22
2025/08
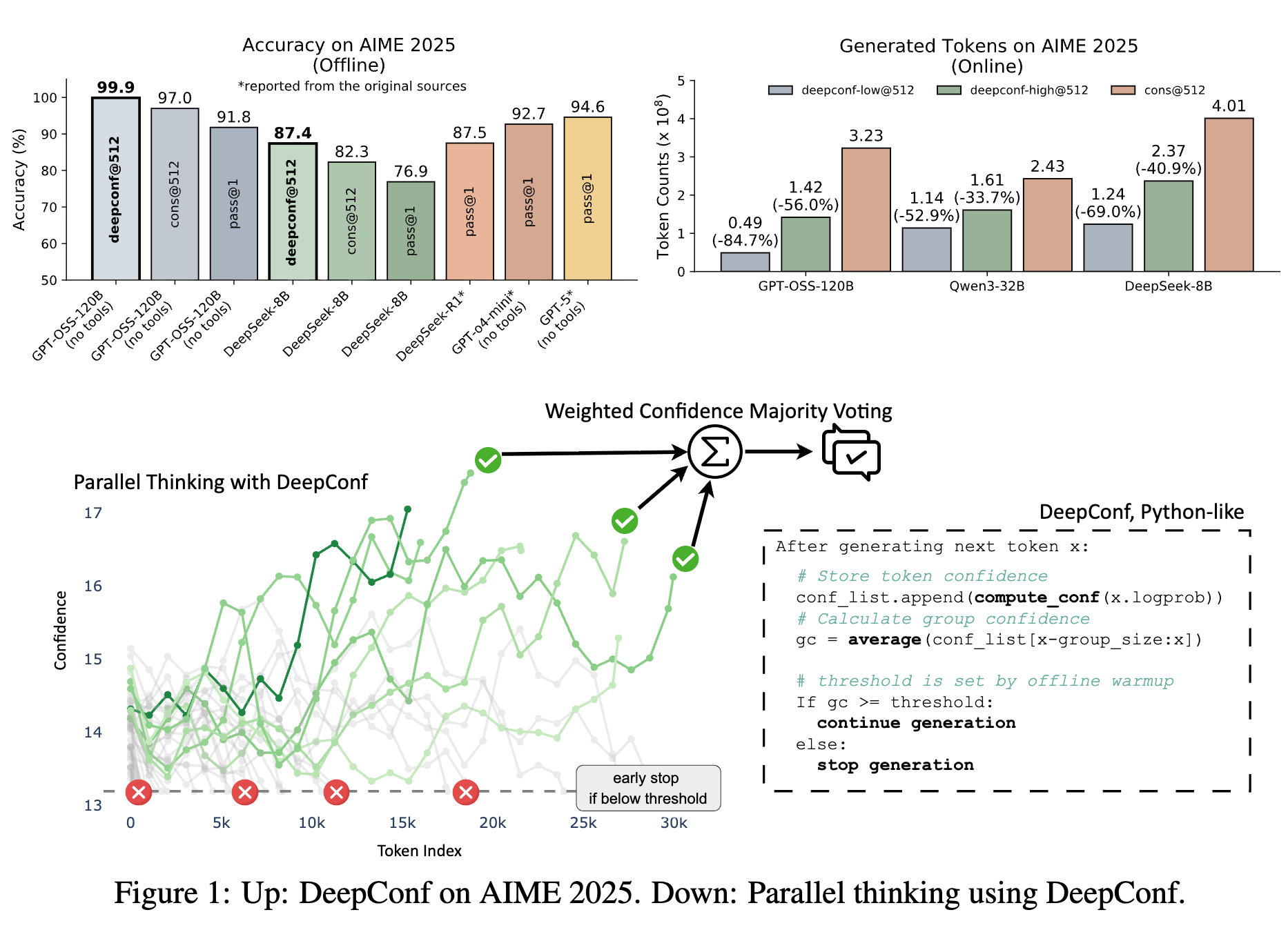
Meta AI&UCSD提出DeepConf:将GPT-OSS-120B AIME 2025准确率提升至99.9%
测试时(test-time)扩展大模型推理能力的核心好处是无需重新训练或微调模型,即可在推理阶段动态提升其在特定任务或复杂场景下的性能与泛化能力。但是在面对复
...

“天下没有免费的午餐”:反思LLM推理中的内在反馈
最近出了不少基于内在反馈的强化学习(Reinforcement Learning from Internal Feedback, RLIF)的研究成果,RLI
...

GEPA:反思式Prompt进化,效果超过RL
仅靠prompt工程就可以超过强化学习?
是的,没错。来自UC Berkeley、斯坦福大学等机构的研究者们提出了一篇论文:《GEPA: REFLECTIVE
...