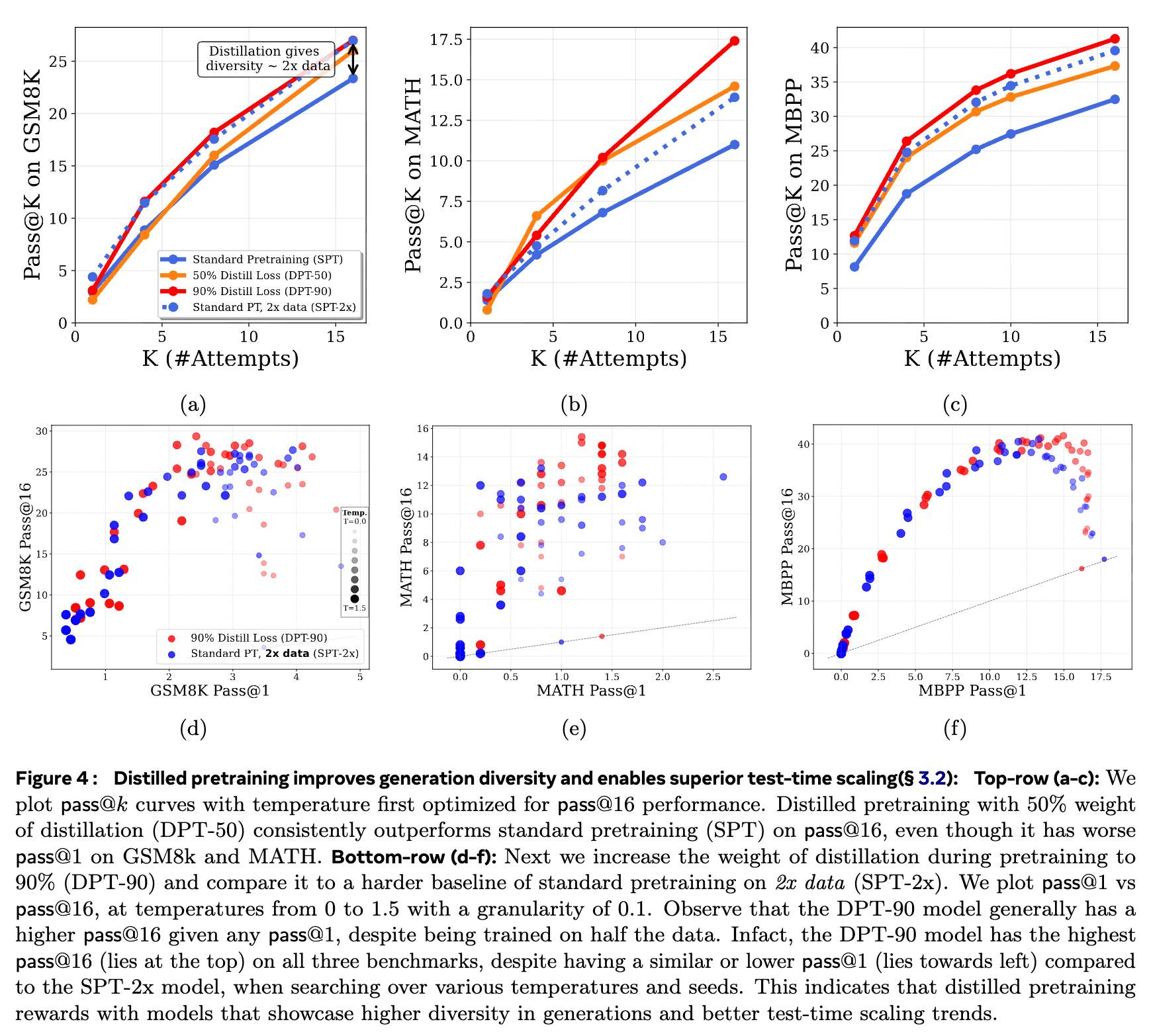
上图(a-c)展示了 pass@k 曲线。DPT-50 代表蒸馏损失权重为 50% 的模型。
-
交叉现象:在 GSM8k 和 MATH 任务上,尽管 DPT-50 的 pass@1表现与 SPT 相当甚至略差,但随着k的增加,DPT-50 的性能曲线迅速超越 SPT。例如,在 GSM8k 上,pass@16的表现 DPT-50 达到了约 27%,而 SPT 只有 23%。这清晰地表明蒸馏模型生成了更多样且有用的候选解。
上图(d-f)从另一个角度展示了这种优势。它绘制了 pass@1 vs pass@16 的关系图,每个点代表在不同采样温度下的模型表现。
-
帕累托最优:DPT-90(蒸馏权重90%)的曲线(蓝色点集)整体位于 SPT-2x(2倍数据训练的标准模型)的曲线(红色点集)的上方。这意味着,对于任意给定的 pass@1水平,蒸馏模型都能达到一个更高的pass@16水平。这证明了蒸馏模型在生成多样性上具有压倒性优势,甚至超过了用两倍数据训练的标准模型。
为什么会这样? 这与蒸馏损害 ICL 的原因是同一个机制的两个方面:
-
高熵任务的丰富监督:与 ICL 不同,许多通用的语言建模任务是高熵(high-entropy)的。例如,对于前缀 I work at,合理的续写可以是the hospital,a restaurant,a gym等等。 -
