12
2025/08
少即是多:Lite PPO如何用最简策略在LLM推理上超越复杂强化学习算法
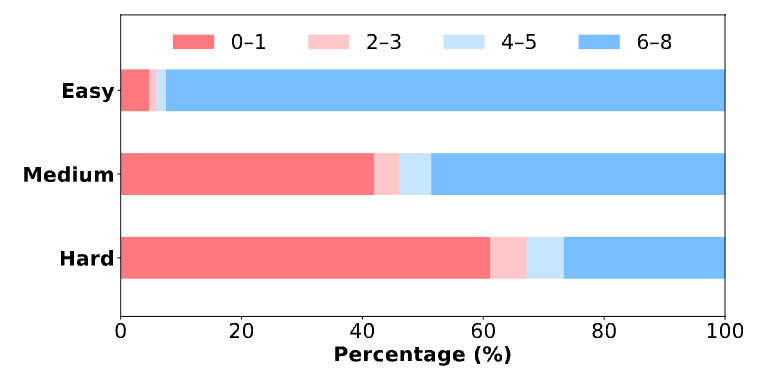
利用强化学习(RL)提升大型语言模型(LLM)的推理能力,即RL4LLM,已成为人工智能领域炙手可热的研究方向。然而,该领域的飞速发展也带来了一系列严峻挑战:
...