硬标签的局限性:在标准预训练中,训练数据只提供了这些可能性中的一个样本(例如, the hospital)。这相当于一个 one-hot 的硬标签,它告诉模型只有一个正确答案,而忽略了其他所有合理的可能性。 -
软标签的优势:教师模型由于其强大的能力,在其输出的 logits 中,会为所有这些合理的续写( hospital,restaurant,gym)都分配较高的概率。学生模型通过学习这个软标签分布,能够理解到这个情境下存在多个有效的答案,并学会了它们之间的相对可能性。这种监督信号远比单一的硬标签要丰富得多。
因此,蒸馏通过提供一个更平滑、更多样化的目标分布,教会了学生模型“世界的真实概率分布”,而不是训练数据中的“经验采样分布”。这使得模型在面对高熵任务时,能够生成更多样、更合理的候选,从而极大地提升了 pass@k 性能。
2.3 小结:一个核心权衡
总结第二部分,论文揭示了一个由蒸馏预训练引发的核心权衡:
-
在低熵、确定性任务(如 ICL 中的复制)上,蒸馏的软标签会引入噪声,损害性能。 -
在高熵、多可能性任务(如开放式生成和复杂推理)上,蒸馏的软标签提供了比硬标签更丰富的监督信号,增强了生成多样性和测试时扩展能力。
理解这个核心权衡,是有效运用蒸馏预训练的关键。
3. 理论研究
为了更清晰、更可控地验证上述关于“高/低熵任务权衡”的直觉,论文构建了一个二元模型(bigram model)的沙盒环境。二元模型非常简单,下一个 token 的概率只依赖于前一个 token。这可以用一个迁徙矩阵 来表示,其中 是在看到 token 后,下一个 token 是 的概率。
3.1 沙盒实验设计
在这个沙盒中,研究者可以精确地控制迁徙矩阵 的每一行,从而模拟不同类型的任务:
-
高熵行 (High-Entropy Rows) :某一行 的概率分布比较均匀,接近均匀分布。这模拟了 I work at这样的高熵前缀,其后可以跟多个合理的 token。 -
低熵行 (Low-Entropy Rows) :某一行 的概率分布非常尖锐,接近一个 one-hot 向量。这模拟了 2 + 3 =这样的低熵前缀,其后几乎只有一个确定的 token (5)。 -
归纳头模拟 (Induction Head Simulation) :通过设置“触发-复制”模式(例如,看到触发 token T后,下一个 token 必然是序列中早先出现过的某个目标 tokenC),来模拟归纳头的复制行为。
3.2 沙盒实验结果
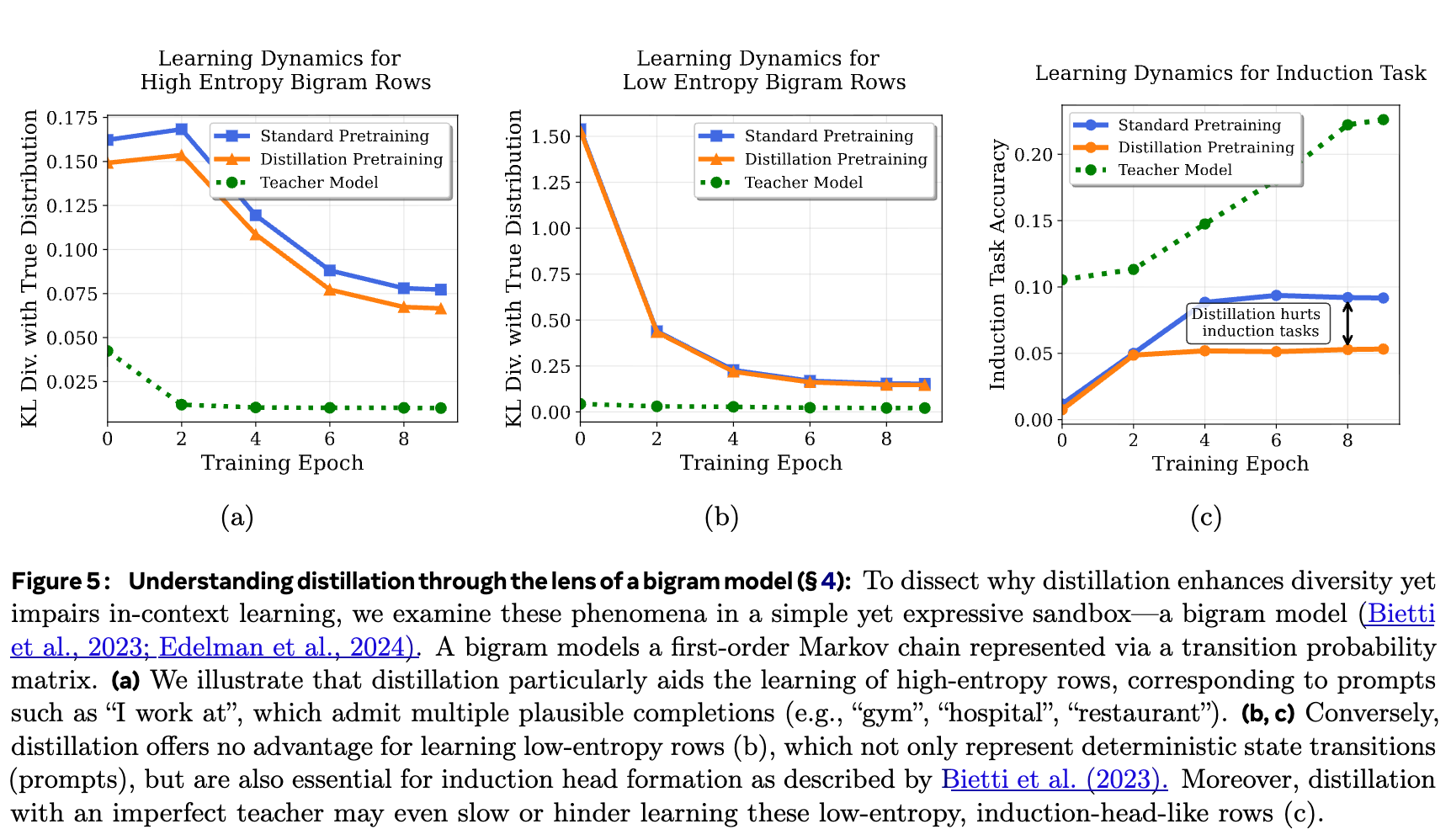
上图展示了沙盒实验的学习动态。纵轴是模型学习到的分布与真实分布之间的 KL 散度(越低越好)或任务准确率(越高越好)。
-
(a) 高熵行学习:蒸馏预训练的学习速度明显快于标准预训练,能用更少的数据达到更低的 KL 散度。这验证了蒸馏在高熵任务上的优势。 -
(b) 低熵行学习:蒸馏和标准预训练的表现几乎没有差别。这验证了在确定性任务上,蒸馏的软标签(在完美教师下)不提供额外信息。 -
(c) 归纳任务学习:蒸馏预训练的性能始终低于标准预训练,并且学习速度更慢。这复现并验证了蒸馏损害 ICL 的发现,并将其归因于不完美教师引入的噪声。
3.3 pass@k 优化的理论视角
论文还从理论上解释了为什么蒸馏有助于 pass@k。对于二元分类问题,标准的贝叶斯最优分类器旨在优化 pass@1,其决策边界是 。它只关心哪个类别的概率更大,而不关心具体的概率值。
然而,当优化 pass@k (k>1) 时,最优分类器的形式会发生变化。论文推导了 pass@k 下的广义贝叶斯最优分类器,其输出的概率 依赖于类别概率的比值 以及 。
这个公式的直观含义是,优化 pass@k 需要模型精确地估计真实的类别概率 ,而不仅仅是它们的排序。正如之前所分析的,蒸馏通过学习教师的软标签,恰恰能够让学生模型更好地逼近真实的概率分布,尤其是在高熵场景下。因此,蒸馏训练出的模型天然地更适合优化 pass@k 指标。
二元模型沙盒的实验和理论分析,为论文的核心观点——高/低熵任务的权衡——提供了坚实的微观层面的证据,使直觉得以在受控环境中清晰地验证。
4. 实践指南
在深刻理解了蒸馏预训练的内在机理和核心权衡之后,论文最后给出了面向实践者的一系列具体、可操作的指南。
4.1 指南一:Token Routing —— 缓解 ICL 性能下降
既然我们知道蒸馏会损害学习低熵(确定性)的复制任务,一个自然的想法是:我们能否在这些任务上“关闭”蒸馏?
论文提出的策略叫做“Token Routing”(令牌路由)。具体操作如下:
-
在训练过程中,对于每个 token,首先计算教师模型输出的概率分布的熵(entropy)。 -
识别出熵最低的 的 tokens。这些 token 很可能对应着那些确定性高的预测(如归纳头复制、 2+3=之后预测5)。 -
对于这 的低熵 tokens,不使用蒸馏损失项,只使用标准的交叉熵损失(即 ground-truth 硬标签)。 -
对于其余高熵 tokens,正常使用蒸馏损失。
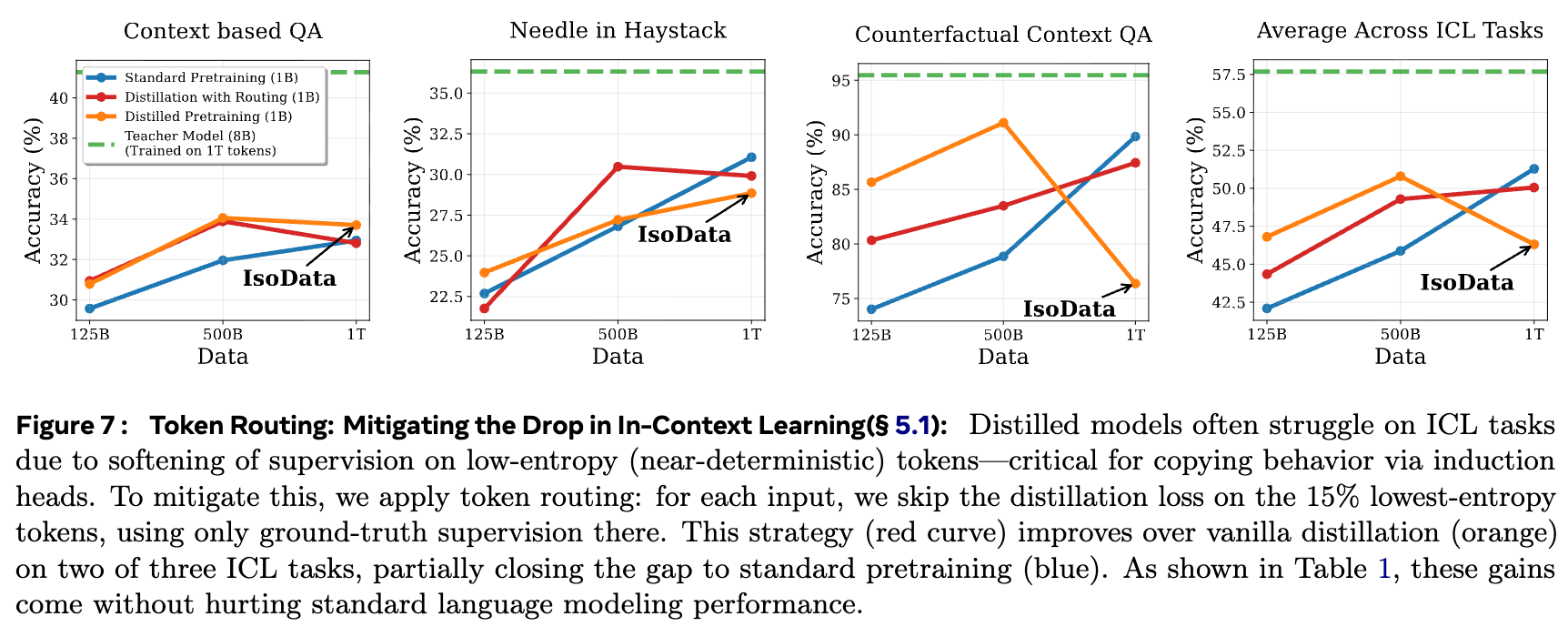
实验结果表明,当设置 x=15% 时,Token Routing 策略(红色曲线)在“大海捞针”和“反事实问答”这两个严重依赖 ICL 的任务上,性能明显优于朴素的蒸馏(橙色曲线),部分弥合了与标准预训练的差距。同时,在标准语言建模任务上,性能几乎不受影响。这证明了 Token Routing 是一种有效缓解蒸馏副作用的策略。
4.2 指南二:蒸馏 vs. 多标记预测 (MTP)
近期,多标记预测(Multi-Token Prediction, MTP)也被提出作为一种增强模型生成多样性的方法。MTP 让模型一次性预测未来多个 tokens,而不是只有一个。那么,对于追求多样性的从业者来说,应该选择 MTP 还是蒸馏?
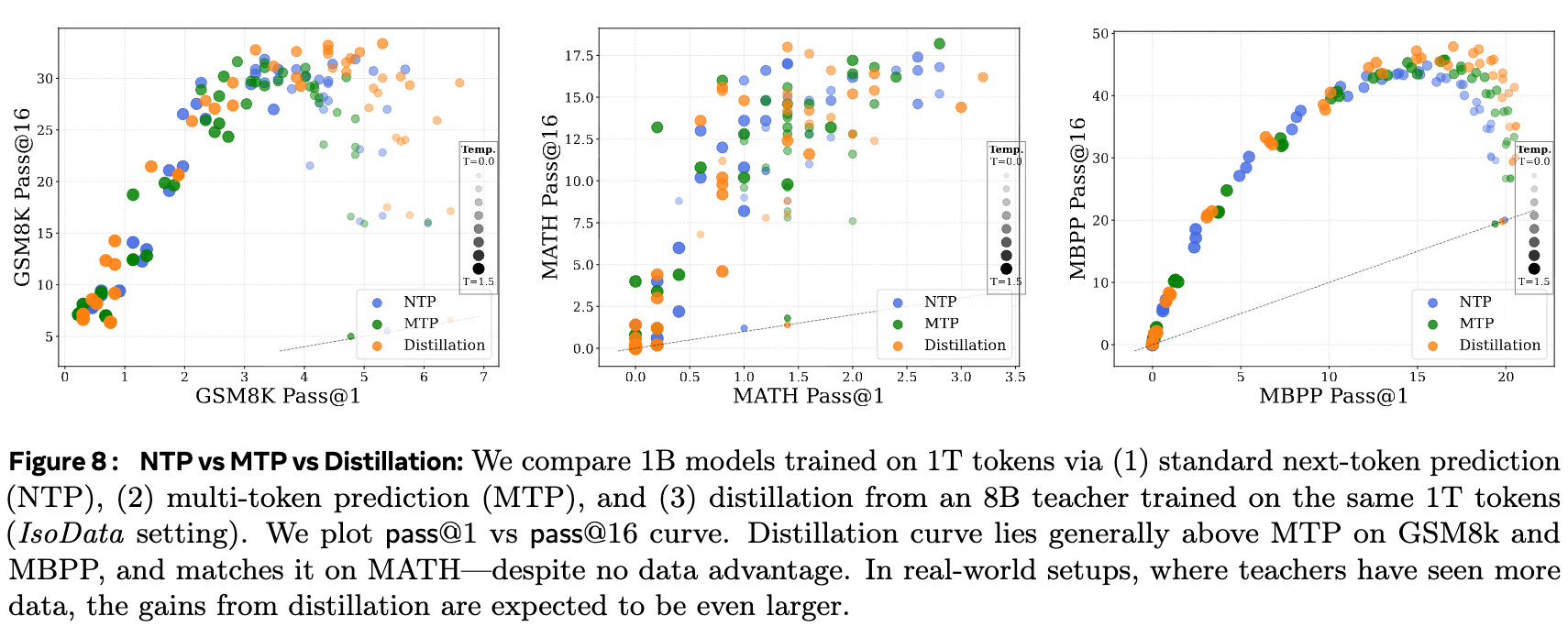
论文在 IsoData 设定下,比较了三种 1B 模型的预训练策略:
-
NTP:标准单标记预测。 -
MTP:多标记预测。 -
Distillation:从 8B 教师模型蒸馏。
结果(pass@1 vs pass@16 曲线)显示,在 GSM8k 和 MBPP 任务上,蒸馏的曲线整体位于 MTP 和 NTP 之上。这意味着,在提升生成多样性方面,蒸馏是比 MTP 更有效的选择,尤其是在没有额外数据优势的情况下。
4.3 指南三:教师模型的选择 —— Base vs. Instruct vs. RL
在进行蒸馏时,一个关键的设计选择是使用哪个版本的教师模型:
-
Base Model:基础预训练模型。 -
Instruct Model:经过指令微调(SFT)的模型。 -
RL Model:经过对齐(如 RLHF)训练的模型。
通常的做法是使用 Base Model 作为教师,因为它与预训练的目标(自由形式的文本补全)最为一致。而 Instruct/RL 模型被认为“过于对齐”,可能失去了生成的多样性。
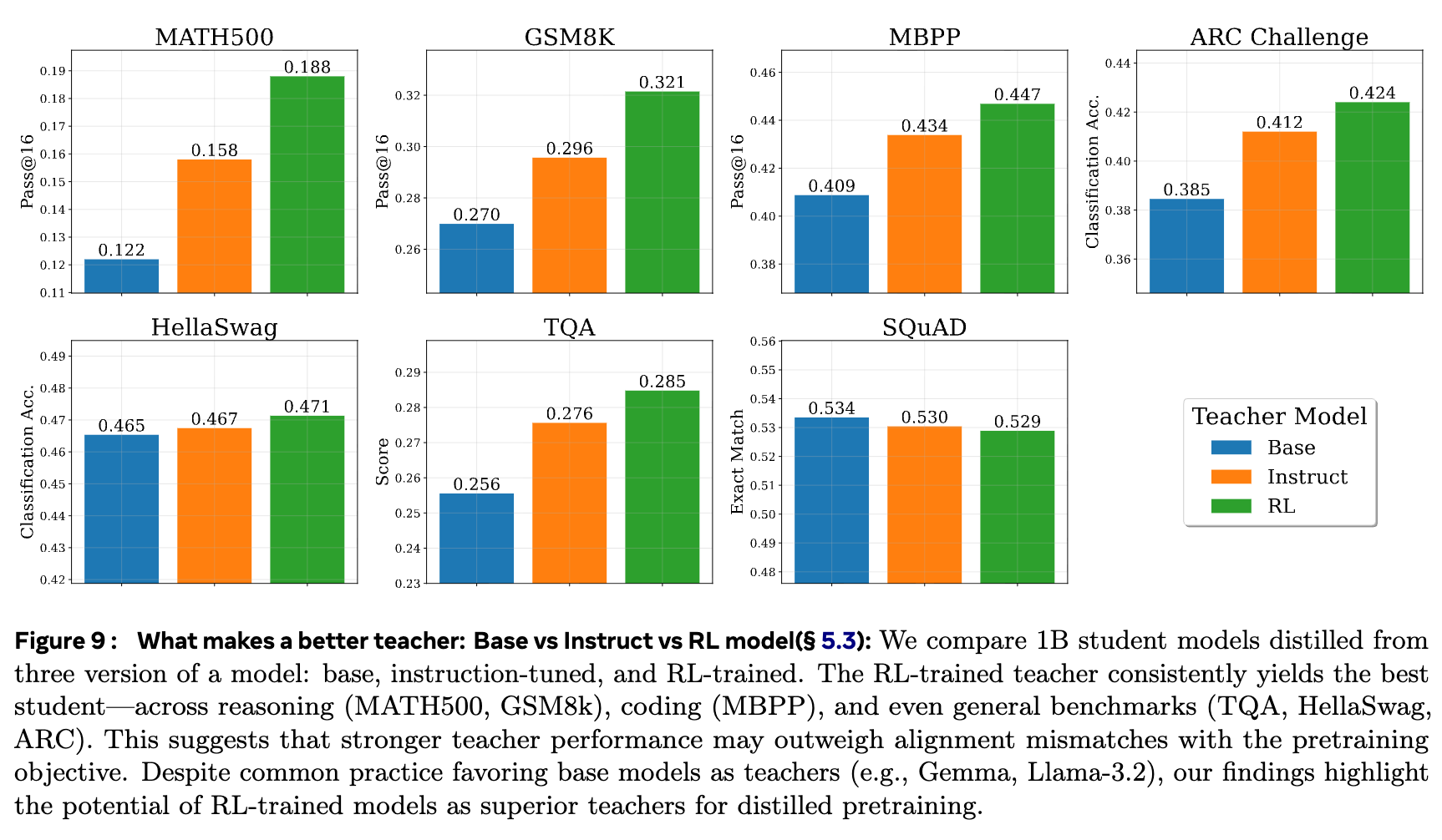
然而,论文的实验得出了一个有些出人意料的结论:
-
在包括推理(MATH, GSM8k)、代码(MBPP)和通用基准(TQA, HellaSwag)在内的几乎所有任务上,使用 RL-trained Teacher 蒸馏出的学生模型表现最好,其次是 Instruct Teacher,表现最差的是 Base Teacher。
这个发现挑战了业界的普遍认知。它表明,一个在下游任务上能力更强的教师,即使其输出分布可能更“尖锐”,但其强大的任务解决能力所带来的高质量监督信号,其益处超过了可能损失一些多样性的弊端。这提示我们,在选择教师模型时,其绝对能力可能是一个比“与预训练目标对齐”更重要的考量因素。
4.4 指南四:Top-k 采样蒸馏
在实际应用中,计算和存储教师模型在整个词汇表上的完整 soft labels 成本很高。一种常见的降成本做法是 Top-k 采样蒸馏:只保留教师 logits 中概率最高的 k 个 token,然后重新归一化形成一个稀疏的软标签。
那么,k 的选择对性能有何影响?
-
k=1:这相当于从教师模型采样生成“合成数据”,然后用硬标签进行标准预训练。 -
k>1:这保留了部分软标签信息。
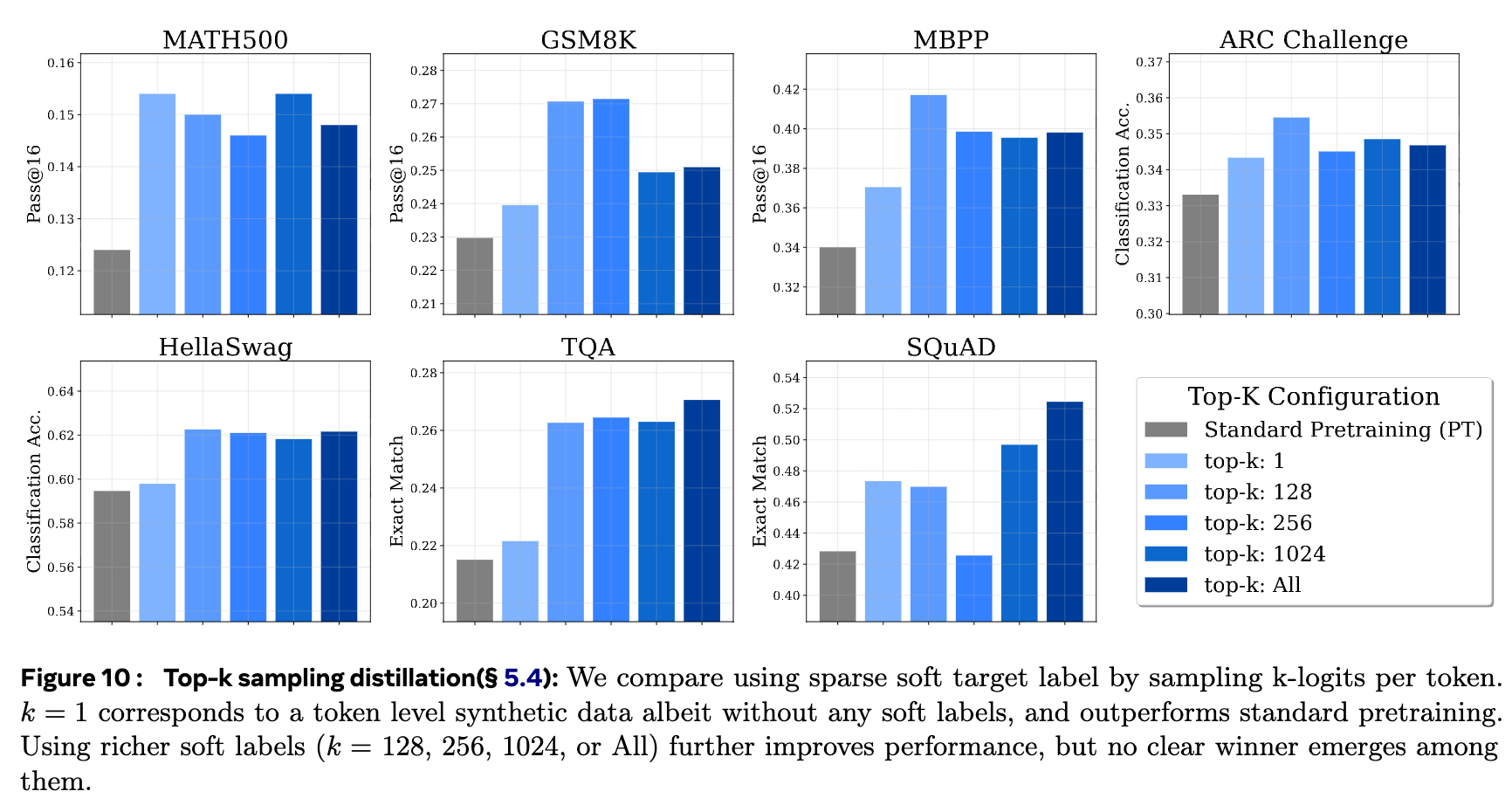
实验结果显示:
-
k=1优于标准预训练:使用教师生成的合成数据进行训练,效果好于直接使用原始数据。这可能是因为教师过滤掉了原始数据中的一些噪声和异常样本。 -
k>1优于k=1:使用稀疏的软标签(如k=128, 256, 1024)通常比只使用k=1的硬标签效果更好。这证明了软标签所携带的“类别间关系”信息是有价值的。 -
k的具体值不敏感:在k较大时(例如从 128 到 All),性能没有明显和一致的规律。这意味着从业者可以选择一个适中的k值(如 256)来平衡性能和计算成本。
总结
核心贡献可以总结为以下几点:
-
证实了蒸馏的内在价值:通过 IsoData 实验,论文证明了蒸馏的优势并不仅仅来源于教师模型的额外数据,蒸馏过程本身通过隐式正则化等机制就能提升模型性能。 -
揭示了核心权衡:蒸馏预训练在“高熵任务”和“低熵任务”之间存在一个根本性的权衡。它通过提供丰富的软标签增强了模型的生成多样性和测试时扩展能力,但代价是可能损害依赖确定性复制的上下文学习(ICL)能力。 -
提供了理论解释:借助二元模型沙盒,论文在可控环境中复现并解释了上述权衡,将其归结为软标签对于不同熵类型任务的差异化影响。 -
给出了实践指导:论文提出了一系列具有高度实践价值的策略,如用 Token Routing 缓解 ICL 问题,论证了蒸馏在多样性上优于 MTP,并给出了关于教师模型选择(RL > Instruct > Base)和 Top-k 采样的宝贵经验。
往期文章:
-
-
-
-
-
DeepSeek V3.1 翻车了!字节 Seed 提出 Inverse IFEval 判断大型语言模型能否听懂“逆向指令”?
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
蚂蚁浙大提出基于“评分细则”(Rubric)的奖励机制,仅靠5000+样本,让30B轻松击败671B DeepSeek V3
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-